
一个大型语言模型框架,用于从PubMed病例报告中提取相对时间线
临床事件的时间是刻画患者轨迹的核心,能够实现诸如过程追踪、预测和因果推理等分析。然而,结构化的电子健康记录捕获了很少对这些任务至关重要的数据元素,而临床报告缺乏事件的结构化时间定位。我们提出一个系统,将病例报告转化为文本时间序列——由文本事件和时间戳组成的结构化对。我们对比了手动注释和大型语言模型(LLM)注释(分别为n320和n390)在十个随机抽取的PubMed开放获取(PMOA)病例报告中的
王静,博士 1{ }^{1}1, 杰里米·C·魏斯,医学博士,博士 1{ }^{1}1 1{ }^{1}1 美国马里兰州贝塞
摘要
临床事件的时间是刻画患者轨迹的核心,能够实现诸如过程追踪、预测和因果推理等分析。然而,结构化的电子健康记录捕获了很少对这些任务至关重要的数据元素,而临床报告缺乏事件的结构化时间定位。我们提出一个系统,将病例报告转化为文本时间序列——由文本事件和时间戳组成的结构化对。我们对比了手动注释和大型语言模型(LLM)注释(分别为 n=320n=320n=320 和 n=390n=390n=390)在十个随机抽取的PubMed开放获取(PMOA)病例报告中的表现(总数为 N=152,974N=152,974N=152,974),并评估了LLM之间的注释一致性(n=3,103N=93n=3,103 N=93n=3,103N=93)。我们发现LLM模型具有适度的事件召回率(O1-preview: 0.80),但在已识别事件中的时间一致性较高(O1-preview: 0.95)。通过建立任务、注释和评估系统,并展示高一致性,这项工作可以作为利用PMOA语料库进行时间分析的基准。代码可在以下网址获取:https://github.com/jcweiss2/LLM-Timeline-PMOA/.
引言
临床事件时间线是在从电子健康记录中的患者轨迹可视化到临床实践指南的开发和更新等多个领域中的关键分析工具。虽然许多自动化文档系统在关系数据库中以带时间戳的方式捕获结构化健康信息,但文本数据模式通常缺乏超出创建和提交日期之外的时间粒度,尽管它们是护理提供者用来记录和沟通患者病史和护理计划的主要工具。例如,病例报告和其他临床笔记可能包含过去医疗史和当前疾病史等部分,其中提到了健康事件的时间。然后可以推断这些事件相对于病例呈现时间的时间,例如“6个月前”,“5天发烧和寒战史”,或“2024年1月诊断出糖尿病”。我们认为,在我们的患者轨迹时间理解中存在一个可以通过提高文本信息的时间丰富性来弥合的差距,或者相反地通过改进带时间戳的事件捕获来实现。
临床信息学研究的几条路线已经解决了这一问题,包括时间关系提取和正式时间规范的任务 1−4{ }^{1-4}1−4。这些研究最终形成了2012年的i2b2时间关系挑战赛,其中从310份医院出院摘要中提取了临床事件和时间表达式,并注释了时间关系 4{ }^{4}4。一系列模型展示了迭代改进,使用自然语言处理和基于BERT的模型 5{ }^{5}5,最近则使用大型语言模型(LLMs)6{ }^{6}6。然而,虽然时间关系捕捉了事件的时间顺序,但没有捕捉时间戳,因此多模态对齐(如与带时间戳的结构化数据元素对齐)以及时间到事件分析等任务无法在没有额外注释努力的情况下进行。为了解决这一问题,Leeuwenberg和Moens以及Frattallone等人专注于时间间隔注释,这表明多模态(文本和表格)深度学习和基于BERT的模型可以成功预测这些间隔 7,8{ }^{7,8}7,8。当应用开源大型语言模型LLaMa-2-13B时,它在区间预测上的表现并不具有竞争力 8{ }^{8}8。关于最高性能的闭源LLMs的表现仍是一个开放的问题,由于在私人和半公共临床数据资源上使用这些模型的挑战,这一问题仍未得到验证。
