
自动提示SQL:一种在资源受限环境中实现文本到SQL转换的高效架构
本文提出了一种新型架构Auto Prompt SQL(AP-SQL),旨在解决资源受限环境中使用大型闭源模型进行文本到SQL翻译的挑战。AP-SQL将任务分解为模式过滤、检索增强式文本到SQL生成以及提示驱动的模式链接和SQL生成。通过微调大型语言模型提高模式选择的准确性,并结合思维链(CoT)和思维图(GoT)模板增强模型的推理能力。在Spider基准上的评估表明,AP-SQL在多种大型语言模型
Zetong Tang 1{ }^{1}1, Qian Ma2\mathrm{Ma}^{2}Ma2, Di Wu3∗\mathrm{Wu}^{3 *}Wu3∗
1{ }^{1}1 西南大学计算机与信息科学学院,xdnx029311@email.swu.edu.cn,中国重庆
2{ }^{2}2 西南大学计算机与信息科学学院,m18608279976@email.swu.edu.cn,中国重庆
3{ }^{3}3 西南大学计算机与信息科学学院,wudi1986@swu.edu.cn,中国重庆
摘要
由于最先进的Text-to-SQL方法依赖于资源消耗较大的开源模型,在资源受限的环境中使用它们具有挑战性。本文介绍了一种新型架构Auto Prompt SQL(AP-SQL),旨在弥合资源高效的轻量级开源模型与强大功能的大型闭源模型之间的差距,用于文本到SQL的翻译。我们的方法将任务分解为模式过滤、基于上下文示例的检索增强式文本到SQL生成、以及提示驱动的模式链接和SQL生成。为了提高模式选择的准确性,我们对大型语言模型进行了微调。至关重要的是,我们还探索了在整个过程中提示工程的影响,利用思维链(CoT)和思维图(GoT)模板显著增强了模型的推理能力,以生成准确的SQL。在Spider基准上的全面评估证明了AP-SQL的有效性。
关键词:语言模型,文本到SQL,提示工程,微调,上下文学习
1 引言
文本到SQL的任务涉及将问题转化为可执行且有效的结构化查询语言(SQL)查询。它展示了根据数据库模式制定自然语言问题并随后将其转换为SQL查询的过程 [4,5][4,5][4,5]。
1.1 最新技术的局限性和不足
传统方法主要采用监督微调。然而,最近一系列大型语言模型(包括GPT、Claude、Qwen和Kimi)的出现引发了范式转变,提示工程开始在该领域崭露头角。(1)大型闭源模型展现出强大的推理能力,这些能力源于其庞大的参数训练。这些参数可能会潜在地影响大型模型的推理过程,导致产生幻觉信息 [6]。(2)这些模型的知识仅限于其训练数据的时间点,导致对未见过的知识和信息缺乏准确理解 [9,10,21][9,10,21][9,10,21]。(3)推理过程的不透明性使得难以解释模型是如何得出特定结论的,并阻止了对模型推理路径的验证 [7]。本文介绍了Autoprompt,这是一种专为大型模型设计的即插即用开源语言模型。该框架中的模式选择模块基于对Qwen模型的微调构建,并使用大型语言模型进行模式链接分类。最后,通过我们设计的提示-提示模板与生成式大型模型集成,实现了文本到SQL的生成。
1.2 研究现状
在我们的调查中,涵盖了基于监督微调和提示工程的文本到SQL方法。此外,我们还调查了各种现有的模式链接技术和提示设计技术,这些技术可以用来增强文本到SQL的方法 [25-36]。
1.2.1 文本到SQL的监督微调:在大型语言模型技术出现之前,文本到SQL的主要方法是对“编码器-解码器”神经网络模型进行微调 [11,12,14,15][11,12,14,15][11,12,14,15]。其他努力集中在将SQL语法注入解码器中,这限制了解码器的输出空间,确保生成语法正确的SQL查询 [8]。随着语言模型的进步,越来越多的趋势是将文本到SQL表述为序列到序列(seq2seq)任务 [23,24][23,24][23,24]。
1.2.2 基于提示工程的文本到SQL:随着ChatGPT系列、Claude系列、Qwen系列和Llama系列等大型语言模型的出现,自然语言处理(NLP)领域发生了革命性的变革。这些模型在各种需要推理的复杂任务上取得了显著进展,而无需微调任何参数。利用文本到SQL的演示作为少样本提示,它们在Spider基准测试中成功达到了最先进(SOTA)的表现 [13,17,19]。
