
机器学习入门2--回归之线性回归及梯度下降
本系列博客基于温州大学黄海广博士的机器学习课程的笔记,小伙伴们想更详细学习黄博士课程请移步到黄博士的Github、或者机器学习初学者公众号,现在在中国慕课也是可以学习的,内容包括机器学习、深度学习及Python编程,matplotlib、numpy、pandas、sklearn等,资料很详细,要系统学习请移步哦!笔者的博客只是笔记,内容不会十分详细,甚至会有些少错误!1.几个基本概念# 回归概念:
本系列博客基于温州大学黄海广博士的机器学习课程的笔记,小伙伴们想更详细学习黄博士课程请移步到黄博士的Github、或者机器学习初学者公众号,现在在中国慕课也是可以学习的,内容包括机器学习、深度学习及Python编程,matplotlib、numpy、pandas、sklearn等,资料很详细,要系统学习请移步哦!笔者的博客只是笔记,内容不会十分详细,甚至会有些少错误!
1.几个基本概念
# 回归概念:
# 监督学习分为:回归(Regression)、分类(Classification)
# 1.回归(Regression、Prediction)--标签是连续的;
# a.预测上海浦东的房价;
# b.预测未来股票市场走向;
# 2.分类(Classification)--标签是离散的;
# a.身高170cm,体重60kg的男人穿什么尺码的牛仔裤;
# b.根据肿瘤的体积、患者的年龄来判断肿瘤是良性还是恶性;
# 线性回归(Linear Regression):通过属性的线性组合进行预测的线性模型;
# 目的:找到一条直线或一个平面或更高维的超平面,使得预测值与真实值之间的误差最小化;
2.线性回归
2.1 一些相关符号约定
- mmm:训练集中样本的数量;
- nnn:特征的数量;
- xxx:特征/输入变量;
- yyy:目标变量/输出变量;
- (x,y)(x,y)(x,y):训练集中的样本;
- (x(i),y(i))(x^{(i)},y^{(i)})(x(i),y(i)):第i个观测样本;
- hhh:学习算法的解决方案或函数,称为假设(hypothesis);
- y^=h(x)\hat{y}=h(x)y^=h(x):预测的值;
- x(i)x^{(i)}x(i):特征矩阵中的第iii行,一个向量;
- xj(i)x_j^{(i)}xj(i):特征矩阵中的第iii行的第jjj个特征;
2. 2 三个函数
- 损失函数(Loss Function):度量单样本预测的错误程度,损失函数值越小,模型越好;常用的损失函数:0-1损失函数、平方损失函数、绝对损失函数、对数损失函数等;
- 代价函数(Cost Function):度量全部样本集的平均误差;常用的代价函数:均方误差、均方根误差、平均绝对误差等;
- 目标函数(Object Function):代价函数和正则化函数,最终要优化的函数;
2.3 回归算法流程(最小二乘法)
-
x、y关系x、y关系x、y关系:h(x)=ω0+ω1x1+ω2x2+⋯+ωnxnh(x)=\omega_0+\omega_1x_1+\omega_2x_2+\dots+\omega_nx_nh(x)=ω0+ω1x1+ω2x2+⋯+ωnxn
-
设x0=1x_0=1x0=1,则有h(x)=ω0x0+ω1x1+ω2x2+⋯+ωnxn=ωTXh(x)=\omega_0x_0+\omega_1x_1+\omega_2x_2+\dots+\omega_nx_n=\omega^TXh(x)=ω0x0+ω1x1+ω2x2+⋯+ωnxn=ωTX
-
损失函数采用平方和损失:l(x(i))=12(h(x(i))−y(i))2l(x^{(i)})=\frac{1}{2}(h(x^{(i)})-y^{(i)})^2l(x(i))=21(h(x(i))−y(i))2
-
