
flask基于Vue的社区拼购商城(毕设源码+论文)
本选题将以社区拼购商城为研究情景,重点分析和研究其运营模式、用户体验、商品管理等问题,以期探寻社区拼购商城可持续发展的问题原因,提出对策建议,为后续更加深入的研究提供基础。[7] 张华, 翟新军, 胥勇, 李伟强, 杨健, 赵嘉伟, 张涛. "Python在集控大数据应用的研究"[J]. 价值工程, 2023, 42 (21): 84-86.特点包括简单性、灵活性和易于扩展。社区拼购商城是一种基于
本系统(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。
系统程序文件列表
开题报告内容
一、选题背景
关于社区拼购商城的研究,现有研究主要以传统电商或线下零售为主,专门针对社区拼购商城这种新兴零售模式的研究较少。在国内外,传统电商发展已较为成熟,线下零售也有众多的研究成果。然而,社区拼购商城作为一种结合社区资源、拼购模式的新型商业模式,正处于快速发展阶段,目前存在多种观点。一些观点认为社区拼购商城依赖社区人际关系网络,能有效降低营销成本;另一些观点则担心其商品质量管控和售后服务的难度。其争论焦点在于如何平衡低价拼购与商品品质、服务质量之间的关系。本选题将以社区拼购商城为研究情景,重点分析和研究其运营模式、用户体验、商品管理等问题,以期探寻社区拼购商城可持续发展的问题原因,提出对策建议,为后续更加深入的研究提供基础。这一研究有助于深入理解新兴零售模式的发展机制,是具有研究价值的,目的在于为社区拼购商城的健康发展提供理论支持和实践指导。
二、研究意义
本选题针对社区拼购商城等问题的研究具有重要的理论意义和现实意义。
- 理论意义:本选题研究将对社区拼购商城的商业模式、用户行为等进行深入的剖析,有助于完善零售商业相关理论。社区拼购商城融合了社区、社交、拼购等多种元素,其独特的运营模式和用户互动方式可以为商业理论提供新的研究素材,进一步丰富和发展零售商业理论体系。
- 现实意义:随着社区拼购商城的兴起,其在满足消费者多样化需求、推动社区经济发展等方面具有巨大潜力。本研究能够为社区拼购商城的运营者提供优化运营策略的建议,例如提高商品分类的合理性、优化拼团规则等,从而提升用户体验,增强竞争力;同时也能为消费者提供消费指导,保障其权益,促进社区拼购商城的健康、可持续发展。
三、研究方法
本研究将采用多种研究方法相结合的方式。
- 文献研究法:通过查阅国内外关于社区拼购、电子商务、零售商业模式等方面的文献资料,了解社区拼购商城的发展历程、现状以及相关理论研究成果,为本研究提供理论基础和研究思路参考[2] 。
- 案例研究法:选取若干具有代表性的社区拼购商城平台进行深入分析,研究其用户管理、商品分类与管理、拼团规则设置、日志信息管理等系统功能,总结成功经验和存在的问题,为研究提供实际案例支撑。
- 问卷调查法:设计针对社区拼购商城用户的调查问卷,内容包括用户的消费习惯、对商品分类的满意度、对拼团规则的看法、对商品信息的需求等方面,通过收集大量用户反馈数据,进行统计分析,了解用户需求和意见,为研究提供数据支持。
四、研究方案
(一)可能遇到的困难和问题
- 数据获取方面:社区拼购商城的部分数据可能涉及商业机密,如用户购买行为数据、商品销售数据等,获取这些数据存在一定困难。同时,不同社区拼购商城平台的数据格式和统计口径可能存在差异,增加了数据整合和分析的难度。
- 案例研究的代表性问题:社区拼购商城市场竞争激烈,平台众多且模式多样,选取具有代表性的案例进行研究存在一定挑战。如果案例选取不当,可能无法全面反映社区拼购商城的整体情况和特征。
- 用户需求的多样性把握:用户对于社区拼购商城的需求受到多种因素影响,如年龄、地域、消费习惯等,准确把握用户需求的多样性并进行量化分析较为困难。
(二)解决的初步设想
