
RoboRefer:让机器人理解空间位置关系
北大与北航合作开发RoboRefer技术,解决机器人理解三维空间关系的难题。该研究针对现有视觉语言模型在复杂空间指称任务中的不足,提出创新解决方案:专用深度编码器避免模态干扰,强化学习微调实现多步推理,并设计新的数据集和评估基准。研究成果使机器人能更精准理解"将物体放在笔筒和键盘之间"等含复杂空间关系的指令,推动具身智能发展。
我们今天要分享的是一个叫RoboRefer的技术。
文章主页链接:RoboRefer | Towards Spatial Referring with Reasoning in Vision-Language Models for Robotics 这是北大和北航合作的一项研究工作、
让机器人理解并与三维物理世界进行有效交互一直是一个机器人理解真实世界的关键的挑战。
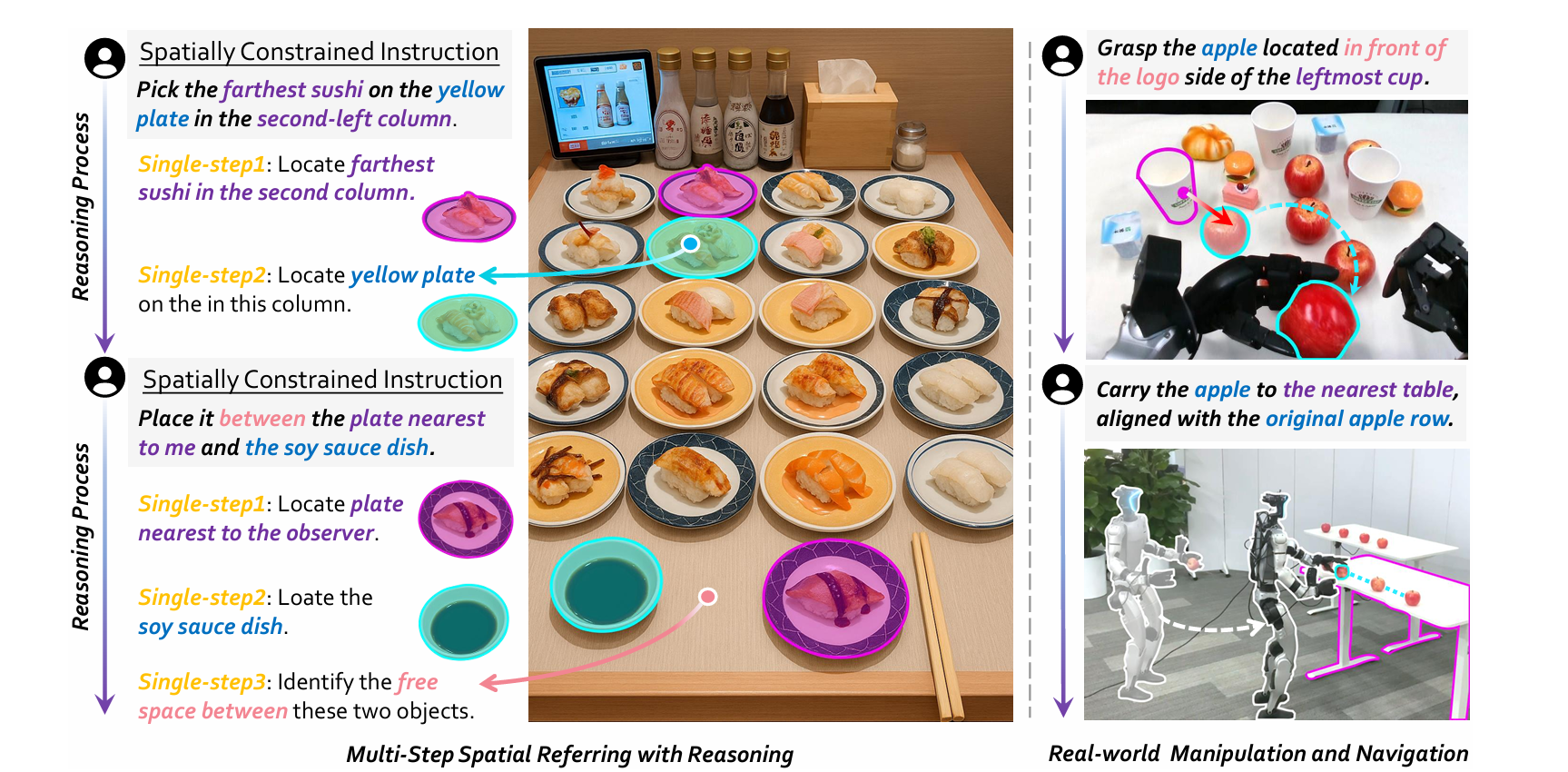
举例来说,你希望机器人帮你 “抓住位于最左边杯子标志一侧前方的苹果”,这样的指令包含了复杂的空间关系,需要机器人不仅能识别物体,还要理解它们之间的位置、方向和距离等空间属性。这种空间指称能力是具身机器人与三维世界交互的基础,但实现起来却面临诸多挑战。
那么这个研究正是针对这一问题展开研究,提出了一种创新的解决方案。
一、研究背景:为什么需要空间指称能力?
