
[Spark]PySpark入门学习教程---RDD介绍(2)
一 RDDpyspark.RDD:http://spark.apache.org/docs/latest/api/python/reference/api/pyspark.RDD.html#pyspark.RDD本节将介绍RDD数据结构的常用函数。包括如下内容:创建RDD常用Action操作常用Transformation操作常用PairRDD的转换操作缓存操作共享变量分区操作这些函数中,常用的是
一 RDD
pyspark.RDD SparkRDD
RDD指的是弹性分布式数据集(Resilient Distributed Dataset),它是spark计算的核心。尽管现在都使用 DataFrame、Dataset 进行编程,但是它们的底层依旧是依赖于RDD的。我们来解释一下 RDD 的这几个单词含义。
弹性:在计算上具有容错性,spark是一个计算框架,如果某一个节点挂了,可以自动进行计算之间血缘关系的跟踪分布式:很好理解,hdfs上数据是跨节点的,那么spark的计算也是要跨节点的数据集:可以将数组、文件等一系列数据的集合转换为RDD
RDD 是 Spark 的一个最基本的抽象 (如果你看一下源码的话,你会发现RDD在底层是一个抽象类,抽象类显然不能直接使用,必须要继承它然后实现它内部的一些方法后才可以使用),它代表了不可变的、元素的分区(partition)集合,这些分区可以被并行操作。假设我们有一个包含 300 万个元素的数组,那么我们就可以将这个数组分成 3 份,每一份对应一个分区,每个分区都可以在不同的机器上进行运算,这样就能提高运算效率。
RDD 支持很多操作,比如:map、filter 等等,我们后面会慢慢介绍。当然,RDD在 Spark 的源码是一个类,但是我们后面有时候会把 RDD 和 RDD实例对象 都叫做 RDD,没有刻意区分,心里面清楚就可以啦。
大致上可分三大类算子:
1、Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据。
2、Key-Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Key-Value型的数据。
3、Action算子,这类算子会触发SparkContext提交作业。
二 创建RDD
创建RDD主要有两种方式
一个是textFile加载本地或者集群文件系统中的数据,
第二个是用parallelize方法将Driver中的数据结构并行化成RDD。
#从本地文件系统中加载数据
file = "/home/data/hello.txt"
#从集群文件系统中加载数据
#file = "hdfs://localhost:9000/user/hadoop/data.txt"
#也可以省去hdfs://localhost:9000
rdd = sc.textFile(file,3)
rdd.collect()['hello world',
'hello spark',
'spark love jupyter',
'spark love pandas',
'spark love sql']#parallelize将Driver中的数据结构生成RDD,第二个参数指定分区数
rdd = sc.parallelize(range(1,11),2)
rdd.collect()[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]三 常用Transformation操作
Transformation转换操作具有懒惰执行的特性,它只指定新的RDD和其父RDD的依赖关系,只有当Action操作触发到该依赖的时候,它才被计算。


3.1 Value型Transformation算子
import pyspark
conf = pyspark.SparkConf().setMaster("local[4]").setAppName("PySpark_Transformation1")
sc = pyspark.SparkContext(conf=conf)[1] map
# 以下的操作由于是Transform操作,因为我们需要在最后加上一个collect算子用来触发计算。
# 1. map: 和python差不多,map转换就是对每一个元素进行一个映射
rdd = sc.parallelize(range(1, 11), 4)
rdd_map = rdd.map(lambda x: x*2)
print("原始数据:", rdd.collect())
