
test——AI赋能软件测试
本文探讨了AI在软件测试全生命周期中的应用,包括需求分析、测试计划制定、测试用例设计、测试报告生成等环节。通过实际案例展示了如何利用AI工具(如Trae、Postman MCP等)实现接口和Web UI自动化测试,包括登录功能、博客列表、详情页等场景的测试脚本生成与优化。文章详细介绍了AI在测试中的具体应用方法,如使用ICIO和CRISPE框架编写提示词,处理测试数据脱敏问题,以及通过AI发现和修
目录
AI介绍
如今,随着AI的发展能力越来越强,对于互联网行业极大提高生产力和效能,当前从事者可能会面临被AI替代的风险:但是自古以来,被替代的大部分都是那些从事简单重复的工作,要想不在该行业中替代,不断的学习,使用AI才有不被替换的资本!
为什么AI会发展的这么快?
人们在追求“怎么懒”,“怎么快”的问题上不断推进,从手洗到洗衣机,从手敲到AI生成,都是人类再追求问题的答案中发展的:既然AI对于编写代码可以提效,那么对应软件测试也可以,但是关键是怎么用?这才是最重要的
- 设计测试用例:手工设计测试用例在一些小型项目还好,但是在一些复杂大项目来说可能就会费时费力,我们可以把设计测试用例的思路(测试标题,数据,步骤,预期结果等)给AI讲清楚,让他来生成测试用例(选择性保存在文档中)
- 编写缺陷报告,测试报告:也可以让AI来写
- 编写自动化脚本:回归测试使用自动化脚本大大提高测试效率,但让测试人员去编写可能当中会出现各种问题,比如:界面元素找不到,接口正确使用等,实现出来还可以有bug,需要去进行处理,这样完整实现出来也是需要一定时间的,像这种情况也是可以去借助AI生成脚本来实现
但在目前,要上AI生成以上数据,需要保证:公司内部业务数据需要“脱敏”后才能喂给AI,不然存在数据安全问题,数据进行处理也是需要花费一定的时间,这点在目前我没有想到好的解决方法,除非有公司内部自研AI大模型就没有数据安全问题
AI 介入软件生命周期
软件生命周期:
- 需求分析:用户上是否合理,技术上是否可行,测试上是否无逻辑矛盾
- 测试计划:标明了每个需求难度,相关测试人员,测试用例
- 测试设计与开发:根据需求文档来进行测试用例的编写,挑选合适的自动化框架和搭建环境,用来编写自动化代码
- 测试执行:根据测试用例手工执行/代码运行
- 测试评估:经过一轮测试后,哪些用例通过了,哪些没有;P0 用例是否全部通过;分析用例不通过的原因
- 上线:在测试环境-预发环境-正式环境 都测试通过后,正式推到线上环境中
- 运行维护:用户使用过程中,如果有问题还要进过测试人员检验,跟进对应人员解决问题
需求分析
面对一些小需求,需求文档简洁明了的情况下,一目了然;但是当该需求是迭代了很多版本,字数变多了,你分配的需求刚好只是迭代中的一部分,这种情况下你可能在观看时,需要去了解前后之间的关联,然后才能理解你复杂的需求要怎么设计测试用例:可能在观看当中你就会看完一遍不是很了解,看了一遍又一遍...不仅浪费时间,还投入了精力去理解可能还没有理解透;这时我们就可以借助 AI 进行需求分析:把整个文档发给它,再给上对应的提示词信息等待结果
以注册邮箱需求为例:给提示词:需求中的问题分别发送给不同的ai (豆包和Gemini 为例)
同样的提示词,豆包使用表格进行汇总,最后再给优化方案
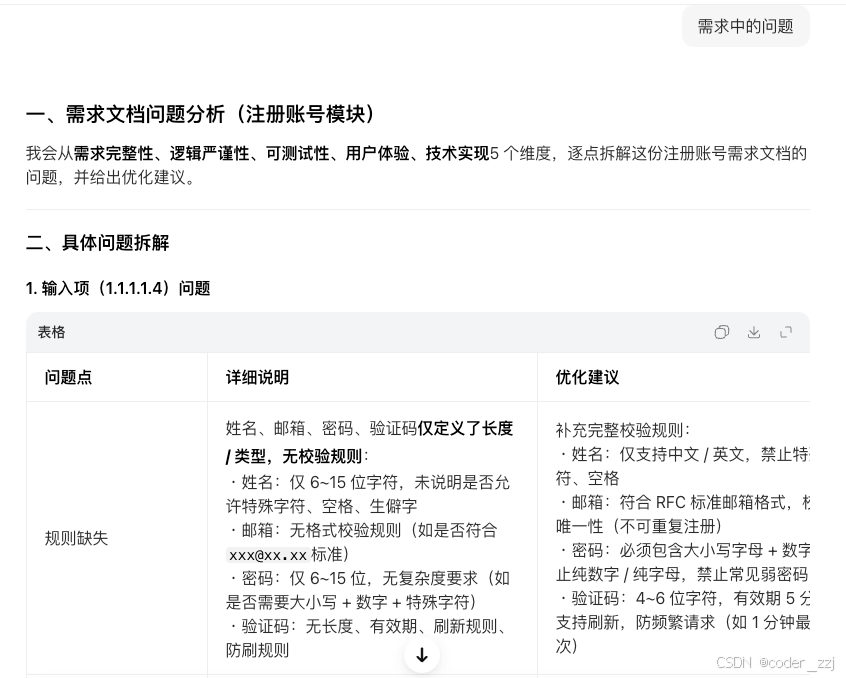
而 gemini 使用多格式进行呈现,并且每个点中给上解决方案

通过该提⽰词,我们可以看到AI给出的结果其实并不符合我们的要求:我们要的是简洁罗列出需求中存在的问题,更换提示词:请详细阅读需求,找出其中存在的模糊描述、不完整信息、逻辑冲突、遗漏或任何可能需要澄清的地⽅,并列出⼀个问题清单。(列举每⼀个问题时请标明原⽂出处或上下⽂,⽅便我与产品同事讨论。)

相比而言,gemini 这次使用的格式就比上面的看起来要清晰点(使用了表格)

看到这里你可能会说,上面这么简单的需求自己就能解决了,用 ai 是不是有点“杀猪用牛刀”的感觉了? 但是你要知道,现实中的需求不是那么简单的:需求可以会经过各种迭代出来的,要完成某个模块的测试就要去了解前因后果,所以使用 ai 来梳理可以避免需求对于人的阅读挑战转而去专心理解需求最主要的功能点的逻辑,从而减低了理解成本,参考提示词:
- 请作为资深软件测试专家,帮助我分析下⾯的需求⽂档,从整体和各个模块的⻆度,提炼出需求的核⼼功能、业务⽬标以及各模块的主要实现内容,并以简洁明了的⽅式输出概要
测试计划
测试计划:本次的项⽬中,测试该按照什么样的⽅式来进⾏,类似“旅游攻略”,测试之前先做好规划,后面按照这个规划好的去执行:比起盲目地执行有方向且有效率;而测试计划一般由于大型项目中,有各种大小需求来规划,如果人为去写的话耗费时间很长,且要经过评审后才是一份完整的计划;现在有了 ai,可以让 ai 在一分钟内生成一份测试计划,根据这份计划和实际情况结合微调,在较短的时间有了份又快又完整的测试计划
以上面的注册需求为例,给上提示词:我是⼀名软件测试⼯程师,现在要对图⽚上项⽬需求⽂档编写测试计划,在2天内完成对全部功能模块的测试,⽬前只有⼀名测试⼈员,输出:《项⽬测试计划书》
从输出内容上看,gemini 生成的内容较精准些,豆包的内容更多更广,几乎是把测试生命周期给包括上了
测试用例
编写测试用例是整个过程中最核心的一步,相对考虑的地方较多花费的时间也比较长,如果让 ai 生成效果怎么样呢?
提示词:“用户的⼿机号为11位”,请针对该功能点设计测试⽤例