- 数据获取方面:与部分社区拼购商城平台建立合作关系,争取获取部分脱敏后的有效数据;同时,利用公开的行业报告、统计数据等作为补充数据源,以确保数据的完整性和可靠性。对于数据格式和统计口径的差异,通过建立统一的数据模型进行数据清洗和转换,以便进行有效的数据分析。
- 案例研究的代表性问题:采用分层抽样的方法选取案例,按照平台规模、运营模式、地域分布等维度进行分类,确保所选案例能够覆盖不同类型的社区拼购商城。同时,对多个案例进行综合分析,对比不同案例之间的异同点,以提高研究结论的普适性。
- 用户需求的多样性把握:在问卷调查过程中,扩大样本量并进行分层抽样,确保样本能够涵盖不同类型的用户群体。同时,结合访谈法对部分典型用户进行深入访谈,获取更详细、深入的用户需求信息,以提高对用户需求多样性的把握能力。
五、研究内容
社区拼购商城是一种基于社区的新型购物模式,本研究将围绕其系统功能展开,包括用户、商品分类、商品信息、拼团规则、日志信息等方面。
- 用户方面:研究用户的注册、登录、权限管理等功能,分析用户的行为特征,如用户的购买频率、购买时间、偏好的商品类型等,探究如何提高用户的活跃度和忠诚度。例如,通过分析用户登录时间和购买频率的关系,制定个性化的营销推送策略。
- 商品分类方面:研究商品分类的合理性和有效性,如何根据用户需求和商品特点进行分类,以便用户快速找到所需商品。同时,分析商品分类与商品销售之间的关系,例如某些热门商品分类是否能够带动整体销售额的增长。
- 商品信息方面:探讨商品信息的完整性、准确性和及时性,包括商品的图片、描述、价格、库存等信息。研究如何通过优化商品信息展示,提高用户的购买决策效率,例如提供详细的商品参数和用户评价信息。
- 拼团规则方面:深入分析拼团规则的设置,如拼团人数、拼团价格、拼团时间等因素对用户参与度和购买行为的影响。研究如何制定合理的拼团规则,以提高拼团成功率和销售额,例如通过分析不同拼团人数下的订单转化率,调整最优拼团人数。
- 日志信息方面:研究日志信息的记录、存储和分析方法,如何通过日志信息挖掘用户行为模式、系统运行状况等信息。例如,通过分析用户操作日志,发现用户在购物过程中的痛点和问题,以便优化系统功能和用户体验。
六、拟解决的主要问题
- 优化商品分类与展示:针对社区拼购商城中商品种类繁多的特点,通过研究用户的搜索和购买行为,设计出更合理的商品分类体系,提高商品的展示效果,让用户能够更快速、准确地找到自己想要的商品。
- 完善拼团规则:分析现有的拼团规则在吸引用户参与、提高销售额方面存在的不足,结合用户需求和市场竞争情况,制定出更加合理、有效的拼团规则,提高拼团的成功率和用户满意度。
- 提高用户体验:从用户注册、登录、购物流程、售后服务等各个环节入手,分析存在的问题,通过优化系统功能、改进服务质量等措施,提高用户在社区拼购商城的整体体验。
七、预期成果
- 建立社区拼购商城运营模型:通过对社区拼购商城的用户、商品分类、商品信息、拼团规则、日志信息等系统功能的研究,构建一个全面的社区拼购商城运营模型,为社区拼购商城的运营者提供理论指导和决策依据。
- 提出优化策略和建议:针对研究过程中发现的问题,提出一系列具体的优化策略和建议,如商品分类优化方案、拼团规则改进措施、用户体验提升方法等,这些策略和建议将有助于提高社区拼购商城的竞争力和可持续发展能力。
- 形成毕业设计论文:完成一篇高质量的毕业设计论文,详细阐述社区拼购商城的研究背景、意义、方法、内容、成果等,为相关领域的研究和实践提供参考。
进度安排:
第1周:查阅文献资料,提交开题报告
第2周:进行需求分析,确定系统具体功能
第3周:进行系统总体设计
第4-7 周:进行详细设计并实现编码
第8周:设计中期成果答辩
第9-11周:完成全部设计成果,并撰写设计说明书(论文)交指导教师审阅
第12周:论文定稿,评阅教师对论文进行评阅,准备答辩
第13周:毕业答辩
第 14 周:毕业设计组档
参考文献:
[1] 池毓森. "基于Python的网页爬虫技术研究"[J]. 信息与电脑(理论版), 2021, 33(21): 41-44.
