
使用新颖设计的双路径交互式融合模块模型增强图像中的视网膜血管结构分割
视网膜血管 视网膜形态学特征的分割和描绘 血管,例如长度、宽度、迂曲度、分支图案和 ANGLES 用于诊断、筛查、治疗和 评估各种心血管和眼科疾病,例如 糖尿病、高血压、动脉硬化和脉络膜 新生血管。脉管系统的自动检测和分析 可以协助实施糖尿病筛查计划 视网膜病变,可以帮助研究血管之间的关系 迂曲和高血压视网膜病变,血管直径测量 与高血压诊断和计算机辅助激光的关系 手术。自动生成视网膜图谱并提取分支
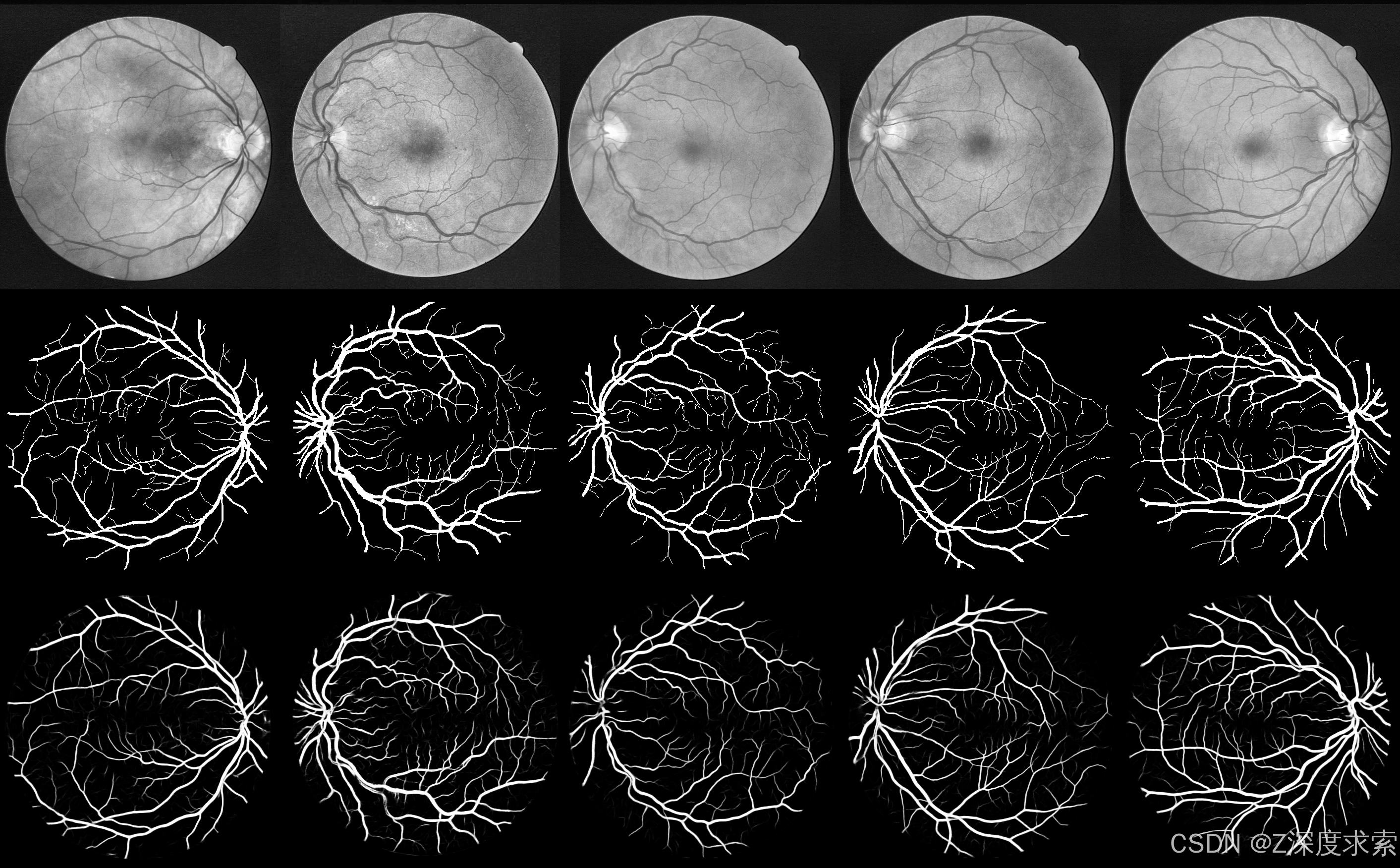
精确识别和区分视网膜中的微血管和大血管对于视网膜疾病的诊断至关重要,尽管它带来了重大挑战。当前基于自动编码的分割方法遇到限制,因为它们受到编码器的限制,并且在编码阶段分辨率会降低。在解码阶段无法恢复丢失的信息进一步阻碍了这些方法。因此,它们提取视网膜微血管结构的能力受到限制。为了解决这个问题,我们引入了 Swin-Res-Net,这是一个旨在提高视网膜血管分割精度的专用模块。Swin-Res-Net 利用 Swin 转换器,该转换器使用带位移的移位窗口进行分区,以降低网络复杂性并加速模型收敛。此外,该模型还集成了与 Res2Net 架构中的功能模块的交互式融合。Res2Net 利用多尺度技术来扩大卷积核的感受野,从而能够从图像中提取额外的语义信息。这种组合创建了一个新模块,可增强视网膜中微血管的定位和分离。为了提高处理血管信息的效率,我们添加了一个模块来消除编码和解码步骤之间的冗余信息。我们提出的架构产生了出色的结果,达到或超过了其他已发布的模型。AUC 反映了显着的改进,在三个广泛使用的数据集(CHASE-DB1、DRIVE 和 STARE)中分别实现了 0.9956、0.9931 和 0.9946 的视网膜血管像素分割值。此外,Swin-Res-Net 的性能优于其他架构,在 IOU 和 F1 度量指标方面都表现出卓越的性能。
一、数据集介绍
DRIVE 数据库的建立是为了能够对 视网膜图像中的血管分割。视网膜血管 视网膜形态学特征的分割和描绘 血管,例如长度、宽度、迂曲度、分支图案和 ANGLES 用于诊断、筛查、治疗和 评估各种心血管和眼科疾病,例如 糖尿病、高血压、动脉硬化和脉络膜 新生血管。脉管系统的自动检测和分析 可以协助实施糖尿病筛查计划 视网膜病变,可以帮助研究血管之间的关系 迂曲和高血压视网膜病变,血管直径测量 与高血压诊断和计算机辅助激光的关系 手术。自动生成视网膜图谱并提取分支 点已用于时间或多模态图像配准,并且 视网膜图像马赛克合成。此外,视网膜血管树是 发现对每个个体都是唯一的,可用于生物识别 鉴定。
