
基于HRNet模型的跌倒检测系统设计与实现
这样PyTorch使用者不需要为每一种架构的网络定制不同的反向传播算法,可以很轻松地利用PyTorch的函数,自动进行反向传播算法,从而计算每一个自动微分变量的梯度信息,很大程度减少了编程的工作量和学习深度学习的难度。的领域上在跌倒检测系统的方面上有着卓越的成效,总体上跌倒检测系统取得了显著的进步,尤其突出的是基于卷积神经网络的学习特征已经可以大部分替代早期手工特征 的识别方法,并且可以很大程度上
收藏关注不迷路!!
🌟文末获取源码+数据库🌟
感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
前言
随着技术不断发展,人们逐渐将侧重点逐渐放到了计算机视觉这个研究方向,而在这一重要领域,跌倒检测系统尤为热门并且也取得了相当程度上的发展。但是这也有着局限性,因为需要识别的图像经常受到数中因素 影响从而导致准确率下降,所以早期基于手工特征的跌倒检测系统的方法也无法获得足以让人们满意的结果。
随着越来越多人逐渐发现,在深度学习的领域上在跌倒检测系统的方面上有着卓越的成效,总体上跌倒检测系统取得了显著的进步,尤其突出的是基于卷积神经网络的学习特征已经可以大部分替代早期手工特征 的识别方法,并且可以很大程度上实现端到端的优化,成为了目前的主流方向。
但是尽管卷积神经网络特征提取方法取得了较大的进展,但是它仍然有着自己的局限性。当使用到实际时,仍 然有着许多的问题在很大程度上降低模型判断的准确性。比如目前的主要研究方向就是掌握模型在精度与速度之间的平衡,其次是考虑量化误差与优化矛盾在其中的重要性。这些都是实现跌倒检测系统的关键问题。为了解 决并完善这些问题,本文将详细展开研究工作。
详细视频演示
文章底部名片,联系我看更详细的演示视频
一、项目介绍
系统能够实现跌倒检测、危机信息上传、用户管理、数据统计、后台管理等功能。通过移动端监护人可以实时查看被监护者的状态,及时对危机进行处理。
基于HRNet模型的跌倒检测系统模块通常包括以下功能和组件:
1.数据采集和预处理:这一部分涉及采集和准备用于训练和测试的数据集,包括包含跌倒和非跌倒情况的图像或视频。
2.HRNet模型:HRNet是高分辨率网络的缩写,它是一种用于图像处理任务的深度学习模型,特别适用于姿势估计和关键点检测。在跌倒检测系统中,HRNet模型用于分析输入图像或视频,以检测可能的跌倒事件。
3.特征提取:HRNet模型通常用于提取图像中的关键点和姿势信息,这有助于系统识别跌倒事件。
4.检测和分类:系统将HRNet提取的信息输入到分类器中,以判断图像中是否存在跌倒事件。这可以是二元分类(跌倒/非跌倒)或多类别分类(不同类型的跌倒事件)。
5.实时监测:系统通常需要实时监测图像或视频流,以及时检测并响应跌倒事件。
6.报警和通知:如果检测到跌倒事件,系统可能会触发警报或通知,以通知相关人员或机构。
7.用户界面:一般会有一个用户界面,允许用户配置系统参数、查看历史记录和监控实时数据。
————————————————
二、功能介绍
系统能够实现跌倒检测、危机信息上传、用户管理、数据统计、后台管理等功能。通过移动端监护人可以实时查看被监护者的状态,及时对危机进行处理。
基于HRNet模型的跌倒检测系统模块通常包括以下功能和组件:
1.数据采集和预处理:这一部分涉及采集和准备用于训练和测试的数据集,包括包含跌倒和非跌倒情况的图像或视频。
2.HRNet模型:HRNet是高分辨率网络的缩写,它是一种用于图像处理任务的深度学习模型,特别适用于姿势估计和关键点检测。在跌倒检测系统中,HRNet模型用于分析输入图像或视频,以检测可能的跌倒事件。
3.特征提取:HRNet模型通常用于提取图像中的关键点和姿势信息,这有助于系统识别跌倒事件。
4.检测和分类:系统将HRNet提取的信息输入到分类器中,以判断图像中是否存在跌倒事件。这可以是二元分类(跌倒/非跌倒)或多类别分类(不同类型的跌倒事件)。
5.实时监测:系统通常需要实时监测图像或视频流,以及时检测并响应跌倒事件。
6.报警和通知:如果检测到跌倒事件,系统可能会触发警报或通知,以通知相关人员或机构。
7.用户界面:一般会有一个用户界面,允许用户配置系统参数、查看历史记录和监控实时数据。
HRNet模型采用PyTorch框架实现,PyTorch借助自动微分变量(autograd variable)来实现动态计算图,无论一个计算过程多么复杂,系统都会自动构造一张计算图来记录所有的运算过程。这样PyTorch使用者不需要为每一种架构的网络定制不同的反向传播算法,可以很轻松地利用PyTorch的函数,自动进行反向传播算法,从而计算每一个自动微分变量的梯度信息,很大程度减少了编程的工作量和学习深度学习的难度。
具体搭建如下:
HRNet是一种用于高分辨率图像分割的神经网络结构,使用PyTorch可以轻松地实现这个模型。
具体而言,可以通过以下步骤来实现HRNet:
1 安装PyTorch:首先,需要在计算机上安装PyTorch。可以在PyTorch官方网站上下载最新的PyTorch版本,并根据指示进行安装。
2 下载HRNet代码库:可以在GitHub上下载HRNet代码库。将HRNet代码库下载到本地计算机上。加载HRNet模型:使用PyTorch中的torchvision模块,可以轻松地加载HRNet模型。在HRNet代码库中的models文件夹中可以找到HRNet的各种模型。
3 配置HRNet模型:HRNet模型可以使用不同的配置进行训练和测试。可以在HRNet代码库中的config文件夹中找到各种配置文件。
4 加载数据:使用PyTorch中的DataLoader模块,可以加载用于训练和测试HRNet模型的数据集。
5 训练HRNet模型:使用PyTorch中的torch.nn模块和torch.optim模块,可以训练HRNet模型。
6 测试HRNet模型:使用训练好的HRNet模型进行图像分割的测试。可以将测试图像传递给HRNet模型,然后将模型输出与真实标签进行比较,以评估模型的性能。
7需要注意的是,HRNet是一种复杂的模型,训练和测试过程可能需要很长时间,并且需要大量的计算资源。
三、核心代码
部分代码:
import argparse
import platform
import shutil
import time
from numpy import random
import argparse
import os
import sys
from pathlib import Path
import cv2
import numpy as np
from PyQt5.QtCore import *
from PyQt5.QtWidgets import *
from PyQt5.QtGui import *
from PyQt5 import QtCore, QtGui, QtWidgets
import os
import sys
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.augmentations import letterbox
from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr,
increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, time_sync
import numpy as np
import time
import cv2
from SimpleHRNet import SimpleHRNet
import torch
import numpy as np
from misc.visualization import draw_points, draw_skeleton, draw_points_and_skeleton, joints_dict, check_video_rotation
from misc.utils import find_person_id_associations
def load_model(
weights=ROOT / 'best.pt', # model.pt path(s)
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
# Load model
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data)
stride, names, pt, jit, onnx, engine = model.stride, model.names, model.pt, model.jit, model.onnx, model.engine
# Half
half &= (pt or jit or onnx or engine) and device.type != 'cpu' # FP16 supported on limited backends with CUDA
if pt or jit:
model.model.half() if half else model.model.float()
return model, stride, names, pt, jit, onnx, engine
#
def run(model, img, stride, pt,
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.5, # confidence threshold
iou_thres=0.05, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
half=False, # use FP16 half-precision inference
):
cal_detect = []
device = select_device(device)
names = model.module.names if hasattr(model, 'module') else model.names # get class names
# Set Dataloader
im = letterbox(img, imgsz, stride, pt)[0]
# Convert
im = im.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
im = np.ascontiguousarray(im)
im = torch.from_numpy(im).to(device)
im = im.half() if half else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
pred = model(im, augment=augment)
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
# Process detections
for i, det in enumerate(pred): # detections per image
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], img.shape).round()
# Write results
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
label = f'{names[c]}'
cal_detect.append([label, xyxy,float(conf)])
return cal_detect
def det_yolov5v6(info1):
# 定义检测函数
def HRNet(frame, model, prev_boxes, prev_pts, prev_person_ids, next_person_id):
pts = model.predict(frame)
boxes, pts = pts
if len(pts) > 0:
if prev_pts is None and prev_person_ids is None:
