
昇思大模型平台打卡体验活动:基于MindSpore实现Transformer机器翻译
昇思大模型平台打卡体验活动:基于MindSpore实现Transformer机器翻译
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
大模型平台
平台说明
昇思大模型平台旨在为AI学习者和开发者提供在线学习的项目、模型、大模型体验和数据集的平台。我们也添加了各领域的经典数据集来帮助学习者解决AI学习过程中的一系列难题, 如高质量的数据集不易获得,以及本地难以使用大体量数据集进行模型训练等。为用户提供多种业务场景的支持。

本文将引导用户对该平台的基础功能进行一个快速浏览, 以便用户了解该平台的主要功能。
快速开始
我们的平台提供了四大模块,分别是:
项目模块:覆盖多领域任务,体验全流程开发,支持用户在线训练和推理可视化,可创建自己的项目空间。
模型模块:覆盖全领域主流模型,可体验MindSpore大模型推理API,用户既可下载公开的预训练模型,也可以上传自行训练的模型文件。
大模型模块:在线体验预训练超大模型任务。
数据集模块:在数据集仓库中,你既可以下载公开的数据集,也可以上传合规的数据集。
鼠标点击头像栏按钮即可快速进入个人中心:

平台内容
平台主要有项目、模型、数据集、三大部分,
- 项目:覆盖多领域任务,体验全流程开发,支持用户在线训练和推理可视化,可创建自己的项目空间。
- 模型:覆盖全领域主流模型,可体验MindSpore大模型推理API,用户既可下载公开的预训练模型,也可以上传自行训练的模型文件。
- 大模型:在线体验预训练超大模型任务。
- 数据集:在数据集仓库中,你既可以下载公开的数据集,也可以上传合规的数据集。
昇思大模型平台为使用者预置华为AI Mindspore深度学习开发框架点击即可配置开发环境。
昇思大模型平台:让AI学习更简单!
登录昇思大模型平台:https://xihe.mindspore.cn/projects ,选择在线编程进行体验

启动Ascend

进入后左侧有相关目录可以进行学习参考

进入LLM原理和实践,可以查看到很多应用案例


应用体验
点击运行该案例,会逐步往下运行,运行结果需要等待
Transformer是一种神经网络结构,由Vaswani等人在2017年的论文“Attention Is All You Need”中提出,用于处理机器翻译、语言建模和文本生成等自然语言处理任务。
Transformer与传统NLP特征提取类模型的区别主要在以下两点:
- Transformer是一个纯基于注意力机制的结构,并将自注意力机制和多头注意力机制的概念运用到模型中;
- 由于缺少RNN模型的时序性,Transformer引入了位置编码,在数据上而非模型中添加位置信息;
以上的处理带来了几个优点:
- 更容易并行化,训练更加高效;
- 在处理长序列的任务中表现优秀,可以快速捕捉长距离中的关联信息。
通过Transformer实现文本机器翻译
全流程
- 数据预处理: 将图像、文本等数据处理为可以计算的Tensor
- 模型构建: 使用框架API, 搭建模型
- 模型训练: 定义模型训练逻辑, 遍历训练集进行训练
- 模型评估: 使用训练好的模型, 在测试集评估效果
- 模型推理: 将训练好的模型部署, 输入新数据获得预测结果
数据准备
我们本次使用的数据集为Multi30K数据集,它是一个大规模的图像-文本数据集,包含30K+图片,每张图片对应两类不同的文本描述:
- 英语描述,及对应的德语翻译;
- 五个独立的、非翻译而来的英语和德语描述,描述中包含的细节并不相同;
因其收集的不同语言对于图片的描述相互独立,所以训练出的模型可以更好地适用于有噪声的多模态内容。

