
带你从入门到精通——自然语言处理(七. Transformer的解码器部分、输出部分和整体搭建)
建议先阅读我之前的博客,掌握一定的自然语言处理前置知识后再阅读本文,链接如下:带你从入门到精通——自然语言处理(一. 文本的基本预处理方法和张量表示)-CSDN博客带你从入门到精通——自然语言处理(二. 文本数据分析、特征处理和数据增强)-CSDN博客带你从入门到精通——自然语言处理(三. RNN扩展和LSTM)-CSDN博客带你从入门到精通——自然语言处理(四. GRU和seq2seq模型)-C
建议先阅读我之前的博客,掌握一定的自然语言处理前置知识后再阅读本文,链接如下:
带你从入门到精通——自然语言处理(一. 文本的基本预处理方法和张量表示)-CSDN博客
带你从入门到精通——自然语言处理(二. 文本数据分析、特征处理和数据增强)-CSDN博客
带你从入门到精通——自然语言处理(三. RNN的分类和LSTM)-CSDN博客
带你从入门到精通——自然语言处理(四. GRU和seq2seq模型)-CSDN博客
带你从入门到精通——自然语言处理(五. 自注意力机制和transformer的输入部分)-CSDN博客
带你从入门到精通——自然语言处理(六. Transformer的编码器部分)-CSDN博客
目录
七. Transformer的解码器部分、输出部分和整体搭建
七. Transformer的解码器部分、输出部分和整体搭建
7.1 掩码张量
7.1.1 填充掩码
填充掩码(Padding Mask)是指当一个批次中输入序列的长度不一致时,使用填充符将输入序列填充至统一长度,此时需要使用掩码用于标记这些填充位置,避免注意力机制对填充内容的无效关注,这种掩码即为填充掩码。
填充掩码的具体实现代码如下:
def create_padding_mask(seq, pad_token=0):
# 升维为了适配多头注意力机制
# 掩码张量值为0的区域表示被掩盖,值为1的区域表示保留
return (seq != pad_token).float().unsqueeze(1).unsqueeze(1)
if __name__ == '__main__':
# t为输入序列,形状为(batch_size, seq_len)
t = torch.tensor([[2, 4, 5, 0, 0], [1, 2, 0, 0, 0]])
t = create_padding_mask(t)
print(t)
print(t.shape)
'''
tensor([[[[1., 1., 1., 0., 0.]]],
[[[1., 1., 0., 0., 0.]]]])
torch.Size([2, 1, 1, 5])
'''7.1.2 因果掩码
在训练transformer的解码器时,由于目标序列是已知的,为了加速训练,我们通常是一次性将向右偏移一位后的目标序列全部送入解码器进行训练(即Teacher Forcing),此时如果不对目标序列进行掩码操作直接进行注意力计算,相当于解码器的输出token都是根据目标序列的所有信息而产生的,而在理论上解码器在预测一个token时,只能利用该token之前的目标序列的信息而不是目标序列的所有信息,而使用因果掩码(Causal Mask)则能够避免这种情况的发生,因果掩码能够掩盖未来的信息,防止由于模型提前利用未来的信息而造成的未来信息泄露,确保自回归模型的正确性。
因果掩码的具体实现代码如下:
def create_causal_mask(seq_len):
# torch.tril用于生成下三角矩阵,即使用0填充一个下三角,其他位置的值不变
# torch.triu用于生成上三角矩阵,即使用0填充一个上三角,其他位置的值不变
return torch.tril(torch.ones(seq_len, seq_len))
if __name__ == '__main__':
print(create_causal_mask(5))
'''
tensor([[1., 0., 0., 0., 0.],
[1., 1., 0., 0., 0.],
[1., 1., 1., 0., 0.],
[1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1.]])