可以看到:豆包设计的测试用例范围还是很全面的,出现的用例也没有重复;但是上面仅仅是需求中的一个场景,可以直接把注册邮箱需求发给他,直接让它来设计会怎么样呢?
ai 从功能,易用,兼容,安全,性能方面展开来设计测试用例,覆盖测试范围还是全面的
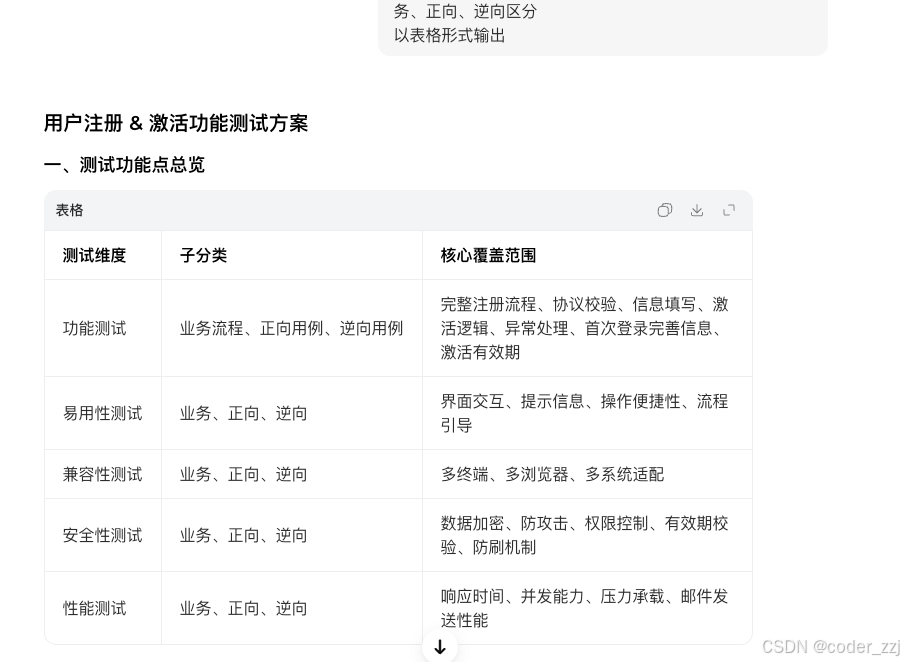
将AI视为测试⼈员的“智能实习⽣”或“超级加速器”,⽽⾮替代者。它擅⻓处理模式识别、枚举和 ⽣成初稿,极⼤地提升效率,特别是在覆盖基础场景⽅⾯。然⽽,测试⼈员的核⼼价值在于其深刻的业务理解、批判性思维、创造性、⻛险评估能⼒和对“测试意图”的精准把握。这些是确保测试有效性的关键,也是AI⽬前⽆法复制的
测试报告
根据测试报告模板
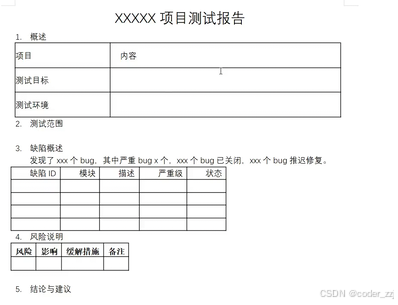
加提示词:请基于以下测试数据和测试报告模板⽣成⼀份测试报告:数据源:
- 测试⽤例总数:85
- 通过⽤例:72
- 失败⽤例:13
- 缺陷个数:20个
- 关闭缺陷:19个
- 推迟修缺陷:1个
缺陷列表:
- 输⼊正确的账号和密码,点击登录,登录失败,严重,已修复;
- 用户登录失败,验证码未刷新,⼀般,已修复;
- 点击分享,分享链接错误,⼀般,已修复;下
- 拉列表未提供输⼊框,对用户使⽤不友好;次要,推迟修复

