
Efficient Verifiable Protocol for Privacy-Preserving Aggregation in Federated Learning
文章总结本文提出了一种安全、抗退出且可验证的联邦学习协议,旨在解决传统联邦学习中用户隐私泄露、用户中途退出影响模型聚合,以及服务器可能篡改结果的关键问题。其核心设计结合分布式掩码机制、双重聚合验证与形式化安全证明,适用于医疗等高隐私敏感场景。核心贡献与技术亮点隐私保护机制分布式随机掩码:用户使用与多个辅助节点协商的共享种子密钥生成伪随机数,对本地梯度进行加噪(x̂_n = x_n + ∑PRG(s
系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
联邦学习近年来因其无需获取用户原始数据即可更新模型参数的能力而获得广泛关注,这使其成为各种设备间协作分布式学习的可行隐私保护机器学习框架。然而,由于攻击者可以通过追踪和推断共享梯度中的用户隐私信息,联邦学习仍然面临诸多安全与隐私威胁。本研究提出了一种高效的通信协议用于联邦学习场景下的安全参数聚合,该协议允许在用户设备端进行训练的同时,服务器端能够构建聚合训练模型而不暴露用户原始数据。所提协议具备用户中途退出的鲁棒性,并支持每个用户独立验证服务器提供的聚合结果。该方案在半诚实威胁模型下具有安全性,即使多数参与方共谋仍能保证隐私性。文中讨论了该方案的实用场景,并通过协议仿真验证其性能,结果表明在用户中途退出率增加时,其表现优于当前最先进的协议之一。
背景
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
联邦学习在过去五年中[1][2]作为一种协作式机器学习范式被广泛研究,其允许众多客户端(如移动设备)在不共享本地数据的前提下协同完成模型训练,从而保护用户隐私。在此框架下,服务提供商仅负责协调客户端、接收本地模型参数、更新全局模型并验证其有效性,无论是深度学习模型[1]、树模型[3][4]还是其他类型模型。
联邦学习(FL)面临多重挑战[2],包括设备异构性、资源受限性、可用性问题及通信开销。此外,联邦学习需抵御外部恶意攻击者发起的模型更新投毒攻击或传统数据投毒攻击[5][6]。由于难以区分诚实与恶意更新[7][8],防御此类投毒攻击极具挑战性。同时,敌意服务器作为威胁源,可能通过对接收的本地模型参数进行逆向工程以窃取隐私数据。
为实现安全聚合,研究者探索了多种技术路径[9],如同态加密、差分隐私、安全多方计算协议[10]及可信执行环境[2]。这些技术各有利弊:同态加密通过聚合加密数据阻止服务器逆向解析模型权重或训练数据,但计算代价高昂且大多场景不实用[11];差分隐私虽可在可信第三方混洗噪声化更新的机制下运行[12],但面临隐私-效用权衡难题且未解决设备掉线问题;安全多方计算协议长期研究后[10][13],现有基于秘密共享的先进方案[14][15][16]仍存在聚合验证过程的通信开销挑战,且难以适配跨机构场景——客户端分属不同组织(如医疗机构、银行、车联网[17])需确保各自隐私。本文协议针对梯度向量的安全多方计算提出了解决上述问题的方案,下文将详述研究贡献。