图片来源:Elliott, D., Frank, S., Sima’an, K., & Specia, L. (2016). Multi30K: Multilingual English-German Image Descriptions. CoRR, 1605.00459.
在本次文本翻译任务中,德语是源语言(source languag),英语是目标语言(target language)。
数据下载模块
使用download进行数据下载,并将tar.gz文件解压到指定文件夹。
数据预处理
在使用数据进行模型训练等操作时,我们需要对数据进行预处理,流程如下:
- 加载数据集;
- 构建词典;
- 创建数据迭代器;
数据加载器
加载数据集,并进行分词,即将句子拆解为单独的词元(token,可以为字符或者单词)。一般在机器翻译类任务中,我们习惯进行单词级词元化,即每个词元要么为一个单词,要么为一个标点符号。同一个单词,不论首字母是否大写,都应该对应同一个词元,故在分词前,我们需统一将单词转换为小写。
"Hello world!" --> ["hello", "world", "!"]
接下来,我们创建数据加载器Multi30K。后期调用该类进行遍历时,每次返回当前源语言(德语)与目标语言(英语)文本描述的词元列表。
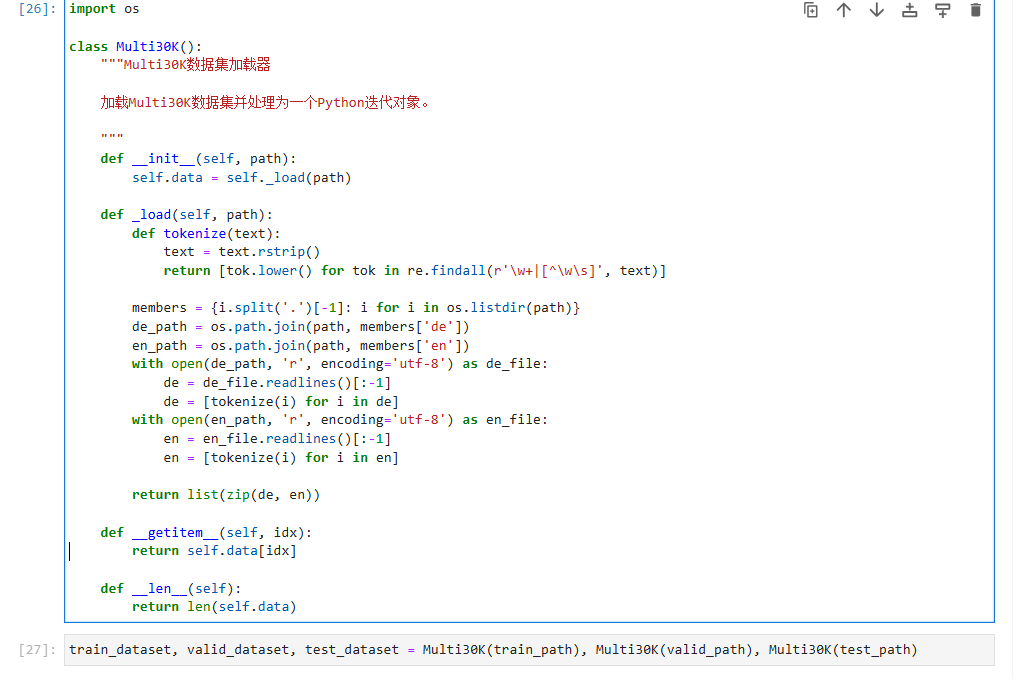
对解压和分词结果进行测试,打印测试数据集第一组英德语文本,可以看到每一个单词和标点符号已经被单独分离出来。

