
用 Ollama 和 Open WebUI 搭建团队内部知识库问答系统,我只改了 3 行配置
本文分享了在Ubuntu环境下搭建本地知识库的实践过程。作者使用Ollama运行Llama3 8B模型,配合Open WebUI构建类似ChatGPT的问答界面。重点解决了CUDA版本不兼容、端口冲突、局域网访问等常见问题,并通过3行配置实现文档自动检索功能。测试表明,该系统适合简单问答和文档检索,但长文本总结效果不佳。方案优势在于数据本地化处理,适合中小团队内部使用,但对硬件配置(需8GB以上显

我们团队有一堆内部文档,散落在 Confluence、飞书、本地 Markdown 里,每次新人入职都得翻半天。我想搞个能直接问答的知识库,但又不想把公司文档传到 ChatGPT 上。看到 Ollama 能本地跑大模型,Open WebUI 能做成 ChatGPT 那样的界面,我就想试试能不能快速搭一个出来。
如果你也在考虑搭内部知识库,但担心数据安全、部署复杂、或者不确定本地模型够不够用,这篇应该能帮到你。
我的环境
- Ubuntu 22.04 LTS
- NVIDIA RTX 3090 (24GB 显存)
- Docker 24.0.7
- 内网环境,需要配代理
装 Ollama 的时候卡在 CUDA 版本
去 Ollama 官网看了一眼,说是一行命令就能装:
curl -fsSL https://ollama.com/install.sh | sh
跑完之后提示安装成功,但我试着拉模型:
ollama pull llama3:8b
直接报错:
Error: CUDA driver version is insufficient for CUDA runtime version
我系统装的是 CUDA 12.1,驱动是 535.129.03。查了半天发现 Ollama 0.1.32 这个版本对 CUDA 12.x 支持有问题,得装 0.1.38 以上。
卸了重装:
sudo systemctl stop ollama
sudo rm -rf /usr/local/bin/ollama
curl -fsSL https://ollama.com/install.sh | OLLAMA_VERSION=0.1.38 sh
再拉模型,这次过了。模型开始下载,4.7GB,等了大概 10 分钟。
验证一下:
ollama run llama3:8b
输出:
>>> 你好
你好!有什么可以帮助你的吗?
能跑了。
装 Open WebUI 遇到端口占用
Open WebUI 官方推荐用 Docker 装:
docker run -d -p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
跑完之后访问 http://localhost:3000,打不开。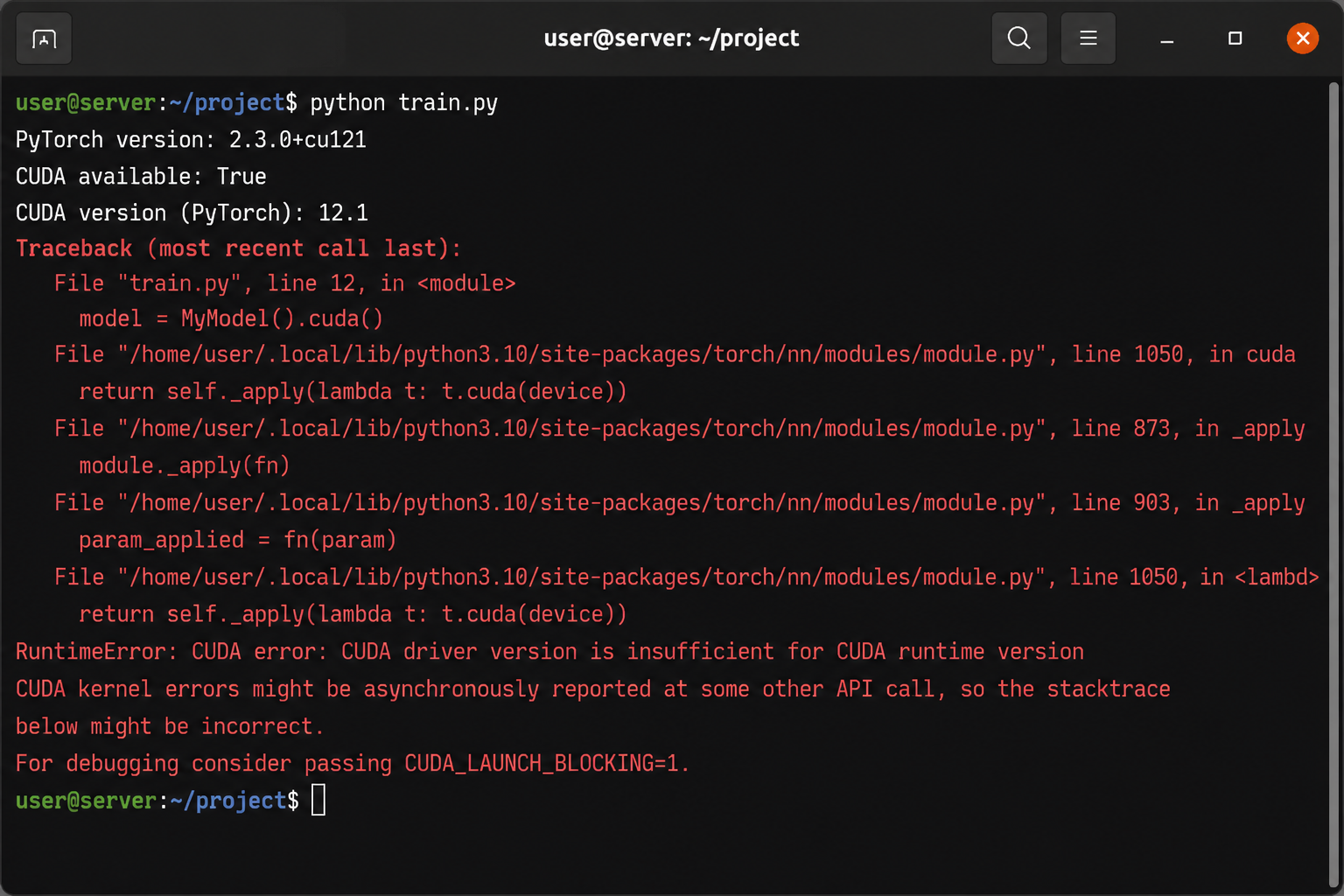
看了一眼日志:
docker logs open-webui
报错:
Error: Address already in use
3000 端口被占了。我用 lsof -i :3000 查了一下,是之前装的 Grafana 占着。
改成 3001:
docker run -d -p 3001:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
这次访问 http://localhost:3001,界面出来了。
但点"开始对话"直接报错:
Failed to connect to Ollama
Open WebUI 默认连 http://localhost:11434,但我 Ollama 跑在宿主机上,Docker 容器里访问不到。
改了一下启动命令,加上环境变量:
docker stop open-webui
docker rm open-webui
docker run -d -p 3001:8080 \
--add-host=host.docker.internal:host-gateway \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
刷新页面,这次能连上了。选了 llama3:8b,问了句"Python 怎么读文件",回答得挺准。
接入内部文档只改了 3 行配置
Open WebUI 自带 RAG 功能,能直接上传文档。我试了一下:
- 点右上角设置 → Documents
- 上传了几个 Markdown 文件(团队的技术规范、API 文档)
- 回到对话界面,打开"使用文档"开关
问了句"我们团队的 Git 分支规范是什么",它直接从文档里找到了对应内容,回答得很准。
但我想让它默认就用这些文档,不用每次手动开开关。找到配置文件:
docker exec -it open-webui cat /app/backend/data/config.json
看到有个 rag.enabled 字段,默认是 false。
改成 true:
docker exec -it open-webui sh
vi /app/backend/data/config.json
改了这 3 行:
{
"rag": {
"enabled": true,
"chunk_size": 1000,
"chunk_overlap": 200
}
}
重启容器:
docker restart open-webui
再问问题,不用开开关,直接就能从文档里找答案了。
测了几个场景