print("扩大2倍:", rdd_map.collect())
# 原始数据: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 扩大2倍: [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]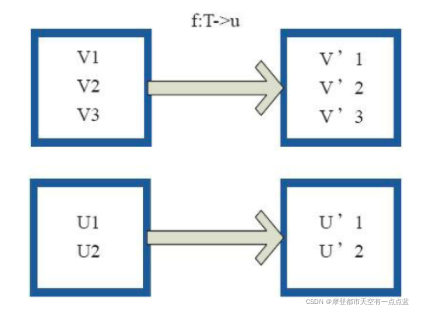
[2] flatMap
# 2. flatMap: 这个相比于map多一个flat(压平)操作,顾名思义就是要把高维的数组变成一维
rdd2 = sc.parallelize(["hello SamShare", "hello PySpark"])
print("原始数据:", rdd2.collect())
print("直接split之后的map结果:", rdd2.map(lambda x: x.split(" ")).collect())
print("直接split之后的flatMap结果:", rdd2.flatMap(lambda x: x.split(" ")).collect())
# 直接split之后的map结果: [['hello', 'SamShare'], ['hello', 'PySpark']]
# 直接split之后的flatMap结果: ['hello', 'SamShare', 'hello', 'PySpark']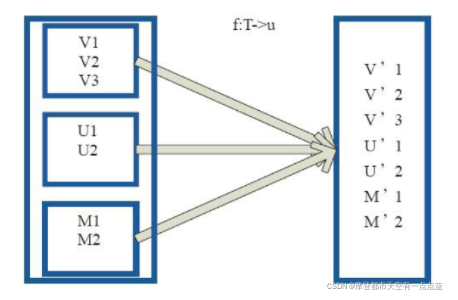
[3] mapPartitions
# mapPartitions: 根据分区内的数据进行映射操作
rdd = sc.parallelize([1, 2, 3, 4], 2)
def f(iterator):
yield sum(iterator)
print(rdd.collect())
print(rdd.mapPartitions(f).collect())
# [1, 2, 3, 4]
# [3, 7]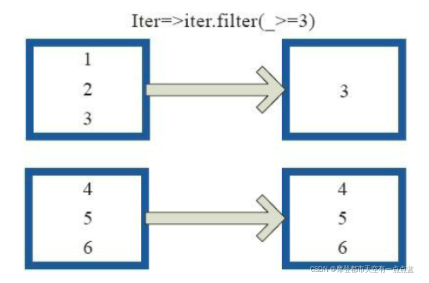
[4] union
# 9. union: 合并两个RDD
rdd = sc.parallelize([1, 1, 2, 3])
print(rdd.union(rdd).collect())
# [1, 1, 2, 3, 1, 1, 2, 3][5] cartesian
# cartesian: 生成笛卡尔积
rdd = sc.parallelize([1, 2])
print(sorted(rdd.cartesian(rdd).collect()))
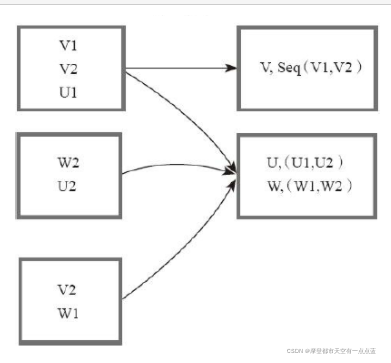
# [(1, 1), (1, 2), (2, 1), (2, 2)] [6] groupByKey
# groupByKey: 按照key来聚合数据
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
print(rdd.collect())
print(sorted(rdd.groupByKey().mapValues(len).collect()))
print(sorted(rdd.groupByKey().mapValues(list).collect()))
# [('a', 1), ('b', 1), ('a', 1)]
# [('a', 2), ('b', 1)]
# [('a', [1, 1]), ('b', [1])]
[7] filter
# 3. filter: 过滤数据
rdd = sc.parallelize(range(1, 11), 4)
print("原始数据:", rdd.collect())
print("过滤奇数:", rdd.filter(lambda x: x % 2 == 0).collect())
# 原始数据: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 过滤奇数: [2, 4, 6, 8, 10]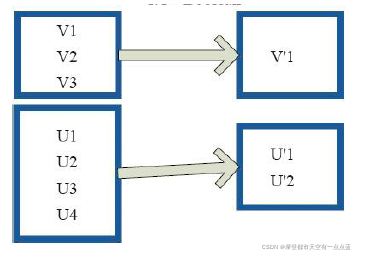
[8] distinct
# distinct: 去重元素
rdd = sc.parallelize([2, 2, 4, 8, 8, 8, 8, 16, 32, 32])
print("原始数据:", rdd.collect())
print("去重数据:", rdd.distinct().collect())
