
Milvus二进制向量
二进制向量是一种将高维浮点向量转换为仅包含0和1的二进制形式的数据表示方法,具有高效存储、快速计算和固定长度等特点。它通过压缩向量大小和降低存储计算成本,在保留语义信息的同时,适用于对非关键特征精度要求不高的场景。二进制向量在搜索引擎、推荐系统等大规模人工智能系统中广泛应用,有助于实时处理海量数据,降低延迟和计算成本。此外,它在资源受限的移动设备和嵌入式系统中也表现出色,能够实现复杂的人工智能功能
二进制向量是一种特殊的数据表示形式,它将传统的高维浮点向量转换成只包含 0 和 1 的二进制向量。这种转换不仅压缩了向量的大小,还降低了存储和计算成本,同时保留了语义信息。当对非关键特征的精度要求不高时,二进制向量可以有效保持原始浮点向量的大部分完整性和实用性。
二进制向量有着广泛的应用,尤其是在计算效率和存储优化至关重要的情况下。在搜索引擎或推荐系统等大规模人工智能系统中,实时处理海量数据是关键所在。通过减小向量的大小,二进制向量有助于降低延迟和计算成本,而不会明显牺牲准确性。此外,二进制向量在移动设备和嵌入式系统等资源受限的环境中也很有用,因为在这些环境中,内存和处理能力都很有限。通过使用二进制向量,可以在这些受限环境中实现复杂的人工智能功能,同时保持高性能。
二进制矢量概述
二进制向量是一种将复杂对象(如图像、文本或音频)编码为固定长度二进制值的方法。在 Milvus 中,二进制向量通常表示为比特数组或字节数组。例如,一个 8 维二进制向量可以表示为[1, 0, 1, 1, 0, 0, 1, 0] 。
下图显示了二进制向量如何表示文本内容中关键词的存在。在这个例子中,用一个 10 维二进制向量来表示两个不同的文本(文本 1和文本 2),其中每个维度对应词汇表中的一个词:1 表示文本中存在该词,0 表示文本中没有该词。
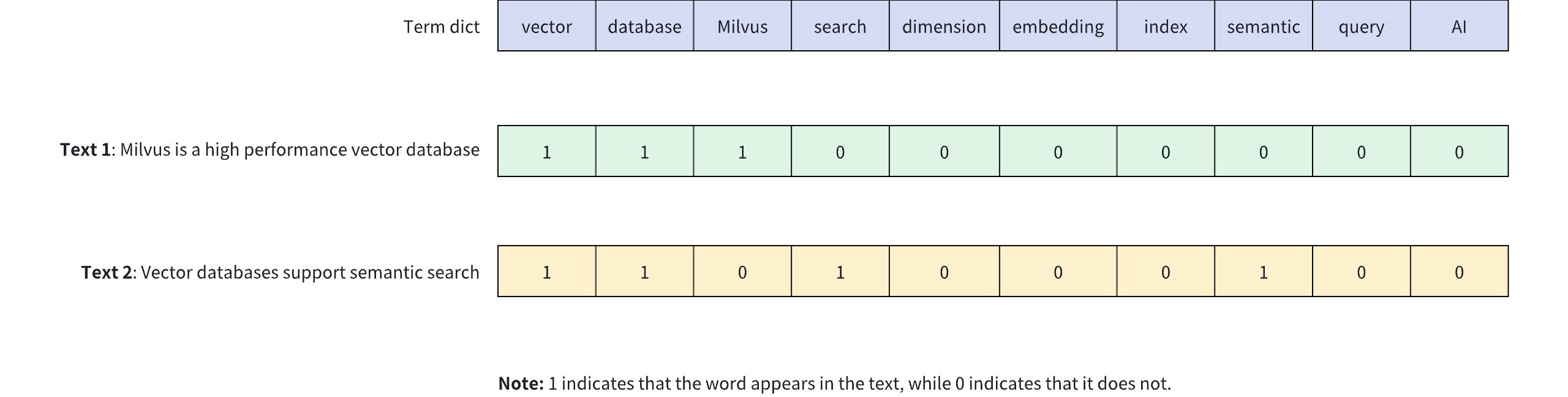
二进制向量
二进制向量具有以下特点:
-
高效存储:每个维度只需 1 位存储空间,大大减少了存储空间。
-
快速计算:使用 XOR 等位运算可以快速计算向量间的相似性。
-
固定长度:无论原始文本的长度如何,向量的长度保持不变,从而使索引和检索更加容易。
-
简单直观:直接反映关键词的存在,适合某些专业检索任务。
二进制向量可以通过各种方法生成。在文本处理中,可以使用预定义的词汇表,根据词的存在设置相应的位。在图像处理中,感知哈希算法(如pHash)可以生成图像的二进制特征。在机器学习应用中,可对模型输出进行二进制化,以获得二进制向量表示。
二进制向量化后,数据可以存储在 Milvus 中,以便进行管理和向量检索。下图显示了基本流程。
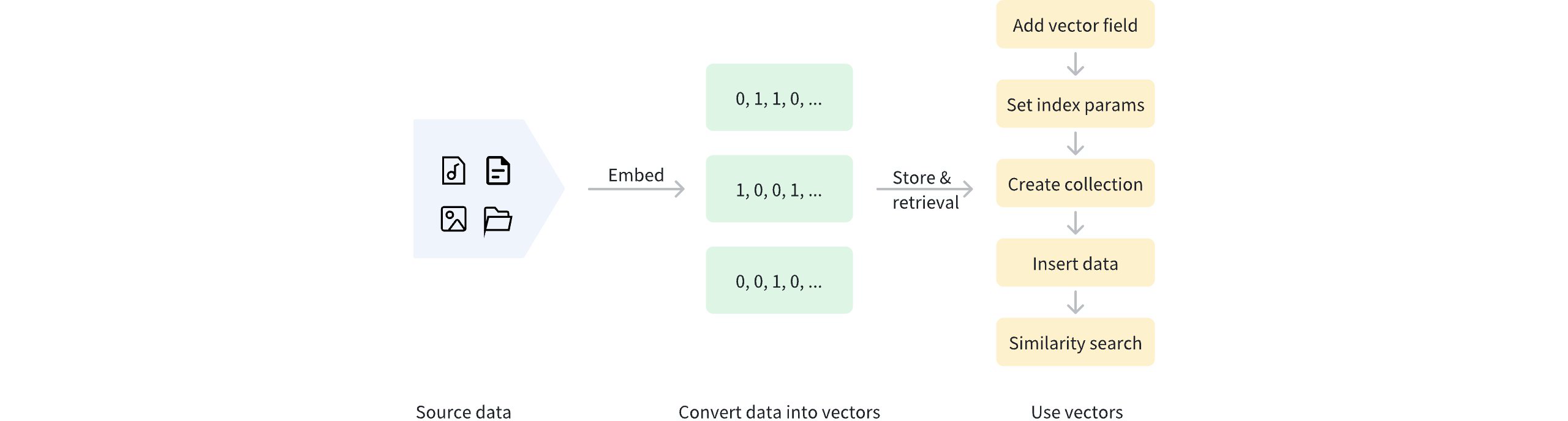
使用二进制向量
虽然二进制向量在特定场景中表现出色,但其表达能力存在局限性,难以捕捉复杂的语义关系。因此,在实际应用场景中,二进制向量通常与其他向量类型一起使用,以平衡效率和表达能力。更多信息,请参阅密集向量和稀疏向量。
使用二进制向量
添加向量场
要在 Milvus 中使用二进制向量,首先要在创建 Collections 时定义一个用于存储二进制向量的向量场。这一过程包括
-
将
datatype设置为支持的二进制向量数据类型,即BINARY_VECTOR。 -
使用
dim参数指定向量的维数。请注意,dim必须是 8 的倍数,因为二进制向量在插入时必须转换成字节数组。每 8 个布尔值(0 或 1)将打包成 1 个字节。例如,如果dim=128,插入时需要一个 16 字节数组。import io.milvus.v2.client.ConnectConfig; import io.milvus.v2.client.MilvusClientV2; import io.milvus.v2.common.DataType; import io.milvus.v2.service.collection.request.AddFieldReq; import io.milvus.v2.service.collection.request.CreateCollectionReq; MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder() .uri("http://localhost:19530") .build()); CreateCollectionReq.CollectionSchema