
大模型 RAG 难点
此外,数据的来源可能多种多样,不同来源的数据质量也参差不齐,如何确保检索到的数据是高质量的、可靠的,是一个难点。但是,准确地识别和提取上下文元信息并非易事,需要对文本的语义和逻辑有深入的理解,并且不同类型的文件和文本内容,其上下文元信息的提取方式也会有所不同。如何优化系统的架构和算法,减少计算资源的消耗,提高系统的性能和效率,是一个重要的问题。检索到的信息可能来自不同的来源,具有不同的写作风格、语
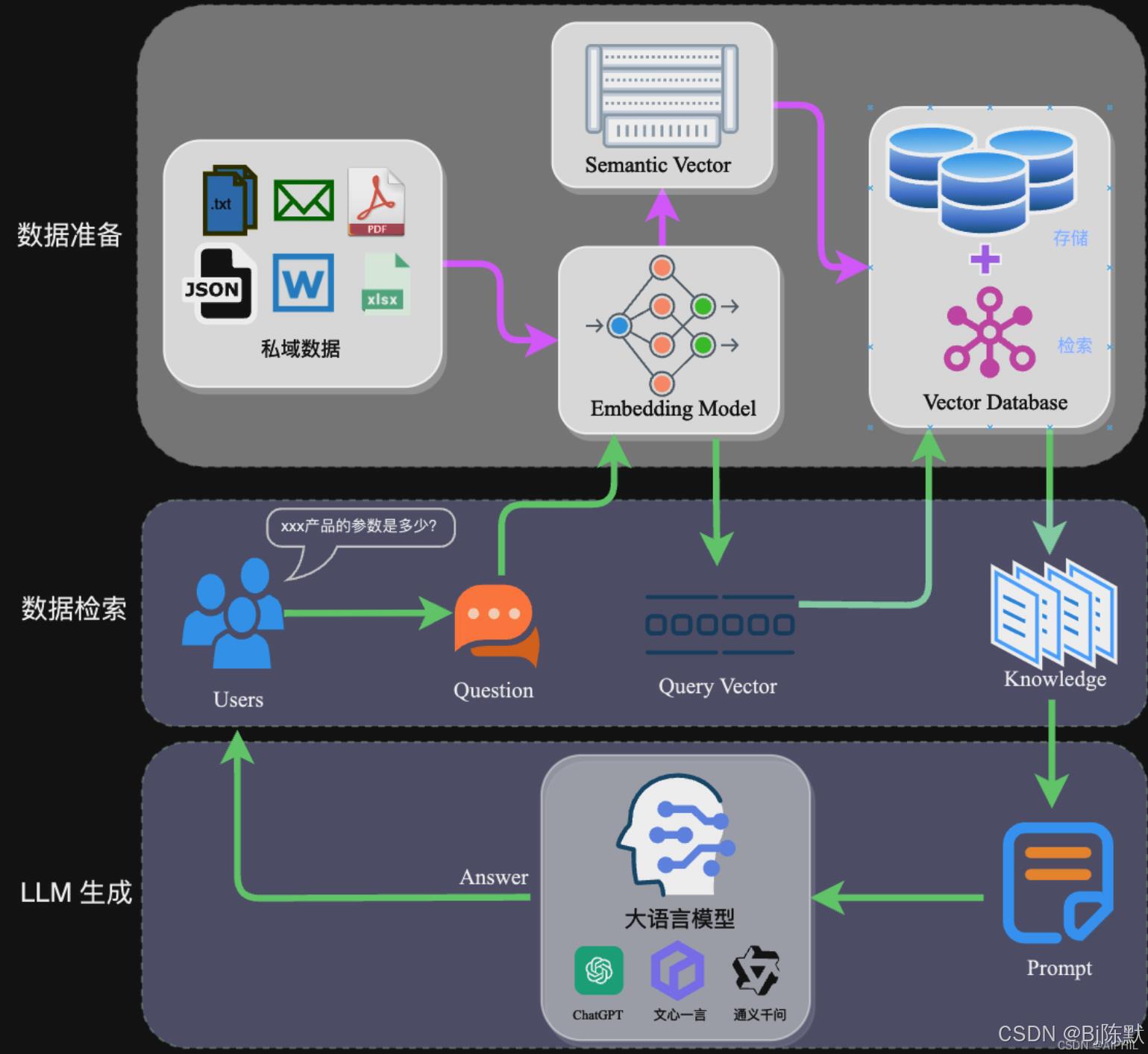
做一个大模型检索增强生成(RAG)系统,有多个部分的工作都存在较大难度,以下是一些较为棘手的方面:
1. 数据处理方面:
数据提取:
复杂文件格式解析:现实中要处理的文件格式多种多样,如PDF文件中可能不光有文字,还夹杂着图表、图片,并且图片中也可能有文字。从这些复杂格式的文件中准确、完整地提取出文本及相关信息是一项挑战。对于图片中的文字提取,需要用到光学字符识别(OCR)技术,而OCR技术的准确率并非100%,可能会出现识别错误或遗漏的情况。对于图表信息的提取,需要理解图表的结构和内容,将其转化为机器可理解的文本信息,这涉及到复杂的算法和模型,建立存储向量和索引时较为困难。
上下文元信息提取:文件通常具有上下文信息,提取这些元信息对于后续的数据处理和分析非常重要。如果不提取元信息,在下一步的数据分块等操作中可能会出现切分错误,影响数据的准确性和完整性。但是,准确地识别和提取上下文元信息并非易事,需要对文本的语义和逻辑有深入的理解,并且不同类型的文件和文本内容,其上下文元信息的提取方式也会有所不同。
数据清洗与质量把控:数据质量是RAG系统的关键。原始数据中可能存在大量的噪声、错误、重复以及不一致性等问题。例如,文本中的拼写错误、语法错误,数据集中的重复记录等,都需要进行清洗和处理。此外,数据的来源可能多种多样,不同来源的数据质量也参差不齐,如何确保检索到的数据是高质量的、可靠的,是一个难点。如果数据质量不高,可能会导致系统生成的答案不准确或不可靠。
2. 索引构建方面:
数据切分策略:需要将文档切分成合适的片段以便进行索引和后续的检索。切分的大小和方式需要仔细考虑,如果切分过大,可能会导致检索的粒度不够精细,无法准确找到与查询最相关的部分;如果切分过小,可能会丢失文本的上下文信息,影响生成的答案的连贯性和准确性。而且,对于不同类型的文本内容,如长文本、短文本、具有复杂逻辑结构的文本等,需要采用不同的切分策略。
向量表示与嵌入:将文本转换为向量表示是索引构建的核心步骤。选择合适的向量嵌入模型和算法非常重要,不同的模型和算法对文本的语义理解和向量表示能力不同,会直接影响到检索的准确性和效率。此外,向量嵌入的计算成本通常较高,特别是对于大规模的数据集,如何在保证嵌入质量的前提下,提高计算效率也是一个挑战。
3. 检索阶段方面:
检索质量和准确性:RAG模型严重依赖于检索到的上下文文档的质量。如果检索器无法找到相关的事实段落,就会严重妨碍模型根据有用信息产生准确、深入的响应。在语义匹配和检索高质量文档方面存在困难,例如,由于语义歧义、向量空间密度等问题,可能会导致检索到不相关或不准确的结果。提高检索质量需要采用更先进的检索算法和模型,如密集检索器模型、多向量表示、近似最近邻搜索等,但这些方法的实现和优化都具有一定的难度。
覆盖范围和实时性:即使是最大的语料库也无法完全覆盖用户可能查询的所有实体和概念,对于一些新兴的或小众的主题,可能无法检索到相关的知识。同时,在一些实时应用场景中,需要系统能够快速地检索到最新的信息,这对数据的更新和检索的实时性提出了要求。如何扩展语料库、增加实时检索功能,以及在保证性能的前提下实现快速的数据更新,是需要解决的问题。
情境调节:即使具有良好的检索能力,RAG模型也常常难以正确地调节上下文文档并将外部知识合并到生成的文本中。如果没有有效的情境调节,就无法产生具体的、真实的反应。这需要设计专门的算法和模型来加强情境化,例如使用专用的交叉注意力转换器层、具有自我监督目标的预训练语言模型等,但这些方法的效果和性能还需要进一步的验证和优化。
4. 生成阶段方面:
信息融合与连贯性:将检索到的信息与大模型生成的内容进行有效融合是一个难点。检索到的信息可能来自不同的来源,具有不同的写作风格、语气和表达方式,如何将这些信息与大模型生成的内容进行无缝融合,使得生成的答案具有连贯性和一致性,是一个挑战。此外,还需要避免生成的内容出现重复、冗余等问题。
答案的准确性和可靠性:生成的答案需要准确可靠,特别是在需要事实性回答的场景中。大模型本身可能存在“幻觉”问题,即生成与现实不符的输出,而RAG系统需要克服这个问题,确保生成的答案是基于准确的检索信息和可靠的推理。这需要对生成的答案进行验证和评估,但目前缺乏有效的自动化评估指标,人工评估又缺乏可扩展性,这阻碍了系统的迭代改进。
个性化落地:在通用语料库上训练的RAG模型缺乏针对特定用户需求、上下文和查询生成响应的能力。不同用户的提问意图、背景知识和需求都可能不同,如何根据用户的个性化信息进行定制化的回答,是实现RAG系统实际应用的关键。这需要设计有效的用户画像和个性化模型,对先前对话和用户反馈进行多任务训练等,但这些方法的实现难度较大,且需要大量的用户数据进行训练和优化。
5. 系统性能优化方面:
计算资源消耗:RAG技术通常需要大量的计算资源,包括CPU、GPU、内存等。在处理大规模数据集和高并发请求时,系统的计算资源需求会进一步增加。如何优化系统的架构和算法,减少计算资源的消耗,提高系统的性能和效率,是一个重要的问题。例如,可以采用模型蒸馏、模型压缩等技术来减少模型的参数和计算量。
推理延迟:对于一些实时应用场景,如在线客服、智能助手等,系统的响应速度非常重要。RAG系统中的检索和生成过程都需要一定的时间,如何优化这些过程,减少推理延迟,提高系统的实时性,是一个挑战。这需要采用高效的索引算法、近似最近邻搜索等技术,以及对系统的硬件和软件进行优化配置。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)