
改善小型大语言模型的钓鱼邮件检测性能
大语言模型(LLMs)在许多自然语言处理(NLP)任务中表现出卓越性能,并已被应用于钓鱼邮件检测研究。然而,在当前的研究中,表现良好的LLMs通常包含数十亿甚至数百亿个参数,需要大量的计算资源。为了降低计算成本,我们研究了小型参数LLMs在钓鱼邮件检测中的有效性。这些LLMs约有30亿个参数,可以在消费级GPU上运行。然而,小型LLMs在钓鱼邮件检测任务中往往表现不佳。为了解决这些问题,我们设计了
林子杰
新加坡国立大学 lin.zijie@u.nus.edu
刘子康
新加坡国立大学 e1351201@u.nus.edu
范翰博
新加坡国立大学 hanbofan1@gmail.com
摘要
大语言模型(LLMs)在许多自然语言处理(NLP)任务中表现出卓越性能,并已被应用于钓鱼邮件检测研究。然而,在当前的研究中,表现良好的LLMs通常包含数十亿甚至数百亿个参数,需要大量的计算资源。为了降低计算成本,我们研究了小型参数LLMs在钓鱼邮件检测中的有效性。这些LLMs约有30亿个参数,可以在消费级GPU上运行。然而,小型LLMs在钓鱼邮件检测任务中往往表现不佳。为了解决这些问题,我们设计了一套方法,包括提示工程、解释增强微调和模型集成,以提高小型LLMs的钓鱼邮件检测能力。我们通过实验验证了我们方法的有效性,显著提高了SpamAssassin数据集上的准确性,从基线模型如Qwen2.5-1.5B-Instruct的大约0.5提升到0.976。
关键词 钓鱼邮件检测 ⋅\cdot⋅ 小型LLMs
1 引言
钓鱼邮件长期以来一直是重大的网络安全威胁,对个人和组织都构成了严重风险。随着时间的推移,各种钓鱼检测技术已被研究。最初,基于规则的过滤系统和简单的黑名单被用于钓鱼邮件检测。后来,简单的机器学习方法如朴素贝叶斯[1]和支持向量机(SVM)[2],以及数据挖掘方法如决策树[3],标志着电子邮件检测技术的重大发展。
近年来,深度学习技术在钓鱼邮件检测中受到了越来越多的关注。深度神经网络模型可以自动捕获电子邮件的高维特征,并已在钓鱼检测中被广泛研究[4]。最初,研究人员专注于使用卷积神经网络(CNN)[5]、循环神经网络(RNN)[6]及类似模型进行钓鱼邮件检测。近年来,基于Transformer的模型迅速发展[7]。这些模型擅长捕捉语义信息,并迅速应用于钓鱼检测任务。起初,人们更喜欢像BERT[8]这样的仅编码器架构,因为其双向注意力机制有助于更好地捕捉上下文信息。随着像GPT[9, 10]这样的仅解码器模型参数数量和训练数据质量的增加,这些LLMs也变得擅长钓鱼邮件检测任务。
然而,我们注意到,虽然许多研究使用LLMs进行钓鱼检测,但表现良好的模型通常具有更大的参数数量。例如,Nguyen等人使用基于LLaMA-3.1-70b和GPT-4构建的辩论框架进行钓鱼检测[11],在SpamAssassin和尼日利亚诈骗等数据集上实现了大约0.99的准确率[12]。尽管它们的准确率很高,但考虑到LLaMA-3.1-70b[13]和GPT-4等模型拥有数百亿甚至数万亿参数,计算成本相当可观。为了解决这个问题,我们提出使用较小的语言模型如LLaMA-3.2-3B-Instruct[14]和Phi-4-mini-Instruct[15]进行检测。这些模型约有30亿个参数,可以在消费级GPU上运行,并显著减少计算需求。然而,我们发现直接使用这些模型进行检测效果较差——例如,Qwen2.5-1.5B-Instruct[16]在SpamAssassin数据集上的准确率仅为0.388,而LLaMA-3.2-3B仅为0.587。为了解决这些挑战,我们提出了几种方法来增强小型LLMs在钓鱼邮件检测任务中的性能。通过逐步实践我们的方法,我们有效提升了小型LLMs的钓鱼邮件检测能力。我们的方法流程如图1所示。
- 提示工程:通过精心设计的提示,我们鼓励LLMs以结构化格式输出其推理和答案,从而实现基本的钓鱼邮件检测。
-