词典
将每个词元映射到从0开始的数字索引中(为节约存储空间,可过滤掉词频低的词元),词元和数字索引所构成的集合叫做词典(vocabulary)。
以上述“Hello world!”为例,该序列组成的词典为:
{"<unk>": 0, "<pad>": 1, "<bos>": 2, "<eos>": 3, "hello": 4, "world": 5, "!": 6}
在构建词典中,我们使用了4个特殊词元。
- <unk>:未知词元(unknown),将出现次数少于一定频率的单词统一判定为未知词元;
- <bos>:起始词元(begin of sentence),用来标注一个句子的开始;
- <eos>:结束词元(end of sentence),用来标注一个句子的结束;
- <pad>:填充词元(padding),当句子长度不够时将句子填充至统一长度;
通过Vocab创建词典后,我们可以实现词元与数字索引之间的互相转换。我们可以通过调用enocde函数,返回输入词元或者词元序列对应的数字索引或数字索引序列,反之亦然,我们同样可以通过调用decode函数,返回输入数字索引或数字索引序列对应的词元或词元序列。
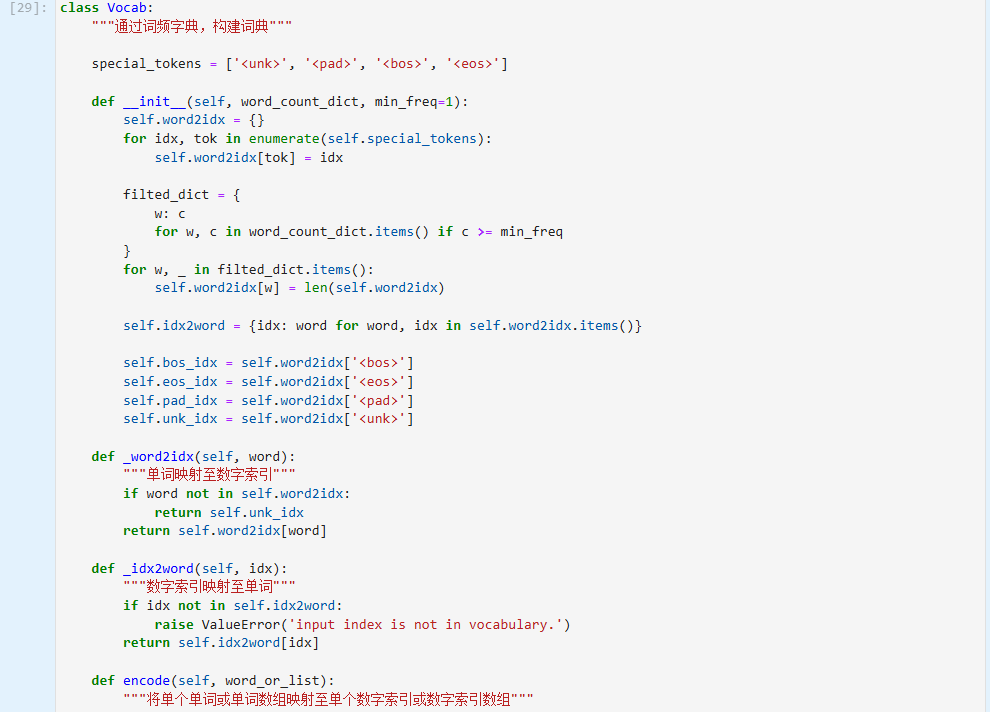
通过自定义词频字典进行测试,我们可以看到词典已去除词频少于2的词元c,并加入了默认的四个特殊占位符,故词典整体长度为:4 - 1 + 4 = 7

