
AI云原生:数智化时代AI Agent加速落地的技术基石与实践指南(THS)
AI云原生:重构智能时代的计算范式 中国AI大模型市场预计2025年突破千亿规模,云原生成为AI基础设施的核心标准。本文解析其技术架构与实践路径: 核心价值:通过容器化、自动化和弹性伸缩,解决传统AI的数据孤岛、资源碎片化等问题,工程效率提升18倍; 技术支柱: 异构GPU池化(NVIDIA MIG/华为昇腾NPU) 高速存储(Fluid加速模型加载延迟降低至8ms) RDMA网络(0.8μs超低
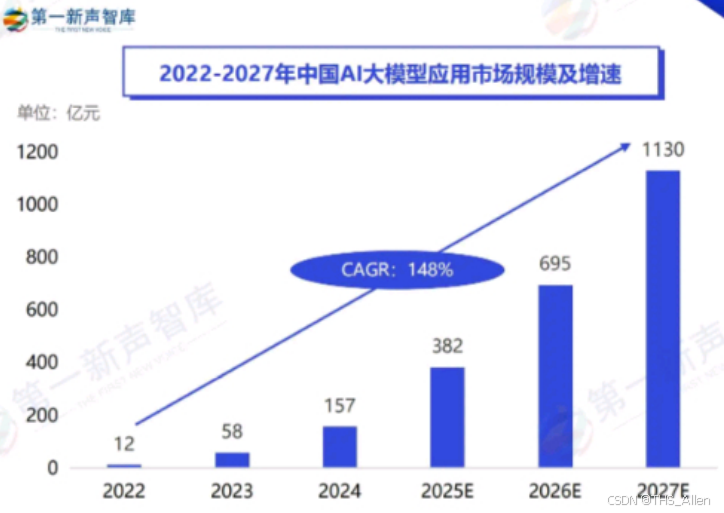
2025年中国AI大模型市场规模将突破1000亿元,年复合增长率达148%,云原生已成为AI基础设施的黄金标准。本文将深入解析AI云原生的技术架构、核心组件与行业实践,为开发者提供从理论到落地的完整指南。

一、为什么需要AI云原生?数智化时代的必然选择
1.1 市场驱动:AI应用爆发式增长
- 市场规模:2022年157亿 → 2027年1200亿(CAGR 148%)
- 企业渗透率:2025年90%头部企业深度集成AI,中小企业工具使用率提升31%
- 技术拐点:大模型参数量从GB级跃升至TB级,传统架构面临三大挑战:
- 百倍增长的token调用压力
- 推理成本居高不下(如千亿模型单次推理>¥0.5)
- Agent安全操作需求激增
1.2 云原生:AI基础设施的基因重构
核心价值公式:
AI生产力 = (算法创新 × 数据价值) / 工程熵
云原生通过三大杠杆降低工程熵:
- 标准化:容器封装消除环境差异
- 自动化:CI/CD流水线加速迭代
- 弹性化:资源按需伸缩应对流量峰值
典型案例:OpenAI ChatGPT依赖Kubernetes实现每秒百万级并发,推理延迟控制在800ms内
二、AI云原生技术架构:四大核心支柱
2.1 计算层:异构GPU算力池化
关键技术:Kubernetes Device Plugin机制
// GPU共享插件示例(NVIDIA gpu-share-plugin)
func main() {
plugin := &NvidiaDevicePlugin{
devices: getGPUs(),
socket: "/var/lib/kubelet/device-plugins/nvidia.sock",
allocFunc: allocateGPU,
}
plugin.Start() // 注册GPU资源到Kubelet
}
// K8s调度器通过Resource Claims分配GPU
apiVersion: v1
kind: Pod
spec:
containers:
- name: trainer
resources:
limits:
nvidia.com/gpu: 2 # 申请2个虚拟GPU切片
实现方案对比:
| 厂商 | 设备插件 | 核心能力 |
|---|---|---|
| NVIDIA | k8s-device-plugin | MIG切分、拓扑感知 |
| 华为昇腾 | ascend-device-plugin | NPU虚拟化、AI任务隔离 |
| 寒武纪 | mlucn-device-plugin | 支持MLU270芯片调度 |
2.2 存储层:TB级模型的高速加载
传统架构痛点:
- 模型加载耗时:TB级模型本地加载>30分钟
- 存储成本:本地SSD存储单价¥1.5/GB/月
云原生解决方案:Fluid数据抽象层
# Fluid数据集加速配置
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
name: imagenet
spec:
mounts:
- mountPoint: oss://bucket/imagenet
name: imagenet
accessModes: ["ReadOnlyMany"]
---
apiVersion: data.fluid.io/v1alpha1
kind: AlluxioRuntime
metadata:
name: imagenet
spec:
replicas: 3
tieredstore:
levels:
- mediumtype: MEM
path: /dev/shm
quota: 100Gi
性能提升:
| 场景 | 传统OSS直读 | Fluid加速 | 提升倍数 |