找到一组ω(ω0,ω1,ω2,…,ωn)\omega(\omega_0,\omega_1,\omega_2,\dots,\omega_n)ω(ω0,ω1,ω2,…,ωn)使得J(ω)=12∑i=1m(h(x(i))−y(i))2最小J(\omega)=\frac{1}{2}\sum_{i=1}^m(h(x^{(i)})-y^{(i)})^2 最小J(ω)=21i=1∑m(h(x(i))−y(i))2最小
-
要找到一组ω(ω0,ω1,ω2,…,ωn)\omega(\omega_0,\omega_1,\omega_2,\dots,\omega_n)ω(ω0,ω1,ω2,…,ωn)使得J(ω)=12∑i=1m(h(x(i))−y(i))2最小J(\omega)=\frac{1}{2}\sum_{i=1}^m(h(x^{(i)})-y^{(i)})^2最小J(ω)=21i=1∑m(h(x(i))−y(i))2最小即最小化:∂J(ω)∂ω\frac{\partial{J{(\omega)}}}{\partial{\omega}}∂ω∂J(ω)
-
将向量表达式转换为矩阵表达式,有:J(ω)=12(Xω−Y)2J(\omega)=\frac{1}{2}(X\omega-Y)^2J(ω)=21(Xω−Y)2
其中:X:m行n+1列的矩阵(m为样本个数,n为特征个数);ω:n+1行1列的矩阵(包含ω0);Y:m行1列矩阵;其中:\\X:m行n+1列的矩阵(m为样本个数,n为特征个数);\\\omega:n+1行1列的矩阵(包含\omega_0);\\Y:m行1列矩阵;其中:X:m行n+1列的矩阵(m为样本个数,n为特征个数);ω:n+1行1列的矩阵(包含ω0);Y:m行1列矩阵; -
由上可得:J(ω)=12(Xω−Y)2=12(Xω−Y)T(Xω−Y)J(\omega)=\frac{1}{2}(X\omega-Y)^2=\frac{1}{2}(X\omega-Y)^T(X\omega-Y)J(ω)=21(Xω−Y)2=21(Xω−Y)T(Xω−Y)
其中:
X=[1x1(1)x2(1)…xn(1)1x1(2)x2(2)…xn(2)⋮⋮⋮⋮⋮1x1(m)x2(m)…xn(m)],Y=[y(1)y(2)⋮y(m)]\\X=\begin{bmatrix} 1 & x_1^{(1)} & x_2^{(1)} & \dots & x_n^{(1)} \\ 1 & x_1^{(2)} & x_2^{(2)} & \dots & x_n^{(2)} \\ \vdots & \vdots & \vdots & \vdots & \vdots\\ 1 & x_1^{(m)} & x_2^{(m)} & \dots & x_n^{(m)}\end{bmatrix},Y=\begin{bmatrix}y^{(1)} \\ y^{(2)} \\ \vdots \\ y^{(m)}\end{bmatrix}X=⎣⎢⎢⎢⎢⎡11⋮1x1(1)x1(2)⋮x1(m)x2(1)x2(2)⋮x2(m)……⋮…xn(1)xn(2)⋮xn(m)⎦⎥⎥⎥⎥⎤,Y=⎣⎢⎢⎢⎡y(1)y(2)⋮y(m)⎦⎥⎥⎥⎤ -
对J(ω)J(\omega)J(ω)求偏导:
∂J(ω)∂ω=12∂∂ω(Xω−Y)T(Xω−Y)=12∂∂ω(ωTXTXω−YTXω−ωTXTY+YTY)=12∂∂ω(ωTXTXω−2ωTXTY+YTY)=12(2XTXω−2XTY+0)=XTXω−XTY \begin{aligned} \frac{\partial{J(\omega)}}{\partial{\omega}} & = \frac{1}{2}\frac{\partial}{\partial\omega}(X\omega-Y)^T(X\omega-Y)\\ & = \frac{1}{2}\frac{\partial}{\partial\omega}(\omega^TX^TX\omega-Y^TX\omega-\omega^TX^TY+Y^TY) \\ & = \frac{1}{2}\frac{\partial}{\partial\omega}(\omega^TX^TX\omega-2\omega^TX^TY+Y^TY)\\ & = \frac{1}{2}(2X^TX\omega-2X^TY+0) \\ & = X^TX\omega-X^TY \end{aligned} ∂ω∂J(ω)=21∂ω∂(Xω−Y)T(Xω−Y)=21∂ω∂(ωTXTXω−YTXω−ωTXTY+YTY)=21∂ω∂(ωTXTXω−2ωTXTY+YTY)=21(2XTXω−2XTY+0)=XTXω−XTY -