schema = client.createSchema(); schema.setEnableDynamicField(true); schema.addField(AddFieldReq.builder() .fieldName("pk") .dataType(DataType.VarChar) .isPrimaryKey(true) .autoID(true) .maxLength(100) .build()); schema.addField(AddFieldReq.builder() .fieldName("binary_vector") .dataType(DataType.BinaryVector) .dimension(128) .build()); -
在此示例中,添加了一个名为
binary_vector的向量字段,用于存储二进制向量。该字段的数据类型为BINARY_VECTOR,维数为 128。
为向量字段设置索引参数
为了加快搜索速度,必须为二进制向量字段创建索引。索引可以大大提高大规模向量数据的检索效率。
import io.milvus.v2.common.IndexParam;
import java.util.*;
List<IndexParam> indexParams = new ArrayList<>();
Map<String,Object> extraParams = new HashMap<>();
indexParams.add(IndexParam.builder()
.fieldName("binary_vector")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.HAMMING)
.build());
在上面的示例中,使用AUTOINDEX 索引类型为binary_vector 字段创建了名为binary_vector_index 的索引。metric_type 设置为HAMMING ,表示使用汉明距离进行相似性测量。
Milvus 提供多种索引类型,以获得更好的向量搜索体验。AUTOINDEX 是一种特殊的索引类型,旨在平滑向量搜索的学习曲线。有很多索引类型可供您选择。详情请参阅 xxx。
此外,Milvus 还支持二进制向量的其他相似度度量。更多信息,请参阅 "度量类型"。
创建 Collections
二进制向量和索引设置完成后,创建一个包含二进制向量的 Collections。下面的示例使用create_collection 方法创建了一个名为my_collection 的 Collection。
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://localhost:19530")
.build());
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexParams)
.build();
client.createCollection(requestCreate);
插入数据
创建集合后,使用insert 方法添加包含二进制向量的数据。请注意,二进制向量应以字节数组的形式提供,其中每个字节代表 8 个布尔值。
例如,对于 128 维的二进制向量,需要一个 16 字节的数组(因为 128 位 ÷ 8 位/字节 = 16 字节)。下面是插入数据的示例代码:
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.response.InsertResp;
private static byte[] convertBoolArrayToBytes(boolean[] booleanArray) {
byte[] byteArray = new byte[booleanArray.length / Byte.SIZE];
for (int i = 0; i < booleanArray.length; i++) {
if (booleanArray[i]) {
int index = i / Byte.SIZE;
int shift = i % Byte.SIZE;
byteArray[index] |= (byte) (1 << shift);