提示词
ICIO 框架
-
I — Instruction(指令):明确告知 AI 需要执⾏的任务或回答的问题
-
C — Context(背景):提供与任务相关的背景信息或上下⽂,以帮助 AI 理解情境
-
I — Input(输⼊):列出 AI 执⾏任务所需的具体数据或信息
-
O — Output(输出):指定期望的结果格式或输出⽅式
-
C — 能⼒与⻆⾊(Capacity & Role):定义 AI应扮演的⻆⾊或⾝份
-
R — 请求(Request):清楚地说明希望 AI 执⾏的任务或回答的问题
-
I — 信息(Information):提供相关背景或上下⽂信息以辅助⽣成回答
-
S — ⻛格(Style):指定输出内容的语⽓或⻛格
-
P — 参数(Parameters):为⽣成内容设置限制或指导
-
E — 实例(Examples,可选):提供⽰例输出,展⽰期望的格式和质量
trae
使用 trae (使用 gml-5.1)来帮助编写博客登录项目,参考:接口自动化测试
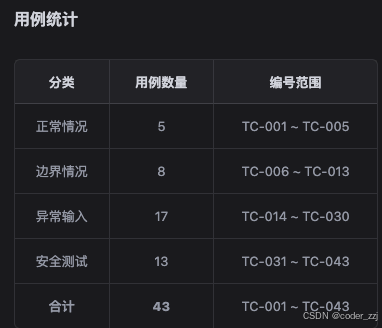
指令:请根据以下接⼝信息,帮我⽣成完整的测试⽤例列表。要求覆盖正常情况、边界情况、异常输⼊、安全测试场景
背景信息:注册接⼝请求参数包含用户名、密码和邮箱三个字段,用户名必填,⻓度3-16,密码必填, ⾄少8位,包含字⺟和数字,邮箱必填,符合邮箱格式
输⼊:接⼝信息如下: POST 192.168.160.203:9090/blog_login.html
请求参数: username: string password: string
输出:⽤表格形式展⽰,包括:⽤例编号、测试⽬标、输⼊参数、预期结果
给出更加准确的数据生成脚本:请帮我使⽤Python和requests库,⽣成⼀个接⼝测试脚本,接⼝信息如下:
接⼝地址:POST 192.168.160.203:9090/blog_login.html
请求参数:username: string(必填)password: string(必填)
正确的账号和密码只有两组:zhangsan 123456 和 lisi 123456
测试⽬标:验证正常注册用户时接⼝返回200,并返回JSON中包含字段"success": true。请⽣成可执⾏脚本,并附带断⾔
import pytest
import requests
BASE_URL = "http://192.168.160.203:9090/blog_login.html"
TIMEOUT = 5
@pytest.fixture(scope="session")
def server_reachable():
try:
requests.post(BASE_URL, data={"username": "test", "password": "test"}, timeout=TIMEOUT)
return True
except requests.exceptions.ConnectionError:
pytest.skip("服务器 192.168.160.203:9090 不可达,跳过所有测试")
except requests.exceptions.Timeout:
pytest.skip("服务器 192.168.160.203:9090 连接超时,跳过所有测试")
except Exception:
return True
def send_login(username, password):
payload = {}
if username is not None:
payload["username"] = username
if password is not None:
payload["password"] = password
return requests.post(BASE_URL, data=payload, timeout=TIMEOUT)
def assert_success(resp):
assert resp.status_code == 200, f"状态码期望200, 实际{resp.status_code}"
body = resp.json()
assert body.get("code") == "SUCCESS", f"code期望SUCCESS, 实际{body.get('code')}, 响应: {body}"
assert body.get("data") is not None, f"data期望非null, 实际null, 响应: {body}"
def assert_fail(resp, expected_err_msg=None):
assert resp.status_code == 200, f"状态码期望200, 实际{resp.status_code}"
body = resp.json()
assert body.get("code") == "FAIL", f"code期望FAIL, 实际{body.get('code')}, 响应: {body}"
if expected_err_msg:
assert body.get("errMsg") == expected_err_msg, (
f"errMsg期望'{expected_err_msg}', 实际'{body.get('errMsg')}', 响应: {body}"
)
# ============================================================
# P0 正常登录测试
# ============================================================
@pytest.mark.parametrize("username,password", [
("zhangsan", "123456"),
("lisi", "123456"),
], ids=["zhangsan正常登录", "lisi正常登录"])
def test_normal_login(server_reachable, username, password):
resp = send_login(username, password)
assert_success(resp)
# ============================================================
# P0 异常登录测试
# ============================================================
@pytest.mark.parametrize("username,password,expected_err", [
("", "123456", "账号或密码不能为空"),
("zhangsan", "", "账号或密码不能为空"),
("", "", "账号或密码不能为空"),
("notexist999", "123456", "用户不存在"),
("zhangsan", "wrongpwd", "密码错误"),
(" ", "123456", "用户不存在"),
("zhangsan", " ", "密码错误"),
], ids=[
"用户名为空",
"密码为空",
"用户名密码均空",
"用户名不存在",
"密码错误",
"用户名纯空格",
"密码纯空格",
])
def test_invalid_login(server_reachable, username, password, expected_err):
resp = send_login(username, password)
assert_fail(resp, expected_err_msg=expected_err)
def test_missing_username_param(server_reachable):
payload = {"password": "123456"}
resp = requests.post(BASE_URL, data=payload, timeout=TIMEOUT)
assert_fail(resp, expected_err_msg="账号或密码不能为空")
def test_missing_password_param(server_reachable):
payload = {"username": "zhangsan"}
resp = requests.post(BASE_URL, data=payload, timeout=TIMEOUT)
assert_fail(resp, expected_err_msg="账号或密码不能为空")
# ============================================================
# P0 边界值测试
# ============================================================
@pytest.mark.parametrize("username,password", [
("ab", "123456"),
("abc", "123456"),
("a" * 16, "123456"),
("a" * 17, "123456"),
("a" * 500, "123456"),
("zhangsan", "a1" * 250),
], ids=[
"用户名2位",
"用户名3位",
"用户名16位",
"用户名17位",
"超长用户名",
"超长密码",
])
def test_boundary(server_reachable, username, password):
resp = send_login(username, password)
assert_fail(resp)
# ============================================================
# P0 安全测试
# ============================================================
@pytest.mark.parametrize("username,password", [
("' OR 1=1 --", "123456"),
("' UNION SELECT * FROM users --", "123456"),
("zhangsan", "' OR '1'='1"),
("zhangsan'; DROP TABLE users; --", "123456"),
("<script>alert(1)</script>", "123456"),
("zhangsan", '<img onerror=alert(1) src=x>'),
("../../etc/passwd", "123456"),
], ids=[
"SQL注入OR",
"SQL注入UNION",
"SQL注入密码",
"SQL注入堆叠",
"XSS-script",
"XSS-IMG",
"路径遍历",
])
def test_security(server_reachable, username, password):
resp = send_login(username, password)
assert_fail(resp)
# ============================================================
# P0 暴力破解测试
# ============================================================
@pytest.mark.parametrize("attempt", range(1, 11), ids=[f"第{i}次错误密码" for i in range(1, 11)])
def test_brute_force(server_reachable, attempt):
resp = send_login("zhangsan", f"wrong{attempt}")
assert_fail(resp)
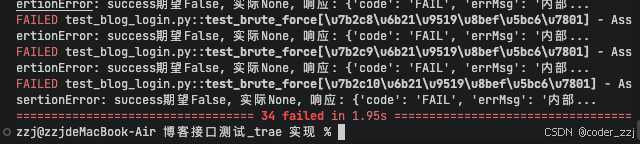
运行用例全部失败,把它们让 AI 进行分析:
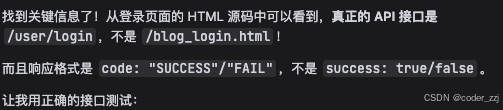
原来是我把 url 写错了,/blog_login.html 是浏览器访问的路径,接口返回要使用 /user/login;修改完之后,所有用例就都通过啦

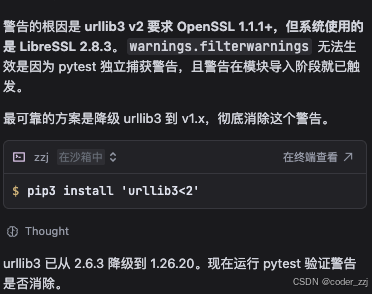
先来解决:这里 pytest 之后有警告很烦,让它来解决:使用 auto 模式它使用的豆包的推理模型来解决,但是解决不了,一直有警告产生;后面换成 glm 5.1 之后一下子就解决了(牛)
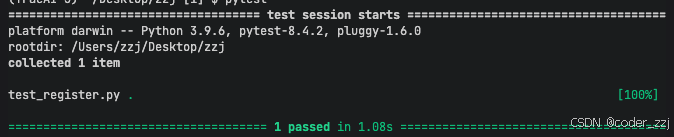
分析接⼝返回值 , 利⽤ pytest 中的参数化操作来减少⽤例数量,并且给上适当的注释让我读起来不用那么费劲要求:1 )可以合并放在同⼀个⽤例中2 )不可以合并的⽤例不做处理,避免强⾏处理降低代码可读性