- 解释增强微调:微调可以增强LLMs在特定下游任务中的能力。然而,我们发现直接在仅包含电子邮件及其标签的数据集上进行微调效果较差。我们认为,在微调过程中仅使用电子邮件标签作为训练目标不符合LLMs的生成性质。因此,我们使用PT-4o-mini[17]为每个训练样本生成解释,详细说明为什么该电子邮件是(或不是)钓鱼尝试。通过这种方法,我们有效提升了微调后LLMs的检测能力。
-
- 模型集成:在前一步中,我们对多个LLMs进行了微调,使我们可以考虑模型集成技术以进一步提升检测性能。我们实施了两种集成方法:(1) 多数投票,其中我们让三个LLMs评估每封电子邮件,并将多数意见作为最终结果;(2) 置信度集成,其中我们根据LLM输出的标记logprobs计算置信度分数,并选择置信度最高的答案。通过模型集成技术,我们进一步提升了检测性能。
2 相关工作
钓鱼邮件与合法邮件之间存在显著的内容差异。早期研究主要利用关键词过滤器来检测钓鱼邮件。这些过滤器通常基于TF-IDF算法或词袋模型,并结合互信息提取关键词特征。Androutsopoulos等人评估了各种类型的朴素贝叶斯分类器的检测能力,并取得了一些成果[18, 19]。然而,他们的方法基于理想化的假设,不足以应对不断演变的钓鱼威胁。Drucker等人采用线性核的支持向量机,并通过加权策略解决现实环境中数据不平衡问题。他们的模型在处理高维稀疏特征方面表现出色[20]。Carreras等人探索了提升树模型的性能及不同复杂度基础学习器的影响。他们的模型比传统线性模型具有更高的准确性,并能适应不同的误分类成本[21]。
深度学习的发展为钓鱼邮件检测带来了新的机遇。Roy等人利用词嵌入技术提取特征。他们能够捕获电子邮件中的深层语义信息。他们在这些特征上训练CNN和LSTM模型,显著超越了传统模型在钓鱼
检测任务中的表现[22]。Guo等人使用预训练的BERT模型从电子邮件文本中提取语义特征,并训练四个传统分类器——朴素贝叶斯、支持向量机、逻辑回归和随机森林——来评估性能。他们的结果显示,由BERT提取的语义特征可以显著提高传统模型的有效性[23]。
随着深度学习的不断发展,生成式LLMs应运而生。这些模型在上下文理解和推理方面表现出卓越的能力,在文本分类任务中取得了杰出的表现。Cunha等人研究了传统模型和LLMs在文本分类任务中的差异,展示了LLMs的显著优势[24]。Heiding等人进一步探讨了LLMs在钓鱼邮件检测任务中的有效性[25]。他们的研究发现,LLMs在识别钓鱼邮件意图方面表现出色,即使是对意图模糊的邮件也是如此。在某些情况下,LLMs的表现甚至优于人类评估者。Koide等人使用GPT-4进行钓鱼邮件检测,达到了令人印象深刻的0.997准确率[26]。通过提示工程,他们使LLMs能够应对多样化的钓鱼攻击策略。此外,提示工程还可以提高可解释性,使模型能够向用户提供结构化的推理,增加用户的信任感。
尽管LLMs在钓鱼邮件检测任务中表现出色,但一个关键挑战依然存在:大量参数对模型部署造成了重大障碍,并导致高昂的API调用费用。此外,针对下游任务微调这些大型LLMs需要大量的计算和时间资源。我们的研究重点在于评估小型LLMs在钓鱼邮件检测中的性能。通过微调,这些LLMs可以达到接近大型LLMs的性能,这使它们成为平衡成本和有效性的同时保持可解释性的优秀选择。
3 方法
3.1 问题陈述
我们的研究集中在钓鱼邮件的检测。给定一封钓鱼邮件 EEE,包括其主题 SSS 和正文 BBB,假设我们使用模型 MMM 及其参数 θ\thetaθ 进行识别。我们期望模型输出一个标签 LLL,其中 LLL 表示该邮件是否为钓鱼邮件:
L=M(<S,B>∣θ) L=M(<S, B>|\theta) L=M(<S,B>∣θ)
当使用LLMs进行检测时,LLL 不再是一个标签,而是关于该邮件是否为钓鱼邮件的文本判断,具体为“钓鱼”或“安全”。我们还需要输入一个提示 PPP 来指导模型按照我们的要求输出内容:
L=M(<S,B>∣θ,P) L=M(<S, B>|\theta, P) L=M(<S,B>∣θ,P)
3.2 提示工程