|---|---|---|---|
| 模型加载延迟 | 150ms | 8ms | 18.75x |
| 训练迭代速度 | 12 it/s | 48 it/s | 4x |
2.3 网络层:RDMA实现微秒级通信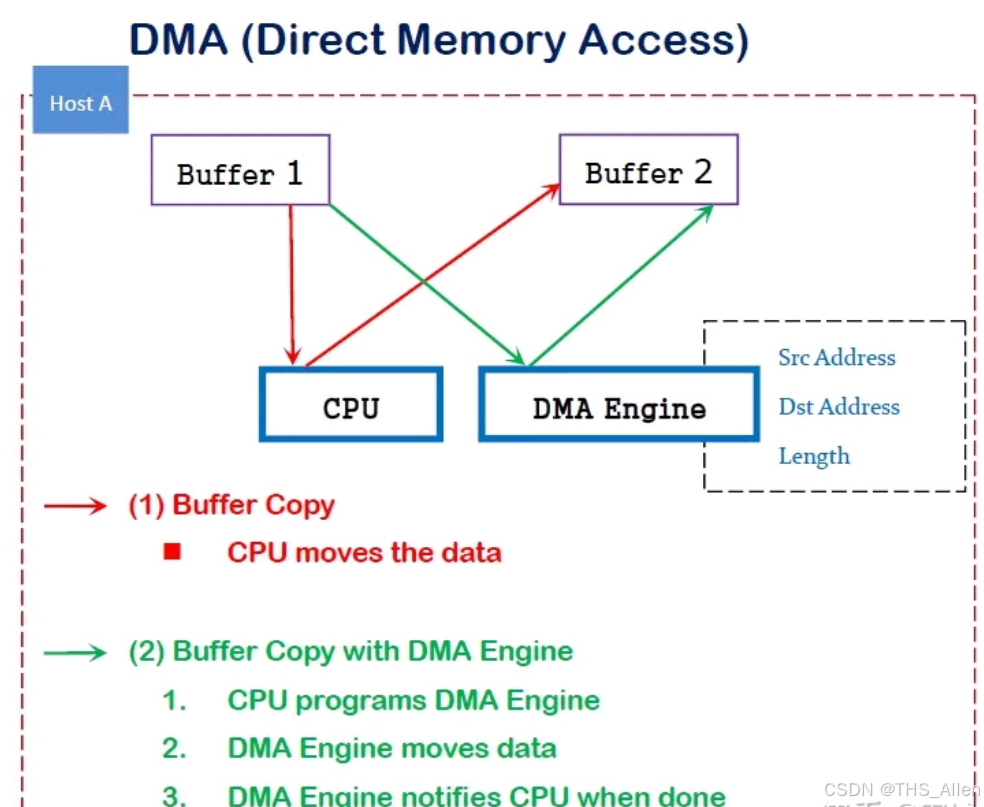
关键技术解析:
协议对比:
| 特性 | RoCEv2 | InfiniBand | 传统TCP/IP |
|---|---|---|---|
| 延迟 | 0.8μs | 0.5μs | 50μs |
| 带宽 | 200Gbps | 400Gbps | 100Gbps |
| CPU占用率 | <5% | ❤️% | 30-70% |
| 部署成本 | 中等(兼容以太网) | 高(专用设备) | 低 |
云原生集成方案:
# 配置K8s CNI插件支持RDMA
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
name: rdma-net
spec:
config: '{
"cniVersion": "0.3.1",
"type": "ipoib",
"master": "eth0",
"mode": "datagram"
}'
2.4 容器层:AI Agent的全生命周期管理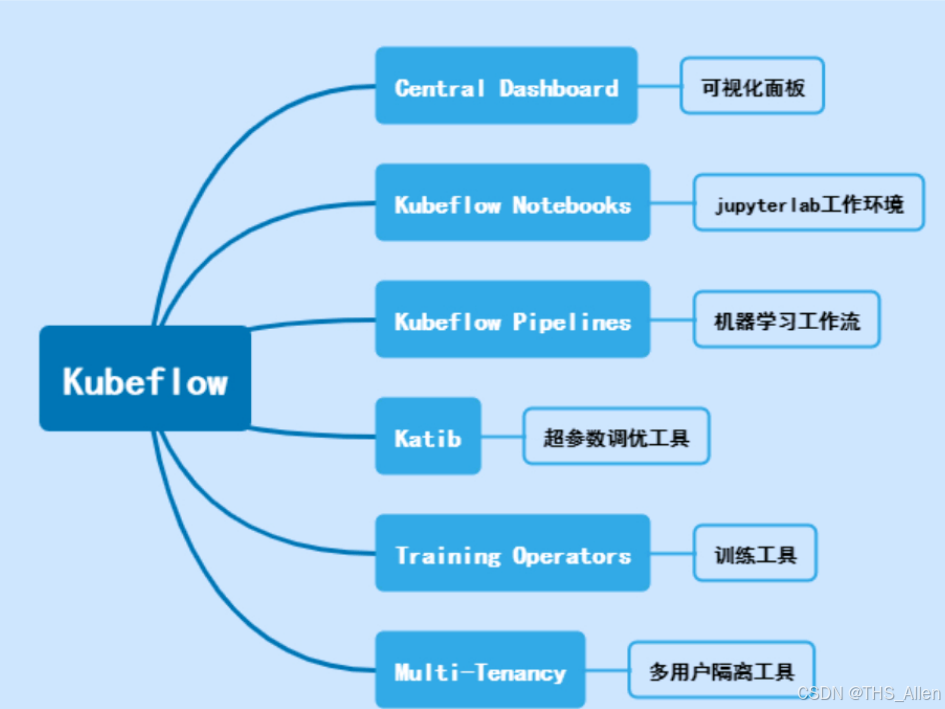
Kubeflow核心组件架构:
关键工作流示例:
# Kubeflow Pipeline定义模型训练
apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
name: resnet50-train
spec:
tfReplicaSpecs:
Worker:
replicas: 4
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:2.8-gpu
command: ["python", "train.py"]
resources:
limits:
nvidia.com/gpu: 2
三、AI云原生落地实践:金融领域案例
3.1 AI-PaaS平台架构
3.2 弹性训练关键技术:DLRover架构解析
# 弹性训练控制逻辑
class TrainingMaster:
def __init__(self):
self.worker_manager = WorkerManager()
self.dataset_service = DatasetShardService()
def handle_worker_failure(self, worker_id):
new_worker = self.worker_manager.restart_worker(worker_id)
self.dataset_service.reassign_shards(worker_id, new_worker)
def scale_workers(self, new_count):
if new_count > current_count:
self._add_workers(new_count - current_count)
else:
self._remove_workers(current_count - new_count)
self.dataset_service.resplit_dataset()
弹性训练三大优势:
- 资源弹性:动态调整Worker数量(如4→8卡)
- 容错弹性:Worker故障自动恢复(恢复时间<30s)
- 配置弹性:实时调整CPU/内存配额
四、进阶:AI云原生未来演进方向
4.1 Serverless AI架构
// Knative Serving函数计算示例
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: llm-inference
spec:
template:
spec:
containers:
- image: llm-inference:v1
resources:
limits:
cpu: "4"
memory: 16Gi
nvidia.com/gpu: 1
scaleMetric: concurrency # 基于并发请求自动扩缩
