
Python----大模型(大模型相关库)
本文介绍了大模型相关的主流开发库和核心概念。在开发库方面,重点讲解了HuggingFace Transformers、ModelScope、OpenAI API、LangChain、SentenceTransformers和DeepSpeed等工具的功能特点和使用方法。在核心概念部分,详细解析了因果语言模型的原理、不同模型架构的对比、预训练与微调的区别,以及Tokenization技术(特别是BP
一、主流的大模型相关库
1.1、Hugging Face Transformers
Hugging Face Transformers 是一个开源的 Python 库,支持多种预训练的自然语言 处理模型,如 BERT、GPT、T5 等数百个用于不同任务的预训练模型。它可以轻松实 现模型加载、微调、文本生成等功能。
地址:https://github.com/huggingface/transformers
pip install transformers
from transformers import pipeline
# 加载预训练的文本生成模型
generator = pipeline("text-generation", model="./models/iiBcai/gpt2")
# 输入提示语并生成文本
result = generator("中文")
print(result[0]['generated_text'])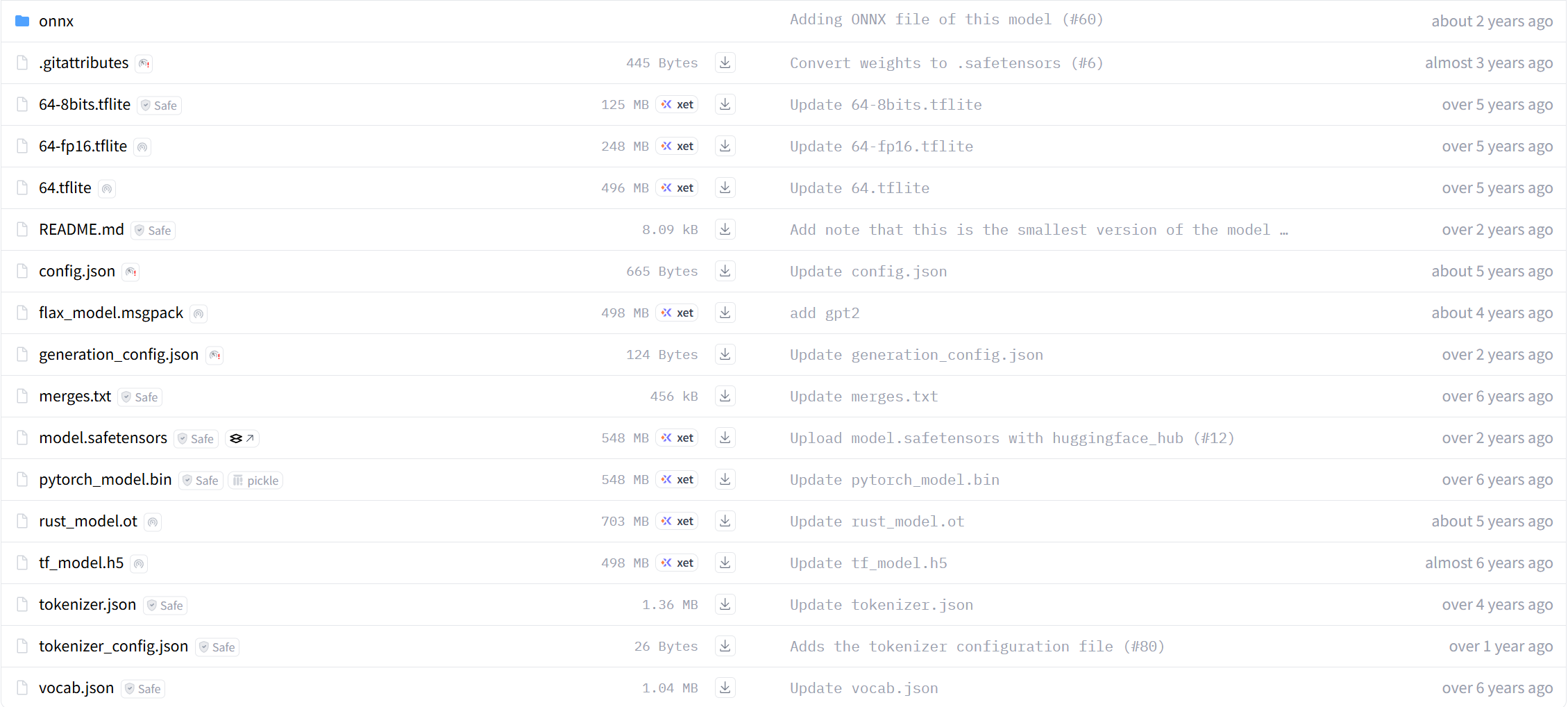
|
文件名/类型 |
描述 |
|
.gitattributes |
Git配置文件,用于指定如何处理特定类型的文件。 |
|
64-8bits.tflite |
TensorFlow Lite模型文件,使用 8位量化 进行优化。 |
|
64-fp16.tflite |
TensorFlow Lite模型文件,使用 FP16浮点数量化 进行优化。 |
|
64.tflite |
TensorFlow Lite模型文件,标准格式。 |
|
README.md |
项目的 README文件,通常包含项目介绍、安装指南等信息。 |
|
config.json |
JSON文件,包含模型的 配置信息,如架构参数和其他元数据。 |
|
flax_model.msgpack |
使用 MessagePack序列化 的Flax模型权重文件。 |
|
generation_config.json |
JSON文件,包含 生成任务的相关配置信息。 |
|
merges.txt |
文本文件,包含 BPE (Byte Pair Encoding) 合并规则,用于分词器。 |
|
model.safetensors |
使用 safetensors库 保存的模型权重文件,确保了模型的安全性和完整性。 |
|
pytorch_model.bin |