同时,最近在临床问答基准上的性能改进 9{ }^{9}9 表明LLMs可能有助于临床信息学中的其他推理任务,其中之一就是时间线构建。因此,我们寻求调查高性能LLM模型在公共存储库PubMed开放获取病例报告中的表现 10{ }^{10}10。病例报告与i2b2语料库中分析的出院摘要有主题重叠,因为许多病例报告是为了描述有趣的临床发现并作为讨论临床推理和最佳实践的交流工件而编写的。正如我们所展示的,我们的提取确定了152,974份病例报告,而在随机抽样的100份中,有93份被确定为单个病例的病例报告,这表明PMOA可以成为临床时间线分析的丰富来源,具有足够的样本量来广泛探索医疗保健和感兴趣的子领域。
为了调查这一努力的可行性,我们的工作描述了一个LLM框架,描述了案例选择、注释过程和评估。为了验证LLM响应,我们手动注释了一小部分随机选取的病例报告,并将其结果与更大子集上的LLM间一致性表现进行了对比(类似于注释者间一致性)。结果令人鼓舞,但仍需努力,我们希望我们的阐述能帮助考虑系统设计选择和评估,因为从自由文本中构建临床时间线的努力将继续完善。
相关工作
我们的LLM注释管道涉及事件提取和相对于病例呈现的时间分配步骤,这两个任务在先前的工作中已被解决。LLMs已在临床领域用于最先进的问答 9{ }^{9}9、实体提取 11{ }^{11}11 和综合 12{ }^{12}12。在那些专注于时间提取和建模的研究中,许多人使用了2012年的i2b2时间关系挑战赛,该挑战提供了医院出院摘要的时间注释,特别是临床命名实体及其时间顺序。其中包括Kougia等人比较GPT 3.5、Mixtral和PMC-LLaMa以及其他方法的研究,这些研究表明在临床时间关系提取方面与多模态基于BERT的模型具有竞争力的性能 6,13{ }^{6,13}6,13。对于非临床时间关系,GPT 4.0零样本提取已被应用,然而在该研究中,基于BERT的策略优于提示工程方法 14{ }^{14}14。
我们关注的时间信息是相对于病例呈现的时间,这更接近于使用模型注释或提取临床时间线的作品 7,8{ }^{7,8}7,8。在这些作品中,带有相关时间间隔的事件被概率建模,而我们的工作重点是与单一相对时间相关的事件,以简化LLM请求。Leeuwenberg提供了基线LSTM模型用于时间线预测,Cheng和Weiss展示了带有临床标记元素的基于BERT的模型的改进性能 5,7{ }^{5,7}5,7。在由临床专家对i2b2出院摘要的时间线注释进行的比较中,Frattallone等人显示多模态基于BERT的模型优于零样本Llama-2-13b提取 8{ }^{8}8。在我们的PubMed开放获取病例报告案例中,缺少额外的数据模式,例如来自电子健康记录的结构化表格数据,因此难以应用多模态增强的基于BERT的策略。最后,PubMed开放获取语料库也被用于其他下游建模任务,取得了一些成功,例如检索生物医学概念 15{ }^{15}15 和服务预训练生物医学BERT模型 16{ }^{16}16。
贡献
我们的工作提出了以下贡献。首先,我们介绍了一种新颖的框架,用于表征和比较从病例报告中提取的相对时间线。其次,我们将我们的框架应用于PubMed开放获取语料库,识别适合事件时间提取的病例报告,生成结构化的事件时间输出,并评估响应的质量和一致性。据我们所知,这是首次使用PubMed病例报告进行时间线恢复。第三,我们的结果表明,使用LLMs进行临床时间构建似乎是可行的,特别是在提供时间顺序方面,但仍有工作需要改进完整性和相对时间。最后,我们提供了我们的注释作为基准测试的试点语料库。
方法
我们的注释系统包括以下部分:提取、注释和评估(图1),以便比较专家注释与LLM注释以及LLM间的协议。