使用collections中的Counter和OrderedDict统计英/德语每个单词在整体文本中出现的频率。构建词频字典,然后再将词频字典转为词典。其中,收录所有源语言(德语)词元的词典为de_vocab,收录所有目标语言(英语)词元的词典为en_vocab。
在分配数字索引时有一个小技巧:常用的词元对应数值较小的索引,这样可以节约空间。
数据迭代器
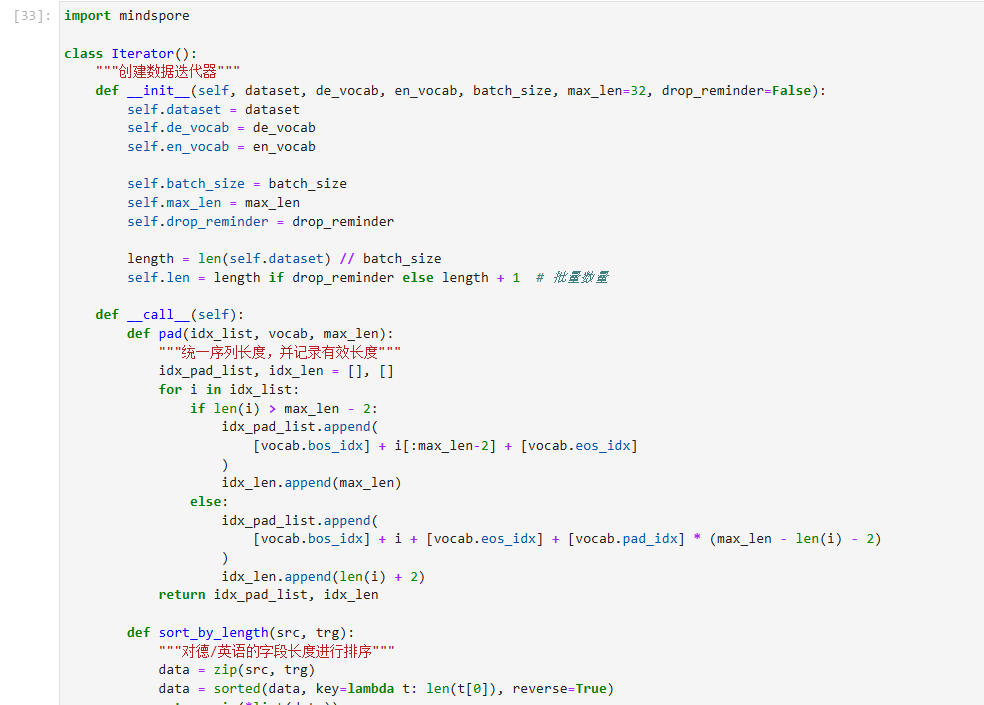
数据预处理的最后一步是创建数据迭代器。截至目前,我们已经通过数据加载器Multi30K将源语言(德语)与目标语言(英语)的文本描述转换为词元序列,并构建了词元与数字索引一一对应的词典,接下来,需要将词元序列转换为数字索引序列。
还是以“Hello world!”为例,我们逐步演示数据迭代器中的操作
- 我们将表示开始和结束的特殊词元 <bos> 和 <eos> 分别添加在每个词元序列的句首和句尾。
["hello", "world", "!"] --> ["<bos>", "hello", "world", "!", "<eos>"]