'''因果掩码和填充掩码通常需要进行合并后送入多头注意力机制进行计算,合并的代码如下:
def merge_mask(p_mask, c_mask):
return p_mask.long() & c_mask.long()
if __name__ == '__main__':
input = torch.tensor([[2, 4, 5, 0, 0], [1, 2, 0, 0, 0]])
p_mask = create_padding_mask(input)
c_mask = create_causal_mask(5)
mask = merge_mask(p_mask, c_mask)
print(mask, mask.shape)
'''
tensor([[[[1, 0, 0, 0, 0],
[1, 1, 0, 0, 0],
[1, 1, 1, 0, 0],
[1, 1, 1, 0, 0],
[1, 1, 1, 0, 0]]],
[[[1, 0, 0, 0, 0],
[1, 1, 0, 0, 0],
[1, 1, 0, 0, 0],
[1, 1, 0, 0, 0],
[1, 1, 0, 0, 0]]]]) torch.Size([2, 1, 5, 5])
'''7.2 解码器层
解码器层是解码器的基本构建单元,一个解码器层能够根据编码器所提供的上下文张量c和当前已经生成的目标序列,以自回归的形式逐步预测下一个token,而每一个解码器层都能够继续处理上一个解码器层的输出,结合编码器所提供的上下文张量c,逐步生成更合理的输出序列。
注意:在训练阶段,解码器的输入是向右偏移一位后的真实的目标序列(通常被称为Ground Truth),并通过Teacher Forcing的方式进行训练;而在推理阶段,解码器没有真实的目标序列,只能使用自己已经生成的输出作为的输入。
解码器层主要包含三个子层连接结构:掩码多头注意力机制子层、多头注意力机制子层、前馈全连接子层。
注意:这里的掩码多头注意力机制子层是指添加了因果掩码的多头注意力机制子层(使用的是自注意力机制,即Q、K、V向量三者同源,都来自于解码器),这里的多头注意力机制子层使用的是交叉注意力机制(也被称为一般注意力机制),即Q、K、V向量三者不同源,Q向量来自解码器,K、V向量来自编码器(编码器的多头注意力机制子层使用的是自注意力机制,即Q、K、V向量三者同源,都来自于编码器)
解码器层的实现代码如下:
class DecoderLayer(nn.Module):
def __init__(self, embedding_size, multi_attn, multi_cross_attn, feed_forward, dropout_p=0.1):
super().__init__()
self.multi_attn = multi_attn
self.multi_cross_attn = multi_cross_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(embedding_size, dropout_p), 3)
def forward(self, x, m, src_mask=None, tgt_mask=None):
# m为编码器的输出
x = self.sublayer[0](x, lambda x: self.multi_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.multi_cross_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
if __name__ == '__main__':
src_ebd = MyEmbedding(5, 8)
tgt_ebd = MyEmbedding(4, 8)
pe = PositionalEncoding(8)
en_multi_attn = MultiHeadAttention(4, 8)
de_multi_attn = MultiHeadAttention(4, 8)
de_multi_cross_attn = MultiHeadAttention(4, 8)
en_ffn = FeedForward(8, 16)
de_ffn = FeedForward(8, 16)
encoder_layer = EncoderLayer(8, en_multi_attn, en_ffn)
encoder = Encoder(encoder_layer, 6)
decoder_layer = DecoderLayer(8, de_multi_attn, de_multi_cross_attn, de_ffn)
generator = Generator(8, 4)
src = torch.tensor([[2, 4, 1, 0], [1, 2, 0, 0]])
tgt = torch.tensor([[1, 3, 2, 0], [1, 3, 1, 0]])
src_mask = create_padding_mask(src)
tgt_mask = merge_mask(create_padding_mask(tgt), create_causal_mask(4))
src = pe(src_ebd(src))
tgt = pe(tgt_ebd(tgt))
c = encoder(src, src_mask)
t = decoder_layer(tgt, c, src_mask, tgt_mask)
print(t.shape)
# torch.Size([2, 4, 8])7.3 解码器
解码器是由多个编码器层堆叠而成(原论文中使用了6个解码器层),它负责根据编码器输出的上下文张量c来生成目标序列。
编码器的实现代码如下:
class Decoder(nn.Module):
def __init__(self, layer, N):
super().__init__()
self.layers = clones(layer, N)
def forward(self, x, m, src_mask=None, tgt_mask=None):
for layer in self.layers:
x = layer(x, m, src_mask, tgt_mask)
return x
if __name__ == '__main__':
src_ebd = MyEmbedding(5, 8)
tgt_ebd = MyEmbedding(4, 8)
pe = PositionalEncoding(8)
en_multi_attn = MultiHeadAttention(4, 8)
de_multi_attn = MultiHeadAttention(4, 8)
de_multi_cross_attn = MultiHeadAttention(4, 8)
en_ffn = FeedForward(8, 16)
de_ffn = FeedForward(8, 16)
encoder_layer = EncoderLayer(8, en_multi_attn, en_ffn)
encoder = Encoder(encoder_layer, 6)
decoder_layer = DecoderLayer(8, de_multi_attn, de_multi_cross_attn, de_ffn)
decoder = Decoder(decoder_layer, 6)
generator = Generator(8, 4)
src = torch.tensor([[2, 4, 1, 0], [1, 2, 0, 0]])
tgt = torch.tensor([[1, 3, 2, 0], [1, 3, 1, 0]])
src_mask = create_padding_mask(src)
tgt_mask = merge_mask(create_padding_mask(tgt), create_causal_mask(4))
src = pe(src_ebd(src))