# 原始数据: [2, 2, 4, 8, 8, 8, 8, 16, 32, 32]
# 去重数据: [4, 8, 16, 32, 2] 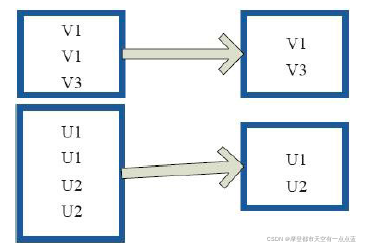
[9] distinct
# subtract: 数据集相减, Return each value in self that is not contained in other.
x = sc.parallelize([("a", 1), ("b", 4), ("b", 5), ("a", 3)])
y = sc.parallelize([("a", 3), ("c", None)])
print(sorted(x.subtract(y).collect()))
# [('a', 1), ('b', 4), ('b', 5)][10] sample
rdd = sc.parallelize(range(1,11),2) # 这里的 2 指的是分区数量
print("原始数据:", rdd.collect())
print("Sample数据:", rdd.sample(False, 0.5, 9).collect())
# 原始数据: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Sample数据: [3, 4, 6, 7, 8, 9]
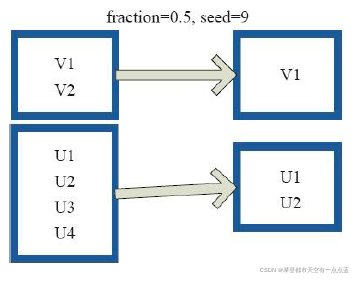
[11] takeSample
rdd = sc.parallelize(range(1,15),2) # 这里的 2 指的是分区数量
print("原始数据:", rdd.collect())
print("taksSample数据:", rdd.takeSample(True, 4, 9))
# 原始数据: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# takeSample数据: [3, 4, 6, 7, 8, 9]
[12] cache、persist
3.2 Key-Value型Transformation算子
[1] mapValues
rdd1 = sc.parallelize([("a", ["apple", "banana", "lemon"]), ("b", ["grapes"])])
print("mapValues:", rdd.mapValues(len).collect())
#mapValues len: [('a', 3), ('b', 1)]
rdd2 = sc.parallelize([("a", [1,2]), ("b", [3,4,5])])
print("mapValues:", rdd2.mapValues(len).collect())
#mapValues sum: [('a', 3), ('b', 1)]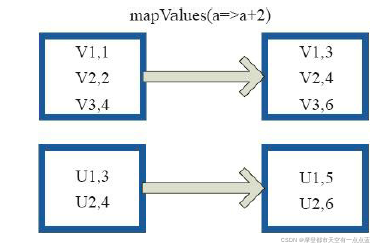
[2] reduceByKey
# reduceByKey: 根据key来映射数据
from operator import add
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
print("原始数据:", rdd.collect())
print("原始数据:", rdd.reduceByKey(add).collect())
# 原始数据: [('a', 1), ('b', 1), ('a', 1)]
# 原始数据: [('b', 1), ('a', 2)]
[3] join | leftOuterJoin | ightOuterJoin
# 16. join:
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2), ("a", 3)])
print(sorted(x.join(y).collect()))
# [('a', (1, 2)), ('a', (1, 3))]
# 17. leftOuterJoin/rightOuterJoin
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2)])
print(sorted(x.leftOuterJoin(y).collect()))
# [('a', (1, 2)), ('b', (4, None))]其他
# 7. sortBy: 根据规则进行排序
tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
print(sc.parallelize(tmp).sortBy(lambda x: x[0]).collect())
print(sc.parallelize(tmp).sortBy(lambda x: x[1]).collect())
# [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
# [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
# subtractByKey 去除x中那些key也在y中的元素
x = sc.parallelize([("a",1),("b",2),("c",3)])
y = sc.parallelize([("a",2),("b",(1,2))])
x.subtractByKey(y).collect()
#[('c', 3)]
# 10. intersection: 取两个RDD的交集,同时有去重的功效
rdd1 = sc.parallelize([1, 10, 2, 3, 4, 5, 2, 3])
rdd2 = sc.parallelize([1, 6, 2, 3, 7, 8])
print(rdd1.intersection(rdd2).collect())