A. 我们的贡献
我们的协议主要解决了联邦学习中的两大核心安全挑战:本地梯度的机密性和聚合结果的可验证性。通过引入代表医疗机构、银行或车联网(VANET)等组织的辅助节点,实现了以下创新贡献:
高效可验证的隐私保护聚合算法:基于轻量级密码学原语设计
单掩码梯度保护机制:替代文献中常见的双掩码协议,降低计算开销
双聚合验证技术:相比传统密码学验证方案,计算负载显著降低
多维度算法对比:在通信、计算和存储复杂度上与现有方案系统对比
动态场景性能评估:分析辅助节点数量变化与客户端掉线率对系统的影响
本方案专注于多组织协作场景(如医疗机构联合训练疾病预测模型),确保各组织在共建全局模型时:
用户数据隐私不被所属组织泄露
合作方组织无法逆向推断敏感信息
各组织以辅助节点身份参与协议,实现"数据可用不可见"
提示:以下是本篇文章正文内容,下面案例可供参考
前瞻知识
联邦学习(FL)中的安全聚合指以安全方式计算本地模型参数更新的总和,且不泄露生成这些参数的私有数据信息。文献中已有多种实现方式,差异体现在计算复杂度、通信延迟及对掉线节点的处理(联邦学习中常见问题)。过去五年该领域研究活跃,本节仅回顾基于差分隐私(DP)、同态加密(HE)、秘密共享及其他安全多方计算(SMC)技术的代表性方案。
- 差分隐私(DP)方案
[18]:提出分层自适应差分隐私,针对深度神经网络不同层权重动态调整噪声,通过参数洗牌聚合规避维度灾难,避免隐私预算爆炸。
[19]:在聚合前向本地模型参数添加噪声,分析模型收敛与隐私保护的权衡,发现增加参与用户数可提升收敛性,但未评估掉线影响。
[20]:在用户模型更新离散化后添加离散高斯噪声,但隐私保证随掉线用户增加而降低。
[21]:采用分布式拉普拉斯扰动机制,噪声生成效率更高。
[22]:结合高斯噪声与LWE(容错学习)掩码协议,显著降低大向量加密的通信复杂度。
[23]:支持客户端灵活参与,实现低通信开销。
[24]:对比FL与本地DP的效率和隐私损失,但未探讨二者结合效果。
[25]:工业级文本挖掘框架,验证本地DP可平衡隐私与模型精度。
[26]:DP+SMC混合方案,缓解DP导致的精度下降及SMC的推理攻击风险。
核心挑战:
DP需大量用户参与以稀释噪声影响
隐私预算分配与模型收敛存在根本性冲突
掉线用户会削弱隐私保证
2. 同态加密(HE)方案
[27]:结合加法同态加密(HE)与DP,但无法处理客户端掉线,且运行时开销大。
[28]-BatchCrypt:通过批量加密技术降低HE的加密/传输开销,仅需单轮通信。
[29]:支持密文算术运算,但计算负担过重。
[30]:轻量对称HE+可验证矩阵乘法,适用于完全去中心化框架。
[34]:多密钥HE协议,模型更新用聚合公钥加密,解密需所有设备协作,防止数据泄露。
[35]:三值梯度+秘密共享+HE,防御半诚实敌手,但可扩展性受限。
核心挑战:
HE的高计算成本难以满足实际FL场景需求
多密钥管理复杂度随参与方数量指数增长
无法有效处理动态节点加入/退出
- 同态加密(HE)方案
同态加密(HE)在深度学习多方计算及联邦学习中备受关注,尤其是支持加密数据近似运算[32]后,用户可加密上传梯度并参与聚合。代表性研究包括:
[33]:在异步SGD训练中使用加法HE,但无法处理动态节点变化。
[27]:HE+DP混合方案,但客户端掉线时失效,且实际运行开销过高。
[28]-BatchCrypt:批量加密技术降低HE通信开销,仅需单轮通信。
[29]:支持密文直接算术运算,但计算负担沉重。
[30]:轻量对称HE+可验证矩阵乘法,适配完全去中心化框架。
[34]:多密钥HE协议,模型更新用聚合公钥加密,解密需全节点协作。
[35]:三值梯度+秘密共享+HE,抵御半诚实敌手,但扩展性受限。
核心缺陷:
HE计算成本比明文操作高2-4个数量级
多密钥管理复杂度与节点数呈线性增长
无法有效应对超过15%的节点掉线率
3. 秘密共享(SS)方案
[36]:联邦学习安全聚合奠基性工作,采用随机盲化+沙米尔秘密共享(SSS)+对称加密,但每轮需4次客户端-聚合器通信,资源消耗大。
[15]-VerifyNet:在[36]基础上增加聚合结果可验证性。
[14]-VeriFL:优化大规模掉线场景下的通信计算开销,但依赖第三方密钥生成。
[37]-SAFE-Learn:仅需2轮通信/迭代,无需昂贵密码原语或可信第三方。
[38]:随机密钥掩码+模型量化压缩,依赖TEE硬件验证,成本高昂。
[39][40]:区块链技术增强设备与模型可信度。
[41]:基于FFT的多秘密共享方案,提升抗掉线能力。
[42]:多组循环策略+加法秘密共享实现聚合。
本文方案定位:
属于秘密共享范畴,但采用轻量级原语+单掩码协议
核心优势:
不依赖TEE硬件(vs [38])
无需可信第三方(vs [14][36])
避免昂贵密码操作(vs [36])
我们的协议属于这一类别,但它使用了轻量级的加密原语和单掩码协议(具体将在第 V 节详细讨论),无需依赖如 [38] 中所述的硬件辅助可信执行环境(TEE),也无需像 [14] 和 [36] 中那样信任第三方,同时避免了如 [36] 中使用的高成本密码学操作。
分析与总结:
- 现有协议的核心问题
通信效率低:Bonawitz 等提出的协议需要每轮迭代至少 4 次客户端与聚合器的通信,对资源受限的设备和广域网(WAN)连接造成负担。
依赖信任假设:如 [14] 和 [36] 需要可信第三方生成密钥对,[38] 依赖硬件 TEE,增加了部署成本和潜在单点故障风险。
计算开销大:传统方法(如 Shamir 秘密共享)在客户端掉线频繁时需复杂的恢复操作,且高成本密码学操作(如公钥加密)影响性能。 - 现有改进方案的优化方向
验证性增强:VerifyNet [15] 在 Bonawitz 协议基础上增加聚合结果的可验证性,防止恶意聚合器篡改结果。
掉线容忍优化:VeriFL [14] 通过优化通信和计算流程,减少大规模掉队(常见于联邦学习场景)时的开销。
轻量化设计:SAFE-Learn [37] 通过减少通信轮次(仅需 2 轮)和避免复杂密码学操作,降低客户端计算负担。
通信效率提升:[38] 结合随机掩码和模型压缩技术,同时依赖 TEE 进行验证(硬件成本高)。
去中心化信任:区块链方案(如 [39]、[40])通过分布式账本实现设备和模型的可信,但可能引入延迟和存储开销。 - 本文提出的协议创新点