- 统一序列长度(超出长度的进行截断,未达到长度的通过填充 <pad> 进行补齐),同时记录序列的有效长度。此处假定统一的长度为7。
["<bos>", "hello", "world", "!", "<eos>"] --> ["", "hello", "world", "!", "<eos>", "<pad>", "<pad>"], valid length = 5
- 最后,对文本序列进行批处理。对于每个batch中的序列,通过调用词典中的
encode为序列中的所有词元找到其对应的数字索引,将结果以Tensor的形式返回。
["<bos>", "hello", "world", "!", "<eos>", "<pad>", "<pad>"] --> [2, 4, 5, 6, 3, 1, 1] --> tensor
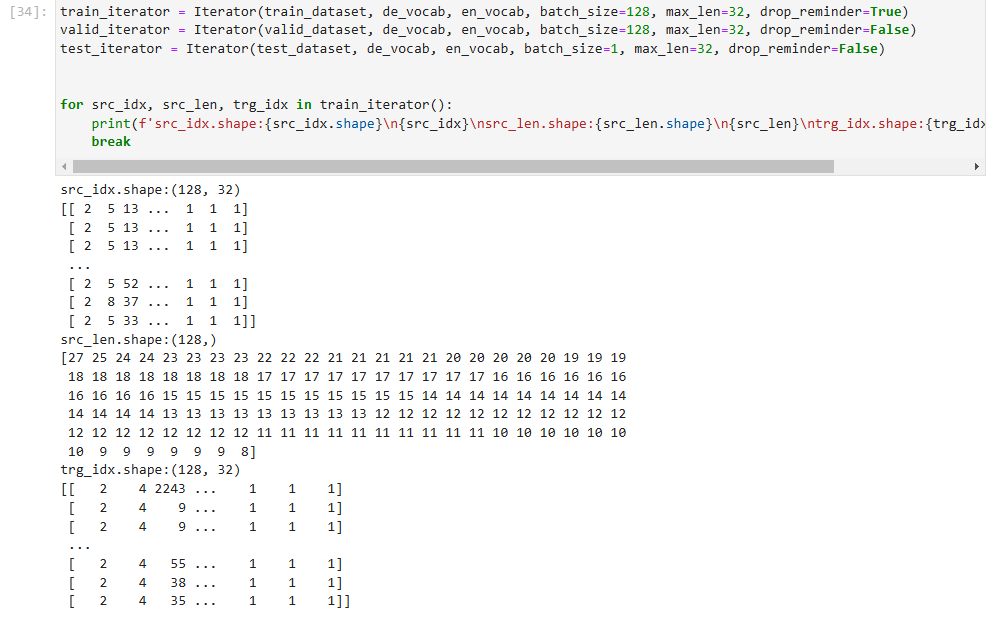
模型构建
定义超参数,实例化模型。