经过指令微调后,LLMs能够遵循人类指令。然而,提示设计仍然显著影响LLMs在特定任务中的表现。我们发现,当简单地要求LLMs输出“钓鱼”或“安全”作为标签时,它们往往无法严格遵守请求的格式,使得提取模型的决策变得困难并降低整体可用性。此外,当指示仅输出一个单词时,LLMs表现出明显的偏差,无论输入如何,都倾向于偏向“钓鱼”或“安全”。我们认为这是因为在要求模型仅输出标签时,与其预训练目标产生了脱节,因为LLMs本质上更适合开放式的生成任务。因此,我们修改了提示策略,首先让LLMs阐述其判断的理由,然后才输出最终答案并用特殊符号括起来,利用模型的自然优势同时确保一致且可提取的结果。
3.3 解释增强微调
预训练-微调范式有效地提高了LLMs在各种下游任务中的能力[8, 27]。我们首先考虑直接使用钓鱼邮件数据集对小型LLMs进行微调,纳入邮件主题 SSS、正文 BBB 和实际标签 LLL。然而,我们发现这种方法在钓鱼检测性能上的改进非常有限。我们认为,虽然生成式LLMs具备强大的开放式文本生成能力和在各种NLP任务中表现出色的泛化能力,但要求它们输出单个单词(“钓鱼”或“安全”)类似于封闭式问答任务,与它们的预训练目标不符。这种缺陷在使用单字标签作为预训练目标时持续存在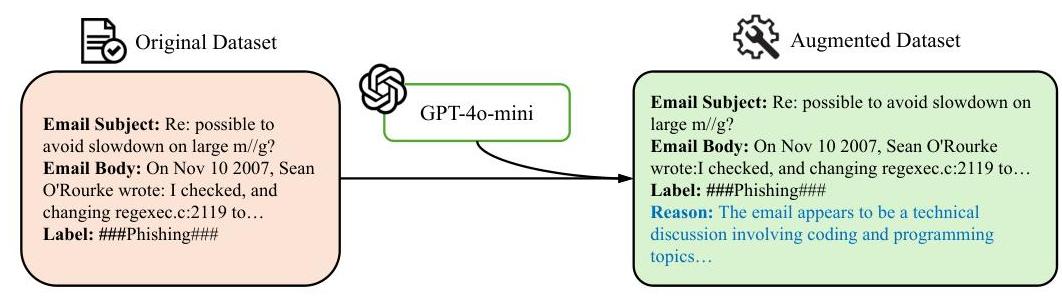
图2:使用GPT-4o-mini为原始钓鱼邮件数据集添加解释
为了解决这个问题,我们通过扩展微调数据目标,将训练目标扩充为包括解释和标签。我们将训练数据中的电子邮件和标签输入GPT-4o-mini模型,如图2所示,指示其生成电子邮件分类的解释,从而创建增强的训练数据。每个增强的训练数据项包含电子邮件主题 SSS、电子邮件正文 BBB、解释 RRR 和标签 LLL。通过解释增强微调,我们的训练数据更接近开放式生成任务,更有利于LLMs微调。此外,通过鼓励LLMs提供解释,我们可以减轻幻觉问题,提高整体检测的可靠性和可解释性。
然后我们使用增强的训练数据对小型LLMs进行微调。由于计算资源的限制,我们不进行全参数微调。相反,我们决定应用低秩适应(LoRA)对LLMs进行微调[28]。LoRA的核心思想是将权重矩阵 WWW 分解为两个较小的矩阵 AAA 和 BBB,使得:
W′=W+ΔW=W+AB W^{\prime}=W+\Delta W=W+A B W′=W+ΔW=W+AB
其中 WWW 是冻结的,ΔW\Delta WΔW 是微调期间的权重更新,B∈Rd×r,A∈Rr×k(r≪min(d,k))B \in \mathbb{R}^{d \times r}, A \in \mathbb{R}^{r \times k}(r \ll \min (d, k))B∈Rd×r,A∈Rr×k(r≪min(d,k))。最终的前向计算按以下方式缩放:
h=Wx+ΔWx=Wx+αrABx h=W x+\Delta W x=W x+\frac{\alpha}{r} A B x h=Wx+ΔWx=Wx+rαABx
其中 α\alphaα 是可调的缩放因子。LoRA通过仅训练低秩分解矩阵(AAA 和 BBB)而不是完整的权重矩阵 WWW 来减少微调期间的内存需求,显著减少了需要存储梯度和优化器状态的参数数量。
3.4 模型集成
由于不同的LLMs可能具备不同的知识和推理能力,我们提出了两种模型集成方法以实现更好的钓鱼检测性能:(1) 置信度评分集成,根据LLMs输出的标记log概率计算置信度评分,并选择置信度最高的答案作为最终答案;(2) 多数投票,选择大多数模型支持的答案作为最终答案。
在前向传播中,最终的logits通过softmax层获得对应不同标记的概率,我们可以通过logprobs形式获取这些概率。序列概率通过指数化每个标记的logprobs并将这些概率相乘,然后取结果的 NNN 次方根得到,其中 NNN 表示序列长度。这个过程有效地计算了标记概率的几何平均值,提供了归一化(LN)置信度评分。
多数投票较为直接。在我们的实验中,我们对三个小型LLMs进行了微调:LLaMA-3.2-3B-Instruct、Phi-4-mini-Instruct和Qwen-2.5-1.5B-Instruct。对于目标电子邮件,如果有两个或更多模型将其分类为钓鱼(或安全),我们采用多数意见作为最终结果。
