
AI大模型应用之微调篇
在大模型的应用当中,微调这个词出现的概率很高,然后与之常做对比的是RAG , 那么何为微调?(写了前面几篇大模型基础篇的文章,感觉还是得好好构建下文章结构,要不后面自己回看都看不明白了,写完后还是需要花点时间来整理一下~)

在大模型的应用当中,微调这个词出现的概率很高,然后与之常做对比的是RAG , 那么何为微调?(Fine-Tuning),实际是在基于已经训练好的大模型,在这个基础上再用特定领域或者任务的数据进行进一步的训练,使它更符合实际的需求,针对性提升特定任务的表现。
(写了前面几篇大模型基础篇的文章,感觉还是得好好构建下文章结构,要不后面自己回看都看不明白了,写完后还是需要花点时间来整理一下~)
1. 何时RAG何时Fine-tuning
Fine-tuning 使用场景: 模型定制化,幻觉, 低延迟,硬件智能体
RAG 使用场景: 动态数据,幻觉 ,依赖通用能力,低成本,可解释性
微调其实还和另一个 In-context Learning(上下文学习) 有点类似, In-context Learing 其实类似把一些正确例子放到prompt 里面直接塞给大模型,以此来增强模型的理解能力,但是缺点就是会导致提示词过长,微调相当于用更多的例子去增加模型的能力。