提取。使用的文本语料库来自截至2024年4月18日的PubMed开放获取(PMOA)存储库,包含1,488,346篇全文文章。虽然PubMed有元数据指示病例报告,但我们在手动审查后发现“病例报告”标签的敏感性和特异性较低。因此,我们使用以下正则表达式来识别临床病例报告:(i) 存在“病例报告”或“病例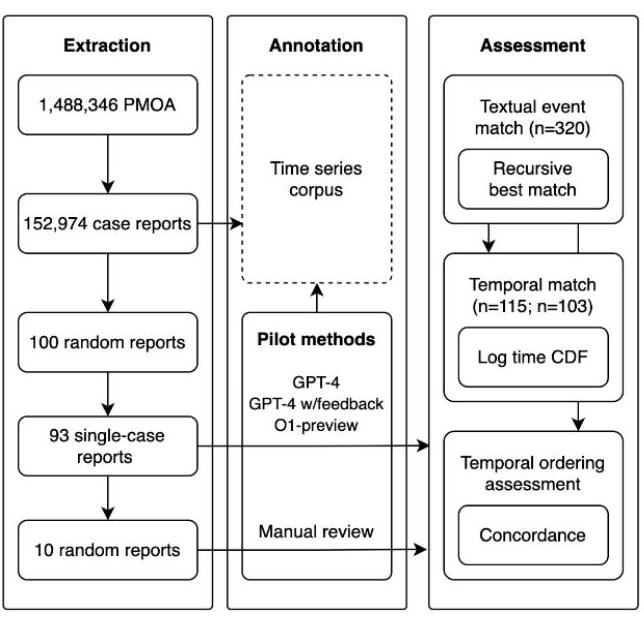
图1. 相对时间注释系统的流程图
演示”,以及 (ii) 文章主体中存在字符串“year-old”或“year old”,忽略大小写。为了找到文章主体,我们只保留“====== BODY”和“====== Refs”之间的文本,这些是PMOA语料库中编码的部分分隔符。这种方法导致识别出152,974份可能的病例报告。为了验证我们识别病例报告方法的精确性,我们取匹配的文章并随机抽取100篇进行手动检查。在100份病例报告中,有一份没有病例演示,六份有多例。我们选择了剩余的93篇文章进行进一步分析。对于参数和设计选择,例如提示调优和文本距离,我们在开发集中随机抽取了另外5份非重叠的病例报告。
注释。
我们的注释包括对93份病例报告的LLM注释,从中我们随机选择了10份病例报告由受过临床培训的专家进行手动注释。注释过程是根据ISO-TimeML规范 3{ }^{3}3 提取事件,这些事件非正式地对应于可以推断出已经发生或保持为真的事件。对于手动注释,专家被要求选择不修改的文本片段作为事件,有两个例外:(i) 允许将连词列表扩展为其组成部分,(ii) 允许将“history of”前缀附加到文本片段。这些例外旨在增加事件的可用性,同时保持原始文本位置的逆映射,以便可以在下游建模中使用文本片段上下文。一旦指定事件,注释者被要求分配相对于病例演示时间的时间,例如入院时间或接触日期。尽管其他时间框架已将时间间隔分配给事件 7,8{ }^{7,8}7,8,在我们最初探索LLM时间注释时,我们发现捕获间隔往往导致无意义的输出格式或时间。如果文本描述了与事件对应的间隔,注释者被要求使用开始时间,即时间间隔的下限。注释过程产生了两列文件(事件和时间),共320个事件。
对于LLM注释,我们使用了GPT-4(gpt-4-0613)和O1-preview(o1-preview-2024-09-12),因为在我们的初步探索中,它们比Llama-3-8B-Instruct、Llama-3-70B和GPT-4o表现更好。我们通过对开发集上的结果进行非正式的手动搜索来确定提示策略,并采用了结合少样本提示原则和反馈的策略。我们比较了三种策略:没有反馈的GPT-4(“GPT-4”)、有响应和反馈的GPT-4(“GPT-4 w/feedback”)以及没有反馈的O1-preview(“O1-preview”)。我们的最终提示形式如下:
“{base_prompt}\n\nOriginal Text: {original_text}\n\nUpdates: {response}{feedback_prompt}”,
其中括号中的占位符替换为相应的字符串值。我们使用了{base_prompt};
"您是一名医生。从病例报告中提取临床事件及相关时间戳。入院事件的时间戳为0 。如果事件不可用,我们将事件视为当前主要临床诊断或治疗,时间戳为0 。发生在时间戳为0的事件之前的时间为负数,发生在时间戳为0的事件之后的时间为正数。时间戳以小时为单位。输出结果时省略单位。如果没有事件的时间信息,请使用您的知识和事件前后带有时间表达式的事件来提供近似值。我们希望根据历史发生的事件预测未来的事件。例如,这里是病例报告。
一名18岁男性因3天发热和皮疹住院。四周前,他被诊断为痤疮并接受了为期3周的每日100毫克米诺环素治疗。白细胞计数升高、嗜酸性粒细胞增多和全身症状,该患者被诊断为DRESS综合征。入院期间发热和皮疹持续存在,弥漫性红斑或斑丘疹伴瘙痒出现。一天后患者出院。