LN 置信度 =(∏i=1Nexp( logprob i))1/N L N \text { 置信度 }=\left(\prod_{i=1}^{N} \exp \left(\text { logprob }_{i}\right)\right)^{1 / N} LN 置信度 =(i=1∏Nexp( logprob i))1/N
4 实验
在本节中,我们通过实验展示我们方法的有效性。我们使用SpanAssassin数据集进行实验,并在包含1,069封电子邮件的保留测试集上进行评估。小型
表1:纯提示实验结果
| 模型 | 准确率 | F1 | 精确率 | 召回率 |
|---|---|---|---|---|
| LLaMA-3.2-3B-Instruct | 0.587 | 0.543 | 0.934 | 0.922 |
| Phi-4-mini | 0.647 | 0.537 | 0.925 | 0.963 |
| Qwen-2.5-1.5b-Instruct | 0.388 | 0.469 | 0.863 | 0.551 |
所使用的LLMs包括LLaMA-3.2-3B-Instruct、Phi-4-mini-Instruct和Qwen-2.5-1.5B-Instruct,参数分别为30亿、38亿和15亿。推理和微调都可以在一个RTX 3090 GPU上完成,我们限制训练序列和输出序列的长度以避免GPU内存溢出问题。我们首先进行基于提示工程的零样本实验,随后进行解释增强微调和模型集成实验。我们还进行消融研究,以说明通过训练数据中的解释增强带来的显著性能提升。
评估指标:我们报告标准分类指标,包括精确率、召回率和F1得分,计算公式如下:
精确率 =TPTP+FP 召回率 =TPTP+FNF1-得分 =2× 精确率 × 召回率 精确率 + 召回率 \begin{gathered} \text { 精确率 }=\frac{T P}{T P+F P} \\ \text { 召回率 }=\frac{T P}{T P+F N} \\ F 1 \text {-得分 }=2 \times \frac{\text { 精确率 } \times \text { 召回率 }}{\text { 精确率 }+ \text { 召回率 }} \end{gathered} 精确率 =TP+FPTP 召回率 =TP+FNTPF1-得分 =2× 精确率 + 召回率 精确率 × 召回率
其中TP、FP、FN分别表示真正例、假正例和假负例。
4.1 纯提示工程性能
我们选择了LLaMA、Phi和其他小型LLMs进行基线实验。与包含数百亿甚至数千亿参数的LLMs(如GPT-4)相比,这些小型LLMs仅包含约30亿参数。通过提示,我们鼓励LLMs在进行钓鱼邮件判断之前输出其推理,并用特殊符号(用###包裹)包裹其答案。表1展示了我们的实验结果。如果电子邮件是钓鱼邮件,则将其标记为正样本。
从结果可以看出:(1) 在小型模型上应用纯提示性能非常差,准确率低于0.7,F1得分约为0.5;(2) 参数较少的模型表现更差,Qwen 1.5B模型的准确率为0.388,比Phi-4-mini(3.8B)低40%。
4.2 解释增强微调性能
然后我们在选定的LLMs上进行增强微调。我们从SpamAssassin训练集中提取1,000个样本子集,并对该子集进行解释增强。然后我们使用LoRA对这些LLMs进行微调。我们将微调后的小型LLMs结果与传统ML模型如朴素贝叶斯、支持向量机(SVM)和XGBoost进行比较,同时还包括GPT-3.5-Turbo、GPT-4o-mini和LLaMA-3.1-70B-Instruct。在使用传统ML时,我们采用了Sentence-BERT中的paraphrase-MiniLM-L3-v2嵌入模型来嵌入电子邮件,并使用生成的嵌入向量进行训练和测试。结果如表2所示。