三者区别:

2. 微调方法
2.1. 全参微调
全参微调实际上就是调整模型的所有参数,需要大量算力,比较适合有钱的团队, 但是也容易导致原来模型能力的遗忘(灾难性遗忘问题)
2.2. 高效微调(PEFT)
微调只训练少量参数, 比较节省资源,效果接近全参数微调。LoRA是微调的其中的一种训练方法
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
# 添加LoRA配置(只训练注意力层的部分参数)
lora_config = LoraConfig(
r=8, # 低秩矩阵的维度
lora_alpha=32,
target_modules=["q_proj", "v_proj"], # 仅修改查询和值矩阵
lora_dropout=0.05
)
# 转换为可微调模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 查看可训练参数占比(通常<1%)微调需要关注的点:
- 数据质量大于数据数量
- 防止过拟合 :训练轮次不宜太多 (一般是3-5轮次)
- 低成本技巧 :用QLoRA(4-bit量化+LoRA)可在消费级显卡(如RTX 3090)上微调大模型。
3. 微调训练方法
主流的高效微调技术有LoRA (Low-RANK Adaptation) ,Adapter Tuning ,Prefix Tuning , Prompt Tuning , 还有 Quantization-aware Training 等,其中比较长听到的LoRA。
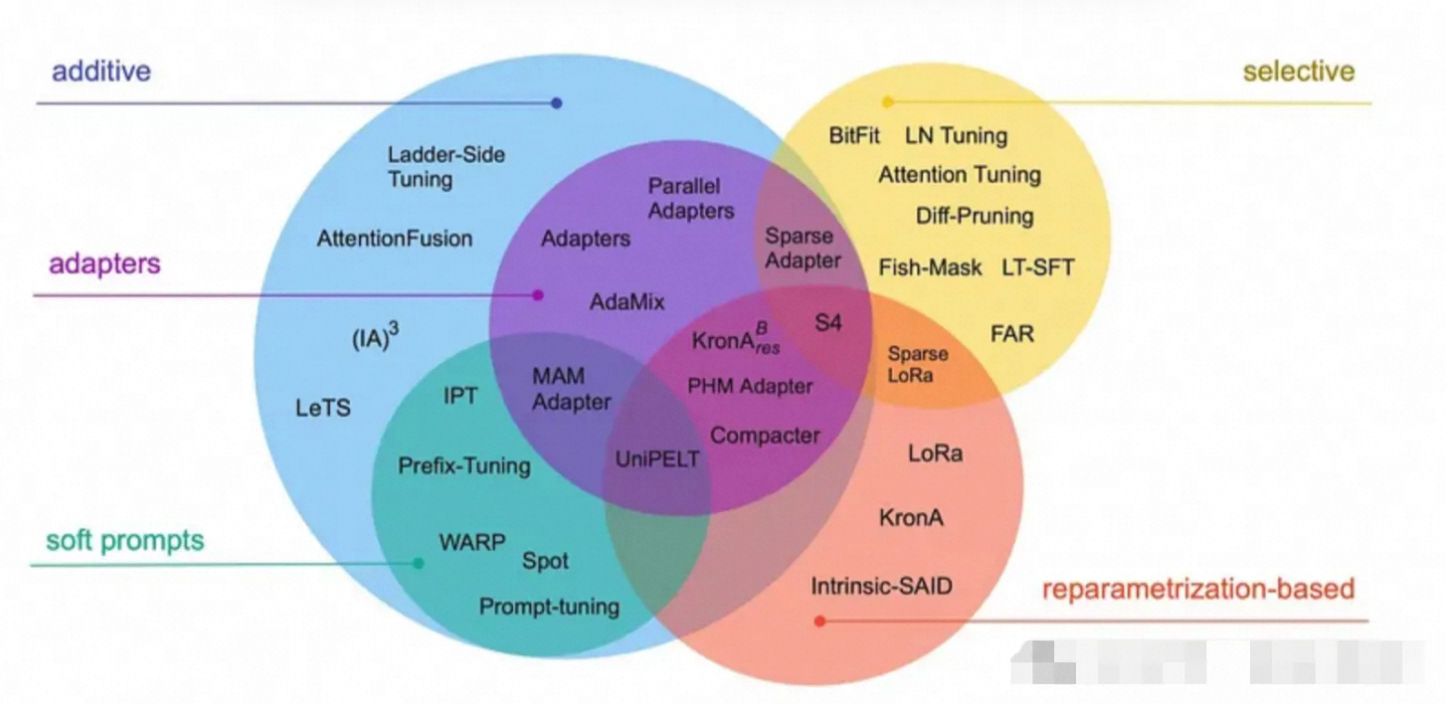
3.1. LoRA(Low-Rank Adaptation)
- 原理:在模型原有参数旁插入两个低秩矩阵(瘦高矩阵),仅训练这两个小矩阵,用它们的乘积更新原始参数(类似给模型打“补丁”)。
- 例子:假设原参数矩阵是1000x1000(100万参数),LoRA用两个1000x10和10x1000的矩阵相乘(共2万参数),只训练这2万参数。
- 优点:几乎不增加推理耗时,兼容性高。
- 适用场景:需要保持原模型结构(如部署时不想修改代码)。
看了下LoRA的专业解析,涉及到各种数学的计算理解了,表示好久没解过数学题了,看不懂呀,看来得微调下自己的大脑才能看的明白。
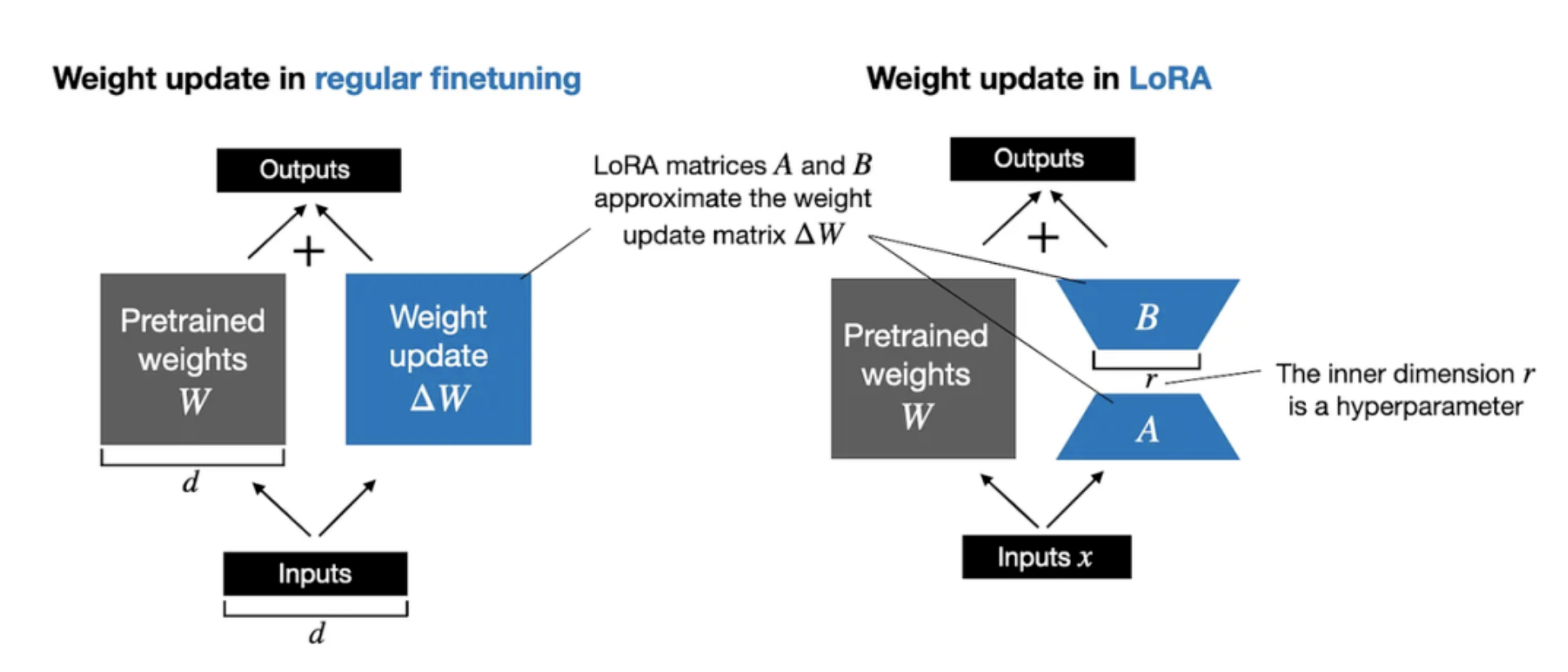
4. 微调成本