1.2.3 模式链接:模式链接在文本到SQL的过程中起着至关重要的作用,该任务旨在识别自然语言问题中引用的数据库模式(表和列)和数据库值。主要有两种策略
对于模式链接:基于字符串匹配的和基于神经网络的。基于字符串匹配的方法看起来简单有效,但在处理同义词和多义词时存在局限性 [22]。
1.2.4 检索增强生成(RAG):它本质上是利用工程化方法来解决大型语言模型的局限性。其核心机制是利用连接到大型语言模型的外部知识数据库来存储训练数据中不存在的新数据、领域特定数据等 [16,18,20][16,18,20][16,18,20]。
2. 方法论
文本到SQL的目标是根据自然语言问题 QQQ 和数据库模式信息 DDD 生成一个SQL查询 SSS,这个过程可以公式化如下:
S=P(Q,D) S=P(Q, D) S=P(Q,D)
模型 PPP 需要匹配并理解自然语言问题 QQQ 与数据库模式信息 DDD,然后生成SQL语句。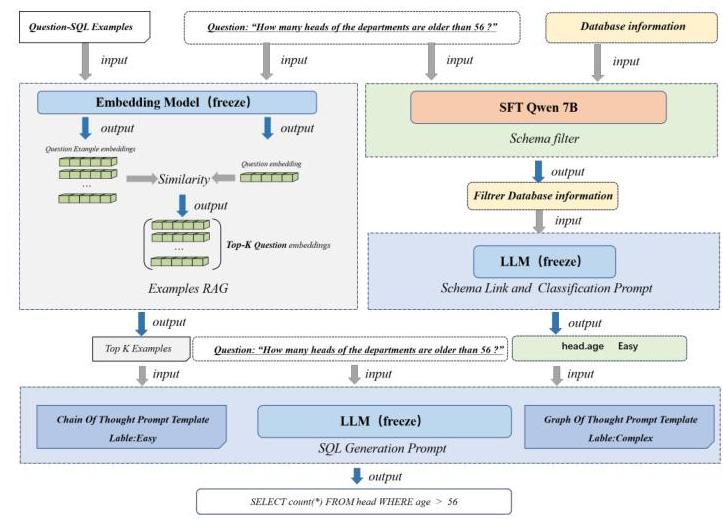
图1. 综合框架示意图
Auto-Prompt的框架如图1所示,首先,我们使用微调的大型语言模型构建了一个模式过滤器,以高效收集与问题相关的表格和列信息。随后,结合模式链接提示策略,引导模型完成模式链接任务,并为不同问题设计难度分级机制。为进一步增强大型模型的推理能力,我们引入了一个示例RAG模块,从训练集中选择Top-K个最相关的NL-SQL示例用于推理增强。在最终的SQL生成阶段,我们设计了思维链提示模板和思维图提示模板,引导大型模型进行结构化和分层推理生成,从而提高SQL生成的准确性。
使用提示工程方法,SQL生成过程可以公式化如下:
S=LM(I,D,Q,E) S=\operatorname{LM}(I, D, Q, \mathcal{E}) S=LM(I,D,Q,E)
III 表示指令,DDD 表示数据库模式信息,QQQ 表示问题。E=[(D1,Q1,P1),…,Dn,Qn,Pn)\mathcal{E}=\left[\left(\mathrm{D}_{1}, Q_{1}, P_{1}\right), \ldots, D_{n}, Q_{n}, P_{n}\right)E=[(D1,Q1,P1),…,Dn,Qn,Pn) ] 表示样本列表。其中 PiP_{i}Pi 是第i个样本的正确SQL答案提示。因此,大型模型的SQL生成性能主要受模式信息的准确性、样本的选择以及提示风格的设计影响。
2.1 示例检索增强生成
为了提高文本到SQL框架的跨域适应性,并在不需要复杂微调的情况下增强大型语言模型在少量样本设置下的性能,我们开发了一个RAG模块。该模块动态提供与输入问题相关的外部知识,用于模式链接和SQL生成。具体来说,它根据用户的自然语言问题,从预先构建的高质量示例库中检索Top-K个最相关的文本-SQL对。这些示例与问题一起作为上下文提示输入到模型中,使模型能够更好地理解语义并生成更准确的SQL查询。
2.2 模式过滤
在实际应用中,包含大量表和列的数据库会导致大型语言模型的提示过长,增加计算负载,并可能忽略关键表和字段。
为了解决这个问题,我们提出了一种基于问题的模式过滤方法,在保留关键信息的同时压缩提示长度。具体来说,给定一个自然语言问题,我们的方法从数据库中选择前3个最相关的表,并保留每个表中前3个最相关的列,从而显著减少提示长度,同时保持与问题紧密相关的模式信息。过滤模型基于监督微调的Qwen-3B构建,在模式理解和问题关联方面表现出色,能够精确过滤。它在一个包含约8万个标注问题-模式对的数据集上进行了10轮微调,使用的学习率为 5e−55 \mathrm{e}-55e−5,批大小为16。训练是在24090 D GPU上进行的,确保了足够的计算资源以实现稳定的收敛和性能。
2.2 模式链接
在我们构建的模式链接提示设计中,我们引入了一种少样本学习机制来指导模型的问题推理。整个过程依次经过两个阶段:表选择和列选择,逐步基于过滤后的模式信息进行,最终选择与当前问题相关的表和列信息。
此外,在表选择过程中,我们还尝试利用大型模型本身来评估其在解决问题中的进展。具体来说,我们基于问题独立评分每张表以确定其相关性。该过程可以公式化如下:
∀d∈Dables ,V(p,q)∼(d↦v(d)) \forall d \in D_{\text {ables }}, V(p, q) \sim(d \mapsto v(d)) ∀d∈Dables ,V(p,q)∼(d↦v(d))
从数据库模式中的表集合 Dables D_{\text {ables }}Dables 中选取单个表 ddd, V(p,q)V(p, q)V(p,q) 是一个函数,用于评估在给定提示 ppp 和问题 qqq 的情况下表 ddd 的相关性。v(d)v(d)v(d) 是一个标量值(1-10),选择得分高于某个阈值(例如6)的表的信息。完成此步骤后,我们再使用投票法比较 ddd 中不同列的信息。
2.3 SQL生成
针对SQL生成任务,我们采用了根据查询复杂度定制的提示策略。对于涉及基本操作(如过滤、排序和聚合)的简单单表查询,我们采用思维链(CoT)提示,引导模型通过线性、逐步的推理过程。
CoT提示通过展示问题-解决方案示例对来促进结构化推理,每个示例对包括一个自然语言问题、详细的推理过程和最终的SQL查询。这种方法通过利用精心挑选的一小部分示例帮助模型推广到新查询。对于更复杂的多表查询——例如涉及嵌套子查询、条件连接、分组和高级SQL构造的查询——我们使用思维图提示。这种方法将问题解决建模为相互连接的推理节点图。每个示例包括一个问题、一个详细中间推理步骤的结构化图以及最终解决方案,允许模型系统地分解并解决复杂的查询。
3 结果
3.1 数据集
我们主要在Spider数据集上进行了主要的文本到SQL实验,该数据集包含8,659个训练样本和1,034个开发样本。Spider覆盖了138个不同领域的200个数据库。
对于在Spider上评估的模型,我们主要使用执行准确性(Execution Accuracy)和测试套件准确性(Test Suite Accuracy)。EX评估预测的SQL和真实SQL查询在数据库上是否产生相同的执行结果。由于执行准确性中可能存在假阳性,即错误的SQL查询恰好产生与正确查询相同的结果,我们使用TS评估生成的SQL查询是否在多个数据库实例上始终通过EX评估。实验是在2块4090D GPU上进行的,模式链接阈值设为6,RAG模块检索了K=3K=3K=3个文本-SQL对。
3.2 对比实验
表1清楚地显示,AP-SQL在Spider数据集上一致优于其他模型,涵盖Qwen-7B、Llama-8B、GPT-4o-mini和GPT-4o等多种LLM。对于每个模型,AP-SQL均达到最高的EX%和TS%分数,明显优于E-SQL[3]、ACT-SQL[1]和C3-SQL[2]。例如,使用GPT-4o时,AP-SQL达到89.7的EX%和82.6的TS%,分别超过次优方法E-SQL 4.1和7.2个百分点。
表1. 在Spider上对AP-SQL的评估。
| 方法 | LLM | EX% | TS% |
|---|---|---|---|
| E-SQL | Qwen-7B | 67.8 | 60.4 |
| DIN-SQL | 63.7 | 54.6 | |
| ACT-SQL | 51.1 | 43.3 | |
| C3-SQL | 52.6 | 47.5 | |
| AP -SQL (ours) | 68.3 | 60.8 | |
| E-SQL | Llama-8B | 70.2 | 63.3 |
| DIN-SQL | 69.5 | 61.4 | |
| ACT-SQL | 63.7 | 55.5 | |
| C3-SQL | 60.9 | 50.2 | |
| AP -SQL (ours) | 72.4 | 64.1 | |
| E-SQL | GPT-4o-mini | 82.6 | 72.4 |
| DIN-SQL | 74.2 | 69.6 | |
| ACT-SQL | 80.7 | 70.2 | |
| C3-SQL | 78.1 | 71.4 | |
| AP-SQL (ours) | 83.2 | 75.8 | |
| E-SQL | GPT-4o | 88.6 | 79.4 |
| DIN-SQL | 87.6 | 81.5 | |
| ACT-SQL | 86.7 | 78.2 | |
| C3-SQL | 86.2 | 79.6 | |
| AP -SQL (ours) | 89.7 | 82.6 |