经过解释增强微调后,小型LLMs在SpamAssassin数据集上的性能显著提升。LLaMA-3.2-3B-Instruct模型的准确率和F1得分分别从0.587和0.543提升到0.963和0.928,而Phi-4-mini的准确率和F1得分从0.647和0.537提升到0.968和0.944。Qwen-2.5-1.5bInstruct的准确率提高了122%,从0.388提升到0.860。此外,这些小型LLMs在微调后甚至超过了较大的LLMs。例如,Phi-4-mini的准确率比GPT-3.5-Turbo高27.8%,比LLaMA-3.1-70B-Instruct高21.8%,比GPT-4o-mini高2.1%。微调后的LLaMA-3.2-3B-Instruct在准确率和F1得分上也超过了这三个大型LLMs。小型LLMs的性能与XGBoost和SVM相似,但它们可以提供以人类语言形式呈现的可解释判断结果。我们的实验结果表明,微调后的小型LLMs在钓鱼邮件检测能力上得到了显著提升,达到了与已建立的传统机器学习方法相当(在某些情况下甚至超过)的性能指标。
表2:GPT-3.5-Turbo、GPT-4o-mini、传统ML模型和解释增强微调的实验结果。EA代表“解释增强微调”
| 模型 | 准确率 | F1 | 精确率 | 召回率 |
|---|---|---|---|---|
| 朴素贝叶斯 | 0.852 | 0.760 | 0.740 | 0.780 |
| SVM | 0.967 | 0.945 | 0.950 | 0.940 |
| XGBoost | 0.953 | 0.920 | 0.941 | 0.900 |
| GPT-3.5-Turbo | 0.757 | 0.705 | 0.553 | 0.972 |
| GPT-4o-mini | 0.948 | 0.915 | 0.941 | 0.891 |
| LLaMA-3.1-70B-Instruct | 0.801 | 0.635 | 0.693 | 0.586 |
| LLaMA-3.2-3B-Instruct-EA | 0.963 | 0.928 | 0.934 | 0.922 |
| Phi-4-mini-EA | 0.968 | 0.944 | 0.925 | 0.963 |
| Qwen-2.5-1.5b-Instruct-EA | 0.860 | 0.673 | 0.863 | 0.551 |
表3:置信度集成和多数投票的实验结果。
| 模型 | 准确率 | F1 | 精确率 | 召回率 |
|---|---|---|---|---|
| LLaMA-3.2-3B-Instruct-EA | 0.963 | 0.928 | 0.934 | 0.922 |
| Phi-4-mini-EA | 0.968 | 0.944 | 0.925 | 0.963 |
| Qwen-2.5-1.5b-Instruct-EA | 0.860 | 0.673 | 0.863 | 0.551 |
| 置信度集成 | 0.975 | 0.953 | 0.958 | 0.947 |
| 多数投票 | 0.976 | 0.959 | 0.980 | 0.937 |
值得注意的是,这些微调后的紧凑模型在参数数量高出几个数量级的情况下,仍优于大型LLMs,突显了我们方法在优化模型效率以检测钓鱼邮件方面的有效性。
4.3 模型集成
在微调多个LLMs后,我们集成这些模型以充分利用不同LLMs的知识和能力。我们采用了置信度集成和多数投票方法,并将这些集成方法的结果与仅微调模型的结果进行比较,如表3所示。注意,在置信度集成中,我们只使用LLaMA-3.2-3B-Instruct和Phi-4-mini,而在多数投票中,我们包括所有三个小型LLMs。
实验结果表明,置信度集成和多数投票进一步将准确率提高到约0.975,F1得分分别达到0.953和0.959。通过模型集成,我们进一步提高了LLMs在钓鱼邮件检测中的能力和稳定性。然而,与微调带来的收益相比,集成带来的改进幅度相对有限。
4.4 消融研究
