
[VL|RIS] CRIS: CLIP-Driven Referring Image Segmentation
本文主要介绍了一种新的基于CLIP模型的指代图像分割方法,称为CRIS。该方法通过视觉语言解码和对比学习来实现文本和像素级特征之间的对齐,以提高跨模态匹配的能力。作者在三个基准数据集上的实验证明了该方法的有效性。
1. BaseInfo
| Title | CRIS: CLIP-Driven Referring Image Segmentation |
| Adress | https://arxiv.org/pdf/2111.15174v2 |
| Journal/Time | CVPR 2022 |
| Author | 悉尼大学,OPPO,北邮,快手 |
| Code | https://github.com/DerrickWang005/CRIS.pytorch |
2. Creative Q&A
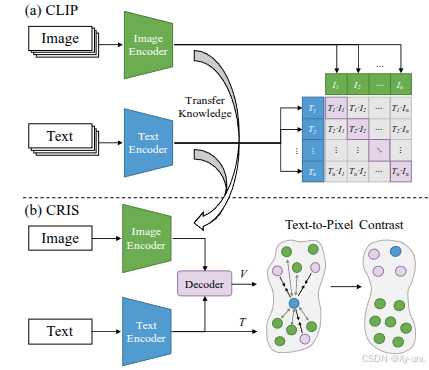
- 受到CLIP的启发,设计了一个visual-language decoder以促进两种模态之间的一致性。直接对齐->注意力-> 模态一致性
- 文本到像素的对比学习。
Related Work : Vision-Language Pretraining、Contrastive Learning、Referring Image Segmentation
3. Concrete
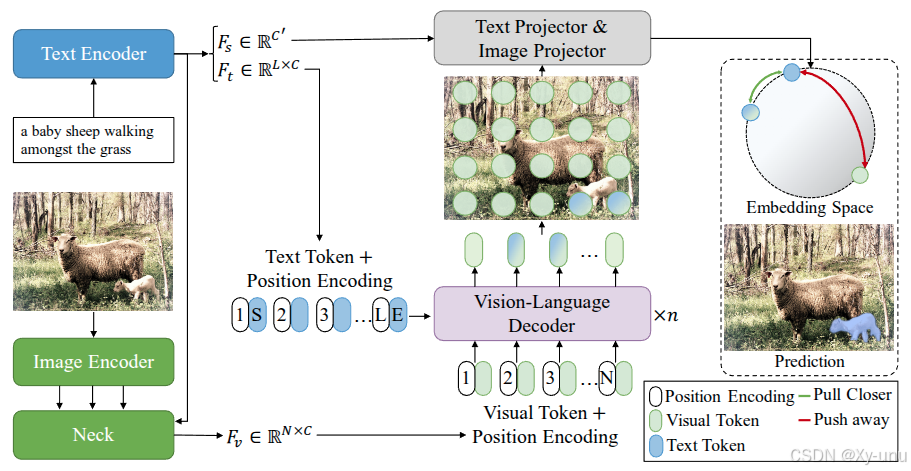
3.1. Model
3.1.1. Input
图+文
3.1.2. Backbone
ResNet + Transformer (提取语言特征和全局文本表示)
3.1.3. Neck
Cross-modal Neck.