这种持续的优越性突显了AP-SQL在增强不同语言模型的SQL查询生成方面的有效性。与DIN-SQL相比,AP-SQL显著提高了复杂数据库模式的适应性,并通过解耦模式链接和生成模块降低了推理成本。
4 结论
Auto-Prompt通过模块化设计、监督微调和提示工程,显著提升了文本到SQL的性能。其开源性质、对新领域的强适应性以及高效的推理使其适用于低资源环境。未来的工作可以进一步优化提示设计,以支持更复杂的数据库查询。
5 参考文献
[1]. Dong X, Zhang C, Ge Y, et al. :‘C3: Zero-shot text-to-SQL with ChatGPT’. arXiv preprint arXiv:2307.07306, 2023
[2]. Caferoğlu, H. A., Ulusoy, Ö. :E-sql: Direct schema linking via question enrichment in text-to-sql’. arXiv preprint arXiv:2409.16751, 2024
[3]. Li, H., Zhang, J., Liu, H., et al. ‘Codes: Towards building open-source language models for text-to-SQL’, Proc. ACM Manage. Data, 2024, 2, (3), pp. 1-28
[4]. Gao, Y., Liu, Y., Li, X., et al.:‘Xiyan-SQL: A multi-generator ensemble framework for text-to-SQL’. arXiv preprint arXiv:241 unter1.08599, 2024
[5]. Li, H., Zhang, J., Li, C., et al. ‘RESDSQL: Decoupling schema linking and skeleton parsing for text-to-SQL’. Proc. AAAI Conf. Artificial Intelligence, Washington, D.C., USA, February 2023, AAAI Press, 37, (11), pp. 13067-13075
[6]. Wang, B., Shin, R., Liu, X., et al.:‘RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers’. Proc. 58th Annu. Meet. Assoc. Comput. Linguistics, Virtual, July 2020, Association for Computational Linguistics, pp. 7567-7578
[7]. Luo, X., Wu, H., Wang, Z., et al.:‘A Novel Approach to Large-Scale Dynamically Weighted Directed Network Representation’, IEEE Trans. Pattern Anal. Mach. Intell., 2022, 44, (12), pp. 9756-9773
[8]. Wu, D., Luo, X., Shang, M., et al.:‘A Data-Characteristic-Aware Latent Factor Model for Web Services QoS Prediction’, IEEE Trans. Knowl. Data Eng., 2022, 34, (6), pp. 2525-2538
[9]. Shang, M., Yuan, Y., Luo, X., et al. :‘An α−β\alpha-\betaα−β-divergence-generalized Recommender for Highly-accurate Predictions of Missing User Preferences’, IEEE Transactions on Cybernetics, 2022, 52,(8),pp. 8006-8018.