[2] 李培. "基于Python的网络爬虫与反爬虫技术研究"[J]. 计算机与数字工程, 2019, 47(06): 1415-1420+1496.
[3] Sebastian Bassi. "A Primer on Python for Life Science Researchers." PLoS Comput. Biol. (2007).
[4] 曾浩. "基于Python的Web开发框架研究"[J]. 广西轻工业, 2011, 27(08): 124-125+176.
[5] 张珩. "Python的计算机软件应用技术探讨"[J]. 电脑知识与技术, 2020, 16(32): 96-97+102.
[6] T. Oliphant. "Python for Scientific Computing." Computing in science & engineering (Print) (2007).
[7] 张华, 翟新军, 胥勇, 李伟强, 杨健, 赵嘉伟, 张涛. "Python在集控大数据应用的研究"[J]. 价值工程, 2023, 42 (21): 84-86.
[8] 张楠. "Python语言及其应用领域研究"[J]. 科技创新导报, 2019, 16(17): 122-123.
[9] G. Mahalaxmi, A. D. Donald et al. "A Short Review of Python Libraries and Data Science Tools." South Asian Research Journal of Engineering and Technology (2023).
[10] Guttu Sai Abhishek, Harshad Ingole et al. "SPEAR: Semi-supervised Data Programming in Python." Conference on Empirical Methods in Natural Language Processing (2021).
[12] 李永刚. "基于Python的计算机软件应用技术研究"[J]. 无线互联科技, 2021, 18(11): 36-37.
[13] 陈乐. "基于Python的网络爬虫技术"[J]. 电子世界, 2018, No.550(16): 163+165.
以上是开题是根据本选题撰写,是项目程序开发之前开题报告内容,后期程序可能存在大改动。最终成品以下面运行环境+技术栈+界面为准,可以酌情参考使用开题的内容。要源码请在文末进行获取!!
系统技术栈:
前端技术栈
Vue.js:是一个用于构建用户界面的渐进式JavaScript框架。允许开发者通过声明式渲染来创建动态的单页应用(SPA)。
HTML (HyperText Markup Language):用于创建网页的标准标记语言。定义网页的结构和内容,如段落、链接、图片等。