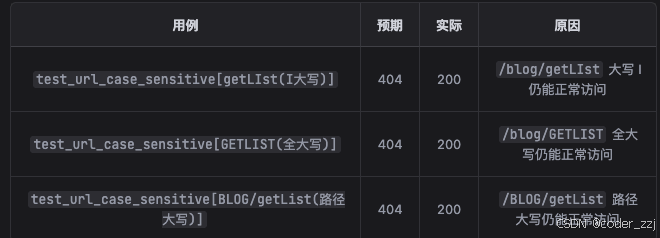
通过以上对登录场景的测试,通过字母大小敏感的四个测试用例,发现了一个BUG
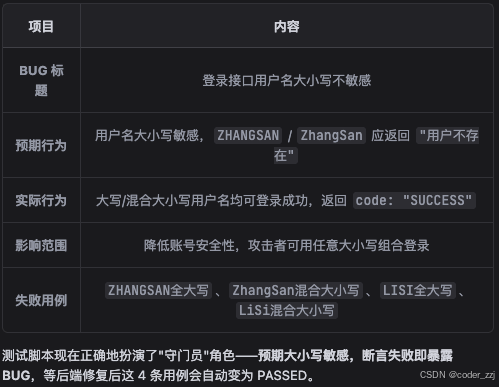
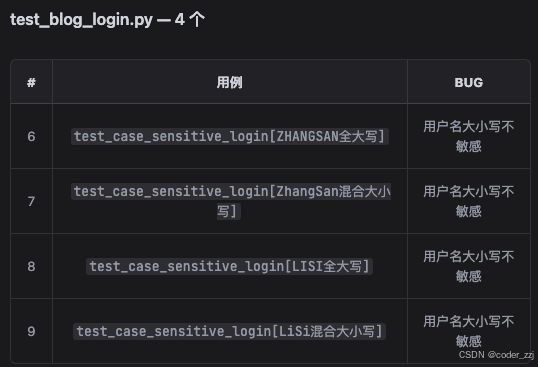
在其他场景中,有时候要依赖登录接口返回的 user_token_header 作为请求参数,才能去测试登录后的其它接口,所以这种情况下也要让 ai 实现出来:
请根据以下接⼝信息 , 帮我⽣成完整的测试⽤例列表。要求覆盖正常情况、边界情况、异常输⼊、安全 测试场景。按照测试的优先级将测试⽤例的数量控制在 10 个以内,⽤表格形式展⽰ , 包括 : ⽤例编号、测 试⽬标、输⼊参数、预期结果GET 192.168.160.203:9090/blog/getLIst请求头:{"user_token_header":"" 这个是登录成功后返回的 data,也就是登录凭证
}⽆请求参数请求成功返回值:{"code" : "SUCCESS" ,"errMsg" : "" ,"data" : [{"id" : ,"title" : " " ,"content" : " " ,"userId" : ,"deleteFlag" : ,"createTime" : "" ,"updateTime" : "" ,"loginUser" :} ] }除了请求成功,其他场景下响应状态码均为 401
先让它看看这个接口是否联通,发现 /blog/getLIst 其实 getLIst 中的 I 大写了,导致无论怎么请求也找不到(怪不得使用 postman 老是有问题)
你先设计出测试用例,再创建新的文件写脚本
import pytest
import requests
from urllib.request import Request, urlopen
from urllib.error import HTTPError
BASE_URL = "http://192.168.160.203:9090"
LOGIN_URL = f"{BASE_URL}/user/login"
BLOG_LIST_URL = f"{BASE_URL}/blog/getList"
TIMEOUT = 5
BLOG_REQUIRED_FIELDS = [
"id", "title", "content", "userId",
"deleteFlag", "createTime", "updateTime", "loginUser",
]
# ============================================================
# Fixture: 服务器连通性预检
# ============================================================
@pytest.fixture(scope="session")
def server_reachable():
try:
requests.get(BLOG_LIST_URL, timeout=TIMEOUT)
return True
except requests.exceptions.ConnectionError:
pytest.skip("服务器不可达,跳过所有测试")
except requests.exceptions.Timeout:
pytest.skip("服务器连接超时,跳过所有测试")
except Exception:
return True
# ============================================================
# Fixture: 获取登录 token
# 登录接口返回 {"code":"SUCCESS","data":"<JWT>"}
# ============================================================
@pytest.fixture(scope="session")
def zhangsan_token():
resp = requests.post(LOGIN_URL, data={"username": "zhangsan", "password": "123456"}, timeout=TIMEOUT)
return resp.json()["data"]
@pytest.fixture(scope="session")
def lisi_token():
resp = requests.post(LOGIN_URL, data={"username": "lisi", "password": "123456"}, timeout=TIMEOUT)
return resp.json()["data"]
# ============================================================
# 工具函数
# ============================================================
def send_get_list(token=None):
"""发送 GET /blog/getList;token 为 None 时不设置请求头"""
headers = {}
if token is not None:
headers["user_token_header"] = token
return requests.get(BLOG_LIST_URL, headers=headers, timeout=TIMEOUT)
def send_get_list_raw(token_value):
"""使用 urllib 发送请求,绕过 requests 对 header 值的合法性校验
用于测试含空格等特殊字符的 token 场景"""
req = Request(BLOG_LIST_URL)
req.add_header("user_token_header", token_value)
try:
resp = urlopen(req, timeout=TIMEOUT)
return resp.status, resp.read().decode()
except HTTPError as e:
return e.code, e.read().decode() if e.fp else ""
def assert_success(resp):
"""断言请求成功:200 + code=="SUCCESS" + data 为数组"""
assert resp.status_code == 200, f"状态码期望200, 实际{resp.status_code}"
body = resp.json()
assert body.get("code") == "SUCCESS", f"code期望SUCCESS, 实际{body.get('code')}, 响应: {body}"
assert isinstance(body.get("data"), list), f"data期望list, 实际{type(body.get('data'))}, 响应: {body}"
def assert_unauthorized(resp):
"""断言未授权:401"""
assert resp.status_code == 401, f"状态码期望401, 实际{resp.status_code}"
def assert_unauthorized_raw(status_code, body_text):
"""断言未授权(urllib 版本):401"""
assert status_code == 401, f"状态码期望401, 实际{status_code}, 响应: {body_text[:200]}"
# ============================================================
# P0-1 正常请求
# 使用有效 token 请求博客列表,应返回 200 + SUCCESS + data 数组
# ============================================================
@pytest.mark.parametrize("user,token_fixture", [
("zhangsan", "zhangsan_token"),
("lisi", "lisi_token"),
], ids=["zhangsan请求列表", "lisi请求列表"])
def test_normal_get_list(server_reachable, request, user, token_fixture):
token = request.getfixturevalue(token_fixture)
resp = send_get_list(token)
assert_success(resp)
# ============================================================
# P0-2 Token 异常
# 无 token / 空 token / 无效 token / 篡改 token → 均应返回 401
# ============================================================
@pytest.mark.parametrize("token,desc", [
(None, "不传token"),
("", "token为空字符串"),
("invalid_token", "token为无效字符串"),
], ids=["不传token", "token为空字符串", "token为无效字符串"])
def test_invalid_token(server_reachable, token, desc):
resp = send_get_list(token)
assert_unauthorized(resp)
def test_token_with_leading_spaces(server_reachable):
"""token 为纯空格,requests 库会拒绝该 header,使用 urllib 绕过校验"""
status_code, body_text = send_get_list_raw(" ")
assert_unauthorized_raw(status_code, body_text)
def test_tampered_token(server_reachable, zhangsan_token):
"""篡改 token 末尾一个字符,应返回 401"""
tampered = zhangsan_token[:-1] + ("0" if zhangsan_token[-1] != "0" else "1")
resp = send_get_list(tampered)
assert_unauthorized(resp)
def test_token_with_spaces_around(server_reachable, zhangsan_token):
"""token 前后加空格,requests 库会拒绝该 header,使用 urllib 绕过校验"""
status_code, body_text = send_get_list_raw(f" {zhangsan_token} ")
assert_unauthorized_raw(status_code, body_text)
# ============================================================
# P0-3 响应数据结构验证
# 验证 data 为数组,且数组元素包含全部必填字段
# ============================================================
def test_data_is_list(server_reachable, zhangsan_token):
"""data 应为 list 类型"""
resp = send_get_list(zhangsan_token)
assert_success(resp)
data = resp.json()["data"]
assert isinstance(data, list), f"data期望list, 实际{type(data)}"
def test_data_item_fields(server_reachable, zhangsan_token):
"""数组中每条博客应包含全部必填字段"""
resp = send_get_list(zhangsan_token)
assert_success(resp)
data = resp.json()["data"]
if len(data) == 0:
pytest.skip("博客列表为空,无法验证字段")
for item in data:
missing = [f for f in BLOG_REQUIRED_FIELDS if f not in item]
assert missing == [], f"缺少字段: {missing}, 实际字段: {list(item.keys())}"
# ============================================================
# P0-4 安全测试
# SQL 注入 / XSS / 超长 token 作为请求头 → 均应返回 401
# ============================================================
@pytest.mark.parametrize("token,desc", [
("' OR 1=1 --", "SQL注入作为token"),
("<script>alert(1)</script>", "XSS作为token"),
("a" * 500, "超长token500字符"),
], ids=["SQL注入作为token", "XSS作为token", "超长token"])
def test_security_token(server_reachable, token, desc):
resp = send_get_list(token)
assert_unauthorized(resp)
# ============================================================
# P0-5 HTTP 方法测试
# 实测: POST 方法也能返回 200 → 接口未做方法限制,属于 BUG
# ============================================================
def test_post_method(server_reachable, zhangsan_token):
"""预期: POST 方法应被拒绝(405);实测: 返回 200 → 接口未限制 HTTP 方法"""
headers = {"user_token_header": zhangsan_token}
resp = requests.post(BLOG_LIST_URL, headers=headers, timeout=TIMEOUT)
assert resp.status_code == 405, (
f"POST方法应返回405, 实际返回{resp.status_code} → BUG: 接口未限制HTTP方法"
)
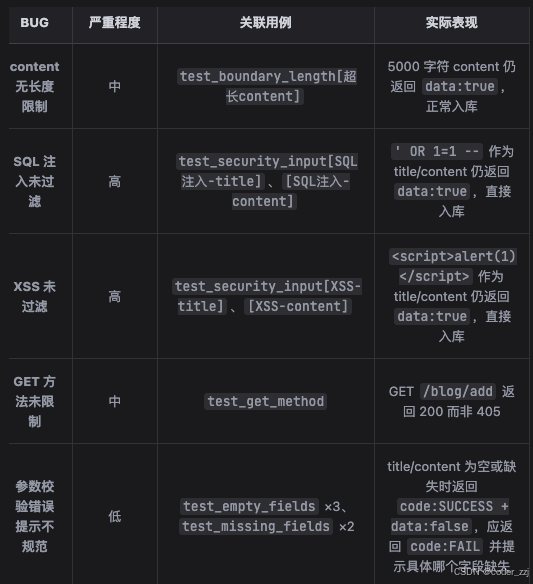
通过测试, trae 发现了两个bug
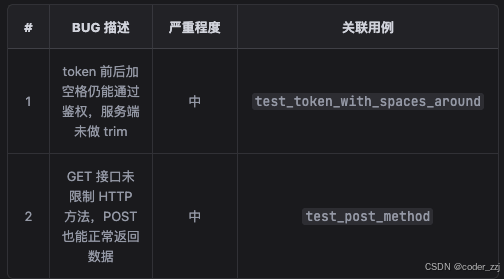