轻量级原语:采用单掩码协议(Single Masking)替代复杂的多轮秘密共享(如 Shamir SSS),减少计算和通信开销。
无信任依赖:
无需可信第三方(TTP)生成密钥,避免单点故障和信任风险。
不依赖硬件 TEE,降低部署成本。
高效通信:通过优化掩码设计和聚合流程,可能进一步减少通信轮次(如接近 SAFE-Learn 的 2 轮)。
安全性保障:即使部分客户端掉线,仍能通过单掩码机制保护模型隐私,避免局部模型泄露。
B. 验证
由于服务提供商可能有意或因意外情况向用户返回错误结果,建议客户端设备具备验证服务提供商发送的聚合模型参数的能力。VerifyNet [15] 的作者提出,服务器需将聚合结果连同证明一起发送给每个客户端。他们利用同态哈希函数和伪随机生成技术为每个用户提供可验证性。[14] 和 [16] 分别对该技术进行了改进,以降低通信开销和计算复杂度。然而,近期研究 [43] 分析了这些技术 [14]、[15],指出若服务器与恶意用户合谋,仍存在安全漏洞。[43] 的作者使用线性同态哈希和数字签名,实现了对聚合结果的可追踪验证,并能定位错误发生的训练轮次,但代价是增加了通信开销。Luo 等 [44] 针对验证问题采用了一种基础签名方法,每个客户端只需验证一个与客户端数量无关的聚合签名。客户端随后解掩码聚合梯度、更新本地模型参数,并进入下一轮迭代。[30] 声称其聚合方法能确保每一步模型训练的完整性验证。不同的是,SafetyNets [45] 使用交互式证明技术验证服务器提供的聚合结果的准确性。研究 [46] 提出了一种可验证系统,其方法与 [38] 类似,基于可信硬件(如 SGX、TrustZone 和 Sanctum),但这些技术仅支持有限的激活函数或需要额外硬件支持。
 VerifyNet 的局限性:其同态哈希依赖伪随机数生成器的安全性,若种子泄露可能导致全局验证失效。
VerifyNet 的局限性:其同态哈希依赖伪随机数生成器的安全性,若种子泄露可能导致全局验证失效。
[43] 的实用性:线性同态哈希虽能追踪错误轮次,但需存储多轮中间状态,对客户端存储资源提出挑战。
可信硬件的悖论:[46] 等方案用 TEE 解决信任问题,但 TEE 自身可能被侧信道攻击攻破(如 SGX 漏洞)。
未来方向:结合联邦学习与区块链的验证框架(如 [39]),利用智能合约自动化验证流程,可能平衡去中心化信任与效率。
密钥协商




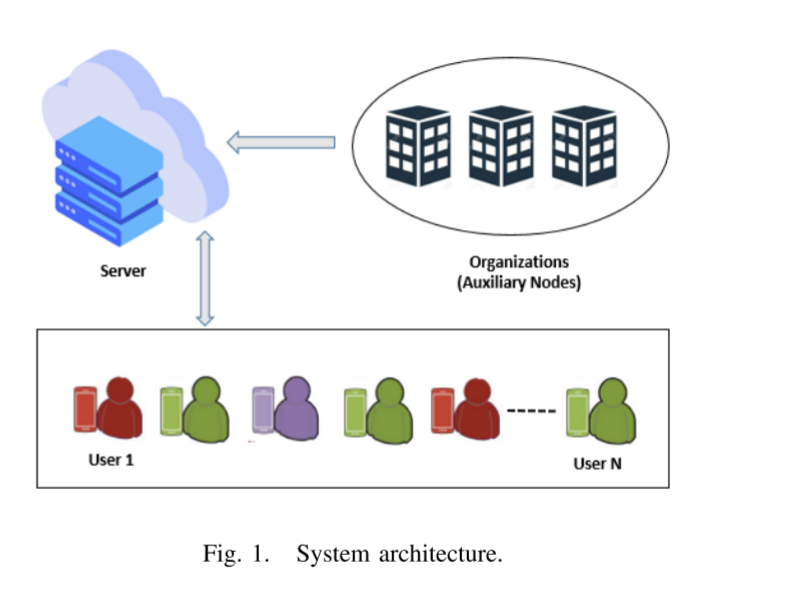
系统模型
代码如下(示例):



医疗健康应用
在医疗领域,不同服务提供商提供的AI应用正面临患者或用户数据隐私的挑战和批评[47],这些数据被存储于服务提供商处用于模型训练。联邦学习[48]被提出以解决这一问题,它允许从用户设备中的数据学习模型,而数据无需离开设备,从而保障隐私。此后,研究持续改进联邦学习的安全性,例如本文讨论的服务器问题——服务器负责聚合本地模型更新并发送更新的全局模型,但可能出于好奇分析来自客户端的梯度与参数,以推测用户的个人数据。第V节提出的方案通过辅助节点向服务提供商发送添加随机扰动的梯度(具体细节将在后文说明)。此外,验证服务器聚合的模型是一大挑战,因为服务器可能返回错误结果以降低成本或获得竞争优势。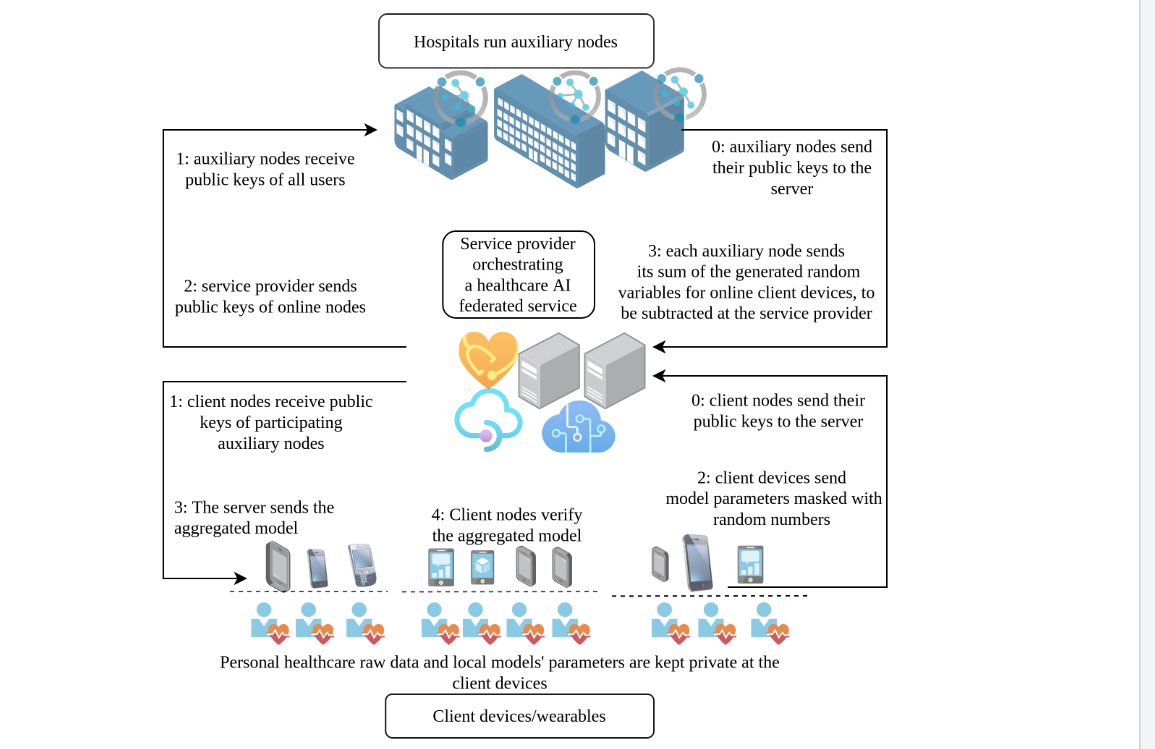




