
中草药饮片识别系统项目介绍
中草药饮片识别系统是一个融合人工智能图像识别技术的综合性平台,旨在为中草药的智能化识别与分类提供高效解决方案。该系统采用前后端分离的先进架构设计,创新性地集成基于 Java 的 RuoYi 框架与基于 Python 的 Django 框架作为双后端,通过 API 接口实现无缝协同,构建了功能完备的中草药图像识别体系。
一、项目概述
中草药饮片识别系统是一个融合人工智能图像识别技术的综合性平台,旨在为中草药的智能化识别与分类提供高效解决方案。该系统采用前后端分离的先进架构设计,创新性地集成基于 Java 的 RuoYi 框架与基于 Python 的 Django 框架作为双后端,通过 API 接口实现无缝协同,构建了功能完备的中草药图像识别体系。
在中医药现代化发展的背景下,传统中草药饮片的识别依赖专业人员的经验,存在效率低、成本高、标准化程度不足等问题。本系统通过深度学习技术赋能,实现了中草药图像的自动化识别,有效提升了识别效率与准确性,为中医药数字化、智能化发展提供了技术支撑。系统不仅适用于医疗机构、中药房的饮片识别场景,也可服务于中医药教育、科研及产业质检等领域,具有广泛的应用前景。
二、系统架构与技术栈
(一)整体架构设计
系统采用前后端分离架构,前端与两个后端服务通过 API 接口交互,形成松耦合的系统结构:
- 前端层:基于 Vue.js 框架构建,负责用户界面展示与交互逻辑
- Java 后端:基于 RuoYi 框架(Spring Boot 生态),处理系统管理、用户权限等业务逻辑
- Python 后端:基于 Django 框架,专注于图像识别算法的实现与模型推理
双后端架构的优势在于:
- 技术栈分离:Java 适合处理业务逻辑,Python 擅长科学计算与算法实现
- 性能优化:识别任务与业务逻辑分离,避免资源竞争
- 可维护性:模块职责清晰,便于团队分工与后续扩展
(二)核心技术栈
| 模块 | 技术选型 | 作用 |
|---|---|---|
| 前端 | Vue.js + Element UI | 构建响应式用户界面,提供组件化开发能力 |
| Java 后端 | Spring Boot + RuoYi | 实现系统管理、权限控制、数据持久化 |
| Python 后端 | Django + Ultralytics YOLO | 提供图像识别 API 服务,集成深度学习模型 |
| 深度学习模型 | YOLO 目标检测算法 | 核心识别模型,实现中草药饮片的目标检测与分类 |
| 数据库 | MySQL | 存储用户数据、识别记录与系统配置 |
| 部署 | Nginx + Gunicorn | 处理反向代理与服务部署 |
三、系统功能模块
(一)核心功能模块
1. 中草药图像识别引擎
- 图像上传与预处理:支持 JPG/PNG 格式图片上传,自动调整尺寸与格式
- 智能识别:基于 YOLO 模型实现多目标检测,返回中草药类别与置信度
- 结果转换:自动将模型输出的英文名称映射为中文,提升可读性
2. 识别历史管理
- 记录存储:保存识别时间、图片路径、结果类型与置信度
- 查询筛选:支持按关键词、时间范围检索历史记录
- 数据导出:将筛选结果导出为 Excel 文件,便于统计分析
3. 统计分析模块
- 类型分布统计:以饼图展示各类中草药识别频率
- 时间趋势分析:通过折线图呈现识别量随时间的变化
- 明细数据报表:表格形式展示识别次数、占比等详细数据
4. 系统管理模块
- 用户权限控制:基于角色的访问控制(RBAC),支持管理员、普通用户等角色
- 菜单配置:动态配置系统菜单,控制不同角色的功能可见性
- 数据备份:支持数据库与上传图片的定期备份,保障数据安全
(二)功能交互流程
-
识别流程:
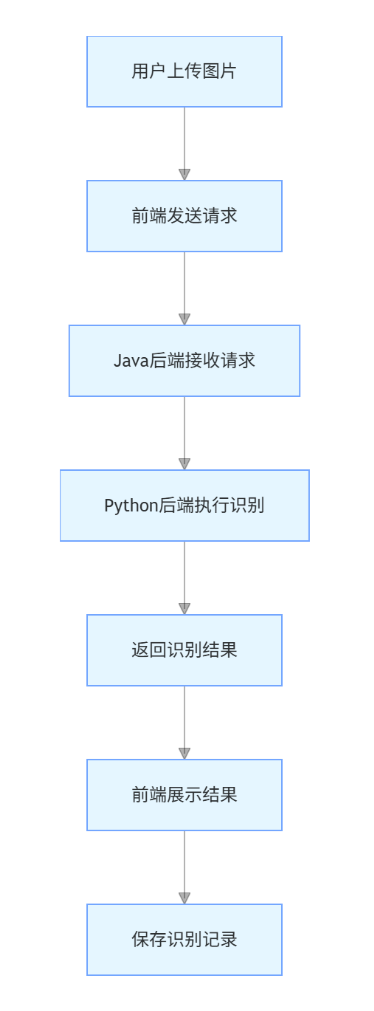
-
数据流转:
- 前端通过 FormData 上传图片至 Java 后端
- Java 后端转发请求至 Python 后端的 Django 服务
- Python 后端调用 YOLO 模型识别并保存记录
- 结果通过 API 返回前端渲染展示
四、核心代码解析
(一)Python 端识别模型实现
python运行
from ultralytics import YOLO
from PIL import Image
import time
# 模型路径配置
model_path = 'static/imageRecognition/model/best.pt'
# 加载YOLO模型(核心识别引擎)
model = YOLO(model_path)
def predict(image_path):
"""
执行图像识别的核心函数
:param image_path: 待识别图片路径
:return: (识别结果类别, 置信度)
"""
# 调用YOLO模型进行预测
results = model(image_path)
# 提取第一张图片的检测结果
boxes = results[0].boxes
# 处理无检测结果的情况
if len(boxes) == 0:
return "未识别", 0.0
# 获取置信度最高的检测目标
best_box = max(boxes, key=lambda b: b.conf)
class_id = int(best_box.cls)
confidence = float(best_box.conf)
class_name = model.names[class_id] # 通过模型获取类别名称
return class_name, confidence
代码解析:
- 使用 Ultralytics YOLO 库加载预训练模型,该模型基于 YOLOv8 架构优化
predict函数接收图片路径,返回识别结果与置信度,核心逻辑包括:- 模型推理:
model(image_path)执行目标检测 - 结果筛选:选取置信度最高的检测框
- 类别映射:通过
model.names获取类别名称
- 模型推理:
- 模型文件存储于
static/imageRecognition/model/目录,支持热更新替换模型
(二)Python 端图像上传与识别视图
python
运行
from django.views.decorators.csrf import csrf_exempt
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import ImageRecognition
from .recognitionModels import predict
import time
from django.utils import timezone
import os
class UploadImageView(APIView):
"""处理图片上传与识别的API视图"""
def post(self, request):
# 1. 获取上传的图片文件
file = request.FILES.get('file')
if not file:
return Response({"code": 400, "msg": "未获取到上传文件"})
# 2. 处理图片并保存至本地
img = Image.open(file)
# 生成唯一文件名(基于当前时间)
filename = time.strftime("%Y%m%d%H%M%S", time.localtime())
image_path = f'static/imageRecognition/uploads/{filename}.jpg'
img.save(image_path)
# 3. 调用识别模型
class_name, confidence = predict(image_path)
# 4. 英文名称转中文(通过映射字典)
herb_name_mapping = {
"ginseng": "人参",
"astragalus": "黄芪",
# 省略更多映射...
}
chinese_name = herb_name_mapping.get(class_name, class_name)
if chinese_name != class_name:
print(f"转换识别结果: {class_name} -> {chinese_name}")
# 5. 保存识别记录至数据库
image_recognition = ImageRecognition.objects.create(
upload_image=image_path,
result_type=chinese_name,
confidence=confidence,
time=timezone.now()
)
# 6. 返回识别结果
return Response({
"code": 200,
"msg": "识别成功",
"data": {
"id": image_recognition.id,
"upload_image": image_recognition.upload_image.url,
"result_type": image_recognition.result_type,
"confidence": image_recognition.confidence,
"time": image_recognition.time
}
})
关键逻辑说明:
- 文件处理流程:接收上传文件→生成唯一文件名→保存至服务器
- 模型调用:通过
predict函数执行识别,获取原始英文结果 - 结果转换:通过
herb_name_mapping字典实现英文到中文的映射 - 数据持久化:使用 Django ORM 将识别记录保存至
ImageRecognition模型 - 接口规范:遵循 RESTful API 设计,返回包含状态码、消息与数据的 JSON 结构
(三)数据模型定义
python
运行
from django.db import models
from django.utils import timezone
class ImageRecognition(models.Model):
"""图片识别记录数据模型"""
# 自动生成的主键ID
id = models.AutoField(primary_key=True, verbose_name='识别记录ID')
# 识别时间(默认使用当前时间)
time = models.DateTimeField(default=timezone.now, verbose_name='识别时间')
# 上传的图片(使用ImageField存储,upload_to指定存储路径)
upload_image = models.ImageField(
verbose_name='识别图片',
upload_to='static/imageRecognition/uploads/'
)
# 识别结果(最多255个字符的字符串)
result_type = models.CharField(max_length=255, verbose_name='识别结果')
# 置信度(浮点数类型)
confidence = models.FloatField(verbose_name='置信度')
class Meta:
db_table = 'image_recognition' # 数据库表名
verbose_name = '图片识别记录' # 单数名称
verbose_name_plural = verbose_name # 复数名称
ordering = ['-time'] # 按时间降序排列(最新记录在前)
def __str__(self):
"""返回对象的字符串表示,便于调试"""
return f"[{self.time}] {self.result_type} (置信度: {self.confidence:.2f})"
模型设计要点:
- 字段设计:包含识别记录的核心要素(时间、图片、结果、置信度)
- 存储策略:图片通过