让我们找出病例报告中事件的位置,结果显示四星期前发热和皮疹,四星期前,他被诊断为痤疮并接受治疗。所以发热和皮疹事件发生在入院前四个星期,672小时,时间戳为-672 。入院体检中记录了弥漫性红斑或斑丘疹伴瘙痒,因此时间戳为0小时,因为它正好发生在入院时。DRESS综合征没有具体时间,但它应该很快发生在入院后,所以我们用临床判断给出DRESS综合征的时间戳为0 。那么输出应如下所示:
18 years old ∣0\mid 0∣0
male ∣0\mid 0∣0
admitted to the hospital ∣0\mid 0∣0
fever ∣−72\mid-72∣−72
rash ∣−72\mid-72∣−72
acne ∣−672\mid-672∣−672
minocycline ∣−672\mid-672∣−672
increased WBC count ∣0\mid 0∣0
eosinophilia ∣0\mid 0∣0
systemic involvement ∣0\mid 0∣0
diffuse erythematous or maculopapular eruption ∣0\mid 0∣0
pruritis ∣0\mid 0∣0
DRESS syndrome ∣0\mid 0∣0
fever persisted ∣0\mid 0∣0
rash persisted ∣0\mid 0∣0
discharged ∣24\mid 24∣24
将连词短语分解为其组成事件,并赋予它们相同的时间戳(例如,将’fever and rash’分离为两个事件:‘fever’和’rash’)。如果事件有持续时间,将事件时间设为时间间隔的开始。尝试使用文本片段而不做修改,除了适用的’history of’。包括所有患者事件,即使它们出现在讨论中;不要遗漏任何事件;包括终止/中断事件;包括相关的阴性发现,如’no shortness of breath’和’denies chest pain’。以行的形式显示事件和时间戳,每行有两个列:一列为事件,另一列为时间戳。时间为小时单位的数值。两列之间用竖线’|'分隔为一个以竖线分隔的文件。跳过表格标题。
"
提供了病例报告正文在{original_text}中,并在{response}中包含了初始输出,以及在{feedback_prompt}中加入了“are you sure?”的反馈。版本GPT-4 w/feedback使用了这个反馈循环两次,并将{response}作为最终输出。我们为GPT-4和GPT-4 w/feedback设置了温度为0,而为O1-preview设置了温度为1,以满足必要条件。由于GPT-4和O1-preview的令牌限制分别为8,192和32,768,我们右截断了上述提示的输入以适应相应需求。
评估。
通过与经过临床培训的专家的手动注释进行比较,并通过LLM间的协议来评估可靠性,从而评估LLM注释。比较在事件级别进行,其中文本跨度按报告逐一匹配,并通过顺序协议(一致性)和相对时间误差(绝对时间误差,或在LLM间协议情况下为绝对时间差异)进行时间级别的比较。
为了识别文本匹配,使用了两个同一报告的注释事件列表之间的距离矩阵。由于事件是从同一报告生成的,这意味着事件之间存在一对一的对应关系,我们采用递归最佳匹配以减少错误匹配,即第一个列表中的多个事件映射到第二个列表中的同一事件。程序上,如果第二个列表中有多个事件与某个事件匹配,则选择最低距离的匹配项,并在递归调用中从列表中移除这些匹配事件。为了计算一对文本跨度之间的距离,我们测试了Levenshtein距离(插入/删除/替换的最小次数)和句子转换器平均嵌入的余弦距离,模型为"all-MiniLM-L6-v2"和"S-PubMedBert-MS-MARCO"17,18。在开发集上对匹配进行视觉检查后,我们确定"S-PubMedBert-MS-MARCO"产生了最佳的文本跨度匹配。通过手动审查选择了0.1作为事件匹配的余弦距离阈值。