}
}
return byteArray;
}
List<JsonObject> rows = new ArrayList<>();
Gson gson = new Gson();
{
boolean[] boolArray = {true, false, false, true, true, false, true, true, false, true, false, false, true, true, false, true};
JsonObject row = new JsonObject();
row.add("binary_vector", gson.toJsonTree(convertBoolArrayToBytes(boolArray)));
rows.add(row);
}
{
boolean[] boolArray = {false, true, false, true, false, true, false, false, true, true, false, false, true, true, false, true};
JsonObject row = new JsonObject();
row.add("binary_vector", gson.toJsonTree(convertBoolArrayToBytes(boolArray)));
rows.add(row);
}
InsertResp insertR = client.insert(InsertReq.builder()
.collectionName("my_collection")
.data(rows)
.build());
执行相似性搜索
相似性搜索是 Milvus 的核心功能之一,可以根据向量间的距离快速找到与查询向量最相似的数据。要使用二进制向量执行相似性搜索,请准备好查询向量和搜索参数,然后调用search 方法。
在搜索操作过程中,还必须以字节数组的形式提供二进制向量。确保查询向量的维度与定义dim 时指定的维度相匹配,并且每 8 个布尔值转换为 1 个字节。
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.BinaryVec;
import io.milvus.v2.service.vector.response.SearchResp;
Map<String,Object> searchParams = new HashMap<>();
searchParams.put("nprobe",10);
boolean[] boolArray = {true, false, false, true, true, false, true, true, false, true, false, false, true, true, false, true};
BinaryVec queryVector = new BinaryVec(convertBoolArrayToBytes(boolArray));
SearchResp searchR = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.annsField("binary_vector")
.searchParams(searchParams)
.topK(5)
.outputFields(Collections.singletonList("pk"))
.build());
System.out.println(searchR.getSearchResults());
// Output
//
// [[SearchResp.SearchResult(entity={pk=453444327741536775}, score=0.0, id=453444327741536775), SearchResp.SearchResult(entity={pk=453444327741536776}, score=7.0, id=453444327741536776)]]

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 16
16 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)