CSS (Cascading Style Sheets):用于描述HTML文档的样式和布局。可以控制字体、颜色、间距、布局等视觉表现。
JavaScript:一种轻量级,解释型或即时编译型的编程语言。通常用于网页上实现交互效果,如表单验证、动态内容更新等。与Vue.js结合,可以创建复杂的用户界面。
后端技术栈
Python3.7.7:高级编程语言,以其清晰的语法和代码可读性而闻名。广泛用于后端开发、科学计算、数据分析等领域。
Flask:是一个用Python编写的轻量级Web应用框架。它提供了一组工具和功能来快速开发Web应用。特点包括简单性、灵活性和易于扩展。
MySQL:是一个关系型数据库管理系统(RDBMS),广泛用于存储、检索和管理数据。支持SQL(结构化查询语言),用于执行数据库操作,如查询、更新、插入和删除数据。
开发工具
PyCharm:是由JetBrains开发的一个集成开发环境(IDE),专为Python开发设计。
提供代码自动完成、项目管理、调试和测试支持等功能。社区版是免费的,适合个人开发者和学习者使用。
开发流程:
• 首先,使用HTML、CSS和JavaScript结合Vue.js构建前端界面,实现用户交互和动态内容展示。接着,在后端使用Python语言结合Flask框架开发RESTful API,处理前端请求并提供业务逻辑。同时,利用MySQL数据库进行数据存储和查询,确保数据的持久化和一致性。