
Python - 文件操作;OS模块操作文件(九)
文件一般操作步骤1、打开文件2、读/写文件3、保存文件4、关闭文件,我们打开一个文件时,可以给它指定一个编码类型。
一、文件操作
文件一般操作步骤
1、打开文件
2、读/写文件
3、保存文件
4、关闭文件
文件中默认的编码是gbk(中文编码),我们打开一个文件时,可以给它指定一个编码类型
1、打开文件
在Python中打开文件使用open函数,可以打开一个已经存在的文件,或者创建一个新文件
语法格式: open('文件名称','打开模式’)
示例:
open('test.txt','w’)在Python中,文件的打开模式主要有以下几种:
'r':只读模式,文件必须存在。
'w':写模式,文件存在则清空,不存在则创建。
'x':写模式,创建新文件,如果文件存在则报错。
'a':追加模式,文件存在则在末尾追加,不存在则创建。
'b':二进制模式,与其他模式结合使用,如 'rb', 'wb', 'ab'。
't':文本模式,与其他模式结合使用,默认模式,如 'rt', 'wt', 'xt'。
'+':更新模式,与 'r', 'w', 'x', 或 'a' 结合使用,在原有功能上增加读写功能

2、 关闭文件
语法格式: close() 方法关闭文件
示例:
f = open('text.txt','w’)
f.close() 注: 打开一个文件之后,一定要关闭,否则后面无法继续操作这个文件
3、with 上下文管理
with 语句,不管在处理文件过程中是否发生异常,都能保证 with 语句执行完毕后已经关闭打开的文件句柄
示例:
def main():
with open('setup.py','w') as f:
content = f.read()
print(content)
main() 4、写文件
写入文件 write() 方法,参数就是需要写入的内容
# 写模式打开一个test.txt 文件
f = open('test.txt', 'w’)
f.write('我爱中国') # write方法写入内容
f.close() # 关闭文件 writelines() 可传一个可迭代对象
# 写模式打开一个test.txt 文件
f = open('test.txt', 'w’)
# writelines 方法将可迭代对象,迭代写入文件
f.writelines(['我','爱','我的','国家'])
f.close() # 关闭文件 5、读文件
读取文件 read() ,将文件的内容全部读取出来
# 写模式打开一个test.txt 文件
f = open('test.txt', 'r’)
f.read() # 一次性将文件内容全部取出
f.close() # 关闭文件 读取指定字符个数 read(num)传入一个数字做参数,表示读取指定字符个数
# 写模式打开一个test.txt 文件
f = open('test.txt', 'r’)
content = f.read(2) # 读取两个字符
print(content)
content = f.read()
print(content) # 第二次读取将从第一次读取的位置继续读取
f.close() # 关闭文件 readlines() 按行读取,一次性读取所有内容,返回一个列表,每一行内容作为一个元素
# 写模式打开一个test.txt 文件
f = open('test.txt', 'w’)
# 写入多行hello world
f.write('hello world\nhello world\nhello world\nhello world\nhello world\nhello world\n’)
f.close()
#打开文件test.txt
f = open('test.txt', 'r’)
content = f.readlines() # 一次性读取所有内容,返回一个列表,列表元素为每一行内容
print(content)
f.close() # 关闭文件 '''
文件一般操作步骤
1、打开文件
2、读/写文件
3、保存文件
4、关闭文件
文件中默认的编码是gbk(中文编码),我们打开一个文件时,可以给它指定一个编码类型
'''
from 函数.内置函数 import data1
# 'a':追加模式,文件存在则在末尾追加,不存在则创建
fileObj = open('./test.txt','a')
# !!!如果文件过大,还没有及时释放,会导致内存泄露
fileObj.close()
# 没有指定编码格式,中文默认是gbk
fileObj = open('./test.txt','w')
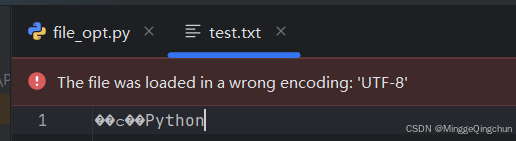
fileObj.write('我喜欢Python') # ��ϲ��Python
fileObj.close()
'''
写操作
'''
# 指定编码格式 UTF-8
fileObj = open('./test.txt','w',encoding='utf-8')
fileObj.write('我喜欢Python')
fileObj.write('我也喜欢Java\r\n') # 换行