在匹配事件中,使用一致性比较相对时间以进行时间顺序排列,这给出了所有事件对中正确排序的经验概率(具体来说,"不错误"排序的概率),假设正确的排序是由手动注释作为真实值提供的。一致性使用R glmnet Cindex函数计算。绝对时间误差或差异在所有匹配事件之间计算,以定量表征相对时间注释。这些时间评估措施被选中以突出时间顺序和时间恢复方面的性能。
作为参考,十份专家注释的病例文件为:PMC4300884、PMC4478313、PMC4818304、PMC5667582、PMC6030904、PMC6034490、PMC7337692、PMC7747049、PMC8127753和PMC9871993。注释、评估和注释代码可在此处获取:https://github.com/jcweiss2/LLM-Timeline-PMOA/。
结果
注释。手动注释结果为320个事件-时间对,平均每份报告注释32个事件(表1)。平均每份报告提取出6个不同的相对时间。相对时间分布从演示时间到演示后的多年不等,其中55%55 \%55%的事件位于演示时间。在10份病例报告中,没有任何事件位于小时分辨率(图2)。相比之下,LLM注释平均每份报告有39−4639-4639−46个事件(范围:122−144%122-144 \%122−144%的手动注释)。尽管存在这种差异,自动注释过程识别出相似数量的不同相对时间:6到8(表1)。
表1. 手动和LLM注释的描述性统计。
| 统计量 | 手动 1^{1}1 | GPT-4 1^{1}1 | GPT-4 w/feedback 1^{1}1 | O1-preview 1^{1}1 |
|---|---|---|---|---|
| 事件 | 32[14,70]32[14,70]32[14,70] | 46[20,297]46[20,297]46[20,297] | 44[16,93]44[16,93]44[16,93] | 39[27,58]39[27,58]39[27,58] |
| 不同时间 | 6[2,13]6[2,13]6[2,13] | 6[1,16]6[1,16]6[1,16] | 6[1,19]6[1,19]6[1,19] | 8[3,13]8[3,13]8[3,13] |
1{ }^{1}1 平均值 [最小值,最大值]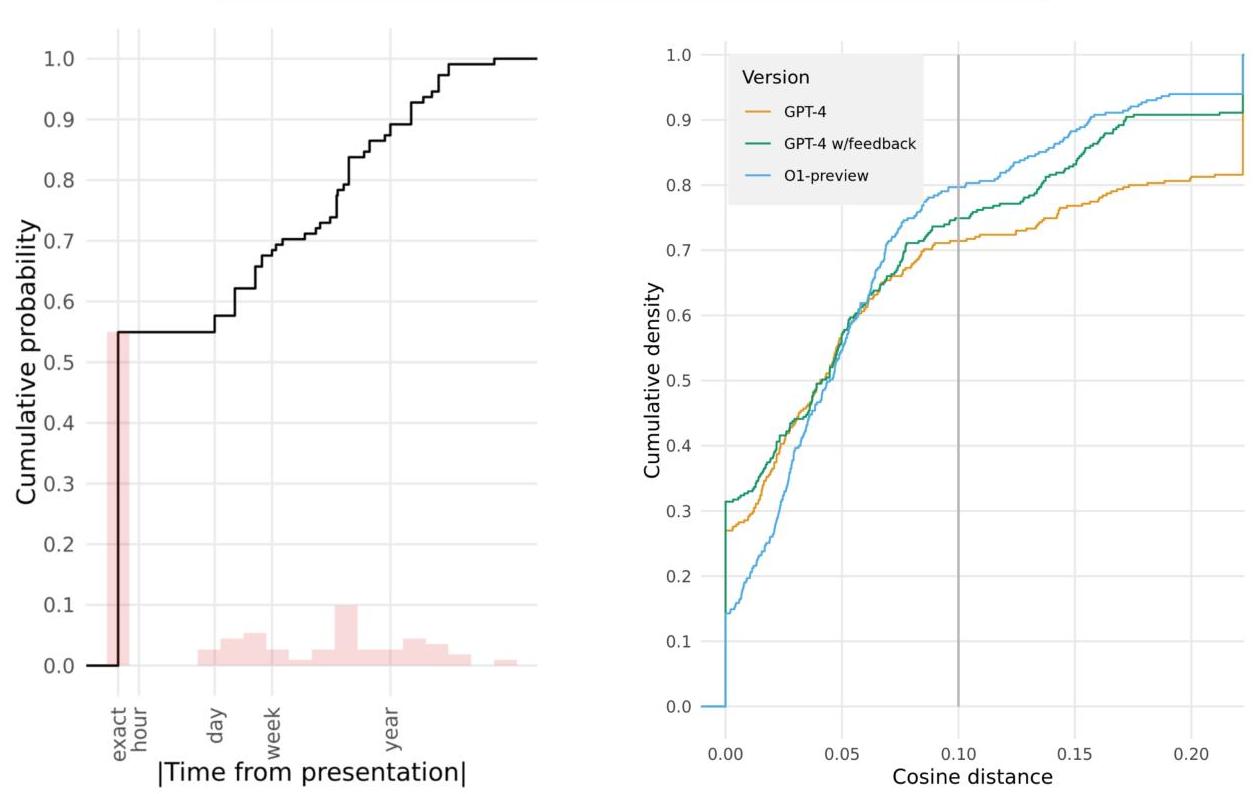
图2. 手动注释的绝对时间相对于演示的分布(左),手动事件匹配率按LLM版本(右)。
事件匹配。
尽管手动注释结果产生的事件少于LLM注释(图2,左),在余弦距离阈值为0.1范围内,事件匹配率在70−80%70-80 \%70−80%之间。修改阈值可能会导致文本匹配的边际增加,但代价是增加了假阳性(图2,右)。事件召回率的潜在因素可能是GPT-4的令牌限制导致的截断,以及连词列表的不完全拆分,导致每个事件列表中有多个手动注释事件。O1-preview注释中显著缺乏确切的文本匹配,这表明频繁的改写或重新表述文本跨度。
| file.name | 手动注释 | GPT-4 w/feedback | 余弦距离 |
|---|---|---|---|
| PMC7337692.csv | 氧气改善 | 氧气改善至仅需2升鼻导管 | 0.0757 |
| PMC6030904.csv | 胆囊炎 | 怀疑胆囊重复伴胆囊炎 | 0.0777 |
| PMC6030904.csv | 右侧胆囊有脓性胆汁和增厚 | 病理报告显示两条渗透性囊管,两条分开… | 0.0842 |