# [1, 2, 3]
# 12. zip: 拉链合并,需要两个RDD具有相同的长度以及分区数量
x = sc.parallelize(range(0, 5))
y = sc.parallelize(range(1000, 1005))
print(x.collect())
print(y.collect())
print(x.zip(y).collect())
# [0, 1, 2, 3, 4]
# [1000, 1001, 1002, 1003, 1004]
# [(0, 1000), (1, 1001), (2, 1002), (3, 1003), (4, 1004)]
# 13. zipWithIndex: 将RDD和一个从0开始的递增序列按照拉链方式连接。
rdd_name = sc.parallelize(["LiLei", "Hanmeimei", "Lily", "Lucy", "Ann", "Dachui", "RuHua"])
rdd_index = rdd_name.zipWithIndex()
print(rdd_index.collect())
# [('LiLei', 0), ('Hanmeimei', 1), ('Lily', 2), ('Lucy', 3), ('Ann', 4), ('Dachui', 5), ('RuHua', 6)]
# 15. sortByKey:
tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
print(sc.parallelize(tmp).sortByKey(True, 1).collect())
# [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]四 常用Action操作
Action操作将触发基于RDD依赖关系的计算。

import os
import pyspark
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("test_SamShare").setMaster("local[4]")
sc = SparkContext(conf=conf)
# 使用 parallelize方法直接实例化一个RDD
rdd = sc.parallelize(range(1,11),4) # 这里的 4 指的是分区数量
rdd.take(100)
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
----------------------------------------------
Action算子解析
----------------------------------------------
# 1. collect: 指的是把数据都汇集到driver端,便于后续的操作
rdd = sc.parallelize(range(0, 5))
rdd_collect = rdd.collect()
print(rdd_collect)
# [0, 1, 2, 3, 4]
# 2. first: 取第一个元素
sc.parallelize([2, 3, 4]).first()
# 2
# 3. collectAsMap: 转换为dict,使用这个要注意了,不要对大数据用,不然全部载入到driver端会爆内存
m = sc.parallelize([(1, 2), (3, 4)]).collectAsMap()
m
# {1: 2, 3: 4}
# 4. reduce: 逐步对两个元素进行操作
rdd = sc.parallelize(range(10),5)
print(rdd.reduce(lambda x,y:x+y))
# 45
# 5. countByKey/countByValue:
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
print(sorted(rdd.countByKey().items()))
print(sorted(rdd.countByValue().items()))
# [('a', 2), ('b', 1)]
# [(('a', 1), 2), (('b', 1), 1)]
# 6. take: 相当于取几个数据到driver端
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
print(rdd.take(5))
# [('a', 1), ('b', 1), ('a', 1)]
# 7. saveAsTextFile: 保存rdd成text文件到本地
text_file = "./data/rdd.txt"
rdd = sc.parallelize(range(5))
rdd.saveAsTextFile(text_file)
# 8. takeSample: 随机取数
rdd = sc.textFile("./test/data/hello_samshare.txt", 4) # 这里的 4 指的是分区数量
rdd_sample = rdd.takeSample(True, 2, 0) # withReplacement 参数1:代表是否是有放回抽样
rdd_sample
# 9. foreach: 对每一个元素执行某种操作,不生成新的RDD
rdd = sc.parallelize(range(10), 5)
accum = sc.accumulator(0)
rdd.foreach(lambda x: accum.add(x))
print(accum.value)全面解析Spark,以及和Python的对接 - 古明地盆 - 博客园 (cnblogs.com) https://www.cnblogs.com/traditional/p/11724876.html
https://www.cnblogs.com/traditional/p/11724876.html

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)