B站看到的一个关于AI 大模型的基础知识科普视频,其中提到了微调的成本并不在于GPU的成本,但是返回进行多轮的微调,例如问题本身解决方案,数据质量问题等,都是直接影响到微调的成本
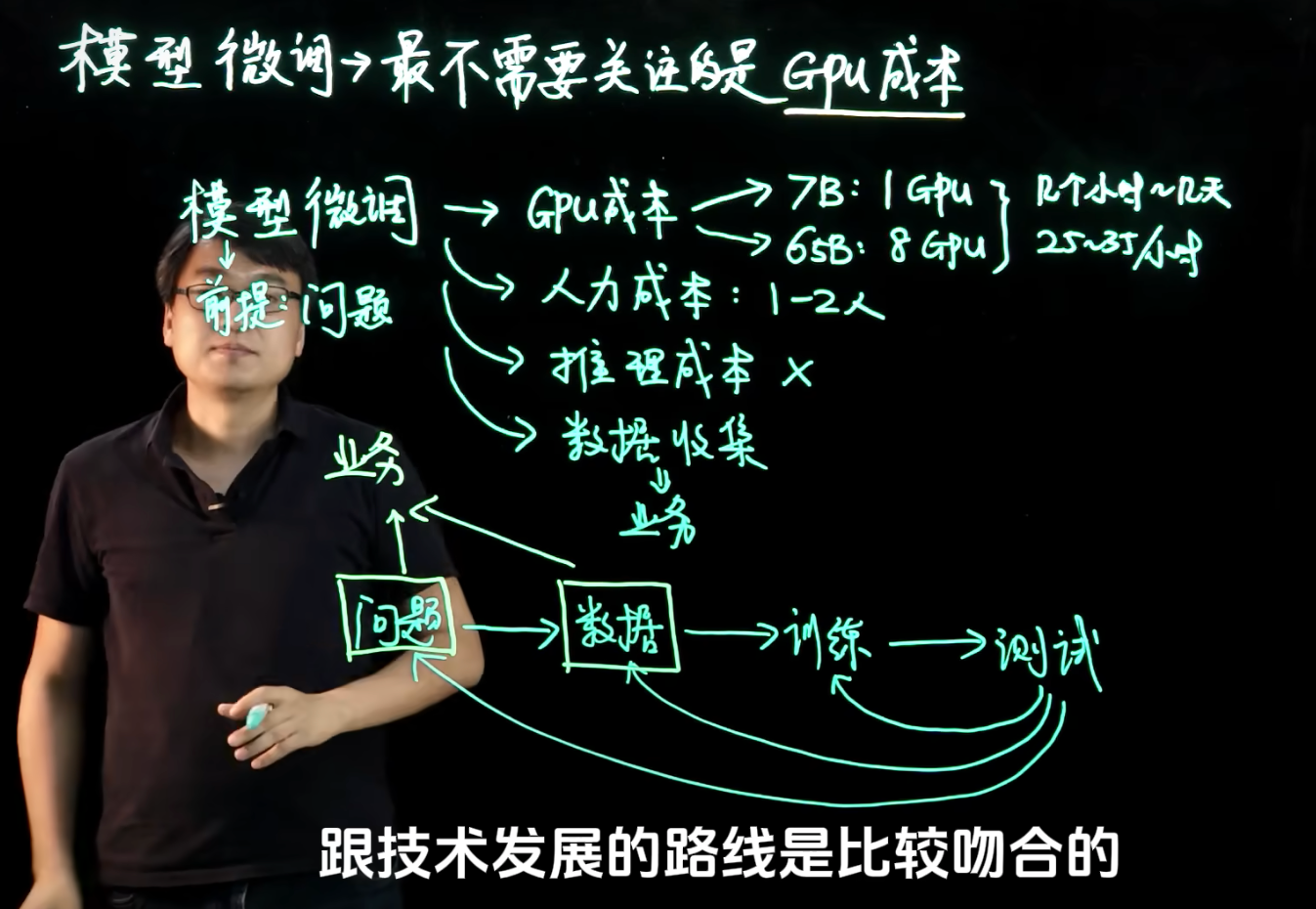
微调成本分析
- GPU成本:可控 7B:1GPU 几个小时~几天 A100 25~35¥/小时
- 人力成本:1-2人
- 推理成本:产品做出来之后,会想方法降低推理成本
- 数据收集:不可控,成本巨大
问题 → 数据 → 训练 → 测试 前两个环节最关键!跟业务相关。不重视前两个环节就会导致花了很多钱不见水花
另外还有一个就是大模型项目失败的十大原因总结:
- 从技术出发找场景 (过度设计,伪需求)
- 大模型团队不了解业务
- 技术方案过度设计
- 过于沉迷模型训练
- 低谷模型评估的重要性
- 不合理的期望管理
- 缺乏清晰的产品/技术路线
- 缺乏对技术发展的认知
- 高估项目的成功率 < 5%
- 忽略微调的隐藏成本(上百轮调试)

5. 微调技巧
- 学习率设置: 使用比预训练更小的学习率 ,分层设置学习率(顶层>中层>底层)
- 数据增强:对小数据集进行增强(翻转,裁剪,MixUp)等,防止过拟合