[10]. Wu, D., He, Y., Luo, X., et al. :‘A Latent Factor Analysis-based Approach to Online Sparse Streaming Feature Selection’. IEEE Transactions on Systems Man Cybernetics: Systems, 2022, 52,(11),pp. 6744−67586744-67586744−6758.
[11]. Luo, X., Wang, D., Zhou, M., et al. :Latent Factor-based Recommenders Relying on Extended Stochastic Gradient Descent Algorithms’. IEEE Transactions on Systems Man Cybernetics: Systems, 2021, 51,(2),pp. 916-926.
[12]. Li,W., He,Q., Luo, X. , et al. ‘Assimilating Second-Order Information for Building Non-Negative Latent Factor Analysis-Based Recommenders’. IEEE Transactions on Systems Man Cybernetics: Systems, 2021, 52,(1),pp. 485-497.
[13]. Luo, X., Zhou,M., Li,S. :‘Algorithms of Unconstrained Non-negative Latent Factor Analysis for Recommender Systems’, IEEE Transactions on Big Data, 2021, 7,(1),pp. 227-240.
[14]. Luo, X., Zhou,M. :‘Effects of Extended Stochastic Gradient Descent Algorithms on Improving Latent Factor-based Recommender Systems’. IEEE Robotics and Automation Letters, 2019, 4,(2),pp. 618624 .
[15]. Wu,D., Luo, X., Wang,G., et al. :‘A Highly-Accurate Framework for Self-Labeled Semi-Supervised Classification in Industrial Applications’. IEEE Transactions on Industrial Informatics, 2018, 14,(3),pp. 909-920.
[16]. Luo, X., Sun,J., Wang,Z., et al. :‘Symmetric and Non-negative Latent Factor Models for Undirected, High Dimensional and Sparse Networks in Industrial Applications’. IEEE Transactions on Industrial Informatics, 2017, 13,(6),pp. 3098-3107.
[17]. Luo, X., Zhou,M., Li,S., et al. :‘A Nonnegative Latent Factor Model for Large-Scale Sparse Matrices in Recommender Systems via Alternating Direction Method’. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27,(3),pp. 524-537.
[18]. Luo, X., Zhou,M, Li,S., et al. :‘An Efficient Second-order Approach to Factorizing Sparse Matrices in Recommender Systems’. IEEE Transactions on Industrial Informatics. 2015, 11,(4),pp. 946-956.
[19]. Luo, X., Zhou,M., Xia,Y. , et al. :‘An Efficient Non-negative Matrix-factorization-based Approach to Collaborative-filtering for Recommender Systems’. IEEE Transactions on Industrial Informatics, 2014, 10,(2),pp. 1273-1284.
[20]. Wu,D., He,Y., Luo, X. :‘A Graph-incorporated Latent Factor Analysis Model for High-dimensional and Sparse Data’. IEEE Transactions on Emerging Topics in Computing, 2023, 11,(4),pp. 907-917.
[21]. Wu,D., Zhang,P., He,Y., et al. :‘A Double-Space and Double-Norm Ensembled Latent Factor Model for Highly Accurate Web Service QoS Prediction’, IEEE Transactions on Services Computing, 2023, 16,(2),pp. 802-814.
