
显存“黑洞”探秘:为何vLLM加载模型后,我的GPU“饿”得快?
嘿,我明明用的是INT4量化的7B模型,理论上模型文件也就3-4GB,怎么用vLLM一加载,我那24GB显存的RTX 4090直接就去了10GB?!这显存是被谁‘偷’走了?如果你也曾对着nvidia-smi的输出发出过这样的灵魂拷问,那么恭喜你,你不是一个人在战斗!这篇博客,我们就扮演一次GPU显存侦探,用最简单直白的方式,层层剥茧,探寻vLLM部署时那些“看似多余”的显存占用究竟从何而来。
“嘿,我明明用的是INT4量化的7B模型,理论上模型文件也就3-4GB,怎么用vLLM一加载,我那24GB显存的RTX 4090直接就去了10GB?!这显存是被谁‘偷’走了?”
如果你也曾对着nvidia-smi的输出发出过这样的灵魂拷问,那么恭喜你,你不是一个人在战斗!这篇博客,我们就扮演一次GPU显存侦探,用最简单直白的方式,层层剥茧,探寻vLLM部署时那些“看似多余”的显存占用究竟从何而来。
启动vllm服务流程:
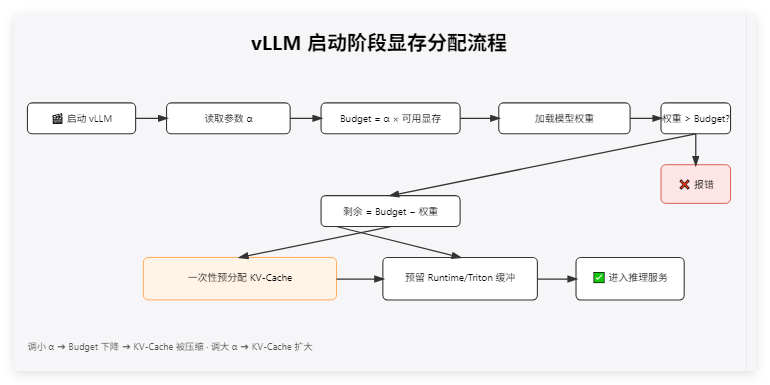
第一案发现场:理论 vs 现实的巨大鸿沟
让我们先回到最开始的疑惑点。一个70亿参数(7B)的模型,如果每个参数用INT4(4位)来存储,那么理论上它的大小应该是:
7,000,000,000 (参数) * 4 (位/参数) / 8 (位/字节) = 3,500,000,000 字节 ≈ 3.5 GB
然而,就像你看到的日志截图,nvidia-smi显示占用了大约10GB,而vLLM加载模型权重(Loading model weights took 5.2048 GB)就已经超过了这个理论值。这中间的差额,就是我们今天要破解的谜题。
嫌疑人一号:模型权重——并不只是“理论值”那么简单
我们以为的“模型大小”往往只是参数本身的存储大小。但实际上,加载到显存中的模型,可不止这些“净重”。
- 混合精度“加餐”:虽然我们说的是INT4量化,但为了保证模型的性能和效果(比如某些关键层如Embedding层或最后的输出层),并非所有部分都会被“狠心”地压到4位。有些部分可能仍然保持在FP16、BF16甚至FP32的精度。这就好比减肥餐里,总有那么几样是“高热量但必需”的。你的日志显示模型权重加载占了
5.2GB,这已经考虑了这些因素。 - 量化“装备”费:INT4量化不是简单地把数字变小,它还需要额外的“装备”——比如缩放因子(scales)和零点(zero-points)来帮助模型在低精度下也能正确计算。这些元数据也需要占用一丢丢显存。
小结:模型权重本身,由于混合精度和量化元数据的存在,实际占用会比纯理论计算要大。这是第一层“超出预期”。
嫌疑人二号:KV Cache——为“远见”预留的豪华套间
这是导致显存占用“飙升”的重量级嫌疑人!
- 什么是KV Cache? 想象一下模型在生成文本,它每生成一个新词,都需要回头看看前面都说了啥(这就是注意力机制)。为了不让模型每次都从头回忆(重新计算),它会把前面内容的关键信息(Key和Value,简称KV)存起来,这就是KV Cache。
- 为何它这么“占地儿”?