- 早停法(Early Stopping) : 监控验证集损失,在性能下降前终止训练
- 权重初始化: 仅对新添加的层(如分类头)随机初始化,保留预训练权重
6. 微调工具
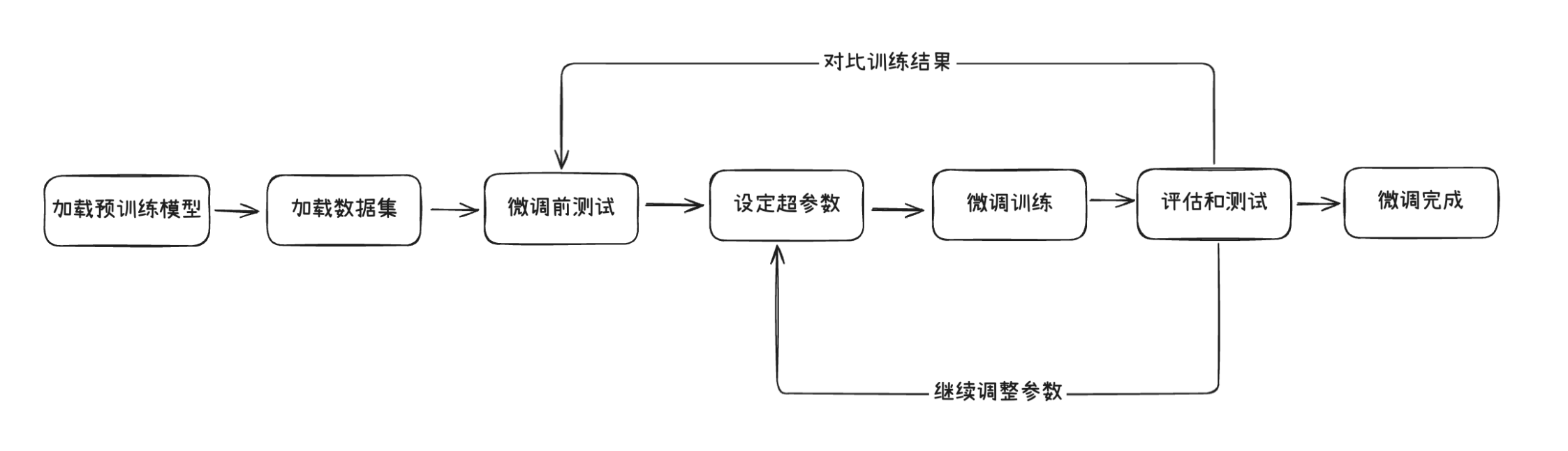
6.1. 前置-数据准备
数据集准备: 数据的内容也可以加上一些推理思考的内容
openAI官方推荐数据格式:保护角色和内容

一些数据集获取网站:
kaggle :Find Open Datasets and Machine Learning Projects | Kaggle
huggingface :https://huggingface.co/datasets
阿里云:天池数据集_阿里系唯一对外开放数据分享平台-阿里云天池
opendatelab : OpenDataLab 引领AI大模型时代的开放数据平台 (国内最大)
6.2. 基于硅基流动平台进行模型微调
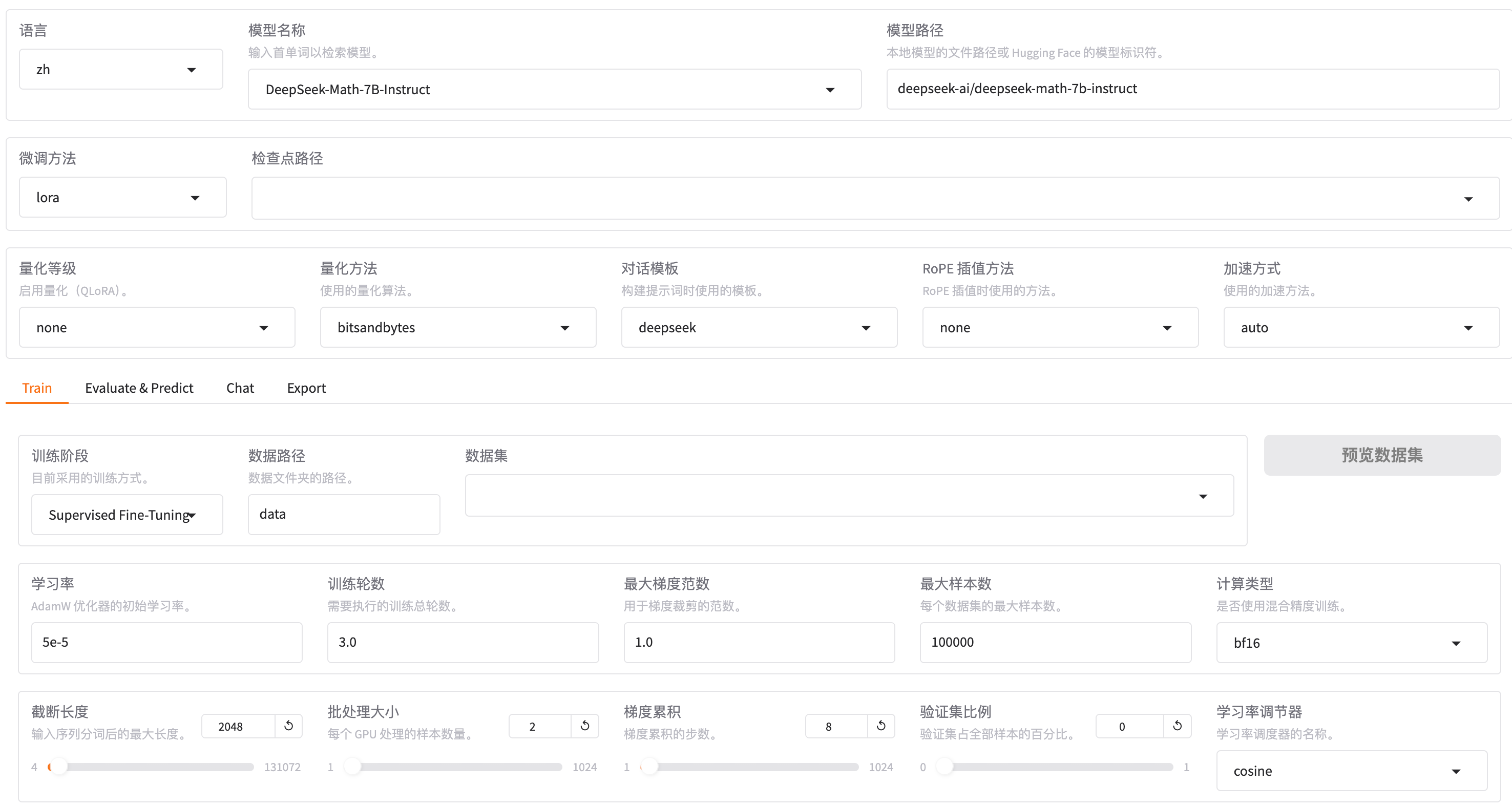
可以看到微调要关注的核心参数 :学习论述,学习率,批量大小
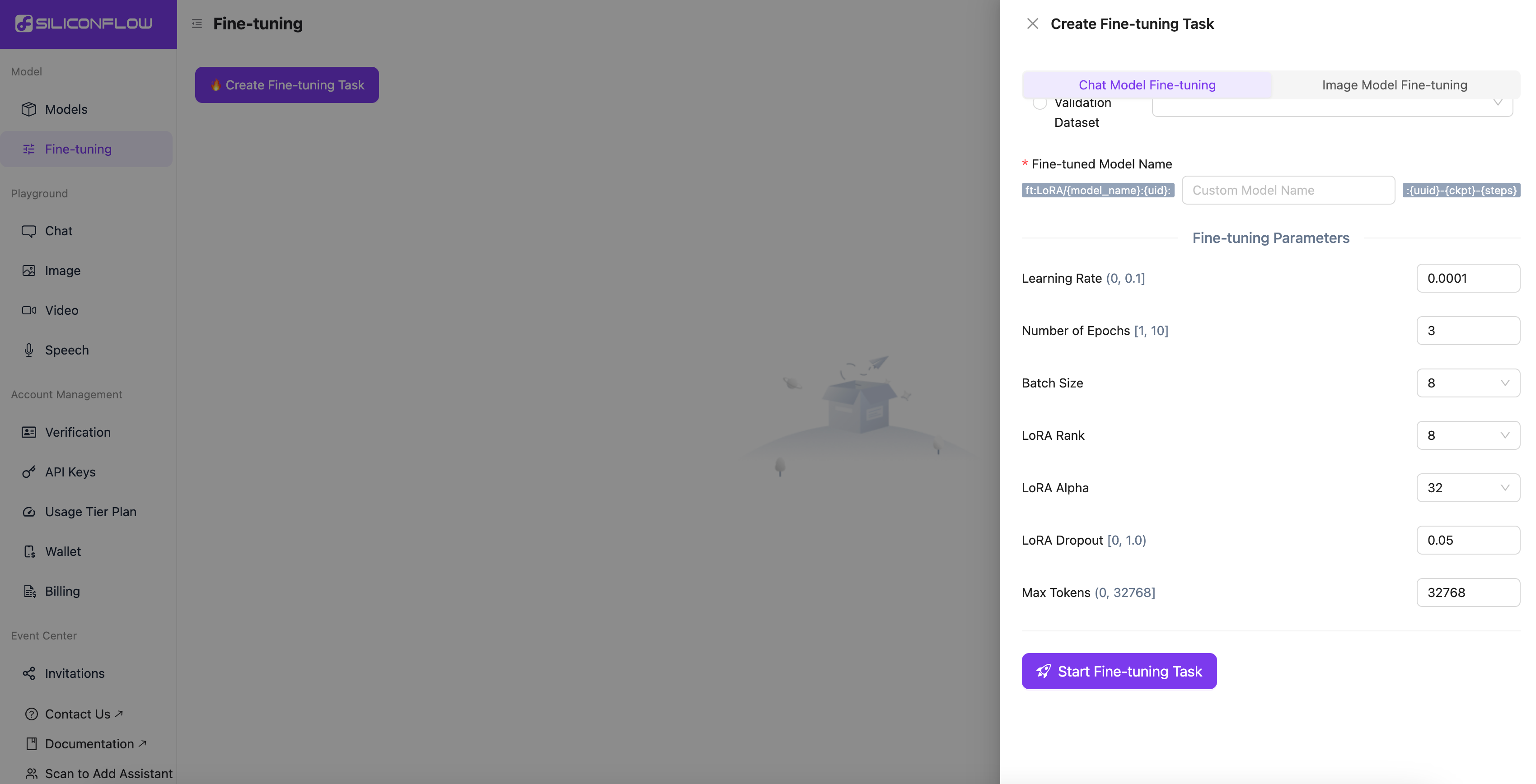