| PMC7747049.csv | 银屑病 | 诊断:甲状腺功能减退症,胰岛素抵抗,银屑病,和hi/… | 0.0888 |
| PMC6030904.csv | 患者术后恢复顺利 | 随访显示患者情况良好 | 0.0989 |
| PMC5667582.csv | 脓苔覆盖的皮肤溃疡 | 自发破裂的水疱形成伴有脓液的皮肤溃疡 | 0.1004 |
| PMC6030904.csv | 第二个胆囊外观正常 | 最终诊断为Y形胆囊重复伴胆囊炎… | 0.1047 |
| PMC6030904.csv | 腹腔镜 | 腹腔镜确认胆囊重复 | 0.1052 |
| PMC5667582.csv | 两性霉素B | 开始抗肺孢子虫治疗 | 0.1144 |
| PMC4818304.csv | 因大囊肿遇到困难… | 胆囊内纤毛前肠囊肿诊断 | 0.1207 |
| PMC8127753.csv | 耳镜检查 | 窦道向上追踪至耳部开口… | 0.1275 |
图3. 余弦距离约为0.1的潜在事件匹配,按GPT-4 w/feedback的平均标记化嵌入余弦距离排序。真匹配(蓝色)倾向于出现在较小的余弦距离,而误匹配(白色/灰色)出现在较大的距离。
时间匹配
将匹配事件的相对时间与手动注释的相对时间进行比较,我们发现LLM注释具有较高的一致性(均值-GPT-4: 0.912,GPT-4 w/feedback: 0.876,O1-preview: 0.951;箱线图-见图4,左)。50%到75%的匹配事件具有与手动注释时间相同的相对时间,约70−8570-8570−85%的事件时间误差在24小时内(图4,中心)。不同LLM版本的时间误差分布没有明显变化。在手动注释的相对时间子组(相对于病例演示时间),我们观察到当手动注释时间远离病例演示时间时,较大的时间误差(大于1周)往往会发生(图4,右)。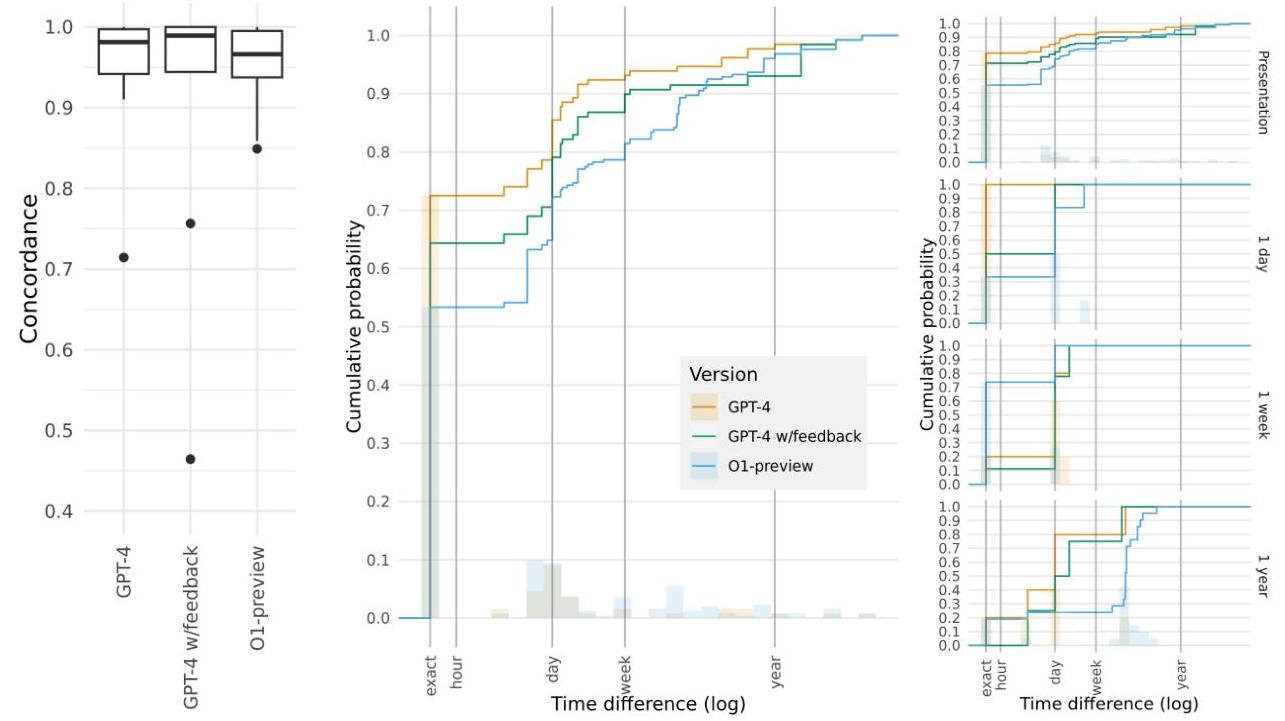
图4. 时间匹配性能指标。显示的是一致性(左),绝对时间误差(中心),以及按从演示时间分组的绝对时间误差:在演示时,≤1\leq 1≤1天从演示,≤1\leq 1≤1周从演示,≤1\leq 1≤1年从演示(右)。
LLM间协议
使用GPT-4和GPT-4 w/feedback方法对93份病例报告进行注释,结果产生了3,998个匹配事件。其中,3,103个(78%78 \%78%)在余弦距离小于0.1时找到匹配事件。在匹配事件中,时间顺序较高(均值:0.97 ,箱线图-见图5左)。与手动注释相比,LLM注释具有一致性的相似水平,相同时间恢复的概率更高,并且随着距病例演示时间的增加,差异也类似增加。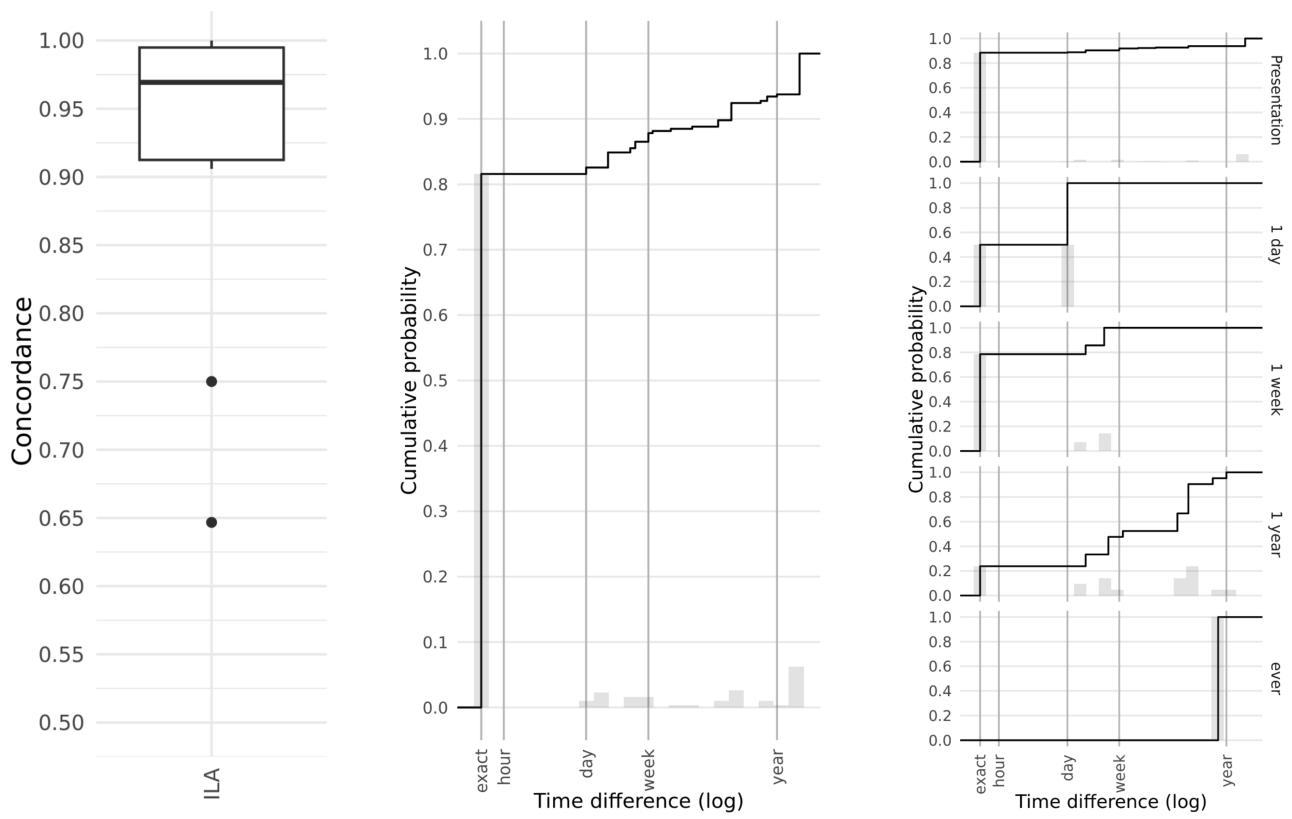
图5. GPT-4和GPT-4 w/feedback之间的LLM间协议(ILA),通过一致性(左),绝对时间差异(中心)和按病例演示时间子组的绝对时间差异(右)测量。
讨论
我们的结果表明,LLM注释查询能够有效地从自由文本病例报告中提取事件-时间对。尽管事件召回率适中(70−80%70-80 \%70−80%),通过LLM方法识别出的相似数量的不同时间表明整体事件时间结构被捕获,且构成事件的确定可以进一步改进(表1,图4左)。尽管时间顺序似乎大部分正确,如高一致性所示,但在相对时间定位上仍存在差异,大约10−20%10-20 \%10−20%的事件至少被错定位一周,2−7%2-7 \%2−7%的事件至少被错定位一年(图4中心)。这在与互补时间数据流对齐时可能产生影响,其中时间戳错误可能会影响锚定、预测特征可用性、右删失等。