- 为未来打算(预分配):vLLM是个急性子,它不喜欢在推理过程中手忙脚乱地去申请显存。所以,它会在启动时就大手一挥,根据你的GPU总显存和配置(比如
gpu_memory_utilization参数,默认0.9,即尝试使用90%的可用显存),预先分配一大片空间作为KV Cache的“豪华套间”。你的日志里# GPU blocks: 4556,这些就是预留的“房间”。 - 长篇大论的准备(支持长上下文):你提到了上下文长度32k。这意味着模型可能需要同时“记住”非常非常长的对话或文章。KV Cache的大小与上下文长度成正比。要支持32k的上下文,就必须准备足够大的KV Cache空间。
- PagedAttention的智慧:vLLM使用PagedAttention技术,像管理操作系统内存分页一样管理KV Cache。它把KV Cache分成固定大小的块(blocks)。虽然高效,但这些块的总和构成了预分配池。
- 为未来打算(预分配):vLLM是个急性子,它不喜欢在推理过程中手忙脚乱地去申请显存。所以,它会在启动时就大手一挥,根据你的GPU总显存和配置(比如
第一性原理思考:如果不在推理前预留好KV Cache的空间,那么当大量请求涌入,或者需要处理长文本时,动态申请显存会非常慢,严重影响性能,甚至导致显存不足而崩溃。所以,vLLM的这种“未雨绸缪”是性能优先的策略。
小结:KV Cache的预分配机制,特别是为了支持长上下文,是显存占用的主要贡献者之一。即使你还没开始推理,这部分空间也已经被“预订”了。
嫌疑人三号:框架与运行时——“地基”和“装修”成本
最后,别忘了运行这一切的“基础设施”:
- PyTorch/TensorFlow等深度学习框架本身:它们需要显存来管理张量、执行操作。
- CUDA运行时和驱动程序:GPU能工作,离不开它们。
- vLLM引擎本身:调度器、内存管理器等组件也需要运作空间。
这部分就像盖房子时的地基和水电煤气管道,虽然不起眼,但必不可少,通常会稳定占用1-2GB甚至更多的显存。
破案陈词:显存都去哪儿了?
现在,让我们把所有线索串联起来,看看那10GB显存是如何构成的(估算):
- 实际模型权重:约 5.2 GB (来自你的日志)
- KV Cache预分配池:这部分是“大头”的剩余部分。如果总共10GB,减去模型权重5.2GB,大约剩下
10 - 5.2 = 4.8 GB。这部分可以理解为KV Cache池的初始分配部分,以及下面要说的运行时开销。 - 框架和运行时开销:通常有1-2GB。
更精确的计算应该是:vLLM会尝试使用你GPU总显存的90%(默认设置下,RTX 4090的24GB * 0.9 ≈ 21.6GB)来规划包括模型权重、主要是KV Cache在内的总空间。启动时,它会先加载权重,然后将剩余大部分可用空间初始化为KV Cache块池。你看到的10GB是这个初始化过程结束后的状态。
所以,谜底揭晓! 你看到的10GB显存占用,并非被“偷走”或“浪费”,而是:
- 一部分是模型本身(比理论值大)。
- 很大一部分是vLLM为了高性能和支持长上下文而预先分配的KV Cache池。
- 还有一部分是基础的框架和运行时开销。
这就像你准备去长途探险(处理长序列或高并发请求),虽然刚开始可能只带了一点点东西(短prompt,低并发),但你已经把一个巨大的登山包(预分配的KV Cache)准备好了,里面分门别类放好了各种应急物资(空的blocks),随时可以装填实际的行李(计算中产生的K和V值)。
我能做些什么来“瘦身”?
--gpu-memory-utilization 0.6
降低 KV-Cache 预留比例,适合 batch 少、上下文短的场景。--max-num-batched-tokens/--max-num-seqs
显式限制并发和上下文上限。--swap-space 4
允许把不活跃的 KV-Cache block 迁到 CPU 内存。- 更激进:再对 embedding / lm_head 做 8bit 量化,进一步压低权重。
🎯 结论
- 10 GB 并没有被“偷”,而是被提前“投资”:
5 GB 给权重,4 GB 给未来会话的 KV-Cache,1 GB 给基础设施。 - 想要缩减占用,核心就是 调小 KV-Cache 预算 或 开启 swap。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)