数据集是jsonl 格式,每一行都是一个独立的json对象。必须包含message, role,content

验证数据集,通常用来进行模型微调效果的评测,一般留出训练数据的10%
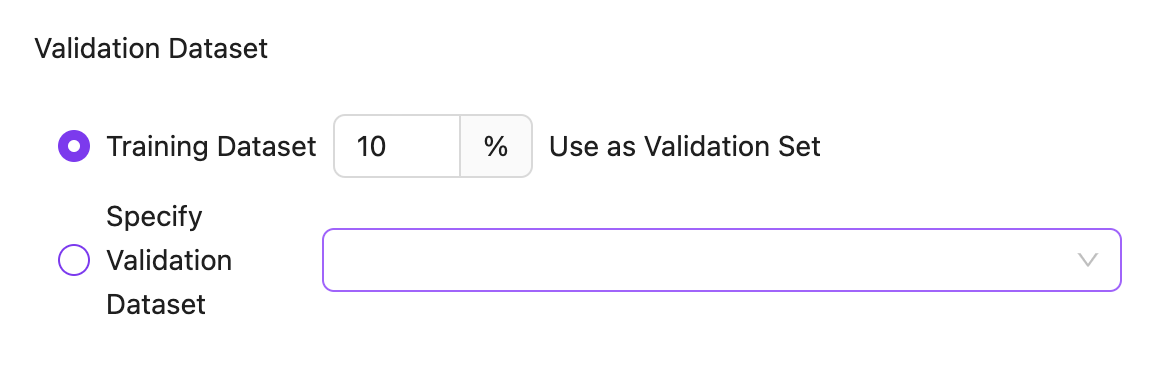
几个微调超参数说明:
轮数:表示模型已经看到了所有训练样本一次,轮数太大容易过拟合。
学习率: 学习率太大,模型每次调整的幅度就越大,进度就越快,但是也容易矫枉过正。
批量大小:批量处理快太大容易忽略细节
6.3. Colab 免费云端环境
免费的云端编程环境,可以使用免费的GPU 资源:
https://colab.research.google.com/
使用文档:https://colab.research.google.com/#scrollTo=gJr_9dXGpJ05
6.4. 基于Unsloth进行模型微调
开源工具,用来加速LLM 微调过程,可以直接在colab 上运行。

点击使用即可在colab 上运行python 代码 ,可直接看到基于千问大模型微调的运行的结果
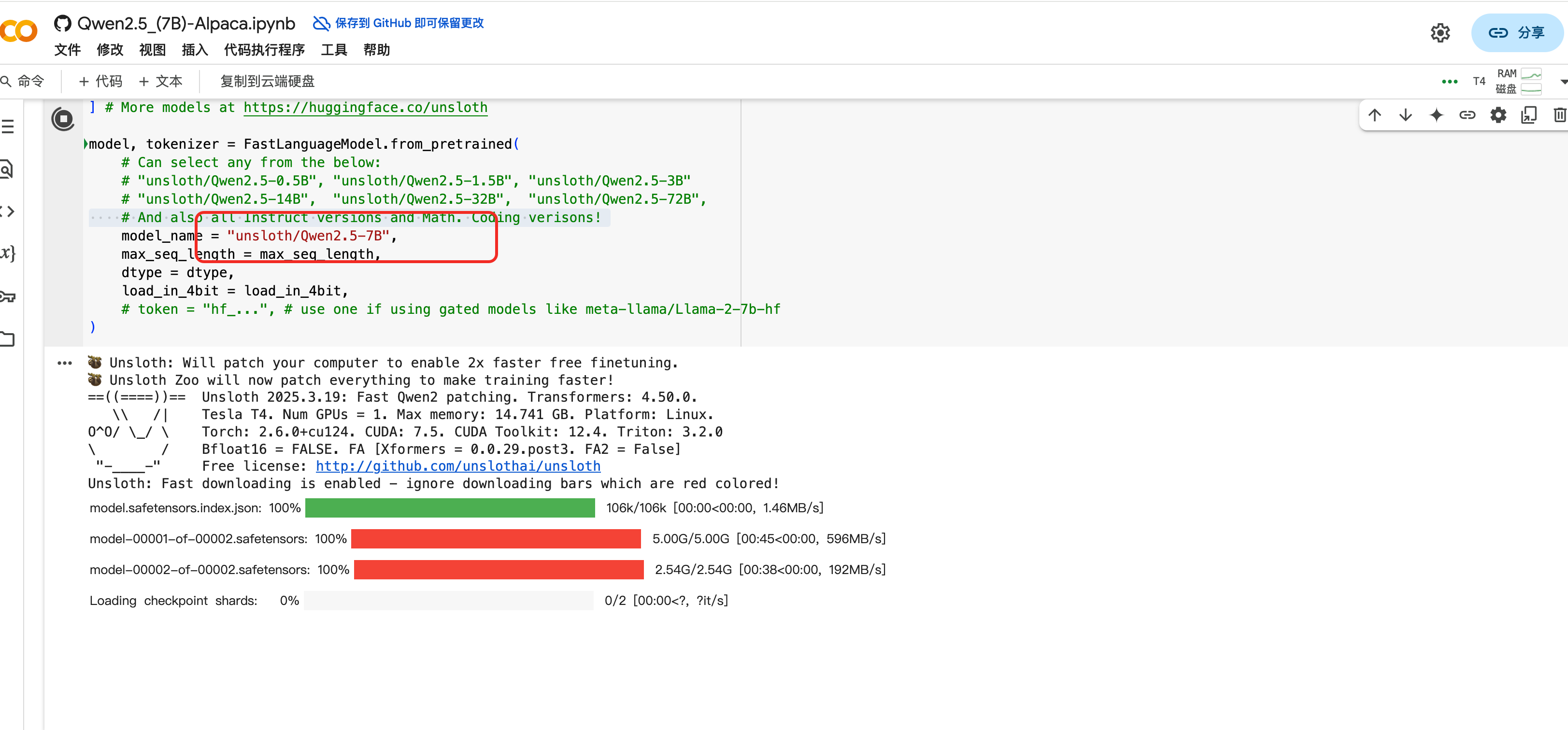