如果不看代码看结果的话,结果没问题

这是我们可以把常见的错误给它,让其自测代码是否存在问题:
自测一下实现代码中有没有存在一下问题:博客系统在编码阶段未区分⼤⼩写;token过⻓响应码为400;错误的HTTP⽅法响应码为200
发现只有一个问题:错误的请求路径居然返回了 401,401 应该是 token 错误,没有权限才会返回的,所以这里有点问题
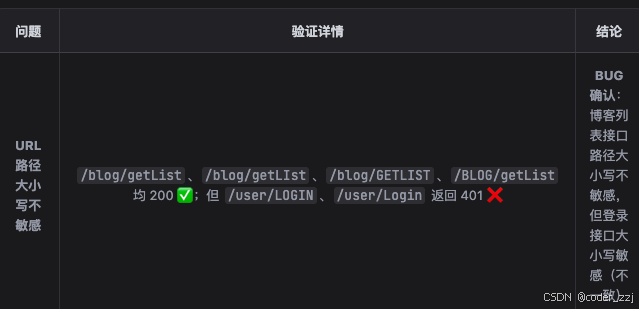
它的解决思路:添加了路径大小写场景的三个用例(运行之后都是 fail,说明后端设计这块接口有点问题,需要提单让开发改)
添加博客接口:
http://192.168.160.203:9090/blog/add 看看这个接口的返回值,与上一个一样要添加上登录返回的 data 作为user_token_header作为参数去请求,还有请求参数:{ "title" : "1111" , "content" : "## 在这⾥写下⼀篇博客 " }
import pytest
import requests
BASE_URL = "http://192.168.160.203:9090"
LOGIN_URL = f"{BASE_URL}/user/login"
BLOG_ADD_URL = f"{BASE_URL}/blog/add"
TIMEOUT = 5
DEFAULT_TITLE = "测试博客标题"
DEFAULT_CONTENT = "## 在这里写下一篇博客"
# ============================================================
# Fixture: 服务器连通性预检
# ============================================================
@pytest.fixture(scope="session")
def server_reachable():
try:
requests.post(BLOG_ADD_URL, timeout=TIMEOUT)
return True
except requests.exceptions.ConnectionError:
pytest.skip("服务器不可达,跳过所有测试")
except requests.exceptions.Timeout:
pytest.skip("服务器连接超时,跳过所有测试")
except Exception:
return True
# ============================================================
# Fixture: 获取登录 token(登录接口返回 {"code":"SUCCESS","data":"<JWT>"})
# ============================================================
@pytest.fixture(scope="session")
def zhangsan_token():
resp = requests.post(LOGIN_URL, data={"username": "zhangsan", "password": "123456"}, timeout=TIMEOUT)
return resp.json()["data"]
@pytest.fixture(scope="session")
def lisi_token():
resp = requests.post(LOGIN_URL, data={"username": "lisi", "password": "123456"}, timeout=TIMEOUT)
return resp.json()["data"]
# ============================================================
# 工具函数
# ============================================================
def send_add_blog(token=None, title=DEFAULT_TITLE, content=DEFAULT_CONTENT):
"""发送 POST /blog/add,token 为 None 时不设置 user_token_header"""
headers = {"Content-Type": "application/json"}
if token is not None:
headers["user_token_header"] = token
body = {"title": title, "content": content}
return requests.post(BLOG_ADD_URL, headers=headers, json=body, timeout=TIMEOUT)
def assert_success(resp):
"""断言添加成功:200 + code=="SUCCESS" + data==true"""
assert resp.status_code == 200, f"状态码期望200, 实际{resp.status_code}"
body = resp.json()
assert body.get("code") == "SUCCESS", f"code期望SUCCESS, 实际{body.get('code')}, 响应: {body}"
assert body.get("data") is True, f"data期望true, 实际{body.get('data')}, 响应: {body}"
def assert_rejected(resp):
"""断言参数被拒绝:200 + code=="SUCCESS" + data==false
接口对非法参数不返回 FAIL,而是 SUCCESS+data:false → 属于设计缺陷"""
assert resp.status_code == 200, f"状态码期望200, 实际{resp.status_code}"
body = resp.json()
assert body.get("code") == "SUCCESS", f"code期望SUCCESS, 实际{body.get('code')}, 响应: {body}"
assert body.get("data") is False, f"data期望false, 实际{body.get('data')}, 响应: {body}"
def assert_unauthorized(resp):
"""断言未授权:401"""
assert resp.status_code == 401, f"状态码期望401, 实际{resp.status_code}"
def assert_server_error(resp):
"""断言服务端错误:200 + code=="FAIL" + "内部错误"(如 form 格式、GET 方法等)"""
assert resp.status_code == 200, f"状态码期望200, 实际{resp.status_code}"
body = resp.json()
assert body.get("code") == "FAIL", f"code期望FAIL, 实际{body.get('code')}, 响应: {body}"
# ============================================================
# P0-1 正常添加博客
# 有效 token + 合法 title/content → SUCCESS + data:true
# ============================================================
@pytest.mark.parametrize("user,token_fixture", [
("zhangsan", "zhangsan_token"),
("lisi", "lisi_token"),
], ids=["zhangsan添加博客", "lisi添加博客"])
def test_normal_add_blog(server_reachable, request, user, token_fixture):
token = request.getfixturevalue(token_fixture)
resp = send_add_blog(token)
assert_success(resp)
# ============================================================
# P0-2 Token 异常
# 无 token / 错误 token / 空 token → 401
# ============================================================
@pytest.mark.parametrize("token,desc", [
(None, "不传token"),
("", "token为空字符串"),
("invalid_token", "无效token"),
], ids=["不传token", "token为空字符串", "无效token"])
def test_invalid_token(server_reachable, token, desc):
resp = send_add_blog(token=token)
assert_unauthorized(resp)
# ============================================================
# P0-3 参数校验
# title/content 为空或缺失 → 接口返回 SUCCESS+data:false
# 预期: 应返回 FAIL 并提示具体错误字段 → BUG: 错误提示不规范
# ============================================================
@pytest.mark.parametrize("title,content,desc", [
("", DEFAULT_CONTENT, "title为空"),
(DEFAULT_TITLE, "", "content为空"),
("", "", "title和content都为空"),
], ids=["title为空", "content为空", "title和content都为空"])
def test_empty_fields(server_reachable, zhangsan_token, title, content, desc):
resp = send_add_blog(zhangsan_token, title=title, content=content)
assert_rejected(resp)
@pytest.mark.parametrize("body,desc", [
({"content": DEFAULT_CONTENT}, "缺少title字段"),
({"title": DEFAULT_TITLE}, "缺少content字段"),
], ids=["缺少title字段", "缺少content字段"])
def test_missing_fields(server_reachable, zhangsan_token, body, desc):
headers = {"user_token_header": zhangsan_token, "Content-Type": "application/json"}
resp = requests.post(BLOG_ADD_URL, headers=headers, json=body, timeout=TIMEOUT)
assert_rejected(resp)
# ============================================================
# P0-4 边界值测试
# 超长 title → data:false(被拒绝)
# 超长 content → data:true(被接受)→ BUG: content 无长度限制
# ============================================================
@pytest.mark.parametrize("title,content,expect_fn,desc", [
("测" * 250, DEFAULT_CONTENT, assert_rejected, "超长title(500字符)"),
(DEFAULT_TITLE, "内" * 2500, assert_rejected, "超长content(5000字符)"),
], ids=["超长title", "超长content"])
def test_boundary_length(server_reachable, zhangsan_token, title, content, expect_fn, desc):
"""超长 content 实测返回 data:true → BUG: 无长度限制"""
resp = send_add_blog(zhangsan_token, title=title, content=content)
expect_fn(resp)
# ============================================================
# P0-5 安全测试
# SQL 注入 / XSS → 实测: data:true → BUG: 未过滤危险输入
# ============================================================
@pytest.mark.parametrize("title,content,desc", [
("' OR 1=1 --", DEFAULT_CONTENT, "SQL注入-title"),
("<script>alert(1)</script>", DEFAULT_CONTENT, "XSS-title"),
(DEFAULT_TITLE, "' OR '1'='1", "SQL注入-content"),
(DEFAULT_TITLE, "<img onerror=alert(1) src=x>", "XSS-content"),
], ids=["SQL注入-title", "XSS-title", "SQL注入-content", "XSS-content"])
def test_security_input(server_reachable, zhangsan_token, title, content, desc):
"""预期: 危险输入应被拒绝;实测: data:true → BUG: 未过滤危险输入"""
resp = send_add_blog(zhangsan_token, title=title, content=content)
assert_rejected(resp)
# ============================================================
# P0-6 HTTP 方法测试
# GET /blog/add → 实测: 200 + FAIL + "内部错误" → BUG: 应返回 405
# ============================================================
def test_get_method(server_reachable, zhangsan_token):
"""预期: GET 应返回 405;实测: 返回 200 → BUG: 未限制 HTTP 方法"""
headers = {"user_token_header": zhangsan_token}
resp = requests.get(BLOG_ADD_URL, headers=headers, timeout=TIMEOUT)
assert resp.status_code == 405, (
f"GET方法应返回405, 实际返回{resp.status_code} → BUG: 未限制HTTP方法"
)
# ============================================================
# P0-7 Content-Type 测试
# form 格式提交 → 接口返回 FAIL + "内部错误",错误提示不友好
# ============================================================
def test_form_content_type(server_reachable, zhangsan_token):
"""使用 form 格式提交,接口应返回 415 或明确提示;实测返回'内部错误'"""
headers = {"user_token_header": zhangsan_token}
resp = requests.post(BLOG_ADD_URL, headers=headers, data={"title": "测试", "content": "内容"}, timeout=TIMEOUT)
assert_server_error(resp)