在本节中,我们将讨论解释增强对数据的有效性,以提高小型LLMs在检测钓鱼邮件方面的能力。我们的核心理念是通过为电子邮件分类添加解释来增强微调数据,从而使微调数据的模式更接近于LLMs适应的开放式文本生成模式。为了验证我们的方法,我们直接使用没有解释增强的数据对LLMs进行微调,并在测试集上进行实验。我们的实验结果如表4所示。
我们的实验表明,如果没有微调数据中的解释,最终预测结果会显著下降。LLaMA-3.2-3B-Instruct模型的准确率下降了40.7%,其F1得分从0.928骤降至0.219。Qwen-2.5-1.5B-Instruct的准确率和F1得分分别下降了36.4%和26.0%。Phi-4-mini表现出了相对稳健的性能,但其准确率和F1得分仍分别下降了15.1%和27.1%。总体而言,通过消融研究,我们发现解释增强对微调效果有显著影响,因为它将我们的钓鱼邮件检测数据集从封闭形式预测数据集转变为开放式生成数据集。
表4:使用和不使用解释增强微调的实验结果。EA代表“解释增强微调”
| 模型 | 准确率 | F1 | 精确率 | 召回率 |
|---|---|---|---|---|
| LLaMA-3.2-3B-Instruct-EA | 0.963 | 0.928 | 0.934 | 0.922 |
| Phi-4-mini-EA | 0.968 | 0.944 | 0.925 | 0.963 |
| Qwen-2.5-1.5b-Instruct-EA | 0.860 | 0.673 | 0.863 | 0.551 |
| LLaMA-3.2-3B-Instruct-no-EA | 0.571 | 0.219 | 0.221 | 0.216 |
| Phi-4-mini-EA-no-EA | 0.822 | 0.688 | 0.621 | 0.771 |
| Qwen-2.5-1.5b-Instruct-no-EA | 0.547 | 0.498 | 0.376 | 0.735 |
5 局限性
我们的方法有效提升了小型LLMs在钓鱼邮件检测任务中的能力,实现了超过LLaMA-3.1-70B-Instruct等模型的性能。然而,受限于时间和实验资源,我们的研究仍存在以下局限性:
- 数据集:由于时间和计算资源的限制,我们仅在SpamAssassin数据集上进行了实验。在其他数据集上进行额外实验可以进一步证明我们方法的有效性。
-
- 可迁移性研究:我们未考虑方法的可迁移性。鉴于参数规模较大的LLMs可能在可迁移性方面具有优势,我们需要设计方法进一步提高小型LLMs的可迁移性。
-
- 可量化成本比较:尽管直观上使用小型LLMs进行推理的成本较低,但我们并未具体量化使用小型LLMs进行检测的成本节约。
6 结论
在这项研究中,我们探讨了使用小型LLMs进行钓鱼邮件检测的可行性。虽然直接使用这些小型LLMs会导致较差的检测性能,我们设计了一个逐步改善其在钓鱼检测任务中性能的过程。通过使用提示工程标准化模型输出格式并鼓励模型输出其分析背后的推理,我们首先获得了带有解释的格式化答案。随后,我们通过解释增强微调显著提升了小型LLMs的钓鱼邮件检测能力,达到了与主流机器学习方法和参数量大几十倍的LLMs相当甚至更高的性能。最后,我们通过模型集成进一步提升了检测性能。总之,我们的研究表明,高效地使用小型LLMs执行钓鱼邮件检测任务是可行的,并且可以从这些小型LLMs中获得高性能和可解释的检测结果。
参考文献
[1] Mehran Sahami, Susan Dumais, David Heckerman, and Eric Horvitz. 垃圾邮件过滤的贝叶斯方法。proc aaai, 1998.
[2] H. Drucker, Donghui Wu, and V.N. Vapnik. 用于垃圾邮件分类的支持向量机。IEEE Transactions on Neural Networks, 10(5):1048-1054, 1999.
[3] Saeed Abu-Nimeh, Dario Nappa, Xinlei Wang, and Suku Nair. 针对钓鱼检测的机器学习技术比较。ACM, 2007.