[22]. Luo, X., Liu,Z., Shang,M., et al. :‘Highly-Accurate Community Detection via Pointwise Mutual Information-Incorporated Symmetric Non-negative Matrix Factorization’, IEEE Transactions on Network Science and Engineering, 2021, 8,(1), pp.463-476.
[23]. Li,Z., Li,S., Luo, X. :‘An Overview of Calibration Technology of Industrial Robots’, IEEE/CAA Journal of Automatica Sinica, 2021, 8,(1),pp.23-36.
[24]. Luo, X., Zhou,M., Xia,Y. , et al. :‘An Efficient Non-negative Matrix-factorization-based Approach to Collaborative-filtering for Recommender Systems’. IEEE Transactions on Industrial Informatics, 2014, 10,(2),pp. 1273-1284.
[25]. Wu,D., Luo, X., He,Y., et al. :‘A Prediction-sampling-based Multilayer-structured Latent Factor Model for Accurate Representation to High-dimensional and Sparse Data’. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35,(3),pp. 3845-3858.
[26]. Wu,D., He,Y., Luo, X. :‘A Graph-incorporated Latent Factor Analysis Model for High-dimensional and Sparse Data’. IEEE Transactions on Emerging Topics in Computing, 2023, 11,(4),pp. 907-917.
[27]. Wu,D., Zhang,P., He,Y., et al. :‘A Double-Space and Double-Norm Ensembled Latent Factor Model for Highly Accurate Web Service QoS Prediction’, IEEE Transactions on Services Computing, 2023, 16,(2),pp. 802-814.
[28]. Wu,D., He,Q., Luo, X., et al. :‘A Posterior-neighborhood-regularized Latent Factor Model for Highly Accurate Web Service QoS Prediction’, IEEE Transactions on Services Computing, 2022, 15,(2),pp. 793-805.
[29]. Wu,D., He,Y., Luo, X., et al. :‘A Latent Factor Analysis-based Approach to Online Sparse Streaming Feature Selection’. IEEE Transactions on Systems Man Cybernetics: Systems, 2022, 52(11),pp.6744-6758.
[30]. Wu,D., Shang,M., Luo, X., et al. :‘An L1-and-L2-norm-oriented Latent Factor Model for Recommender Systems’, IEEE Transactions on Neural Networks and Learning Systems, 2022, 33,(10),pp. 57755788.
[31]. Wu,D., Luo, X., He,Y., et al. :‘A Prediction-sampling-based Multilayer-structured Latent Factor Model for Accurate Representation to High-dimensional and Sparse Data’. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35,(3),pp.3845-3858.
[32]. Luo, X., Wang,Z., Shang,M. :‘An Instance-frequency-weighted Regularization Scheme for Non-negative Latent Factor Analysis on High Dimensional and Sparse Data’. IEEE Transactions on Systems Man Cybernetics: Systems, 2021, 51,(6),pp.3522-3532.
[33]. Luo, X., Liu,Z., Shang,M., et al. :‘Highly-Accurate Community Detection via Pointwise Mutual Information-Incorporated Symmetric Non-negative Matrix Factorization’, IEEE Transactions on Network Science and Engineering, 2021, 8,(1), pp.463-476.
[34]. Li,Z., Li,S., Luo, X. :‘An Overview of Calibration Technology of Industrial Robots’, IEEE/CAA Journal of Automatica Sinica, 2021, 8,(1),pp.23-36.
[35]. Jin,L., Zhang,J., Luo, X., et al. :‘Perturbed Manipulability Optimization in A Distributed Network of Redundant Robots’. IEEE Transactions on Industrial Electronics, 2021, 68, (8),pp. 7209-7220.
[36]. Luo, X., Zhou,M., Li,S.,et al. :‘Non-negativity Constrained Missing Data Estimation for High-dimensional and Sparse Matrices from Industrial Applications’. IEEE Transactions on Cybernetics, 2020, 50,(5),pp. 1844-1855.
参考论文:https://arxiv.org/pdf/2506.03598

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 24
24 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)