fileObj.write('程序员小明')
fileObj.close()
# 以二进制的形式写数据
fobj=open('./test1.txt','wb') #str-->bytes
# TypeError: a bytes-like object is required, not 'str'
# fobj.write('我喜欢写诗')
fobj.write('我喜欢写诗'.encode('utf-8'))
fobj.close()
'''
读操作
'''
# r 只读模式,文件必须存在
print('--------r读数据--------')
fileObj = open('./test.txt','r',encoding='utf-8')
# read()读取所有的数据
data1 = fileObj.read()
print(data1)
# 我喜欢Python我也喜欢Java
#
# 程序员小明
print('--------二进制读数据--------')
# rb 二进制模式打开一个文件只读
fileObj = open('./test.txt','rb')
# ValueError: binary mode doesn't take an encoding argument
# fileObj = open('./test.txt','rb',encoding='utf-8')
data2 = fileObj.read()
# b'\xe6\x88\x91\xe5\x96\x9c\xe6\xac\xa2Python\xe6\x88\x91\xe4\xb9\x9f\xe5\x96\x9c\xe6\xac\xa2Java\r\r\n\xe7\xa8\x8b\xe5\xba\x8f\xe5\x91\x98\xe5\xb0\x8f\xe6\x98\x8e'
print(data2)
print('--------读数据--------')
f = open('./test1.txt','rb')
data = f.read() #读取所有的数据
print(data) # b'\xe6\x88\x91\xe5\x96\x9c\xe6\xac\xa2\xe5\x86\x99\xe8\xaf\x97'
# 使用gbk写入,也只能GBK读取,不然报错:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd4 in position 0: invalid continuation byte
print(data.decode('utf-8')) # 我喜欢写诗
# 使用UTF-8写入,也只能UTF-8读取,不然报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xa2 in position 8: illegal multibyte sequence
# decoding with 'gbk' codec failed
# print(data.decode('gbk'))
# 读取指定字符个数 read(num)传入一个数字做参数,表示读取指定字符个数
print(f.read(12)) # b''
# 读一行数据
print(f.readline()) # b''
print(f.readlines(1)) # []
# 如果文件对象#数据比较大时,文件一直不关闭会导致资源内存不能被释放,从而内存泄露
f.close() #文件对象关闭掉
'''
with上下文管理对象
with 语句,不管在处理文件过程中是否发生异常,都能保证 with 语句执行完毕后已经关闭打开的文件句柄
优点:自动释放打开关联的对象,不需要调用close()方法
'''
with open('./test.txt','a') as f:
f.write('python非常好学\n')
#print(f.read())
'''
小结
文件读写的几种操作方式
1、read:r,r+,rb,rb+
r,r+ 只读;使用普通读取场景
rb,rb+;适用于文件、图片、视频、音频文件读取
2、write:w,w+,wb+,wb,a,ab
w,wb+,w+;每次都会去创建文件
二进制读写的时候,要注意编码问题 ,默认情况下,中文写入文件的编码是gbk
a,ab,a+;在原有的文件的基础之后去【文件指针的末尾】去追加,并不会每次的都去创建一个新的文件
'''
小结
文件读写的几种操作方式
1、read:r,r+,rb,rb+
r,r+ 只读;使用普通读取场景
rb,rb+;适用于文件、图片、视频、音频文件读取
2、write:w,w+,wb+,wb,a,ab
w,wb+,w+;每次都会去创建文件
二进制读写的时候,要注意编码问题 ,默认情况下,中文写入文件的编码是gbk
a,ab,a+;在原有的文件的基础之后去【文件指针的末尾】去追加,并不会每次的都去创建一个新的文件
二、文件备份
利用脚本完成自动备份,要求用户输入文件名称,完成自动备份
def file_backup():
# 获取文件名
oldFileName = input("请输入要备份的文件名:")
fileList = oldFileName.split(".")