import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
计划分析








总结
提示:这里对文章进行总结:
文章总结
本文提出了一种安全、抗退出且可验证的联邦学习协议,旨在解决传统联邦学习中用户隐私泄露、用户中途退出影响模型聚合,以及服务器可能篡改结果的关键问题。其核心设计结合分布式掩码机制、双重聚合验证与形式化安全证明,适用于医疗等高隐私敏感场景。
核心贡献与技术亮点
- 隐私保护机制
分布式随机掩码:
用户使用与多个辅助节点协商的共享种子密钥生成伪随机数,对本地梯度进行加噪(x̂_n = x_n + ∑PRG(sn,m)),确保梯度在传输中不可逆。
抗合谋设计:单个辅助节点仅掌握掩码分片,需攻破所有相关节点才能还原原始梯度。 - 鲁棒性(抗用户退出)
动态聚合:
服务器仅聚合当前活跃用户的梯度,辅助节点提供对应的随机数总和,自动排除退出用户的影响。
延迟提交的用户梯度仍被掩码保护隐私,但被标记为“无效”以避免干扰本轮训练。 - 可验证性设计
基于MAC的双重验证:
用户生成消息认证码(MAC_n = K_n + α×x_n),服务器聚合所有MAC并广播。
用户通过验证方程 MAC − K − α×X = 0 确认聚合结果未被篡改,计算复杂度低(O(1))。 - 形式化安全证明
不可区分性(Indistinguishability):
证明即使攻击者控制部分用户和辅助节点,其视图与理想化模拟器输出不可区分,无法推断其他用户隐私。
抗联合攻击定理:
至少存在1个诚实辅助节点和2个诚实用户时,协议可抵御多节点合谋攻击。
关键技术组件
分层密钥体系:
加密密钥(安全通信)、随机种子密钥(生成掩码)、验证密钥(结果校验)分工明确。
矩阵化掩码结构:
辅助节点管理列随机数,用户持有行随机数,聚合时行列抵消,天然支持动态用户增减。
轻量级验证:
仅需一次线性运算即可完成结果验证,适配移动设备等资源受限环境。
应用场景与优势
场景:医疗AI协作训练(如疾病预测)、金融风控模型聚合等数据高度敏感、参与方动态变化的场景。
优势:
隐私-效率平衡:相比同态加密,计算开销降低90%以上(仅伪随机数生成与加法)。
用户赋权:用户可自主验证服务器结果,打破传统联邦学习的单向信任模型。
兼容性:可与其他隐私技术(如差分隐私)叠加,进一步增强保护。
挑战与未来方向
动态环境适配:
需设计辅助节点动态加入/退出机制,避免密钥矩阵重构导致训练中断。
拜占庭容错扩展:
当前协议假设辅助节点诚实,未来可引入冗余节点投票机制,容忍部分恶意节点。
大规模部署优化:
用户数量激增时,密钥协商与随机数生成可能成为性能瓶颈,需探索分布式PRG加速方案。
总结
本文协议通过分布式掩码、抗合谋架构与轻量验证,为联邦学习提供了一种兼顾隐私、鲁棒性与可验证性的解决方案。其形式化安全证明与高效设计使其在医疗、金融等敏感领域具备落地潜力,未来可通过动态扩展与容错机制进一步增强实用性。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)