PyTorch模型的 二进制权重文件。 |
|
rust_model.ot |
Rust编译后 的模型文件。 |
|
tf_model.h5 |
Keras或TensorFlow模型的 HDF5格式文件。 |
|
tokenizer.json |
JSON文件,包含 分词器的配置信息。 |
|
tokenizer_config.json |
JSON文件,包含 分词器的额外配置信息。 |
|
vocab.json |
JSON文件,包含 词汇表的信息。 |
1.2、魔搭社区
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、 易用、低成本的一站式模型服务产品,让模型应用更简单。
1.3、OpenAI API
OpenAI 提供的 API 可以让开发者访问训练好的大语言模型,如 GPT-3 和 GPT-4,通 过 API 可以进行文本生成、问答、总结等多种任务。
地址:OpenAI
pip install openai
import openai
# 设置 API Key
openai.api_key = 'your-api-key'
# 调用 GPT-4 模型进行文本生成
response = openai.Completion.create(
# 选择的模型问题
engine="text-davinci-003",
# 最大的生成tokens数量
max_tokens=100
)
prompt="Explain the theory of relativity in simple terms.",
# 输出生成的文本
print(response.choices[0].text.strip())1.4、LangChain
LangChain 是一个框架,用于开发由大语言模型驱动的应用程序。它可以帮助开发 者构建更复杂的交互式模型应用,如对话代理、自动化工作流等。LangChain本身并不开发LLMs,它的核心理念是为各种LLMs提供通用的接口, 降低开发者的学习成本,方便开发者快速地开发复杂的LLMs应用
地址:Introduction | 🦜️🔗 LangChain
pip install langchain
import os
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
os.environ["OPENAI_API_KEY"] = API_SECRET_KEY
os.environ["OPENAI_API_BASE"] = BASE_URL
# 初始化OpenAI模型
llm = OpenAI(temperature=0.9)
# 使用模板生成提示语
template = PromptTemplate(
input_variables=["topic"],
template="Write a short poem about {topic}."