# 构造新文件名,加上备份后缀.
newFileName = fileList[0] + "_备份." + fileList[1]
# 读取原文件
oldFile = open(oldFileName, "r")
oldContent = oldFile.read()
# 旧文件内容写入到新文件中
newFile = open(newFileName, "w")
newFile.write(oldContent)
newFile.close()
oldFile.close()
with open('./test2.txt', 'a') as fileObj:
fileObj.write('test测试文件')
file_backup()如果处理超大文件,一次将全部内容读取出来显然是不合适的,在需求1的基础上改进下代码,让它备份大文件也不会导致内存被占满
# 备份大文件
def big_file_backup():
oldFileName = input("请输入要备份的文件名:")
fileList = oldFileName.split(".")
newFileName = fileList[0] + "_备份." + fileList[1]
try:
with open(oldFileName, "r") as oldFile, open(newFileName, "w") as newFile:
while True:
# 一次就读取1024字节
content = oldFile.read(1024)
newFile.write(content)
if len(content) < 1024:
break
except Exception as msg:
print(msg)
pass
三、文件定位
1、tell()
文件定位,指的是当前文件指针读取到的位置,光标位置。在读写文件的过程中,如果想知道当前的位置,可以使用tell()来获取
# 以读模式打开test.txt 文件
f = open('test.txt','r’)
content = f.read(3) # 读取三个字符
# 查看当前游标所在位置
cur =f.tell()
print(cur)
content = f.read(3) # 读取三个字符
# 查看当前游标所在位置
cur =f.tell()
print(cur)
2、seek()
如果在操作文件的过程,需要定位到其他位置进行操作,用seek()。
seek(offset, from)有2个参数,offset,偏移量单位字节,负数是往回偏移,正数是往前偏移,from位置:0表示文件开头,1表示当前位置,2表示文件末尾
# 以读模式打开test.txt 文件
f = open('test.txt',’rb’)
content = f.read(3) # 读取三个字符
print(content)
f.seek(-2, 1) # 在当前位置往回偏移两个字节
content = f.read(3) # 读取三个字符
print(content)
f.seek(-5,2) # 定位到文章末尾,往回偏移5个字节
content = f.read(3) # 读取三个字符
print(content)
f.seek(5,0) # 定位到文章末尾,往回偏移5个字节
content = f.read(3) # 读取三个字符
print(content)
# 偏移量为负数,是往回偏移,正数是往前偏移
四、OS模块操作文件
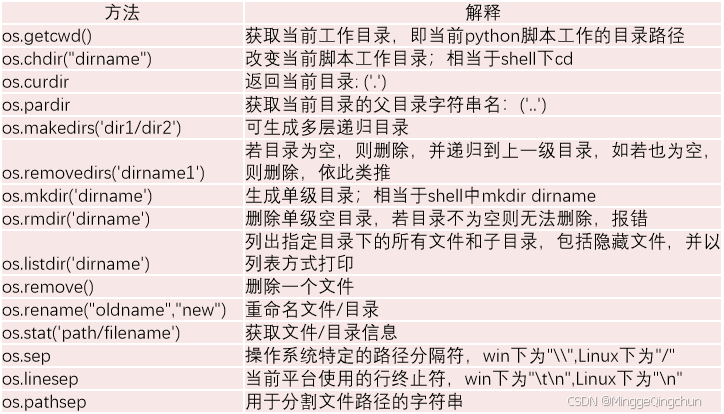
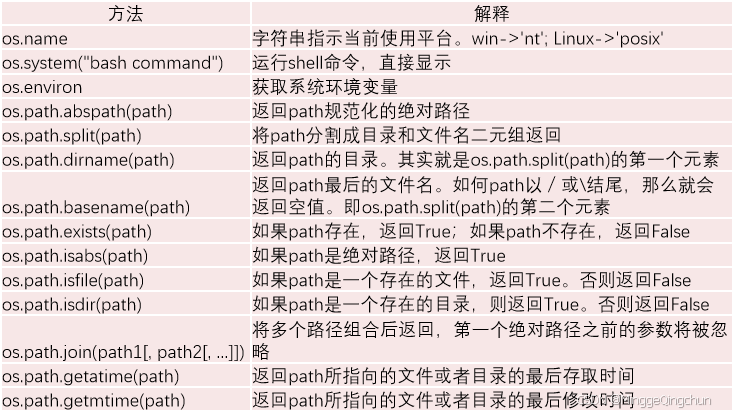
Python中的os模块包含有操作系统所具备的功能,如查看路径、创建目录、显示文件列表等。
os模块是Python标准库,可直接导入使用:
# 导入os模块
import os在Python中,os模块的常用函数分为两类:
(1)通过os.path调用的函数
(2)通过os直接调用的函数
在Python的os模块中,通过os.path常用函数:
| 函数名 | 含义 |
|---|---|
| exists(pathname) | 用来检验给出的路径是否存在。 |
| isfile(pathname) | 用来检验给出的路径是否是一个文件。 |
| isdir(pathname) | 用来检验给出的路径是否是一个目录。 |