LLM间协议图与手动-LLM协议图大致相似(图4和图5),这缓解了由于手动注释语料库规模较小而导致代表性不足的担忧。此外,在ILA图中观察到相同的趋势——高一致性、相似的差异分布,无论是全分析还是相对时间子组中,这表明ILA评估可以用作合理代理,以减少对高成本专家注释的依赖。
这项工作有几个局限性;我们从任务规范、评估设计选择和统计分析方面描述它们。首先,我们任务的一部分是将事件建模为尽可能不修改的文本跨度,这使得反向映射到文本中的参照段落变得简单(对LLM维持字符位置回溯引用的非正式尝试因虚构而受阻)。这与事件是可映射到现有临床本体的命名实体的方法形成对比 8,19{ }^{8,19}8,19。我们的选择增加了我们对通过标记化嵌入进行文本比较的依赖,这需要反复审查按余弦距离排序的事件匹配。我们的意图是,通过保留对反向引用的访问,下游应用如预测和过程发现将能够在建模过程中使用上下文。
其次,以前的工作已经建模了更大的时间表达集合,最接近的是带时间戳的间隔 7,8{ }^{7,8}7,8,还有扩展到日期、日期时间、持续时间、频率和时间关系的时间表达。虽然在我们的初步探索中我们考虑使用相对时间间隔,但我们观察到我们样本报告中的大多数事件都可以用单个相对时间引用,并且请求额外的时间信息往往会大大降低查询响应质量。未来的工作可以考虑基于我们项目中的相对时间、文本跨度和案例报告中的上下文,将时间点扩展为时间间隔。除了从时间点到时间间隔的问题外,还存在一些实例,其中指定了时间顺序而没有相对时间规格,这让专家注释员难以注释。例如,在“术后[手术]患者稳定后恢复抗凝治疗”中,时间关系是明确的,但是专家会选择将抗凝治疗视为与稳定和手术同时开始,因为手术和稳定持续时间从未指定。这个例子说明了单个相对时间规格的局限性,并可以通过时间和概率方法进行扩展 7,8{ }^{7,8}7,8。
第三,在我们的评估中,我们使用递归事件匹配来避免文本嵌入的多对一映射。这具有防止由于错误、低距离事件匹配而导致的大时间差异的优势,但代价是较低的事件召回率。当一个事件列表包含连词列表而另一个列表拆分它们时,1对1匹配的要求会阻止完全匹配。由于我们的重点在于获得高质量(即使部分)时间序列,我们认为对时间一致性的强调胜过较低的召回率,未来的工作可以集中在改进列表扩展的规律性,而不仅仅是提示工程。
第四,我们仅使用了PubMed开放获取病例报告的一个样本,这意味着许多病例报告子组仍未被充分描述。例如,在经过手动审查的10份报告中,没有任何事件处于分钟或小时分辨率。这些时间分辨率在重症监护、麻醉和程序学科等领域可能很重要。未来的工作将涉及扩展我们的注释框架到整个PMOA病例报告语料库,并且跨多样化的病例报告进行调查将是重要的验证步骤,这将有助于改进我们的注释过程。此外,LLM中可能存在影响子组描述和代表性的偏差。
更多的方法可以作为未来方向扩展这项工作——包括LLM注释集成、提示工程和基于主动学习的微调——并且可以进一步改进事件-时间提取系统的性能。在我们的工作之后,我们预计一个事件-时间PMOA语料库可以帮助改进预测模型、过程发现和AI辅助临床推理。
结论
我们发现LLM注释过程可以从自由文本病例报告中有效恢复临床事件的顺序,如高一致性所示,而完整事件列表的提取和准确时间的恢复仍有很大的改进空间。未来的工作可以将LLM注释的重点扩展到更多的时间表达,开发使用人类参与反馈的增强注释过程,并对特定临床队列进行详细评估。
致谢
这项研究得到了美国国立卫生研究院国家医学图书馆内部研究部门的支持。
参考文献
- Kohane IS. 医疗专家系统中的时间推理。博士论文,波士顿大学,1987年。
-
- Zhou L, Hripcsak G. 医疗数据的时间推理 - 侧重于医疗自然语言处理的综述。Journal of Biomedical Informatics. 2007 Apr 1;40(2):183-202.