给定多个视觉特征和全局文本表示FsF_sFs,可以通过融合Fv4F_{v4}Fv4以及FsF_sFs得到简单的多模态特征
Fm4=Up(σ(Fv4Wv4)⋅σ(FsWs))(1) F_{m4} = Up(\sigma(F_{v4}W_{v4}) \cdot \sigma(F_{s}W_{s})) \tag{1} Fm4=Up(σ(Fv4Wv4)⋅σ(FsWs))(1)
其中UpUpUp是上采样两倍,将两个模态的特征变换到同一个特征空间,类似得到 Fm3F_{m3}Fm3和Fm2F_{m2}Fm2。
Fm3=[σ(Fm4Wm4),σ(Fv3Wv3)]Fm2=[σ(Fm3Wm3),σ(Fv2′Wv2)],Fv2′=Avg(Fv2) \begin{align} F_{m3} &= [\sigma(F_{m4}W_{m4}), \sigma(F_{v3}W_{v3})] \\ F_{m2} &= [\sigma(F_{m3}W_{m3}), \sigma(F_{v2}'W_{v2})], F_{v2}' = Avg(F_{v2}) \tag{2} \end{align} Fm3Fm2=[σ(Fm4Wm4),σ(Fv3Wv3)]=[σ(Fm3Wm3),σ(Fv2′Wv2)],Fv2′=Avg(Fv2)(2)
拼接后的特征通过1×11 \times 11×1卷积进行聚合得到FmF_{m}Fm:
Fm=Conv([Fm2,Fm3,Fm4])(3) F_{m} = Conv([F_{m2}, F_{m3}, F_{m4}]) \tag{3} Fm=Conv([Fm2,Fm3,Fm4])(3)
其中Fm∈RH8×W8×CF_{m} \in \mathbb{R}^{\frac{H}{8} \times \frac{W}{8} \times C}Fm∈R8H×8W×C。最后,作者将2D的空间坐标特征Fcoord∈RH8×W8×2F_{coord} \in \mathbb{R}^{\frac{H}{8} \times \frac{W}{8} \times 2}Fcoord∈R8H×8W×2与FmF_{m}Fm拼接并通过3×33 \times 33×3卷积进行融合:
Fv=Conv([Fm,Fcoord])(4) F_{v} = Conv([F_{m}, F_{coord}]) \tag{4} Fv=Conv([Fm,Fcoord])(4)
其中Fv∈RH8×W8×CF_{v} \in \mathbb{R}^{\frac{H}{8} \times \frac{W}{8} \times C}Fv∈R8H×8W×C。
3.1.4. Decoder
Vision-Language Decoder
vision-language decoder由n个layer组成,每个layer包括一个多头自注意力,一个多头交叉注意力以及前馈网络。
加上了正弦位置编码
Fv′=MHSA(LN(Fv))+Fv(5) F_{v}' = MHSA(LN(F_{v})) + F_{v} \tag{5} Fv′=MHSA(LN(Fv))+Fv(5)
Fc′=MHCA(LN(Fv′),Ft)+Fv′Fc=MLP(LN(Fc′))+Fc′ \begin{align} F_{c}' &= MHCA(LN(F_{v}'), F_{t}) + F_{v}' \tag{7}\\ F_{c} &= MLP(LN(F_{c}')) + F_{c}' \end{align} Fc′Fc=MHCA(LN(Fv′),Ft)+Fv′=MLP(LN(Fc′))+Fc′(7)
3.1.5. Loss
Text-to-Pixel Contrastive Learning
zv=Fc′Wv+bv,Fc′=Up(Fc)zt=FsWt+bt \begin{align} z_{v} &= F_{c}'W_{v} + b_{v}, &F_{c}' = Up(F_{c}) \\ z_{t} &= F_{s}W_{t} + b_{t} & \tag{8} \end{align} zvzt=Fc′Wv+bv,=FsWt+btFc′=Up(Fc)(8)
其中 zt∈RDz_{t} \in \mathbb{R}^{D}zt∈RD, zv∈RN×Dz_{v} \in \mathbb{R}^{N \times D}zv∈RN×D, N=H4×W4N = \frac{H}{4} \times \frac{W}{4}N=4H×4W。
目的是让 ztz_{t}zt 和与之对应的 zvz_{v}zv 尽可能相似:
Lconi(zt,zvi)={−logσ(zt⋅zvi),i∈P−log(1−σ(zt⋅zvi)),i∈N(9) L_{con}^{i}(z_{t}, z_{v}^{i}) = \begin{cases} -\log \sigma(z_{t} \cdot z_{v}^{i}), &i \in \mathcal{P} \\ -\log(1 - \sigma(z_{t} \cdot z_{v}^{i})), &i \in \mathcal{N} \end{cases} \tag{9} Lconi(zt,zvi)={−logσ(zt⋅zvi),−log(1−σ(zt⋅zvi)),i∈Pi∈N(9)
Loss 计算
Lcon(zt,zv)=1∣P∪N∣∑i∈P∪NLconi(zt,zvi)(10) L_{con}(z_{t}, z_{v}) = \frac{1}{|\mathcal{P} \cup \mathcal{N}|} \sum_{i \in \mathcal{P} \cup \mathcal{N}} L_{con}^{i}(z_{t}, z_{v}^{i}) \tag{10} Lcon(zt,zv)=∣P∪N∣1i∈P∪N∑Lconi(zt,zvi)(10)
3.2. Training
| 名称 | 值 |
|---|---|
| 文本和图像编码器权重 | 使用CLIP |
| 用于消融研究的图像编码器 | ResNet - 50 |
| 输入图像调整后的尺寸 | 416×416 |
| RefCOCO和RefCOCO+输入句子的最大长度 | 17 |
| G - Ref输入句子的最大长度 | 22 |
| Transformer Decoder层的头数 | 8 |
| 前馈隐藏层维度 | 2048 |
| 训练轮数 | 50 |
| 优化器 | Adam |
| 初始学习率 | 0.0001 |
| 第35轮时学习率调整因子 | 0.1(即学习率降为原来的0.1) |
| 训练的批量大小 | 64 |
| 推理时预测结果的上采样操作 | 上采样回原始图像大小 |
| 推理时的二值化阈值 | 0.35 |
| 推理时是否有其他后处理操作 | 无 |
3.2.1. Resource
8块显存为16GB的Tesla V100 GPU
3.2.2 Dataset
RefCOCO , RefCOCO+ , and G-Ref .