| abspath(pathname) | 获得绝对路径。 |
| join(pathname,name) | 连接目录与文件名或目录。 |
| basename(pathname) | 返回单独的文件名。 |
| dirname(pathname) | 返回文件路径。 |
(1)在某目录下手动新建file目录与hello.txt文件;
(2)判断file/hello.txt是否存在、是否是文件、是否是目录、获取绝对路径名、获取单独的文件名
import os
# 定义变量
path = "./file/hello.txt"
# 文件是否存在
print('文件是否存在:%s'%os.path.exists(path))
# 是否是文件
print('是否是文件:%s'%os.path.isfile(path))
# 是否是目录
print('是否是目录:%s'%os.path.isdir(path)) # False
# 绝对路径
print('绝对路径:%s'%os.path.abspath(path))
# 单独文件名
print('单独文件名:%s'%os.path.basename(path))
输出:
文件是否存在:False
是否是文件:False
是否是目录:False
绝对路径:D:\4Python\ProjectCode\FirstPythonProject\file\file\hello.txt
单独文件名:hello.txt目录操作
| 函数名 | 含义 |
|---|---|
| getcwd() | 获得当前工作目录,即当前Python脚本工作的目录路径。 |
| system(name) | 运行shell命令。 |
| listdir(path) | 返回指定目录下的所有文件和目录名,即获取文件或目录列表。 |
| mkdir(path) | 创建单个目录。 |
| makedirs(path) | 创建多级目录。 |
| remove(path) | 删除一个文件。 |
| rmdir(path) | 删除一个目录。 |
| rename(old,new) | 重命名文件。 |
# 1.获取目录
path = os.getcwd()
print(path)
# 2.获取文件或列表信息
path_name = "./"
dir_lists = os.listdir(path_name)
print(dir_lists)
# 3.新建目录
# 问题: 当目录不存在时,才需要创建; 已存在, 则不创建
new_path_name = "./python"
# 获取python中的目录列表
# listRs=os.listdir(new_path_name) 老版本的用法
# for dirname in listRs:
# print(dirname)
if not os.path.exists(new_path_name): # 逻辑
# 创建
os.makedirs(new_path_name)
print("已创建成功!!!")
# os.rename('Test.txt','Test_重命名.txt')
# os.remove('File_del.py') #删除文件 前提是文件必须存在
# os.mkdir('TestCJ') 创建文件夹
# os.rmdir('TestCJ') #删除文件夹 文件必须存在
# mkdir 创建一级目录
# os.mkdir('d:/Python编程/sub核心') #不允许创建多级
# 创建多级目录
# os.makedirs('d:/Python编程/sub核心/三级sub') #允许
# os.rmdir('d:/Python编程') #只能删除空目录
# 如果要删除非空目录的话 就需要调用shutil模块
# shutil.rmtree('d:/Python编程') #非空删除
输出:
D:\4Python\ProjectCode\FirstPythonProject\文件
['file_opt.py', 'OS模块操作文件.py', 'test.txt', 'test1.txt', 'test2.txt', 'test2_备份.txt', '文件', '文件备份.py', '文件定位.py']
已创建成功!!!
GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)