unsloth 微调例子,代码 (网上一个关于算命大师的例子) ,运行一下别人的例子来体验一下整个微调的过程:
https://colab.research.google.com/drive/1B4nS1L5_GuGHU4U8l-qI-Ej7EqeBNHg6
安装unsloth 的过程中就遇到了包冲突的问题,在colab 运行了好几次安装都失败了,因为使用colab要爬墙 ,流量有点浪费,就没有继续运行了
6.5. 基于LLaMA-Factory的微调
据说这个LLamMa-Factory 是目前国内比较火的微调平台,零代码微调,配备可视化页面,几行代码就可以实现模型微调,比较友好,这个logo 还蛮可爱的。

开源项目:LLaMA-Factory/README_zh.md at main · hiyouga/LLaMA-Factory · GitHub
使用文档:安装 - LLaMA Factory
colab :https://colab.research.google.com/drive/1d5KQtbemerlSDSxZIfAaWXhKr30QypiK?usp=sharing
微调步骤:
- 安装 LLaMA Factory 依赖
- 更新自我认知数据集
- 使用 LLaMA Board Web UI 微调模型
- 使用命令行微调模型
- 模型推理
- 合并 LoRA 权重并上传模型
colab运行:
在colab 上运行了下,页面可以启动了~72小时过期的link~
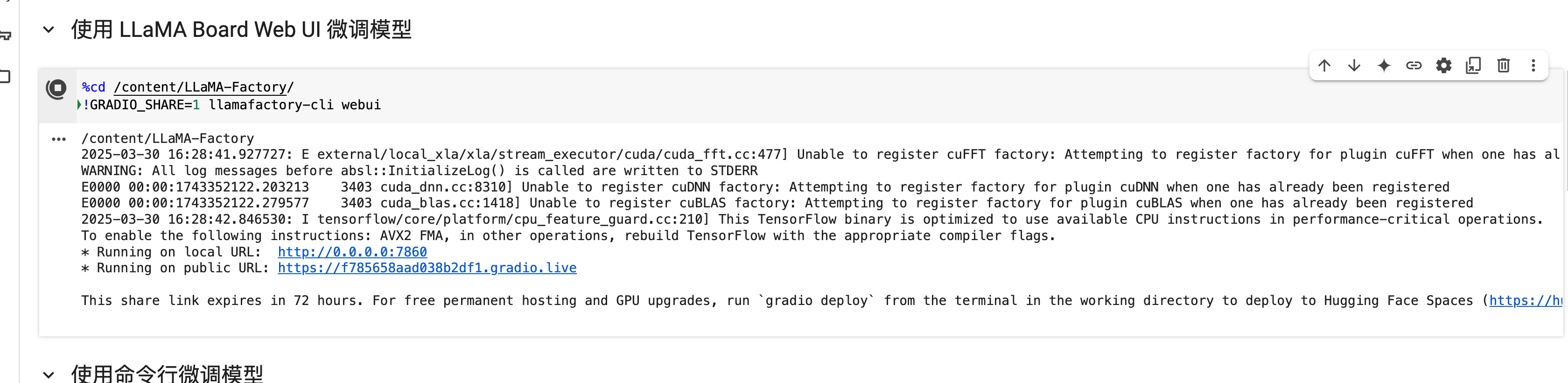
这里还用到了Gradio, 是一个开源的 Python 库,专注于快速构建机器学习模型的交互式演示界面。它简化了将模型或函数转化为可视化 Web 应用的过程,尤其适合机器学习开发者、数据科学家快速展示和分享成果。
页面:https://f785658aad038b2df1.gradio.live/ ,还支持多种语言展示,体验蛮友好的
6.6. 其他的一些微调平台
目前的一些支持微调的平台:

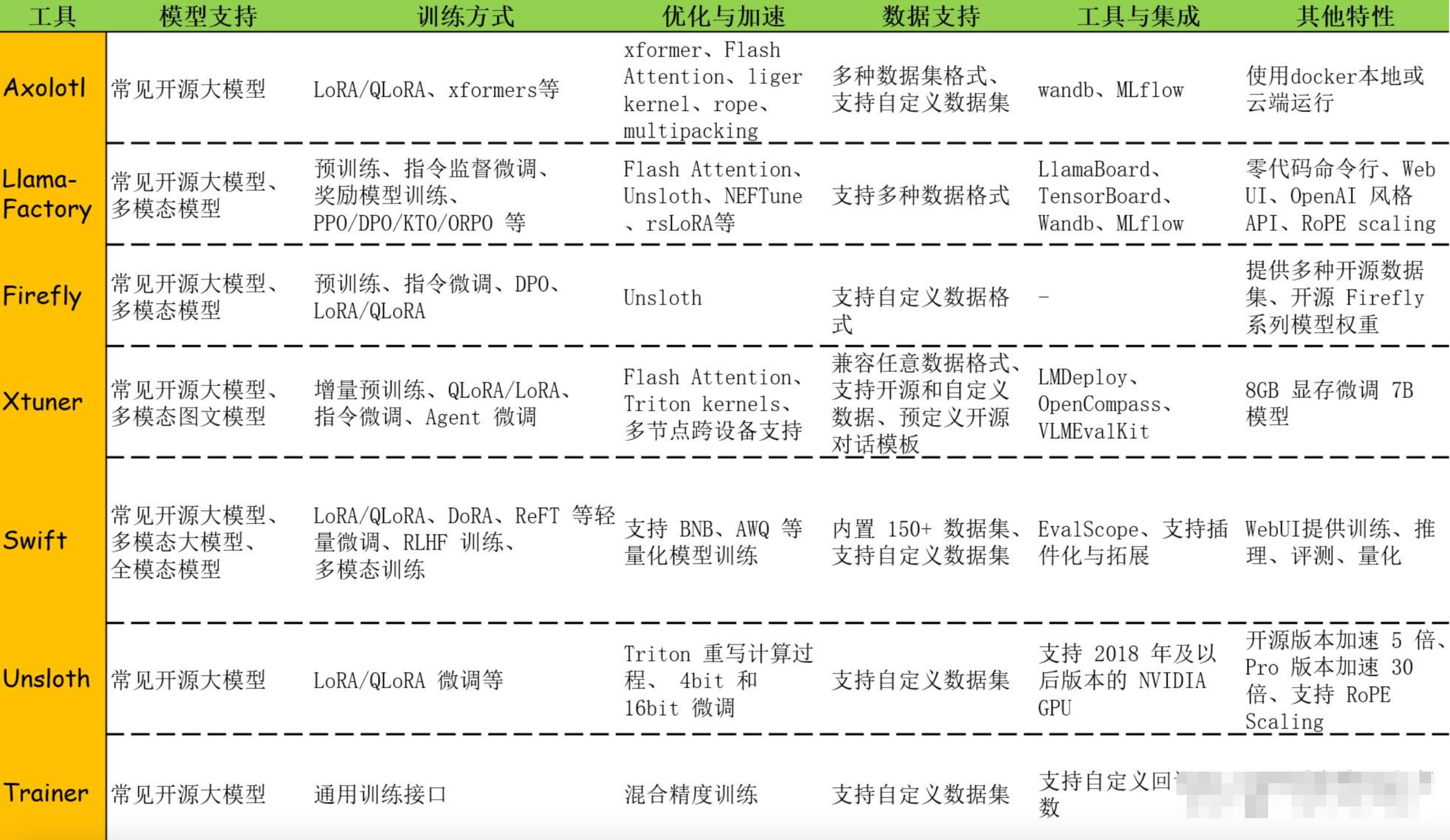
微调相关的还是要结合日常工作场景进行实际落地可能才会有更深的体会,自己学习练习还是少了深度的时候投入以及缺资源。
附件:
如何把你的 DeePseek-R1 微调为某个领域的专家?.pdf
网上资料:Docs

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)