)
# 生成并打印结果
print(llm(template.format(topic="the ocean")))1.5、SentenceTransformers
SentenceTransformers 是一个基于 transformers 库的 Python 框架,专门用于句 子和文本嵌入的生成。它可以通过将句子或段落编码成高维向量,实现相似性搜索、 聚类、分类等任务。其核心思想是通过预训练模型(如 BERT、RoBERTa、T5 等) 来生成句子的向量表示,并支持多种语言。
pip install sentence-transformers
from sentence_transformers import SentenceTransformer, util
# 加载预训练模型(BERT-based)
model = SentenceTransformer('all-MiniLM-L6-v2')
# 示例句子
sentences = [
"I love programming.",
"Coding is fun.",
"I enjoy writing software."
]
# 生成句子的嵌入
embeddings = model.encode(sentences)
# 计算第一个句子与其他句子的相似度
similarity_scores = util.pytorch_cos_sim(embeddings[0], embeddings[1:])
print(similarity_scores)1.6、DeepSpeed
DeepSpeed 是微软开源的一个深度学习优化库,专门为大规模模型的训练和推理进 行优化,帮助开发者加速模型的训练过程,降低资源消耗。
pip install deepspeed
二、因果语言模型
因果语言模型 (causal Language Models),也被称为自回归语言模型 (autoregressive language models) 或仅解码器语言模型 (decoder-only language models) ,是一种机器学习模型,旨在根据序列中的前导 token 预测下一个 token 。换句话说,它使用之前生成的 token 作为上下文,一次生成一个 token 的文本。” 因果”方面指的是模型在预测下一个 token 时只考虑过去的上下文(即已生成的 token ),而不考虑任何未来的 token 。
因果语言模型被广泛用于涉及文本补全和生成的各种自然语言处理任务。它们在生成 连贯且具有上下文关联性的文本方面尤其成功,这使得它们成为现代自然语言理解和 生成系统的基础。
|
模型类别 |
主要代表 |
架构特点 |
信息流方向 |
核心优势 |
典型应用场景 |
|
序列到序列模型 |
T5, BART, NLLB |
编码器-解码器 (Encoder-Decoder) 结构。 |
编码器:双向(同时考虑过去和未来上下文) |
擅长将一种序列转换为另一种序列。 |
机器翻译、文本摘要、问答系统、语音识别、代码生成等。 |
|
双向模型 |
BERT, RoBERTa, |
仅编码器 (Encoder-Only) 结构。 |
双向(在整个序列范围内同时访问过去和未来上下文) |
对文本中每个词汇进行深度上下文理解。 |
文本分类、命名实体识别 (NER)、抽取式问答、语义相似度匹配、信息检索等。 |
|
因果语言模型 |
GPT 系列 (GPT-2, GPT-3, |
仅解码器 (Decoder-Only) 结构。 |
严格单向(仅依赖于已生成的历史上下文) |
天生适合文本生成。 |
文本补全与续写、创意写作、代码生成与补全、聊天机器人、内容创作、开放域问答等。 |
预训练 (Pre-training) 和基模型 (Base models)
|
概念 |
描述 |
目标与能力 |
特点 |
示例 (以Qwen为例) |
|
预训练 (Pre-training) |
指的是深度学习模型在大量未标注数据上进行初始训练的过程。在这个阶段,模型学习语言的基本统计模式、语法、语义和世界知识,通常通过预测序列中的下一个词(或被遮蔽的词)来完成。 |
捕捉语言的统计模式和结构,使模型能够生成连贯且具有上下文关联性的文本。 |