模型训练 & 模型评估
定义损失函数与优化器。
- 损失函数:定义如何计算模型输出(logits)与目标(targets)之间的误差,这里可以使用交叉熵损失(CrossEntropyLoss)
- 优化器:MindSpore将模型优化算法的实现称为优化器。优化器内部定义了模型的参数优化过程(即梯度如何更新至模型参数),所有优化逻辑都封装在优化器对象中。

模型训练逻辑
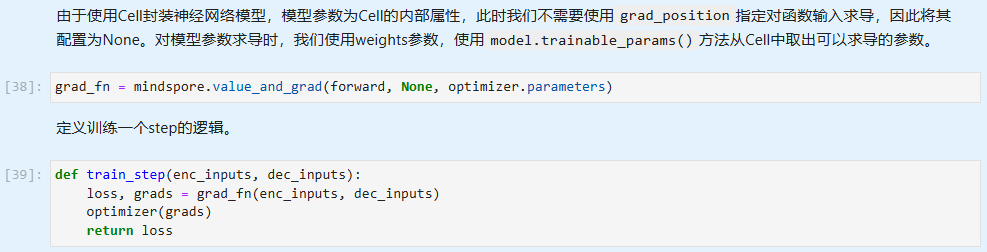
MindSpore在模型训练部分使用了函数式编程(FP)。
构造函数→函数变换→函数调用
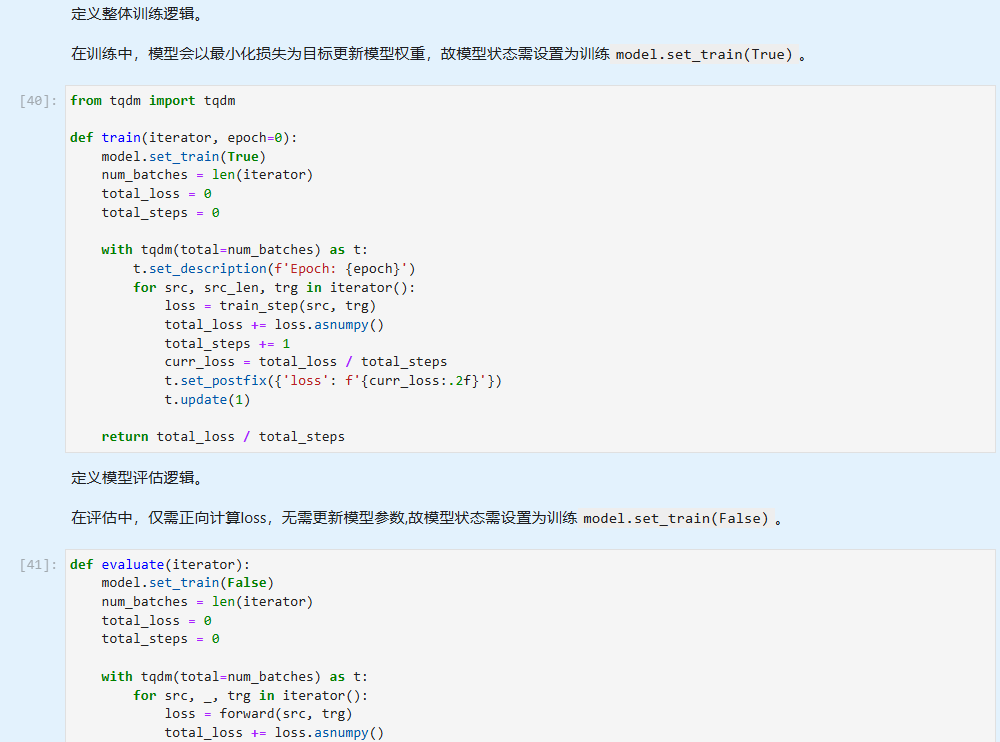
模型训练
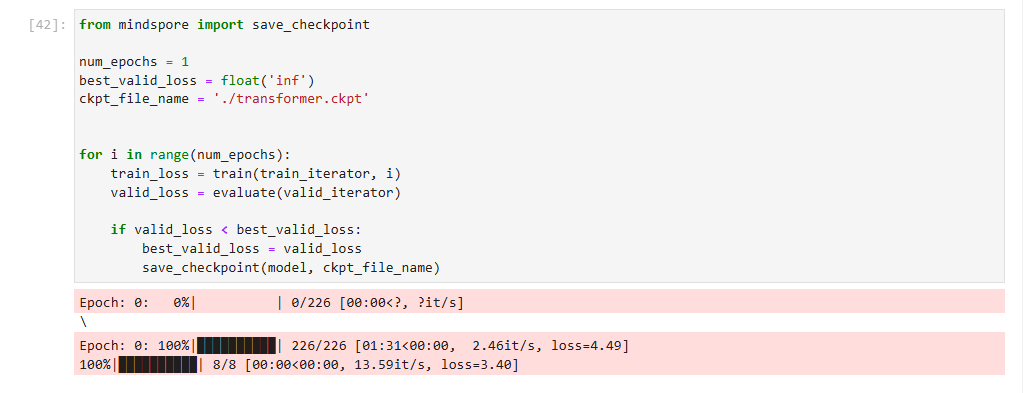
数据集遍历迭代,一次完整的数据集遍历成为一个epoch。我们逐个epoch打印训练的损失值和评估精度,并通过save_checkpoint保存评估精度最高的ckpt文件(transformer.ckpt)到home_path/.mindspore_examples/transformer.ckpt。
模型推理
首先,通过load_checkpoint与load_param_into_net将训练好的模型参数加载入新实例化的模型中。