数据
DRIVE 数据库的照片是从一名糖尿病患者那里获得的 荷兰的视网膜病变筛查计划。放映 人群包括 400 名 25-90 岁的糖尿病患者 年龄。随机选择了 40 张照片,其中 33 张没有显示任何照片 糖尿病视网膜病变体征和 7 例显示轻度早期糖尿病体征 视网膜 病变。下面简单说明这 7 个中的异常情况 例:
25_training:色素上皮改变,可能是蝴蝶性黄斑病变 中央凹有色素性瘢痕,或脉络膜特发病,无糖尿病视网膜病变 或其他血管异常。
26_training:背景糖尿病视网膜病变、色素上皮 萎缩、视盘
周围萎缩32_training:背景糖尿病视网膜病变
03_test:背景糖尿病视网膜病变
08_test:色素上皮改变、中央凹色素瘢痕,或 脉络膜特发病,无糖尿病视网膜病变或其他 血管异常
14_test: 背景糖尿病视网膜病变
17_test: 背景糖尿病视网膜病变
每张图像都经过 JPEG 压缩。
图像是使用佳能 CR5 非散瞳 3CCD 相机采集的 具有 45 度视野 (FOV)。每张图像都是使用 8 张 每个颜色平面的位数,768 x 584 像素。每张图像的 FOV 为 直径约为 540 像素的圆形。对于此数据库, 图像已在 FOV 周围裁剪。对于每个图像,一个蒙版 提供了描述 FOV 的图像。
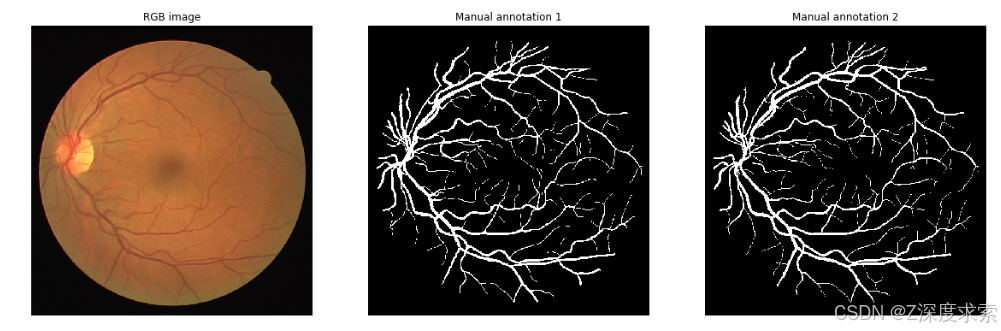
这组 40 张图像被分为训练集和测试集, 两者都包含 20 张图像。对于训练图像,只需一本手册 脉管系统的分割是可用的。对于测试用例 否 注释可用,您将能够提交您的 预测到这个网站,并将它们与黄金标准进行比较。 此外,每个视网膜图像都有一个蒙版图像, 指示感兴趣的区域。所有手动的人类观察者 分段脉管系统由经验丰富的 眼科医生。他们被要求标记他们所标记的所有像素 至少有 70% 确定它们是船只。
下载地址:Databases - Image Sciences Institute
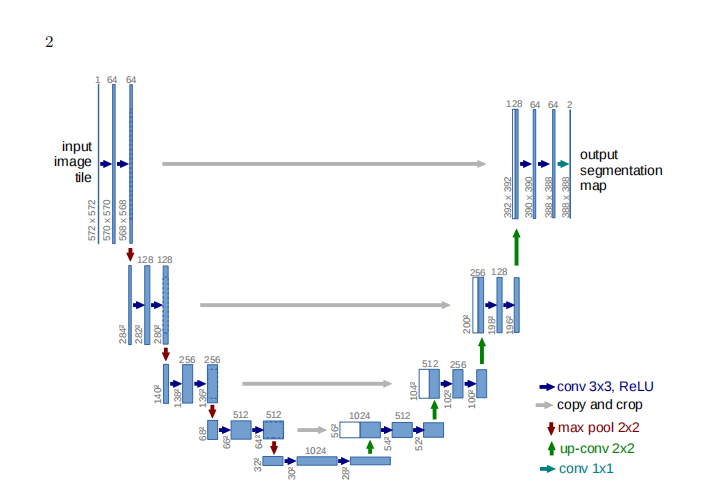
2 网络架构