既然获取博客和添加博客接口的前提要先请求一遍登录接口,返回的 data 作为参数来使用,那就可以把这段逻辑进行封装,就不要写两遍了;这种我们也让 AI 帮助我们来进行优化
先登录后再使用获取博客接口或者添加博客接口这里是否可以继续优化
# conftest.py
import pytest
import requests
BASE_URL = "http://192.168.160.203:9090"
LOGIN_URL = f"{BASE_URL}/user/login"
TIMEOUT = 5
@pytest.fixture(scope="session")
def server_reachable():
try:
requests.post(LOGIN_URL, data={"username": "test", "password": "test"}, timeout=TIMEOUT)
return True
except requests.exceptions.ConnectionError:
pytest.skip("服务器不可达,跳过所有测试")
except requests.exceptions.Timeout:
pytest.skip("服务器连接超时,跳过所有测试")
except Exception:
return True
@pytest.fixture(scope="session")
def zhangsan_token(server_reachable):
resp = requests.post(LOGIN_URL, data={"username": "zhangsan", "password": "123456"}, timeout=TIMEOUT)
return resp.json()["data"]
@pytest.fixture(scope="session")
def lisi_token(server_reachable):
resp = requests.post(LOGIN_URL, data={"username": "lisi", "password": "123456"}, timeout=TIMEOUT)
return resp.json()["data"]AI实现接⼝⾃动化实战
由于 trae 无法上传文件生成测试用例,这个任务让 codex 来完成
博客系统接⼝⽂档 博客系统接⼝测试⽤例模板(这是待上传的两个文件)针对博客系统接⼝⽂档中涉及到的所有接⼝,分别设计接⼝测试⽤例要求:1 )⽤例需覆盖:正常场景、参数缺失、参数异常(类型 / ⻓度 / 格式)、边界值等,按照测试的优先级将每个接⼝对应测试⽤例的数量控制在 10 个以内2 )输出格式:完全按照博客系统接⼝测试⽤例模板⽂档中的格式来输出测试⽤例,保存在 “ 接⼝测试⽤例.md” ⽂件中
根据接⼝测试⽤例 .md ⽂件内容,生成接⼝⾃动化⽬录使用md文件创建并保存技术栈要求:1. 编程语⾔: Python2. 测试框架: pytest3. HTTP 库: requests4. 数据驱动: YAML5. 报告: Allure6. 接⼝返回值断⾔: jsonschema7. logging ⽇志记录:⽇志分级输出,按天分割其他设计要求:1. 其他接⼝需要在请求头添加有效 token ,但是 token 值来⾃于登录接⼝的返回值 data2. 其他接⼝中有效的 blogId 取⾃列表⻚接口 getList 的有效返回值 id
根据以上生成的两个文档和接口设计文档,严格按照要求⽣成接⼝⾃动化测试
生成的代码运行 pytest ,执行一遍没问题后,自己阅读一遍(如果不知道怎么阅读,可以让它生成一份 READMI.md 文件来帮我们按照文件顺序阅读),阅读后发现:登录获取的 token 如果过期了的,要重新获取 token 的逻辑没有实现:描述清楚提示词,叫 AI 自己补上
自测下看看生成的代码有没有以下问题:缺少参数;找不到fixture;中英⽂标点符号识别问题;yaml⽂件中不合理格式导致代码报错
postman-mcp-server
MCP,即模型上下⽂协议Model Context Protocol (MCP),是当前AI领域的热⻔概念。MCP 是⼀种开放标准和协议,旨在规范⼈⼯智能模型(如 ChatGPT) 与外部数据源、⼯具和系统之间的通信⽅式。 简单来说,可以把 MCP 理解成 “⼤模型和外部世界交流的翻译官”。⼤模型(像 GPT 这种)本⾝只 会根据输⼊⽂字来回答问题。但是如果我们希望模型能去“⼲活”,⽐如: 查数据库,打开一个网站等等;而Postman MCP Server 是⼀个MCP 服务器,它与 Postman API 集成,提供对 Postman 集合(collections)、环境(environments) 和 API 的全⾯管理。
这里使用 postman mcp来举例子:前提:下载了postman 和 vibecodeing(这里选择 trae)
首先按照 npm,它是管理 node.js 的工具 https://nodejs.org/en/download,选择 v20 左右的版本稳定点;下载完成后一直点击继续完完成安装,之后在终端查看版本看是否安装成功
安装pnpm(macos 为例):sudo corepack enable 验证安装:pnpm -v