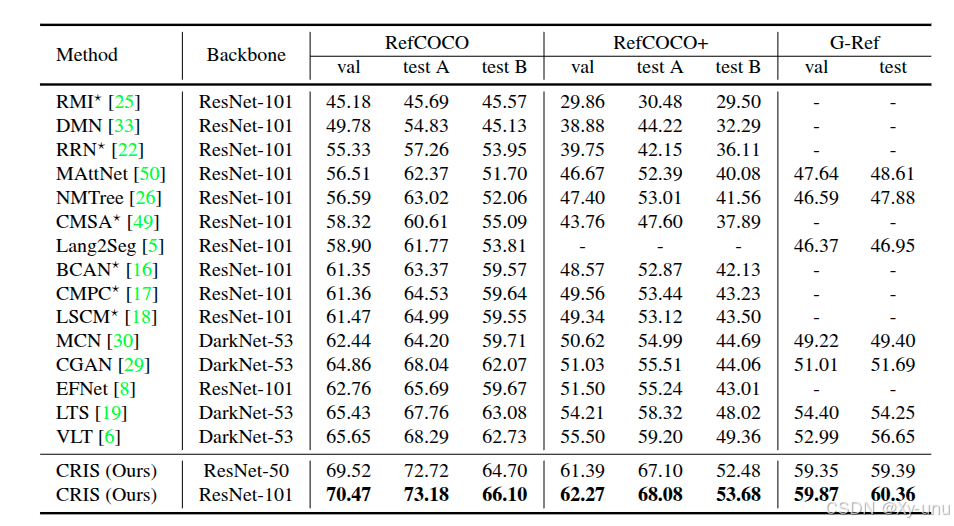
3.3. Eval
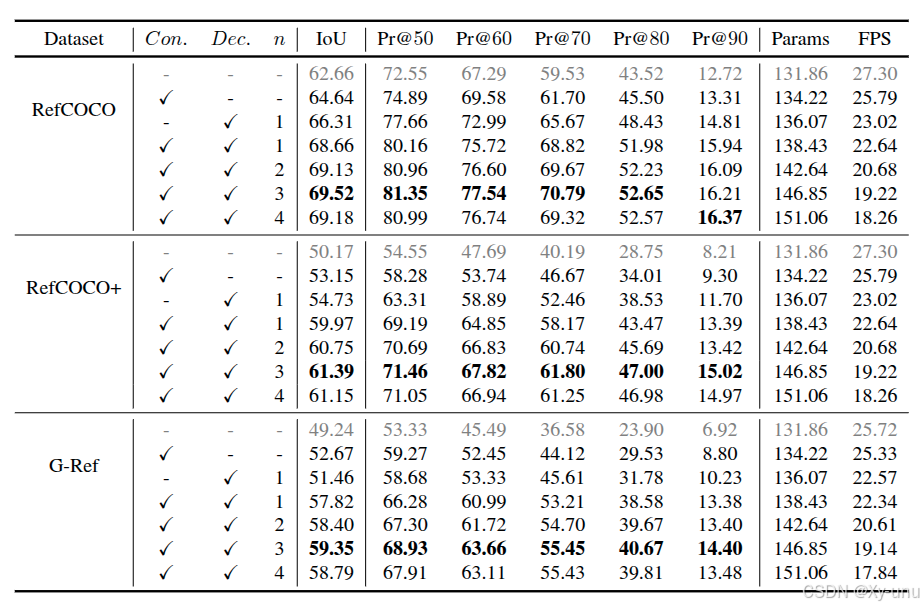
3.4. Ablation
- 解码器和对比学习的有效性
- Decoder 的 layers
比较有趣的是这些failure case。第一种导致failure的原因是输入的表达具有歧义,其次是标签标注问题,最后是遮挡问题。
4. Reference
5. Additional
很早的工作了,之前也读过,重新整理一下。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)