tgt = pe(tgt_ebd(tgt))
c = encoder(src, src_mask)
t = decoder(tgt, c, src_mask, tgt_mask)
print(t.shape)
# torch.Size([2, 4, 8])7.4 输出部分
Transfomer的输出部分结构如下:
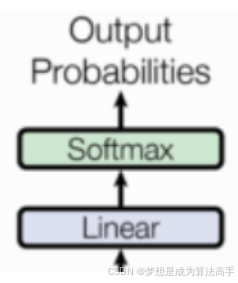
输出部分通常由一个线性层(Linear Layer)和一个Softmax函数组成,其具体工作流程为:线性层接收解码器最后一层的输出并将其embedding_size映射到tgt_vovab_size,即目标词汇表的大小,之后通过Softmax函数生成目标词的预测概率分布并选取概率最大的词作为目标词。
输出部分的实现代码如下:
class Generator(nn.Module):
def __init__(self, embedding_size, output_size):
super().__init__()
self.out = nn.Linear(embedding_size, output_size)
def forward(self, x):
return torch.log_softmax(self.out(x), dim=-1)
if __name__ == '__main__':
src_ebd = MyEmbedding(5, 8)
tgt_ebd = MyEmbedding(4, 8)
pe = PositionalEncoding(8)
en_multi_attn = MultiHeadAttention(4, 8)
de_multi_attn = MultiHeadAttention(4, 8)
de_multi_cross_attn = MultiHeadAttention(4, 8)
en_ffn = FeedForward(8, 16)
de_ffn = FeedForward(8, 16)
encoder_layer = EncoderLayer(8, en_multi_attn, en_ffn)
encoder = Encoder(encoder_layer, 6)
decoder_layer = DecoderLayer(8, de_multi_attn, de_multi_cross_attn, de_ffn)
decoder = Decoder(decoder_layer, 6)
generator = Generator(8, 4)
src = torch.tensor([[2, 4, 1, 0], [1, 2, 0, 0]])
tgt = torch.tensor([[1, 3, 2, 0], [1, 3, 1, 0]])
src_mask = create_padding_mask(src)
tgt_mask = merge_mask(create_padding_mask(tgt), create_causal_mask(4))
src = pe(src_ebd(src))
tgt = pe(tgt_ebd(tgt))
c = encoder(src, src_mask)
t = decoder(tgt, c, src_mask, tgt_mask)
t = generator(t)
print(t.shape)
# torch.Size([2, 4, 4])
7.5 Transform的整体搭建
Transform的整体搭建实现代码如下:
class MyTransformer(nn.Module):
def __init__(self, encoder, decoder, src_ebd, tgt_ebd, generator):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_ebd = src_ebd
self.tgt_ebd = tgt_ebd
self.generator = generator
def encode(self, src, src_mask):
return self.encoder(self.src_ebd(src), src_mask)
def decode(self, tgt, m, src_mask, tgt_mask):
return self.decoder(self.tgt_ebd(tgt), m, src_mask, tgt_mask)
def forward(self, src, tgt, src_mask, tgt_mask):
m = self.encode(src, src_mask)
output = self.decode(tgt, m, src_mask, tgt_mask)
return self.generator(output)
def makeModel(vocab_size, out_size, N=6, embedding_size=512, hidden_size=2048, h=8, dropout_p=0.1):
pe = PositionalEncoding(embedding_size, dropout_p)
en_multi_attn = MultiHeadAttention(h, embedding_size, dropout_p)
de_multi_attn = MultiHeadAttention(h, embedding_size, dropout_p)
de_multi_cross_attn = MultiHeadAttention(h, embedding_size, dropout_p)
en_ffn = FeedForward(embedding_size, hidden_size, dropout_p)
de_ffn = FeedForward(embedding_size, hidden_size, dropout_p)
model = MyTransformer(
Encoder(EncoderLayer(embedding_size, en_multi_attn, en_ffn, dropout_p), N),
Decoder(DecoderLayer(embedding_size, de_multi_attn, de_multi_cross_attn, de_ffn, dropout_p), N),
nn.Sequential(MyEmbedding(vocab_size, embedding_size), pe),
nn.Sequential(MyEmbedding(out_size, embedding_size), pe),
Generator(embedding_size, out_size)
)
return model
VOCAB_SIZE = 5
OUT_SIZE = 4
EMBEDDING_SIZE = 8
HIDDEN_SIZE = 16
N = 6
if __name__ == '__main__':
model = makeModel(VOCAB_SIZE, OUT_SIZE, N, EMBEDDING_SIZE, HIDDEN_SIZE)
src = torch.tensor([[2, 4, 1, 0], [1, 2, 0, 0]])
tgt = torch.tensor([[1, 3, 2, 0], [1, 3, 1, 0]])
src_mask = create_padding_mask(src)
tgt_mask = merge_mask(create_padding_mask(tgt), create_causal_mask(4))
output = model(src, tgt, src_mask, tgt_mask)
print(output.shape)
# torch.Size([2, 4, 4])
GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 24
24 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)