下载postman-mcp-server源码: git clone https://github.com/delano/postman-mcp-server.git

进入下载完成的命令:cd postman-mcp-server
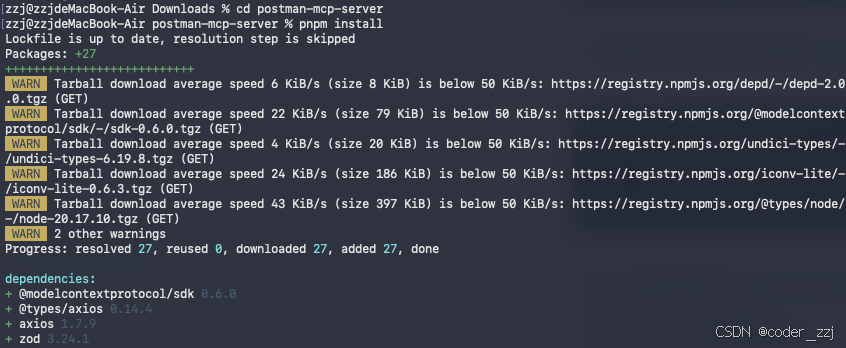
安装依赖: pnpm install
构建服务器:pnpm run build
trae 配置 MCP
Postman 生成 API Key
链接:https://web.postman.co/settings/me/api-keys
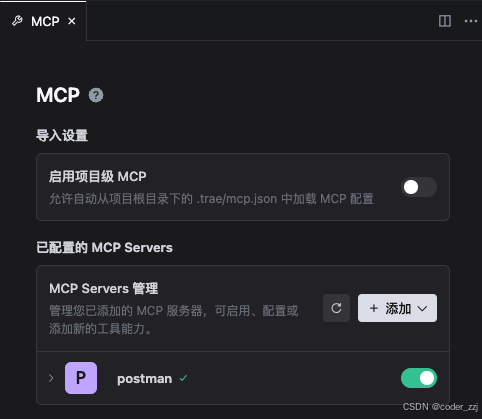
在 trae 中设置找不到 mcp 进行配置
{
"mcpServers": {
"postman": {
"command": "node",
"args": [
# 具体路径
"XXX/postman-mcp-server/build/index.js"
],
"env": {
# postman 创建好的 api key
"POSTMAN_API_KEY": "Wirte API Key"
}
}
}
}
配置完成之后,就可以拿着以下提示词试试(使用 minimax 2.7)
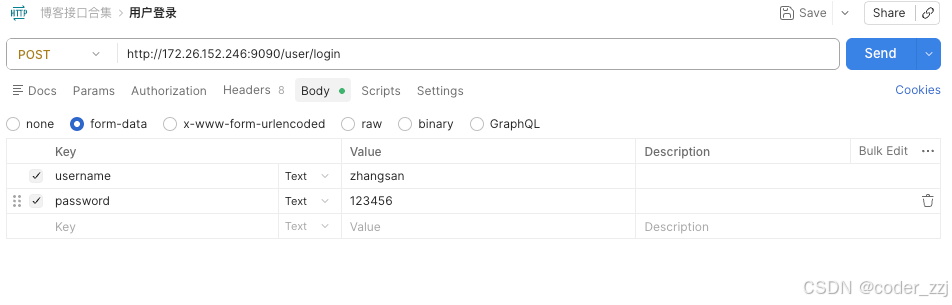
使⽤postman MCP执⾏以下操作
接⼝信息:
POST http://172.26.152.246:9090//user/login
form-data:
username=zhangsan
password=123456
返回值
{
"code": "SUCCESS",
"errMsg": "",
"data": "有效JWT"
}
可以创建出接口来,但是无法自动添加 body,需要手动添加(curosr 就能实现自动化这点就好一些)
使⽤ postman MCP 将以下接⼝添加到博客系统接⼝集合中接⼝信息:GET http://172.26.152.246:9090 /blog/getList请求头user_token_header:有效 JWT使⽤环境变量来统⼀管理博客系统URL:http://172.26.152.246:9090
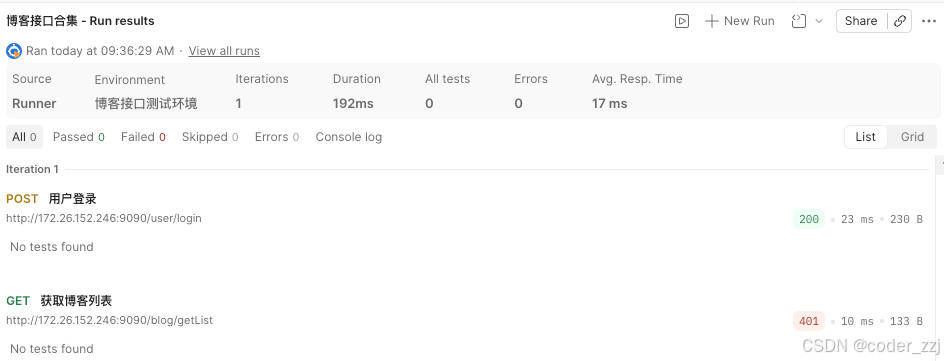
使⽤postman MCP处理以下操作:
处理博客系统测试环境,JWT_TOKEN变量的数据为登录接⼝的返回值data字段
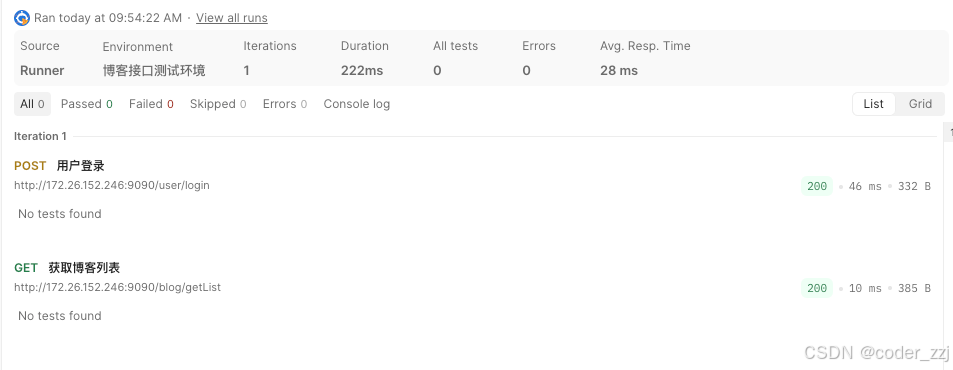
/user/login接⼝返回值添加断⾔, { "code": "SUCCESS", "errMsg": "", "data":"有效JWT" } 返回值必须包含以上三个字段 code和errMsg必须满⾜以上返回值,data返回值不能为空 状态码必须为200
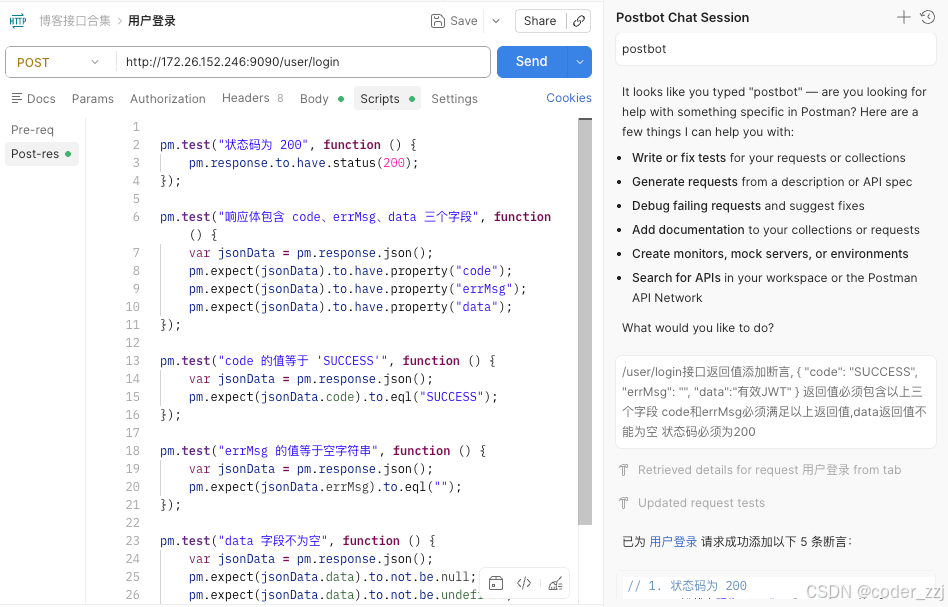