开发过程中,通过PyCharm IDE进行代码编写、调试和项目管理,确保开发效率和代码质量。最后,通过持续集成和测试,确保应用的稳定性和可靠性,完成开发后进行部署,使应用可以在服务器上运行并对外提供服务。整个流程注重模块化设计和分层架构,以便于维护和扩展。
使用者指南
理解基本概念:了解HTML、CSS和JavaScript的基本概念是非常重要的。
学习Vue.js:通过官方文档或在线课程学习Vue.js的基本用法和生态系统。
掌握Python:学习Python语言的基础,包括数据类型、控制流、函数和模块。
熟悉Flask框架:通过阅读Flask文档和教程来学习如何构建Web应用。
数据库知识:了解SQL语言和数据库设计原则,学习如何使用MySQL进行数据存储和管理。
实践项目:通过实际项目来应用所学知识,这是提高技能的最佳方式。
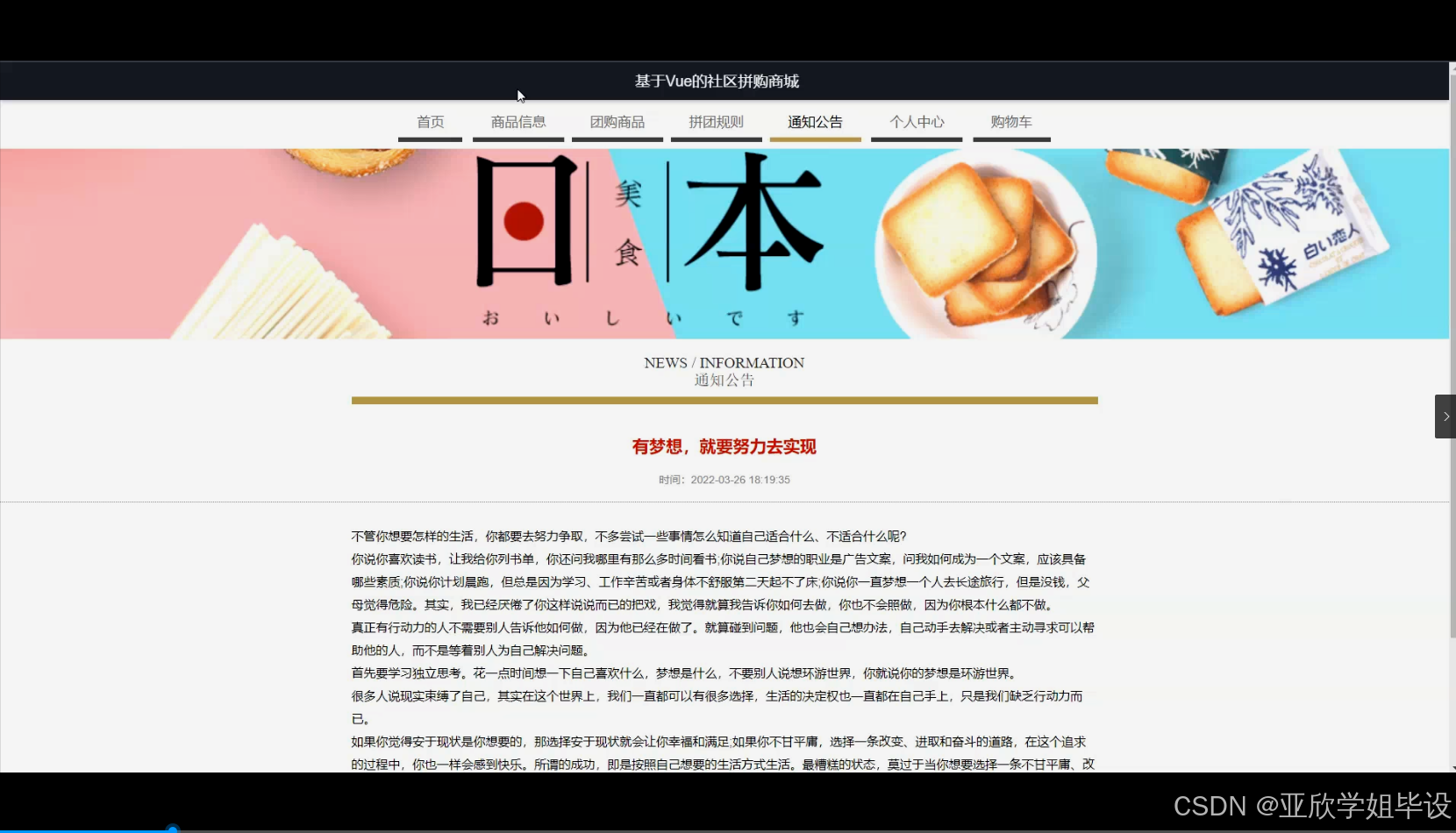
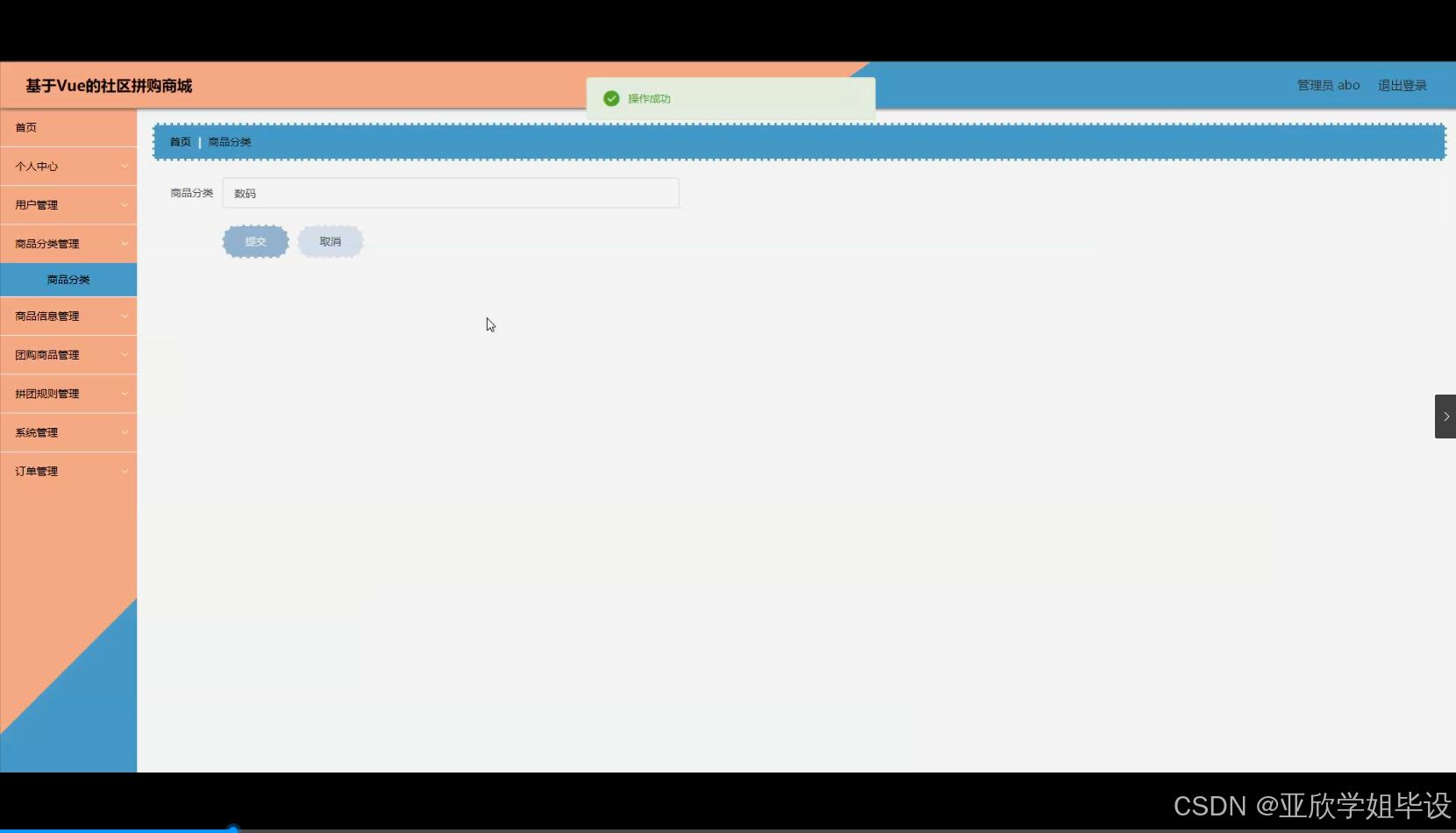
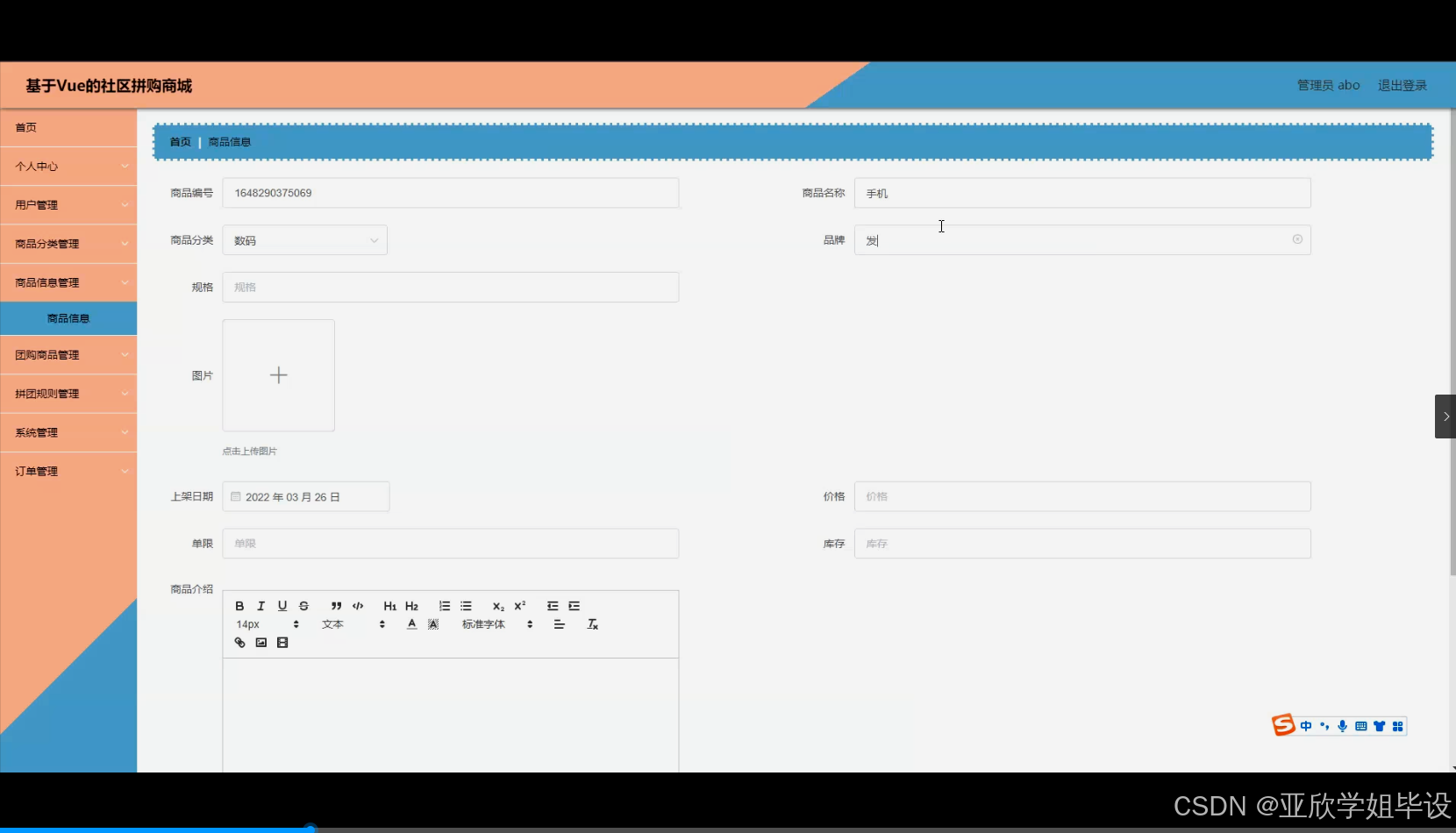
程序界面:

源码、数据库获取↓↓↓↓

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 19
19 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)