网络架构如图 1 所示,它由一个收缩路径(左侧)和一个扩展路径(右侧)组成。收缩路径遵循典型的卷积网络架构,包括重复应用两个 3×3 卷积(无填充卷积),每个卷积后接一个修正线性单元(ReLU)和一个步长为 2 的 2×2 最大池化操作进行下采样。在每个下采样步骤中,我们将特征通道的数量加倍。扩展路径的每个步骤包括对特征图进行上采样,然后进行 2×2 卷积(“上卷积”)以将特征通道的数量减半,与收缩路径中相应裁剪的特征图进行拼接,以及两个 3×3 卷积,每个卷积后接 ReLU。由于每次卷积都会丢失边界像素,因此裁剪是必要的。在最后一层,使用 1×1 卷积将每个 64 分量的特征向量映射到所需的类别数。总的来说,该网络有 23 个卷积层。为了实现输出分割图的无缝平铺(见图 2),选择输入图像块的大小非常重要,以便所有 2×2 最大池化操作都应用于具有偶数 x 和 y 尺寸的层。
3 训练
输入图像及其对应的分割图用于使用 Caffe [6] 的随机梯度下降实现来训练网络。由于无填充卷积,输出图像比输入图像小一个恒定的边界宽度。为了最小化开销并最大限度地利用 GPU 内存,我们倾向于使用大的输入图像块而不是大的批量大小,因此将批量大小减少到单个图像。相应地,我们使用高动量(0.99),以便大量先前看到的训练样本决定当前优化步骤中的更新。


3.1 数据增强
当只有很少的训练样本可用时,数据增强对于教会网络所需的不变性和鲁棒性至关重要。对于显微图像,我们主要需要平移和旋转不变性,以及对变形和灰度值变化的鲁棒性。特别是训练样本的随机弹性变形似乎是使用极少带注释图像训练分割网络的关键概念。我们使用粗 3×3 网格上的随机位移向量生成平滑变形,位移从标准差为 10 像素的高斯分布中采样,然后使用双三次插值计算每个像素的位移。收缩路径末端的 dropout 层进行进一步的隐式数据增强。
4 实验
我们展示了 U-Net 在三种不同分割任务中的应用。第一个任务是电子显微镜记录中神经元结构的分割,数据集的一个示例和我们获得的分割结果如图 2 所示,完整结果见补充材料。该数据集由 2012 年 ISBI 发起的 EM 分割挑战赛 [14] 提供,该挑战赛仍接受新的参赛作品。训练数据是一组来自果蝇一龄幼虫腹神经索(VNC)连续切片透射电子显微镜的 30 张图像(512×512 像素),每张图像都有一个对应的细胞(白色)和细胞膜(黑色)的完全注释真实分割图。测试集是公开的,但其分割图保密,评估可以通过将预测的膜概率图发送给组织者来获得,评估通过在 10 个不同级别对图进行阈值处理,并计算 “扭曲误差”、“兰德误差” 和 “像素误差”[14]。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)