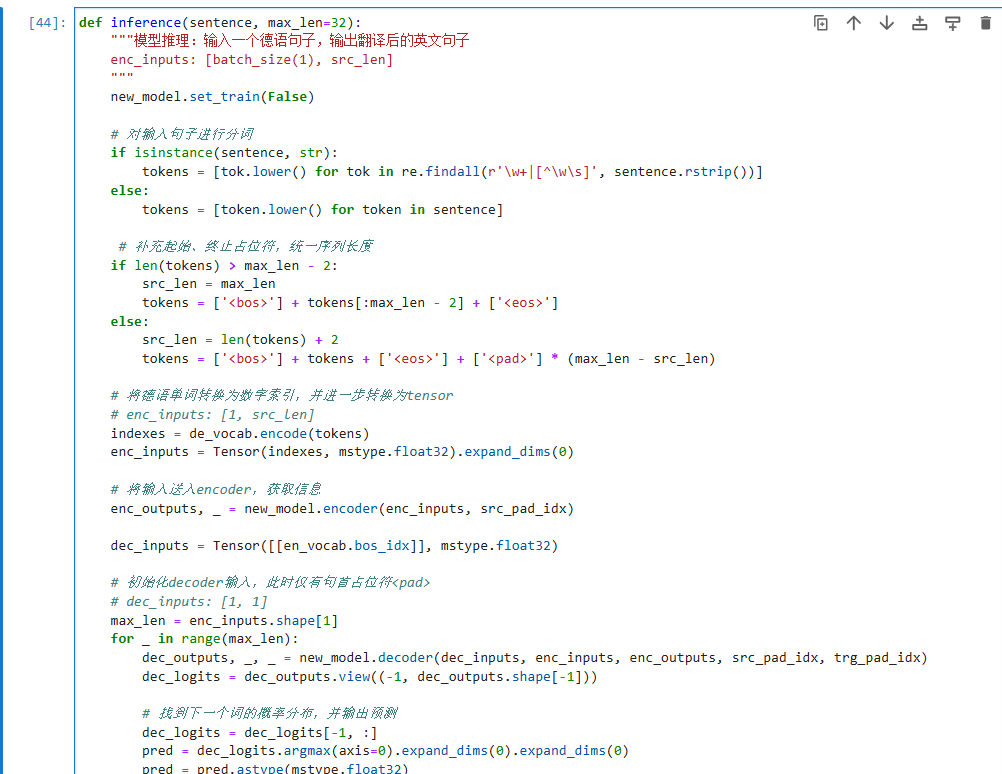
以测试数据集中的第一组语句为例,进行测试。

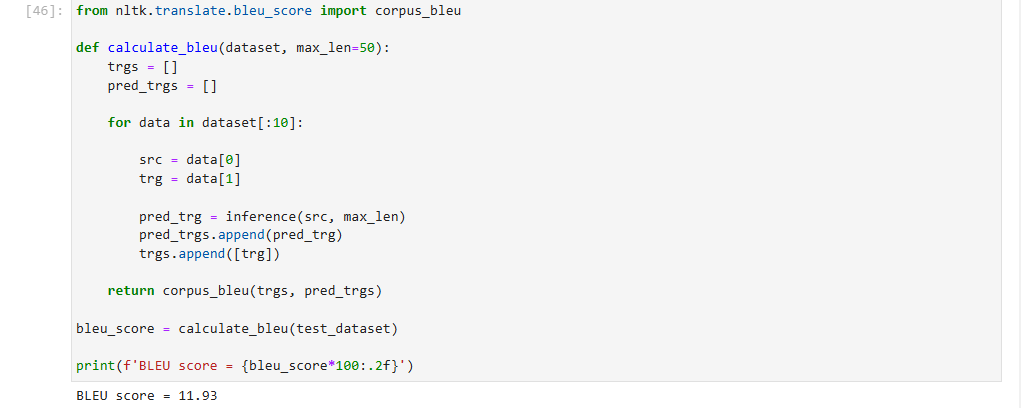
BLEU得分
双语替换评测得分(bilingual evaluation understudy,BLEU)为衡量文本翻译模型生成出来的语句好坏的一种算法,它的核心在于评估机器翻译的译文 predpred 与人工翻译的参考译文 labellabel 的相似度。通过对机器译文的片段与参考译文进行比较,计算出各个片段的的分数,并配以权重进行加和,基本规则为:
- 惩罚过短的预测,即如果机器翻译出来的译文相对于人工翻译的参考译文过于短小,则命中率越高,需要施加更多的惩罚;
- 对长段落匹配更高的权重,即如果出现长段落的完全命中,说明机器翻译的译文更贴近人工翻译的参考译文;
最终得出11.93分

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)