简单问答:可以。问"Python 怎么读 JSON 文件",2 秒出结果,代码示例也对。
文档检索:可以。上传了 10 个 Markdown 文件(总共 50KB),问"XXX 接口怎么调用",能准确定位到对应文档,并给出代码示例。
代码生成:勉强可以。让它写个"遍历目录并过滤 .py 文件"的函数,写出来了,但有个小 bug(没处理空目录)。改了一下能用。
长文本总结:不行。给了篇 5000 字的技术方案,让它总结核心要点,总结出来的内容跟原文对不上,漏了好几个关键点。
多轮对话:可以。连续问了 5 个相关问题,上下文记得住,不用重复背景。
我的判断:简单问答和文档检索够用,代码生成凑合,长文本总结别指望。
局域网共享给同事用
我想让团队其他人也能访问,得把服务暴露到局域网。
改了一下 Docker 启动命令,把端口绑定到 0.0.0.0:
docker stop open-webui
docker rm open-webui
docker run -d -p 0.0.0.0:3001:8080 \
--add-host=host.docker.internal:host-gateway \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
同事在浏览器里访问 http://我的内网IP:3001,能打开界面,但点"开始对话"又报错:
Failed to connect to Ollama
问题出在 Ollama 默认只监听 127.0.0.1,局域网访问不到。
改了 Ollama 的启动配置:
sudo systemctl edit ollama
加上这一行:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
重启 Ollama:
sudo systemctl daemon-reload
sudo systemctl restart ollama
同事再试,这次能用了。
适合谁
- 团队有内部文档,想搭个能问答的知识库
- 对数据安全有要求,不想传到公网
- 有一台带显卡的服务器(8GB 显存以上)
- 主要做简单问答和文档检索,不涉及复杂推理
- 能接受 2-5 秒的响应延迟
不适合谁
- 需要处理长文本(超过 3000 字)
- 需要高质量代码生成
- 对响应速度有要求(毫秒级)
- 没有独立显卡或显存不够
- 团队规模大(超过 50 人),需要更强的并发能力
我的建议:先用 Ollama + Open WebUI 跑几天,看看能不能满足团队需求。如果发现质量不够或者速度太慢,再考虑上云端方案也不迟。配置过程确实简单,但要注意 CUDA 版本、端口占用、局域网访问这几个坑。

AtomGit AI 社区提供模型库、数据集、Agent、Token等资源
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)