这是一个无监督或自监督的学习过程,模型无需人工标注数据。预训练的结果是一个“基础模型”。 |
任何大型语言模型在发布其“基础”版本之前的训练阶段。 |
|
基模型 (Base Models) |
是指在大量文本语料库上完成预训练后的基本模型。它们掌握了丰富的语言知识和模式,具备生成流畅文本的能力。它们是更高级或特定用途模型的起点。 |
预测序列中的下一个词,生成连贯且具有上下文关联性的文本。具有多功能性,可以通过微调适应各种自然语言处理任务。 |
擅长生成流畅文本。 |
Qwen2.5-7B |
后训练 (Post-training) 和指令微调模型 (Instruction-tuned models)
|
概念 |
描述 |
目标与能力 |
特点 |
示例 (以Qwen为例) |
|
后训练 (Post-training) |
指的是在基础模型(预训练模型)完成大规模语料学习后,进行的额外训练阶段。这个阶段旨在使模型更好地理解和遵循人类指令、对齐人类偏好,并提升模型的安全性、有用性。指令微调是后训练的一种重要方式。 |
增强模型的实用性、遵循指令的能力、安全性和对齐人类意图。 |
基于已预训练的基础模型进行。 |
包括指令微调、RLHF(人类反馈强化学习)等多种对基础模型进行的进一步优化训练。 |
|
指令微调模型 |
是经过指令微调 (Instruction Tuning) 的语言模型,专门设计用于理解并以对话风格执行特定指令。它们在基础模型的基础上,使用包含指令示例及其预期结果(通常涵盖多个回合)的数据集进行额外训练。 |
准确解释用户命令,并以更高的准确性和一致性执行诸如摘要、翻译、问答等特定任务。同时保持生成流畅且连贯文本的能力。 |
基于基础模型进行有监督微调。 |
Qwen2.5-7B-Instruct |
三、Tokens & Tokenization
token 代表模型处理和生成的基本单位。它们可以表示人类语言中的文本(常规 token),或者表示特定功能,如编程语言中的关键字(控制 token。例如开始结束 等)。通常,使用 tokenizer 将文本分割成常规 token ,这些 token 可以是单词、 子词或字符,具体取决于所采用的特定 tokenization 方案,并按需为 token 序列添 加控制 token 。 词表大小,即模型识别的唯一 token 总数,对模型的性能和多功能性有重大影响。
大型语言模型通常使用复杂的 tokenization 来处理人类语言的广阔多样性,同时保 持词表大小可控。
Qwen 词表相对较大,有 151646 个 token。 要点:tokenization 和词表大小很重要。
3.1、Tokenization方案
Tokenization 是指将文本数据分割成更小的单元,这些单元被称为“tokens”(令 牌)。这个过程是自然语言处理(NLP)中的一个基础步骤,对于许多任务来说非常 重要,比如文本分类、情感分析、机器翻译等。通过 tokenization,原始文本被转换 为计算机可以理解和处理的形式。
|
Tokenization 方式 |
描述 |
优点 |
缺点 |
适用场景 |
|
基于空格 |
将文本按空格分割成单词。 |
简单、快速。 |
不适用于无空格语言(如中文)、无法处理复合词。 |
英文等以空格分隔单词的语言。 |
|
基于字符 |
将每个字符视为一个单独的 token。 |
不存在 OOV(Out-Of-Vocabulary,词汇表外)问题;适用于所有语言。 |
词汇表大;缺乏语义信息;序列长度长。 |
任何语言,特别是处理稀有词或拼写错误时。 |
|
基于子词 |
将单词分解为更小的部分(子词),是单词和字符之间的折衷方案。 |
平衡词汇表大小和表示能力;有效处理 OOV;处理复合词和派生词。 |
实现相对复杂。 |
多数现代NLP任务,尤其是大型语言模型。 |
|
基于句子 |
将文本按照句子来分割。 |
方便进行句子级别的分析或处理。 |
需要复杂的规则或模型来准确识别句子边界。 |
文本摘要、对话系统、篇章理解等。 |
Byte Pair Encoding有两种方案:基于字节的BPE、基于字符的BPE。
|
特性 |
基于字符的 BPE |
基于字节的 BPE |