-
- Pustejovsky J, Lee K, Bunt H, Romary L. ISO-TimeML: 语义注释的国际标准。In LREC, 2010年5月18日(第10卷,第394-397页)。
-
- Sun W, Rumshisky A, Uzuner O. 评估临床文本中的时间关系:2012年i2b2挑战。Journal of the American Medical Informatics Association. 2013年9月1日;20(5):806-13.
-
- Cheng C, Weiss JC. 类型标记和上下文用于临床时间关系提取。In Machine Learning for Healthcare Conference, 2023年12月22日(第94-109页)。PMLR.
-
- Kougia V, Sedova A, Stephan A, Zaporojets K, Roth B. 使用时间一致性分析临床笔记中零样本时间关系提取。arXiv preprint arXiv:2406.11486. 2024年6月17日。
-
- Leeuwenberg A, Moens MF. 从英语临床报告中提取绝对事件时间线。IEEE/ACM Transactions on Audio, Speech, and Language Processing. 2020年9月28日;28:2710-9.
-
- Frattallone-Llado G, Kim J, Cheng C, Salazar D, Edakalavan S, Weiss JC. 使用多模态数据提高住院事件时间线的精度。In Pacific-Asia Conference on Knowledge Discovery and Data Mining 2024年5月1日(第322-334页)。新加坡:Springer Nature Singapore.
-
- Singhal K, Tu T, Gottweis J, Sayres R, Wulczyn E, Hou L, Clark K, Pfohl S, Cole-Lewis H, Neal D, Schaekermann M. 使用大型语言模型实现专家级医学问题解答。arXiv preprint arXiv:2305.09617. 2023年5月16日。
10.10. PMC 开放访问子集 [Internet]. Bethesda (MD): National Library of Medicine. 2003 - 2024年9月14日。可从 https://pmc.ncbi.nlm.nih.gov/tools/openfllist/ 获取。
- Singhal K, Tu T, Gottweis J, Sayres R, Wulczyn E, Hou L, Clark K, Pfohl S, Cole-Lewis H, Neal D, Schaekermann M. 使用大型语言模型实现专家级医学问题解答。arXiv preprint arXiv:2305.09617. 2023年5月16日。
- Xie Q, Chen Q, Chen A, Peng C, Hu Y, Lin F, Peng X, Huang J, Zhang J, Keloth V, He H. Me llama: 基础大型语言模型在医学应用中的应用。arXiv preprint arXiv:2402.12749. 2024年2月20日。
-
- Li R, Wang X, Yu H. 使用大型语言模型进行临床数据生成的两个方向:数据到标签和标签到数据。In Proceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing 2023年12月(第2023卷,第7129页)。
-
- Knez T, Žitnik S. 临床文本中时间关系提取的多模态学习。Journal of the American Medical Informatics Association. 2024年6月1日;31(6):1380-7.
-
- Yuan C, Xie Q, Ananiadou S. 使用ChatGPT进行零样本时间关系提取。In the 61st Annual Meeting of the Association for Computational Linguistics. 2023年7月。
-
- Wei CH, Allot A, Lai PT, Leaman R, Tian S, Luo L, Jin Q, Wang Z, Chen Q, Lu Z. PubTator 3.0: 一种用于解锁生物医学知识的人工智能驱动文献资源。Nucleic Acids Research. 2024年4月4日。
-
- Peng Y, Chen Q, Lu Z. 关于BERT在生物医学文本挖掘中的多任务学习的实证研究。BioNLP 2020. 2020年7月9日:205
-
- Wang W, Wei F, Dong L, Bao H, Yang N, Zhou M. MiniLM: 用于任务无关压缩预训练Transformer的深度自注意力蒸馏。Advances in Neural Information Processing Systems. 2020;33:5776-88.
-
- Deka PR, Jurek-Loughrey AN, Padmanabhan D. 改进的方法以辅助在线健康新闻的无监督证据基础事实核查。Journal of Data Intelligence. 2022年11月;3(4):474-505.
-
- Hu Y, Chen Q, Du J, Peng X, Keloth VK, Zuo X, Zhou Y, Li Z, Jiang X, Lu Z, Roberts K. 通过提示工程改进大型语言模型在临床命名实体识别中的应用。Journal of the American Medical Informatics Association. 2024年1月27日。
参考论文:https://arxiv.org/pdf/2504.12350
- Hu Y, Chen Q, Du J, Peng X, Keloth VK, Zuo X, Zhou Y, Li Z, Jiang X, Lu Z, Roberts K. 通过提示工程改进大型语言模型在临床命名实体识别中的应用。Journal of the American Medical Informatics Association. 2024年1月27日。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 11
11 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)