
数据开发高频面试题之维度建模
维度建模是数据仓库设计的核心基础,其本质是在业务数据之上构建一个高效的分析体系。通过事实表(记录业务事件)与维度表(描述业务背景)的组合,形成星型、雪花或星座模型。维度建模的关键在于:选择业务过程、声明数据粒度、确定维度和事实,最终实现查询性能优化和业务可读性。相比业务系统的原始数据,维度建模需要进行数据标准化(如统一ID格式)、历史数据处理(如拉链表)和分析属性扩展(如年龄分组)。良好的维度建模
前言
有句话叫做“底层基础决定上层建筑”,在数据开发领域,这简直是金科玉律!就算你SQL写得飞起,逻辑推理堪比福尔摩斯,如果底层的模型设计——特别是维度建模——不合理、不清晰,那一切都将事倍功半,甚至功亏一篑。
优秀的维度建模,就是为数据仓库打下坚实、清晰、灵活的地基。 它定义了数据的“语言”和“骨架”,确保数据易于理解、高效访问、稳定可靠、并能适应业务变化。它让复杂的业务逻辑在底层就被合理抽象和组织,使得上层的查询、分析、应用开发变得顺畅、敏捷、可维护。没有这个坚实的地基,再炫酷的上层建筑(报表、分析、应用)都不过是空中楼阁,经不起时间和需求的考验。 因此,磨刀不误砍柴工,在模型设计上多花一分心思,就能在后续开发中省下十分力气,避免百分麻烦。这才是数据开发真正的“硬实力”和“高境界”。
本文将从以下几个方面讨论维度建模相关的知识,欢迎留言讨论与指正。
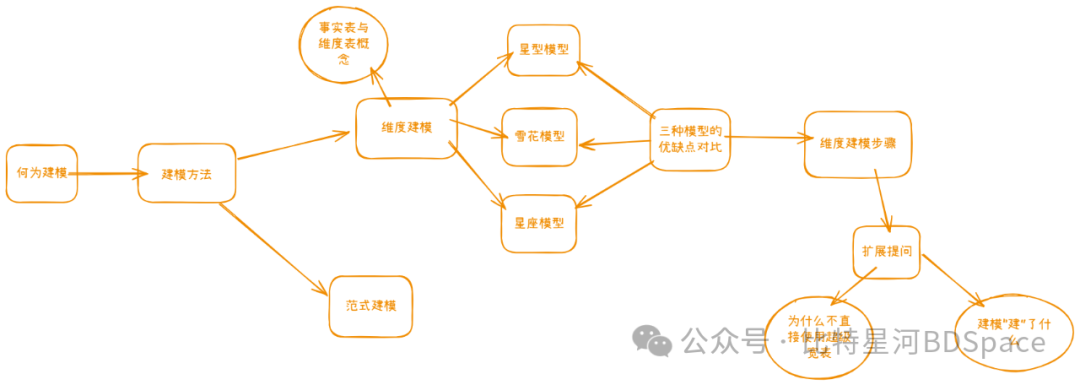
何为建模
建模(Data Modeling)在数仓开发中的本质是设计数据的存储结构(表结构)及其关系,通俗点讲就是设计一套表结构来承载数据,支持分析需求。主要包括:
-
定义数据如何组织:表、字段、数据类型
定义数据间关系:主键、外键、关联逻辑
服务于特定目标:高效查询、减少冗余、保证一致性、业务可读性等
建模方法
-
维度建模
核心理念: 将数据组织成直观的、以业务过程为中心的星型模式或雪花模式,核心结构是事实表+维度表
目标: 优化查询性能,提升业务用户(分析师、决策者)的理解和使用体验,支持在线分析处理(OLAP),它关注的是“如何方便、快速地分析数据”
特点: 反规范化设计,数据冗余相对较高,结构简单,查询速度快
-
范式建模/3NF
核心理念: 遵循关系数据库设计理论(尤其是第三范式),将数据分解成多个高度规范化的、通过主键/外键关联的实体表,核心是实体关系模型
目标: 消除数据冗余,确保数据一致性、完整性和高效的在线事务处理(OLTP)操作(插入、更新、删除),它关注的是“如何精确、无冗余地存储数据”
特点: 高度规范化,数据冗余极低,结构复杂(表多),更新操作高效,但复杂查询性能通常较差(需要大量 JOIN)
事实表与维度表
维度建模的核心结构是事实表+多个维度表
事实表告诉我们“发生了什么”,而维度表则告诉我们“这些事情是在什么背景下发生的”。事实表是动词(发生了什么),维度表是形容词(谁/什么/在哪里);举个最简单的例子,“小张去超市买了一瓶冰阔落” 请问这件事情会被超市的数据分析师记录在哪些表里面?首先事实表“小张+冰阔落+3块钱+今天下午” 其次围绕这件事情有多少维度表?用户信息表,产品信息表,超市店铺信息表,时间维度表...