(一)机器人交互的现实需求
随着机器人在家庭、工业、服务等领域的应用日益广泛,它们需要处理的任务越来越复杂。从简单的物体抓取到复杂的场景导航,从物品摆放到位姿调整,机器人都需要准确理解人类指令中的空间约束。
例如,在家庭环境中,机器人需要根据 “将咖啡杯放在餐桌靠近窗户的一角” 这样的指令完成任务;在工业生产线上,机器人需要精准定位零部件的位置以进行装配。这些任务的核心都涉及到空间指称 —— 即根据语言描述在视觉场景中定位目标位置或对象。
(二)现有方法的局限性
尽管预训练的视觉语言模型(VLMs)在许多任务上表现出色,但在准确理解复杂三维场景和动态推理指令指示的交互位置方面仍存在不足。现有的基于 VLMs 的方法主要尝试通过集成 3D 输入来增强单步空间理解,但存在两种主要问题:
-
要么需要对多视图图像进行昂贵的 3D 重建,这会导致模态差距;
-
要么将深度视为类似 RGB 的输入,通过共享图像编码器处理,这可能导致模态干扰,降低预训练图像编码器的性能,还需要额外的协同训练数据来补偿。
此外,对于需要组合推理来逐步解决复杂空间引用的多步空间推理能力,现有方法更是缺乏足够的探索。这主要是由于缺乏合适的数据集和评估基准,限制了模型在这方面能力的发展。
(三)多步空间推理的重要性
在真实场景中,复杂的空间指称任务往往需要多步推理。
例如,指令 “将物体放在笔筒和键盘之间,与杯子的标志对齐” 就需要分步骤处理:首先确定笔筒和键盘的位置,然后找到它们之间的区域,再确定杯子标志的方向,最后确定准确的放置位置。这种多步推理能力对于机器人在复杂环境中执行任务至关重要,但现有模型在这方面的能力严重不足,缺乏有效的训练数据和评估手段。
二、RoboRefer:一种 3D 感知的视觉 - 语言模型
(一)核心目标与定位
RoboRefer 的核心目标是构建一个能够实现精准空间理解和广义多步空间推理的 3D 感知视觉 - 语言模型。它不仅能够处理单步的空间指称任务,还能通过强化学习微调(RFT)实现对复杂多步空间关系的推理,从而在机器人操作、导航等任务中实现更自然、更准确的人机交互。
(二)关键创新点
-
特权动作与课程学习框架:提出了结合特权动作与课程学习的通用框架,使策略能够高效解决长期、接触丰富的操作任务,同时通过课程学习逐步引入现实世界的约束。
-
深度编码器与模态对齐:采用专用的深度编码器,通过监督微调(SFT)实现精准的空间理解,避免了 RGB 和深度模态之间的干扰。
-
度量敏感的过程奖励函数:在强化学习微调阶段,设计了针对空间指称任务的度量敏感过程奖励函数,引导模型进行更准确的多步推理。
-
大规模数据集与基准:引入了 RefSpatial 数据集和 RefSpatial-Bench 基准,为模型训练和评估提供了丰富的资源。
(三)整体架构概览
点击阅读链接RoboRefer:让机器人理解空间位置关系阅读全文

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 28
28 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)