[4] Nguyet Quang Do, Ali Selamat, Ondrej Krejcar, Enrique Herrera-Viedma, and Hamido Fujita. 钓鱼检测的深度学习:分类法、当前挑战和未来方向。IEEE Access, 10:36429-36463, 2022.
[5] Cameron McGinley and Sergio A. Salinas Monroy. 针对钓鱼邮件分类的卷积神经网络优化。2021 IEEE International Conference on Big Data (Big Data), pages 5609-5613, 2021.
[6] Sohan Sarkar, Ankit Yadav, and T. Balachander. 使用人工智能和机器学习进行邮件钓鱼检测。International Conference on Deep Sciences for Computing and Communications, 2024.
[7] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 注意力就是你所需要的。Advances in neural information processing systems, 30, 2017.
[8] Jacob Devlin, Ming Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: 预训练深度双向变压器以理解语言。ArXiv, abs/1810.04805, 2019.
[9] OpenAI. 推出ChatGPT, https://openai.com/index/chatgpt, 2022.
[10] OpenAI. GPT-4, https://openai.com/index/gpt-4/, 2022.
[11] Ngoc Tuong Vy Nguyen, Felix D Childress, and Yunting Yin. 基于辩论驱动的多智能体LLMs进行钓鱼邮件检测。2025.
[12] Naser Abdullah Alam. 钓鱼邮件数据集, https://www.kaggle.com/datasets/naserabdullahalam/phishing-email-dataset, 2024.
[13] Meta. 推出Llama 3.1, https://ai.meta.com/blog/meta-llama-3-1, 2024.
[14] Meta. Llama 3.2, https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices, 2024.
[15] Microsoft, Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, and Vishrav Chaudhary. Phi-4-mini技术报告:通过混合LoRA实现紧凑而强大的多模态语言模型。2025.
[16] Qwen Team. 推出Qwen, https://qwenlm.github.io/blog/qwen, 2024.
[17] OpenAI. GPT-4o-mini, https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence, 2024.
[18] Ion Androutsopoulos, John Koutsias, Konstantinos V Chandrinos, and Constantine D Spyropoulos. 使用个人电子邮件的朴素贝叶斯和关键词反垃圾邮件过滤的实验比较。Proceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval, pages 160-167, 2000.
[19] Ion Androutsopoulos, John Koutsias, Konstantinos V Chandrinos, George Paliouras, and Constantine D Spyropoulos. 朴素贝叶斯反垃圾邮件过滤评估。arXiv preprint cs/0006013, 2000.
[20] Harris Drucker, Donghui Wu, and Vladimir N Vapnik. 用于垃圾邮件分类的支持向量机。IEEE Transactions on Neural networks, 10(5):1048-1054, 1999.
[21] Xavier Carreras and Lluis Marquez. 提升树用于反垃圾邮件电子邮件过滤。arXiv preprint cs/0109015, 2001.
[22] Pradeep Kumar Roy, Jyoti Prakash Singh, and Snehasish Banerjee. 使用深度学习过滤SMS垃圾邮件。Future Generation Computer Systems, 102:524-533, 2020.
[23] Yanhui Guo, Zelal Mustafaoglu, and Deepika Koundal. 使用双向变压器和机器学习分类器算法进行垃圾邮件检测。journal of Computational and Cognitive Engineering, 2(1):5-9, 2023.
[24] Washington Cunha, Leonardo Rocha, and Marcos André Gonçalves. 自动文本分类的彻底基准测试:从传统方法到大型语言模型。arXiv preprint arXiv:2504.01930, 2025.
[25] Fredrik Heiding, Bruce Schneier, Arun Vishwanath, Jeremy Bernstein, and Peter S Park. 设计和检测使用大型语言模型的钓鱼邮件。IEEE Access, 2024.
[26] Takashi Koide, Naoki Fukushi, Hiroki Nakano, and Daiki Chiba. Chatspamdetector: 利用大型语言模型进行有效的钓鱼邮件检测。arXiv preprint arXiv:2402.18093, 2024.
[27] Alec Radford and Karthik Narasimhan. 通过生成预训练改进语言理解。2018.
[28] Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. LoRA: 大型语言模型的低秩适应。2021.
参考论文:https://arxiv.org/pdf/2505.00034

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 15
15 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)