AI实现WebUI自动化
既然接口自动化可以使用AI赋能实现,那么WebUI也是同样可以的(使用python的seleium库来实现)(这里用的 codex 生成,trae 检查并运行)
登录页

根据图⽚提供的登陆界⾯设计UI⾃动化测试⽤例,⻚⾯包含标题、导航栏和登陆表单模块要求:
1)⽤例包含登陆功能(正常、异常)、导航栏的跳转、标题的验证
2)按照优先级设计⽤例数量在10以内
3)输出格式:⽤例名称、操作步骤,预期结果。内容具体,避免模糊的描述⽅式
4)将输出内容保存⾄“登录⻚⾯测试⽤例.md”⽂件中

正确账号zhangsan 密码 123456 将文登录页面测试用例.md进行优化
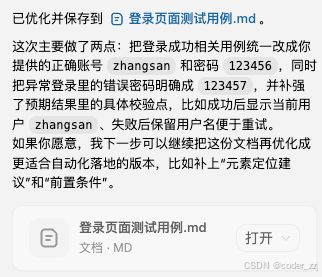
读取登录⻚⾯测试⽤例 .md ⽂档内容并⽣成测试脚本,要求:1 )使⽤ Python+selenium 实现⾃动化脚本编写2 )⽤例遵循 pytest 框架运⾏规则3 )测试⽅法命名要合理4 )每个测试⽤例都要对结果进⾏断⾔5 )不使⽤复杂设计模式6 )完全遵循以上要求,不要做额外拓展
由于AI实现的web驱动是,每次请求前根据浏览器版本进行安装,这固然是好事,但是每次范围是会很卡,问问AI:
分析下生成的代码,为什么启动谷歌浏览器时会很慢?
由于现在使用的谷歌,每次安装会很慢所以AI在本地下载一个驱动每次直接根据路径找就行
根据博客登录页的html文件,优化生成的脚本代码
接着让AI通过截图的方式,让我可以直白观察到结果
每次用例的结果截图保存在以日期目录中
但是截图内容我还要把登录失败的各种提示弹窗一同显示在截图中
现在代码截图功能实现了,但是没能截图到登录失败的提示词弹窗,帮忙优化一下(这个trae的minimax解决不了,使用 codex 才解决了)
首页

根据图⽚提供的列表界⾯设计UI ⾃动化测试⽤例,⻚⾯包含个⼈信息(头像、 GitHub 地址、⽂章、分 类)、导航栏(主⻚、写博客、注销)和博客列表(⾄少包含⼀条博客,每条博客包含标题、发布时 间、博客内容、查看全⽂按钮)要求:1 )⽤例包含博客列表信息、个⼈信息的验证2 )按照优先级设计⽤例数量在 10 以内3 )输出格式:⽤例名称、操作步骤,预期结果。内容具体,避免模糊的描述⽅式5 )将输出内容保存⾄ “ 列表⻚⾯测试⽤例 .md” ⽂件中
读取列表⻚⾯测试⽤例.md内容和⻚⾯源码博客列表页⽂件,⽣成列表⻚测试脚本,要求:
1)使⽤Python+selenium实现⾃动化脚本编写
2)⽤例遵循pytest框架运⾏规则
3)测试⽅法命名要合理
4)每个测试⽤例都要对结果进⾏断⾔
5)不使⽤复杂设计模式
6)完全遵循以上要求,不要做额外拓展
7) 加上适量注释方便阅读
但这次生成出来的代码不能直接执行,需要先执行登录代码再执行,之前使用的 pytest-order来实现,这次让AI来实现
使⽤pytest-order插件指定类的执⾏顺序,顺序依次为:test_login_page.py、test_blog_list_page.py
AI生成的代码,每运⾏⼀个⽤例都需要重新创建driver对象启动浏览器,这样做会导致: 登录态不会被保存,导致列表⻚⽤例执⾏失败;⼤量重复的操作导致⽤例执⾏时间太⻓,解决:一般使⽤pytest中的conftest.py操作将类中定义的fixture标记⽅法管理起来,并重新修改作⽤域;也让AI来进行优化
背景:登录成功后才能访问列表⻚,否则会⾃动跳转⾄登录⻚,导致列表⻚测试⽤例全部执⾏失败重新优化代码设计,要求:1 )提取测试⽂件中的启动和关闭浏览器操作,封装为 fixture 标记的⽅法,使得所有⽤例执⾏前启动⼀次浏览器,执⾏结束后关闭⼀次浏览器2 )执⾏列表⻚每个测试⽤例之前需要保证已经存在登录态3 )不改变每个测试⽤例的逻辑4 )不要做过多拓展

根据图片和提供的博客详情和编辑页的html⽂件,设计各个⻚⾯的UI⾃动化测试⽤例,为后续的编写UI⾃动化测试脚本做准
备,要求:
1)包含功能和界⾯等⽅⾯来设计
2)按照优先级,每个⻚⾯设计⽤例数量在10以内
3)输出格式:按照博客系统测试⽤例模板.md格式输出,内容具体,避免模糊的描述⽅式
4)将输出内容保存成md⽂件保存在当前路径下
读取列表⻚⾯测试⽤例.md内容和⻚⾯源码博客列表页⽂件,⽣成列表⻚测试脚本,要求:
1)使⽤Python+selenium实现⾃动化脚本编写
2)⽤例遵循pytest框架运⾏规则
3)测试⽅法命名要合理
4)每个测试⽤例都要对结果进⾏断⾔
5)不使⽤复杂设计模式
6)完全遵循以上要求,不要做额外拓展
7) 加上适量注释方便阅读
生成后发现:在没有登录态的状态下直接拿着 url 去访问会有警告弹窗出现,这是不符合预期的,需要先登录才能进行一下测试
修改博客详情和编辑逻辑,需要先登录成功后才能进行后续博客的各种操作
此时执行到博客编辑和博客详情页时,停在登录页面不动了,原因时实现的代码中没有先登录的逻辑,让AI给我们补充上
生成的博客编辑和博客详情页时没有在登录态下进行,在代码中补充这一逻辑
还有执行顺序问题
运行所有脚本时,按照一下顺序执行:登录 -> 博客列表 -> 博客详情 -> 博客编辑
执行顺序解决完了,前提是你还要保证至少有一遍博客才能进行博客列表测试;最后查看当前失败的用例,让ai分析失败原因和解决方法进行解决(高级模型可以做到一步到位解决)

AtomGit AI 社区提供模型库、数据集、Agent、Token等资源
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)