person_ids = np.arange(next_person_id, len(pts) + next_person_id, dtype=np.int32)
next_person_id = len(pts) + 1
else:
boxes, pts, person_ids = find_person_id_associations(
boxes=boxes, pts=pts, prev_boxes=prev_boxes, prev_pts=prev_pts, prev_person_ids=prev_person_ids,
next_person_id=next_person_id, pose_alpha=0.2, similarity_threshold=0.4, smoothing_alpha=0.1,
)
next_person_id = max(next_person_id, np.max(person_ids) + 1)
else:
person_ids = np.array((), dtype=np.int32)
prev_boxes = boxes.copy()
prev_pts = pts.copy()
prev_person_ids = person_ids
for i, (pt, pid) in enumerate(zip(pts, person_ids)):
frame = draw_points_and_skeleton(frame, pt, joints_dict()['coco']['skeleton'], person_index=pid,
points_color_palette='gist_rainbow', skeleton_color_palette='jet',
points_palette_samples=10)
return frame
# 导入模型
hrnet_m = 'HRNet'
hrnet_c = 32 # hrnet parameters - number of channels (if model is HRNet)
hrnet_j = 17 # hrnet parameters - number of joints
yolo_model_def = "./models/detectors/yolo/config/yolov3.cfg"
yolo_class_path = "./models/detectors/yolo/data/coco.names"
yolo_weights_path = "./models/detectors/yolo/weights/yolov3.weights"
# 初始化参数
prev_boxes = None
prev_pts = None
prev_person_ids = None
next_person_id = 0
# 加载模型
HRNetmodel = SimpleHRNet(c=hrnet_c,
nof_joints=hrnet_j,
checkpoint_path="./weights/pose_hrnet_w32_256x192.pth",
model_name=hrnet_m,
resolution=(256, 192),
multiperson=True,
yolo_model_def=yolo_model_def,
yolo_class_path=yolo_class_path,
yolo_weights_path=yolo_weights_path,
return_bounding_boxes=True,
device=torch.device("cuda:0"))
global model, stride, names, pt, jit, onnx, engine
if info1[-3:] in ['jpg','png','jpeg','tif','bmp']:
image = cv2.imread(info1) # 读取识别对象
try:
results = run(model, image, stride, pt) # 识别, 返回多个数组每个第一个为结果,第二个为坐标位置
for i in results:
box = i[1]
p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
color = [255,0,0]
if i[0] == 'fall':
color = [0,0,255]
cv2.putText(image, 'fall ' + str(i[2])[:4],
(int(box[0]), int(box[1]) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 2)
ui.printf(str(time.strftime('%Y.%m.%d %H:%M:%S ', time.localtime(time.time()))) + '警告!检测人员跌倒')
cv2.rectangle(image, p1, p2, color, thickness=3, lineType=cv2.LINE_AA)
except:
pass
image = HRNet(image, HRNetmodel, prev_boxes, prev_pts, prev_person_ids, next_person_id)
ui.showimg(image)
if info1[-3:] in ['mp4','avi']:
capture = cv2.VideoCapture(info1)
while True:
_, image = capture.read()
if image is None:
break
try:
results = run(model, image, stride, pt) # 识别, 返回多个数组每个第一个为结果,第二个为坐标位置
for i in results:
box = i[1]
p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
if i[0] == 'fall':
color = [0, 0, 255]