upload_to指定存储路径,自动生成相对路径 - 排序规则:默认按时间降序排列,确保最新记录优先展示
- 元数据配置:明确数据库表名与显示名称,提升可维护性
(四)前端识别页面逻辑
javascript
// 前端识别页面核心代码(Vue.js实现)
export default {
data() {
return {
loading: false, // 加载状态
recognitionResult: { // 识别结果数据
visible: false,
imagePath: '',
className: '',
confidence: 0,
recognitionTime: ''
}
}
},
methods: {
uploadImage(options) {
// 1. 构建FormData对象上传文件
const formData = new FormData();
formData.append('file', options.file);
this.loading = true;
// 2. 调用API上传图片并识别
uploadImage(formData).then(response => {
this.loading = false;
if (response.code === 200) {
const data = response.data;
console.log("原始响应数据:", data);
// 3. 处理不同格式的响应数据(兼容Java与Python后端)
let upload_image = '';
let result_type = '';
let recognition_time = '';
if (typeof data === 'string') {
// 处理Django返回的JSON字符串
try {
const djangoData = JSON.parse(data);
if (djangoData.code === 200 && djangoData.data) {
upload_image = djangoData.data.upload_image || '';
result_type = djangoData.data.result_type || '';
recognition_time = djangoData.data.time || new Date().toLocaleString();
}
} catch (e) {
console.error("解析响应失败:", e);
}
} else {
// 处理对象格式响应(Java或Django)
if (data.imagePath) {
// Java后端响应格式
upload_image = data.imagePath || '';
result_type = data.className || '';
} else if (data.upload_image) {
// Django后端响应格式
upload_image = data.upload_image || '';
result_type = data.result_type || '';
}
recognition_time = data.recognitionTime || new Date().toLocaleString();
}
// 4. 更新识别结果数据
this.recognitionResult.imagePath = this.getImagePath(upload_image);
this.recognitionResult.className = result_type;
this.recognitionResult.confidence = data.confidence || 0;
this.recognitionResult.recognitionTime = recognition_time;
this.recognitionResult.visible = true;
// 5. 刷新历史记录列表
this.getList();
this.$message.success("识别成功:" + result_type);
}
}).catch(() => {
this.loading = false;
this.$message.error("识别失败,请重试");
});
},
getImagePath(path) {
// 处理图片路径,兼容不同环境
if (path.startsWith('http')) {
return path;
}
// 假设后端返回相对路径,此处拼接完整URL
return process.env.VUE_APP_BASE_API + '/' + path;
}
}
}
前端交互逻辑说明:
- 跨后端兼容:同时处理 Java 与 Python 后端的不同响应格式
- Java 后端返回对象格式(包含 imagePath、className)
- Python 后端返回 JSON 字符串(包含 upload_image、result_type)
- 加载状态管理:通过
loading变量控制加载动画,提升用户体验 - 结果展示逻辑:解析响应数据后,更新
recognitionResult对象并渲染到页面 - 错误处理:使用
try-catch捕获解析异常,通过$message提示用户操作结果
五、系统目录结构
(一)Java 前端目录(RuoYi-Vue-master/ruoyi-ui)
plaintext
src/
├── api/system/herb/ # 中草药相关API接口
│ ├── recognition.js # 识别功能API
│ └── history.js # 历史记录API
├── views/system/herb/ # 中草药相关页面
│ ├── recognition/ # 识别功能页面
│ │ ├── index.vue # 识别主页面
│ │ └── herb.vue # 中草药详情页面
│ ├── history/ # 历史记录页面