核心价值:
- 冷启动延迟:<100ms(AWS Lambda实测)
- 成本降低:按毫秒计费,闲置资源归零
4.2 异构算力联邦调度
# Katalyst QoS配置
apiVersion: scheduling.katalyst.kubewharf.io/v1alpha1
kind: ServiceProfileDescriptor
spec:
QoSLevel: BE # 弹性任务
Resources:
- Name: nvidia.com/gpu
Request: 1
Priority: 5 # 低优先级可被抢占
4.3 AI安全基座技术
| 技术 | 实现方案 | 防护目标 |
|---|---|---|
| 可信执行环境 | Intel SGX / AMD SEV | 模型权重加密 |
| 差分隐私 | TensorFlow Privacy | 训练数据保护 |
| 模型水印 | 隐写算法+数字签名 | 版权防篡改 |
五、开发者实战指南
5.1 环境搭建:Minikube部署AI训练集群
# 启用GPU插件
minikube start --driver=docker --container-runtime=containerd \
--feature-gates="DevicePlugins=true" \
--extra-config=kubelet.device-plugin-path=/var/lib/kubelet/device-plugins
# 安装NVIDIA设备插件
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.14.1/nvidia-device-plugin.yml
5.2 模型训练:PyTorch弹性分布式训练
# 使用TorchElastic启动训练
from torch.distributed.elastic import agent
def train_fn(args):
# 模型初始化
model = ResNet50().cuda()
# 数据加载
train_loader = get_data_loader()
if __name__ == "__main__":
spec = agent.LaunchSpec(
entrypoint=train_fn,
min_nodes=1, max_nodes=8, # 弹性伸缩范围
nproc_per_node=4, # 每节点4个GPU
)
agent.run(spec)
5.3 推理服务:KServing流量治理
# 金丝雀发布配置
apiVersion: serving.kserve.io/v1beta1
kind: InferenceGraph
spec:
nodes:
- name: model-router
routerType: Splitter
steps:
- serviceName: fraud-detection-v1
weight: 90 # 90%流量走V1
- serviceName: fraud-detection-v2
weight: 10 # 10%流量测试V2
conditions:
- "[user.tier] == 'premium'" # 高净值用户全量切V2
结语:AI云原生的黄金法则
云原生不是选择,而是AI时代的生存必需。当大模型参数量以指数级增长,当企业AI应用从实验走向生产,唯有云原生架构能提供:
- 资源利用率:GPU利用率从30%→80%+
- 迭代速度:模型部署从小时级→分钟级
- 可靠性:故障恢复从人工干预→自动愈合
开发者行动建议:
- 基础设施容器化:将数据预处理/训练/推理封装为OCI镜像
- 编排调度K8s化:采用Kubeflow/Arena构建计算平台
- 核心服务Serverless化:按需使用函数计算资源池
- 运维体系AIOps化:引入Prometheus+Alertmanager实现智能告警
正如Linux成为互联网时代的操作系统,Kubernetes正成为AI时代的新内核。掌握AI云原生,就是握住智能时代的通行证。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐


 45
45 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)