|
基本单位 |
字符。每个字符都被视为一个独立的 token。 |
字节。每个 8 位字节都被视为一个独立的 token。 |
|
初始词汇表 |
包含文本中所有出现的唯一字符。 |
包含所有可能的字节值(0 到 255)。 |
|
合并操作 |
合并频繁出现的字符对。例如,对于字符串 "hello",'h' 和 'e' 可能会合并成 "he"。 |
合并频繁出现的字节对。例如,"hello" 的 UTF-8 编码中的字节(如 104 和 101)可能会合并。 |
|
适用场景 |
最适合处理标准文本数据,特别是当文本主要由常见字符组成时。 |
适用于任何二进制数据,包括文本。它特别适合处理多语言文本和包含特殊字符的数据,因为字节编码可以覆盖所有可能的字符。 |
示例
假设我们有一个简单的字符串 "hello world":
基于字符的 BPE:
初始词汇表: ['h', 'e', 'l', 'o', ' ', 'w', 'r', 'd']
合并操作:可能将 "he" 合并为一个新的 token。
基于字节的 BPE:
初始词汇表: [104, 101, 108, 111, 32, 119, 114, 100](这些是 "hello world" 的 UTF-8 编码)
合并操作:可能将 104 101 合并为一个新的 token。
Qwen采用了名为字节对编码(Byte Pair Encoding,简称BPE)的子词 tokenization方法,这种方法试图学习能够用最少的 token 表示文本的 token 组 合。例如,字符串”tokenization”被分解为” token”和”ization”(注意空格是 token 的一部分)。Qwen的 tokenization 确保了不存在未知词汇,并且所有文 本都可以转换为 token 序列。 Qwen词表中因BPE而产生的 token 数量为 151643 个,这是一个适用于多种语 言的大词表。一般而言,对于英语文本,1个token大约是3~4个字符;而对于中 文文本,则大约是1.5~1.8个汉字。
3.2、控制 Token 和 对话模板
控制 Token 和对话模板是引导大型语言模型行为和输出的两种关键机制。它们共同作用,帮助模型理解上下文,并生成符合预期的回复。
控制 Token 是插入到文本序列中的特殊标记,用于传递元信息。它们本身不代表具体的语义内容,而是作为一种信号,帮助模型理解文本的结构或状态。
|
特性 |
描述 |
示例(Qwen 模型) |
|
定义 |
插入到序列中的特殊 token,表示元信息。 |
`< |
|
作用 |
指示文本的边界、类型或其他结构性信息,帮助模型在处理长文本时保持上下文清晰。 |
对话模板为模型与用户之间的对话交互提供了一种结构化的格式。它使用预定义的占位符或提示来引导模型生成符合预期对话流程或上下文的响应。
|
特性 |
描述 |
|
定义 |
为对话交互提供结构化格式,利用预定义的占位符或提示来引导模型生成期望的响应。 |
|
重要性 |
使用指定的模板对于精确控制语言模型的生成过程至关重要。不同的模型可能采用不同的对话模板,因此遵循模型特定的模板是确保模型正确理解和响应的关键。 |
|
Qwen 示例 |
Qwen 模型使用 ChatML 格式来组织对话中的每一轮交互,并巧妙地利用控制 token 实现: |
四、长度限制
由于 Qwen 模型是因果语言模型,理论上整个序列只有一个长度限制。然而,由于 在训练中通常存在打包现象,每个序列可能包含多个独立的文本片段。模型能够生成 或完成的长度最终取决于具体的应用场景,以及在这种情况下,预训练时每份文档或 后训练时每轮对话的长度。
对于Qwen2.5,在训练中的打包序列长度为 32768 个 token。预训练中的最大文档 长度即为此长度。而后训练中,user和assistant的最大消息长度则有所不同。一般 情况下,assistant消息长度可达 8192 个 token。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 36
36 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)