│ │ └── index.vue # 历史记录主页面
│ └── statistics/ # 统计分析页面
│ └── index.vue # 统计分析主页面
├── assets/ # 静态资源(图片、样式等)
├── components/ # 公共组件(按钮、表单等)
└── utils/ # 工具函数(请求封装、数据处理等)
(二)Java 后端目录(RuoYi-Vue-master)
plaintext
├── ruoyi-admin/ # 启动模块(包含application.yml配置)
├── ruoyi-common/ # 通用模块(工具类、异常处理等)
├── ruoyi-framework/ # 框架核心(安全认证、AOP日志等)
└── ruoyi-system/ # 系统功能模块
└── src/main/java/com/ruoyi/system/
├── controller/herb/ # 中草药控制器(处理API请求)
├── service/herb/ # 中草药服务层(业务逻辑实现)
├── mapper/herb/ # 数据访问层(SQL映射)
└── domain/herb/ # 实体类(Herb实体定义)
(三)Python 后端目录(hzsystem_django)
plaintext
├── image_recognition/ # 图像识别应用
│ ├── models.py # 数据模型定义
│ ├── recognitionModels.py # 识别模型加载与预测
│ ├── views/ # 视图函数
│ │ ├── FuncationViews.py # 功能视图(上传、识别)
│ │ └── CRUDViews.py # 数据管理视图(增删改查)
│ ├── urls.py # URL路由配置
│ └── serializers.py # 序列化器(数据格式转换)
├── yolo_model/ # YOLO模型相关文件
├── static/
│ └── imageRecognition/ # 识别相关静态资源
│ ├── uploads/ # 上传图片存储
│ └── model/ # 模型文件存储
├── hzsystem_django/ # 项目配置
└── manage.py # Django管理脚本
六、应用场景与价值
(一)核心应用场景
-
医疗机构与中药房:
- 辅助药师快速识别中草药饮片,减少人工误判
- 建立饮片识别数据库,支持药材溯源与质量管控
-
中医药教育与科研:
- 为中医药院校提供可视化教学工具,提升学习效率
- 为科研项目提供海量识别数据,支持药性分析与药效研究
-
中药材产业质检:
- 对中药材初加工产品进行自动化分类筛选
- 辅助鉴别真伪药材,打击市场假冒伪劣产品
-
中医药数字化平台:
- 作为子模块集成至中医药信息化系统
- 为中医 AI 问诊系统提供药材识别能力支持
(二)项目价值与创新点
-
技术创新:
- 采用双后端架构,实现业务逻辑与算法推理的高效分离
- 基于 YOLO 目标检测算法,突破传统图像分类模型的局限性
- 支持模型热更新,便于后续算法迭代优化
-
应用价值:
- 提升识别效率:单个图片识别耗时 < 1 秒,支持批量处理
- 降低人力成本:减少专业人员依赖,可应用于基层医疗场景
- 推动标准化:建立统一的中草药图像识别标准,促进产业规范化
-
社会意义:
- 助力中医药文化传承:通过数字化手段保护传统中药知识
- 促进中医药现代化:为 "智慧中医" 发展提供技术基础设施
- 提升医疗服务可及性:偏远地区也能获得专业的药材识别支持
七、系统运行与部署
(一)运行环境要求
- 操作系统:Windows/Linux/MacOS
- Java 环境:JDK 1.8+
- Python 环境:Python 3.6+
- 数据库:MySQL 5.7+
- 前端依赖:Node.js 12+
- 浏览器:Chrome/Firefox/Edge 最新版本
(二)核心部署步骤
-
环境准备:
bash
# 安装Python依赖 cd hzsystem_django pip install -r requirements_pip.txt # 安装Java依赖(通过Maven) cd RuoYi-Vue-master mvn clean install -
数据库配置:
sql
-- 创建数据库 CREATE DATABASE ry_vue DEFAULT CHARSET utf8mb4 COLLATE utf8mb4_general_ci; CREATE DATABASE hzsystem DEFAULT CHARSET utf8mb4 COLLATE utf8mb4_general_ci; -
服务启动:
bash
# 启动Python后端(Django服务) python manage.py runserver 0.0.0.0:8000 # 启动Java后端(Spring Boot服务) java -jar ruoyi-admin/target/ruoyi-admin.jar -
前端部署:
bash
cd RuoYi-Vue-master/ruoyi-ui npm install npm run build:prod
八、总结与展望
中草药饮片识别系统通过人工智能技术与中医药领域的深度融合,实现了传统药材识别的智能化升级。系统采用的双后端架构与 YOLO 目标检测模型,在保证识别准确率的同时,兼顾了系统的可扩展性与性能优化。
未来,项目可在以下方向进一步优化:
- 模型优化:引入迁移学习,针对小众药材增加训练数据,提升罕见药材识别率
- 功能扩展:集成药材药性查询、配伍禁忌提醒等附加功能
- 移动端适配:开发 Android/iOS 客户端,支持野外采药现场识别
- 多模态融合:结合药材气味、纹理等多维度特征,构建更全面的识别体系

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)