令∂J(ω)∂ω=0\frac{\partial{J(\omega)}}{\partial\omega}=0∂ω∂J(ω)=0则有:ω=(XTX)−1XTY\omega=(X^TX)^{-1}X^TYω=(XTX)−1XTY
3.梯度下降
梯度下降的三种形式:
- 批量梯度下降(Batch Gradient Descent,BGD):梯度下降的每一步中,都用到所有的训练样本;
- 随机梯度下降(Stochastic Gradient Descent,SGD):梯度下降的每一步中,用到一个样本,在每一次计算后,便更新参数,不需要首先将所有的训练集求和;
- 小批量梯度下降(Mini-Batch Gradient Descent,MBGD):梯度下降的每一步中,用到一定批量的训练样本;
3.1 批量梯度下降(Batch Gradient Descent)
- 参数更新:
ωj:=ωj−α1m∑i=1m((h(x(i))−y(i))⋅xj(i)),同步更新ωj,(j=0,1,…,n) \omega_j:=\omega_j-\alpha\frac{1}{m}\sum_{i=1}^m((h(x^{(i)})-y^{(i)})·{x_j^{(i)}}),同步更新\omega_j,(j=0,1,\dots,n) ωj:=ωj−αm1i=1∑m((h(x(i))−y(i))⋅xj(i)),同步更新ωj,(j=0,1,…,n)
3.2 随机梯度下降(Stochastic Gradient Descent)
- 推导过程:
ω=ω−α⋅∂J(ω)∂ωh(x)=ωTX=ω0x0+ω1x1+ω2x2+⋯+ωnxnJ(ω)=12(h(x(i))−y(i))2∂∂ωjJ(ω)=∂∂ωj12(h(x(i))−y(i))2=2⋅12(h(x(i))−y(i))⋅∂∂ωj(h(x(i))−y(i))=(h(x(i))−y(i))⋅∂∂ωj(∑i=0n(ωixi(i)−y(i)))=(h(x(i))−y(i))xj(i) \begin{aligned} \omega =& \omega-\alpha·\frac{\partial{J(\omega)}}{\partial\omega} \\ h(x) &= \omega^TX=\omega_0x_0+\omega_1x_1+\omega_2x_2+\dots+\omega_nx_n \\ J(\omega) =& \frac{1}{2}(h(x^{(i)})-y^{(i)})^2 \\ \frac{\partial}{\partial\omega_j}J(\omega) =& \frac{\partial}{\partial\omega_j}\frac{1}{2}(h(x^{(i)})-y^{(i)})^2 \\ =& 2·\frac{1}{2}(h(x^{(i)})-y^{(i)})·\frac{\partial}{\partial\omega_j}(h(x^{(i)})-y^{(i)}) \\ =& (h(x^{(i)})-y^{(i)})·\frac{\partial}{\partial\omega_j}(\sum_{i=0}^n(\omega_ix_i^{(i)}-y^{(i)}))\\ =& (h(x^{(i)})-y^{(i)})x_j^{(i)} \end{aligned} ω=h(x)J(ω)=∂ωj∂J(ω)====ω−α⋅∂ω∂J(ω)=ωTX=ω0x0+ω1x1+ω2x2+⋯+ωnxn21(h(x(i))−y(i))2∂ωj∂21(h(x(i))−y(i))22⋅21(h(x(i))−y(i))⋅∂ωj∂(h(x(i))−y(i))(h(x(i))−y(i))⋅∂ωj∂(i=0∑n(ωixi(i)−y(i)))(h(x(i))−y(i))xj(i) - 参数更新:
ωj:=ωj−α(h(x(i))−y(i))xj(i),同步更新ωj(j=0,1,…,n) \omega_j:=\omega_j-\alpha(h(x^{(i)})-y^{(i)})x_j^{(i)},同步更新\omega_j(j=0,1,\dots,n) ωj:=ωj−α(h(x(i))−y(i))xj(i),同步更新ωj(j=0,1,…,n)
3.3 小批量梯度下降(Mini-Batch Gradient Descent)
- 参数更新:
ωj:=ωj−α1b∑k=ii+b−1(h(x(k))−y(k))xj(k),同步更新ωj(j=0,1,2,…,n) \omega_j:=\omega_j-\alpha\frac{1}{b}\sum_{k=i}^{i+b-1}(h(x^{(k)})-y^{(k)})x_j^{(k)},同步更新\omega_j(j=0,1,2,\dots,n) ωj:=ωj−αb1k=i∑i+b−1(h(x(k))−y(k))xj(k),同步更新ωj(j=0,1,2,…,n) - bbb的取值:
b=1:随机梯度下降,SGD;b=m:批量梯度下降,BGD;b=batch_size:小批量梯度下降,MBGD,一般是2的倍数,常见:32,64,128等; \begin{aligned} b =& 1:随机梯度下降,SGD;\\ b =& m:批量梯度下降,BGD;\\ b =& batch\_size:小批量梯度下降,MBGD,一般是2的倍数,常见:32,64,128等; \end{aligned} b=b=b=1:随机梯度下降,SGD;m:批量梯度下降,BGD;batch_size:小批量梯度下降,MBGD,一般是2的倍数,常见:32,64,128等;
3.4 梯度下降与最小二乘法比较
- 梯度下降:需要选择学习率α\alphaα,需要多次迭代,当特征数量n大时能较好适用,适用于各种类型的模型;
- 最小二乘法:不需要选择学习率α\alphaα,一次计算得出,需要计算(XTX)−1(X^TX)^{-1}(XTX)−1,如果特征数量n较大,则运算代价大,只适用于线性模型,不适合逻辑回归等其他模型;
3.5 数据归一化/标准化
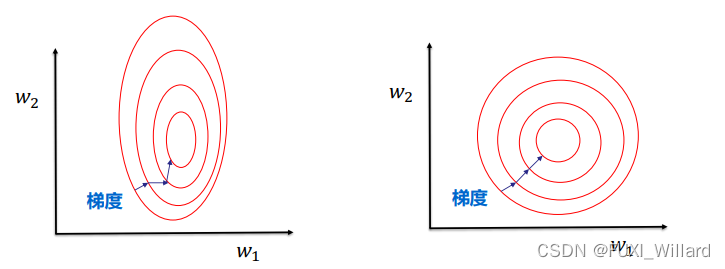
- 数据归一化可以提升模型精度:不同维度间的特征在数值上有一定比较性,可以提高分类器的准确性;
- 数据归一化可以加速模型收敛:最优解的寻优过程明显变得平缓,更容易正确的收敛到最优解;
3.5. 1 归一化(最大-最小规范化)
-
数据归一化:使得各特征对目标变量影响一致,会将特征数据进行伸缩变化,数据归一化会改变特征数据分布;
x∗=x−xminxmax−xmin,将数据映射到[0,1]区间; x^* = \frac{x-x_{min}}{x_{max}-x_{min}},将数据映射到[0,1]区间; x∗=xmax−xminx−xmin,将数据映射到[0,1]区间; -
Z-Score标准化:使得不同特征间具备可比性,经过标准化变换后特征数据分布没有发生改变;
x∗=x−μσ,处理后数据均值为0,方差为1; x^* = \frac{x-\mu}{\sigma},处理后数据均值为0,方差为1; x∗=σx−μ,处理后数据均值为0,方差为1;
3.5. 2 归一化/标准化的模型
-
需要做数据归一化/标准化的模型:
-
a.线性模型:KNN(K近邻)、K-means聚类、感知机、SVM;
-
不需要做数据归一化/标准化的模型:
-
a.决策树、基于决策树的Boosting和Bagging等集成学习模型;
-
b.随机森林、XGBoost、LightGBM等树模型;
-
c.朴素贝叶斯;

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)