cv2.putText(image, 'fall ' + str(i[2])[:4],
(int(box[0]), int(box[1]) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 2)
ui.printf(str(time.strftime('%Y.%m.%d %H:%M:%S ', time.localtime(time.time()))) + '警告!检测人员跌倒')
cv2.rectangle(image, p1, p2, color, thickness=3, lineType=cv2.LINE_AA)
except:
pass
image = HRNet(image, HRNetmodel, prev_boxes, prev_pts, prev_person_ids, next_person_id)
ui.showimg(image)
QApplication.processEvents()
class Thread_1(QThread): # 线程1
def __init__(self,info1):
super().__init__()
self.info1=info1
self.run2(self.info1)
def run2(self, info1):
result = []
result = det_yolov5v6(info1)
class Ui_MainWindow(object):
def setupUi(self, MainWindow):
MainWindow.setObjectName("MainWindow")
MainWindow.resize(1280, 960)
MainWindow.setStyleSheet("background-image: url(\"./template/carui.png\")")
self.centralwidget = QtWidgets.QWidget(MainWindow)
self.centralwidget.setObjectName("centralwidget")
self.label = QtWidgets.QLabel(self.centralwidget)
self.label.setGeometry(QtCore.QRect(168, 60, 491, 71))
self.label.setAutoFillBackground(False)
self.label.setStyleSheet("")
self.label.setFrameShadow(QtWidgets.QFrame.Plain)
self.label.setAlignment(QtCore.Qt.AlignCenter)
self.label.setObjectName("label")
self.label.setStyleSheet("font-size:50px;font-weight:bold;font-family:SimHei;background:rgba(255,255,255,0);")
self.label_2 = QtWidgets.QLabel(self.centralwidget)
self.label_2.setGeometry(QtCore.QRect(40, 188, 751, 501))
self.label_2.setStyleSheet("background:rgba(255,255,255,1);")
self.label_2.setAlignment(QtCore.Qt.AlignCenter)
self.label_2.setObjectName("label_2")
self.textBrowser = QtWidgets.QTextBrowser(self.centralwidget)
self.textBrowser.setGeometry(QtCore.QRect(73, 746, 851, 174))
self.textBrowser.setStyleSheet("background:rgba(0,0,0,0);")
self.textBrowser.setObjectName("textBrowser")
self.pushButton = QtWidgets.QPushButton(self.centralwidget)
self.pushButton.setGeometry(QtCore.QRect(1020, 750, 150, 40))
self.pushButton.setStyleSheet("background:rgba(53,142,255,1);border-radius:10px;padding:2px 4px;")
self.pushButton.setObjectName("pushButton")
self.pushButton_2 = QtWidgets.QPushButton(self.centralwidget)
self.pushButton_2.setGeometry(QtCore.QRect(1020, 810, 150, 40))
self.pushButton_2.setStyleSheet("background:rgba(53,142,255,1);border-radius:10px;padding:2px 4px;")
self.pushButton_2.setObjectName("pushButton_2")
self.pushButton_3 = QtWidgets.QPushButton(self.centralwidget)
self.pushButton_3.setGeometry(QtCore.QRect(1020, 870, 150, 40))
self.pushButton_3.setStyleSheet("background:rgba(53,142,255,1);border-radius:10px;padding:2px 4px;")
self.pushButton_3.setObjectName("pushButton_2")
MainWindow.setCentralWidget(self.centralwidget)
