
【预训练语言模型】SpanBERT: Improving Pre-training by Representing...
【预训练语言模型】SpanBERT: Improving Pre-training by Representing and Predicting Spans (2020ACL) 陈丹琦团队的一篇改进BERT预训练任务的工作,扩展了BERT预训练语言模型:不像BERT只MASK单独的一个token,而是随机MASK掉连续的序列( contiguous random span);训练span bou
【预训练语言模型】SpanBERT: Improving Pre-training by Representing and Predicting Spans (2020ACL)
陈丹琦团队的一篇改进BERT预训练任务的工作,扩展了BERT预训练语言模型:
- 不像BERT只MASK单独的一个token,而是随机MASK掉连续的序列( contiguous random span);
- 训练span boundary representation预测mask掉的整个区间内容;
1、动机:
- 许多NLP任务涉及到包含多个span之间关系的推理,传统的BERT则无法处理这类问题;
- 预测一个区间的多个token更加困难;
2、方法:
- 不同于BERT,我们使用不同的随机策略mask掉一个span;
- 添加辅助任务SPO,根据span boundary的两个token表征信息来预测span;
- 随机采样一段文本,而不是两个,删掉了BERT中的Next Sentence Predicition任务
3、span masking
给定一个文本序列X,从中挑选一些token组成Y集合,并迭代地进行采样。
-
在每一次采样过程中,先基于几何分布采样span的长度(最短为1,最长为10,p=0.2),平均采样的区间长度约为3.8:
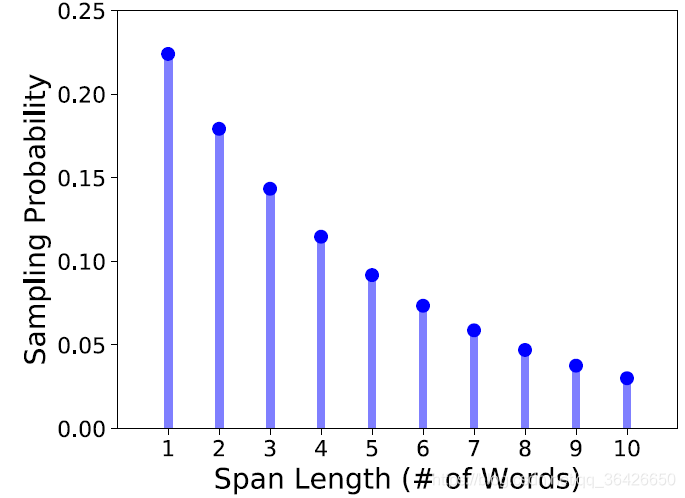
-
然后再基于均匀分布采样span的start位置。由于BERT采用的是word piece,因此需要保证采样的起始点必须是某个单词的起始点。
-
传统的BERT模型中,对一个句子随机mask 15%的token,这些mask掉的token中,有80%被替换为[MASK],10%为随机替换一个token,10%保持不变。spanBERT中则是对span完成的,也就是说整个span的所有token都会满足“80%被替换为[MASK],10%为随机替换一个token,10%保持不变”的设置。
4、span boundary objective
任务目标:根据span的前一个与后一个位置的token来预测span的所有token。假设Transformer的每个token输出记作 x1,...,xn\mathbf{x}_1, ..., \mathbf{x}_nx1,...,xn,给定一个mask span (xs,...,xe)(x_s, ..., x_e)(xs,...,xe),对mask span内的每一个token的表示,取决于 xs−1,xe+1\mathbf{x}_{s-1}, \mathbf{x}_{e+1}xs−1,xe+1、以及位置表征 Pi−s+1\mathbf{P}_{i - s + 1}Pi−s+1(相对于xs−1\mathbf{x}_{s-1}xs−1的距离):
其中 fff 函数为两层前馈网络,并添加Layer normalization:
最终获得的 yi\mathbf{y}_iyi 表示maxk span中的第 iii 个[MASK] token,使用交叉熵损失函数作为目标函数,预测该[MASK]对应的词
5、single-sequence training
作者认为添加next sentence prediction效果不好,因此摈弃这一个任务。
关于对抽取式问答的下有任务,spanBERT依然在模型的输出部分,添加两个独立的分类器,并分别预测start和end的位置。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)