self.retranslateUi(MainWindow)
QtCore.QMetaObject.connectSlotsByName(MainWindow)
def retranslateUi(self, MainWindow):
_translate = QtCore.QCoreApplication.translate
MainWindow.setWindowTitle(_translate("MainWindow", "HRNet跌倒检测系统"))
self.label.setText(_translate("MainWindow", "HRNet跌倒检测系统"))
self.label_2.setText(_translate("MainWindow", "请点击以添加对象"))
self.pushButton.setText(_translate("MainWindow", "选择文件"))
self.pushButton_2.setText(_translate("MainWindow", "开始识别"))
self.pushButton_3.setText(_translate("MainWindow", "停止识别"))
# 点击文本框绑定槽事件
self.pushButton.clicked.connect(self.openfile)
self.pushButton_2.clicked.connect(self.click_1)
self.pushButton_3.clicked.connect(self.handleCalc3)
def openfile(self):
global sname, filepath
fname = QFileDialog()
fname.setAcceptMode(QFileDialog.AcceptOpen)
fname, _ = fname.getOpenFileName()
if fname == '':
return
filepath = os.path.normpath(fname)
sname = filepath.split(os.sep)
ui.printf("当前选择的文件路径是:%s" % filepath)
def handleCalc3(self):
os._exit(0)
def printf(self,text):
self.textBrowser.append(text)
self.cursor = self.textBrowser.textCursor()
self.textBrowser.moveCursor(self.cursor.End)
QtWidgets.QApplication.processEvents()
def showimg(self,img):
global vid
img2 = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
_image = QtGui.QImage(img2[:], img2.shape[1], img2.shape[0], img2.shape[1] * 3,
QtGui.QImage.Format_RGB888)
n_width = _image.width()
n_height = _image.height()
if n_width / 500 >= n_height / 400:
ratio = n_width / 800
else:
ratio = n_height / 800
new_width = int(n_width / ratio)
new_height = int(n_height / ratio)
new_img = _image.scaled(new_width, new_height, Qt.KeepAspectRatio)
self.label_2.setPixmap(QPixmap.fromImage(new_img))
def click_1(self):
global filepath
try:
self.thread_1.quit()
except:
pass
self.thread_1 = Thread_1(filepath) # 创建线程
self.thread_1.wait()
self.thread_1.start() # 开始线程
if __name__ == "__main__":
global model, stride, names, pt, jit, onnx, engine
model, stride, names, pt, jit, onnx, engine = load_model() # 加载模型
app = QtWidgets.QApplication(sys.argv)
MainWindow = QtWidgets.QMainWindow()
ui = Ui_MainWindow()
ui.setupUi(MainWindow)
MainWindow.show()
sys.exit(app.exec_())
四、效果图
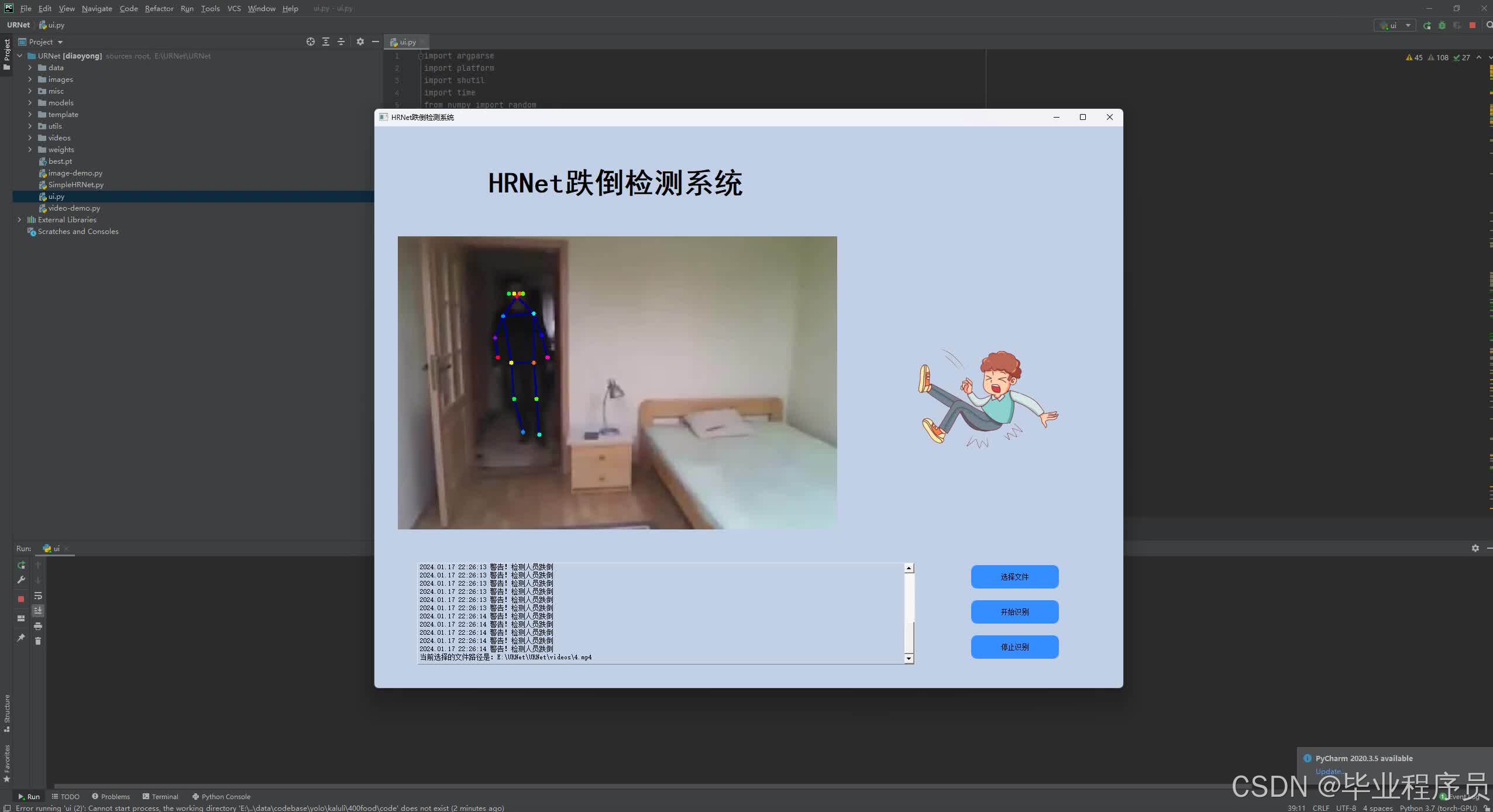
五、文章目录
目 录
1 绪 论 1
1.1 选题的背景 1
1.2 国内外研究现状 1
1.3 选题的目的和意义 1
1.4主要研究内容 3
2 相关技术介绍 5
2.1 卷积神经网络 5
2.2 系统开发相关技术 9
3 数据获取及预处理 14
3.1 数据集的获取及简介 14
3.2 数据预处理 17
4 模型训练与评估 18
4.1 模型选择 14
4.2 模型训练 17
4.3 模型评估 17
5 模型优化 18
5.1 优化器选择 14
5.2 效果对比分析 17
6 系统部署 19
6.1 需求分析 14
6.2 系统设计与实现 17
6.3 系统测试 17
7 总结与展望 29
7.1 总结 29
7.2 展望 29
参考文献 30
致 谢 33
六 、源码获取
下方名片联系我即可!!
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)