维度建模模型
-
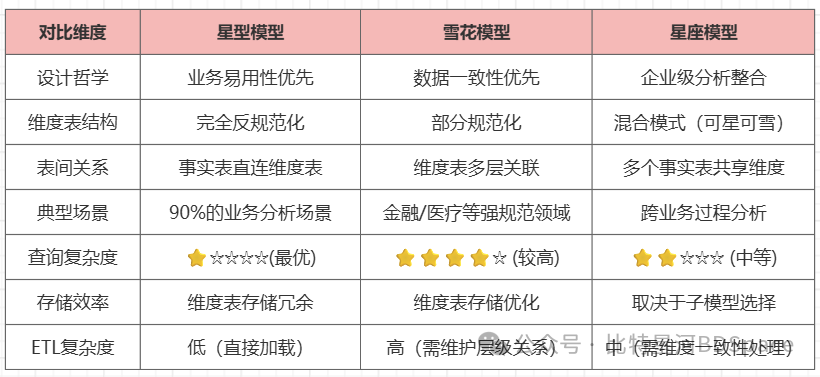
星型模型
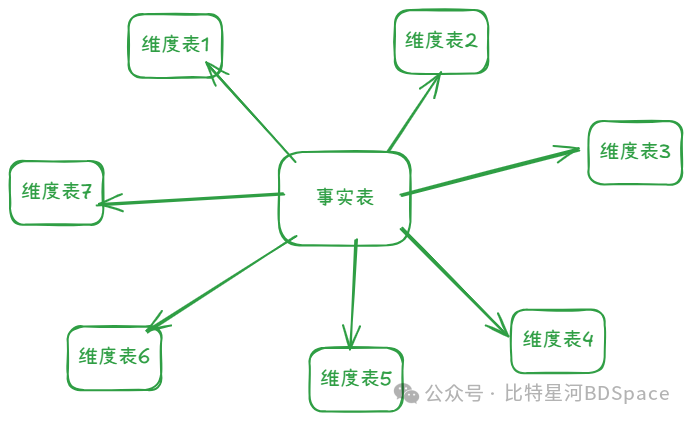
维度表反规范化,包含所有层级信息(如用户表直接包含省、市字段),查询只需1次JOIN(事实表→维度表),用空间换时间,性能最优
-
雪花模型
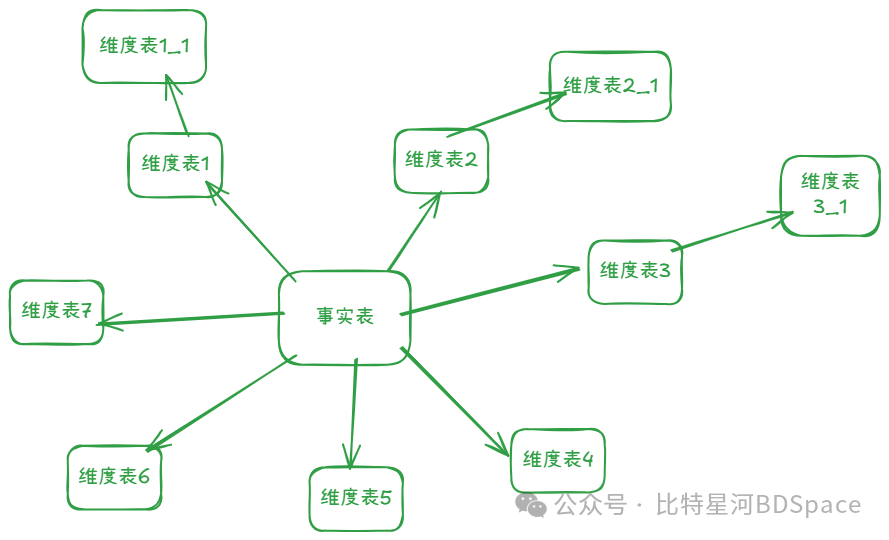
维度表再规范化,拆得更细(如用户表关联到独立的地址表),查询需多层JOIN(事实表→用户表→地址表)
-
星座模型
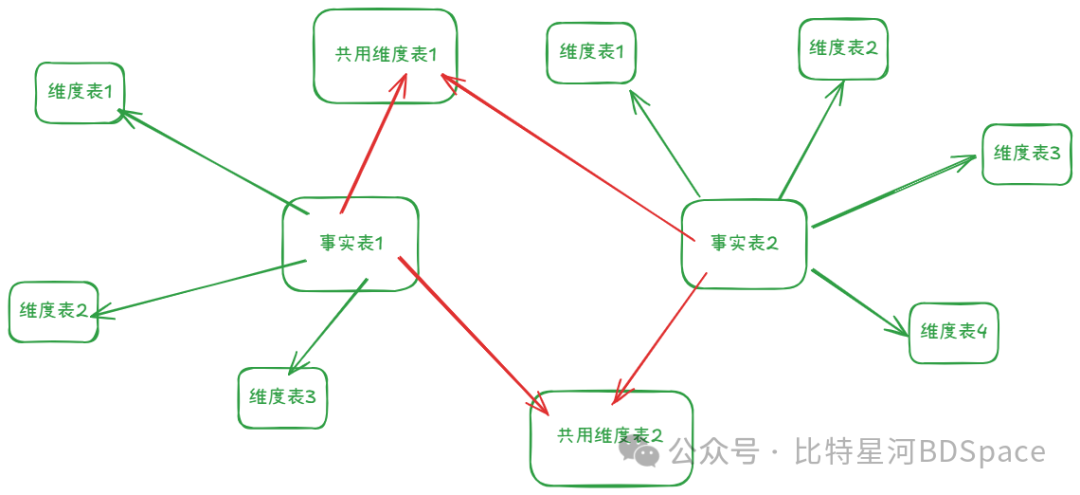
多个事实表存在共用维度表
三种模型的优缺点对比
维度建模步骤
-
选择业务过程:
确定要建模的具体业务活动或事件(如:销售订单、客户服务请求、库存变动、网站点击),通常对应源系统中的一个主要事务或事件表
-
声明粒度:
这是最关键的一步! 明确定义事实表中的每一行数据代表业务上的什么(最原子级别的细节)。粒度决定了事实表的详细程度和分析能力。建议选择最细粒度的数据,以满足未来不可预知的分析需求
-
确定维度:
围绕业务过程,找出所有用于描述事实发生“谁、什么、何时、何地、为什么、如何”的描述性上下文,为每个维度确定主键
-
确定事实:
确定在业务过程中发生的、可量化、可加的度量值(指标)。常见事实:销售额、销售数量、成本、利润、点击数、停留时长、交易笔数等,事实通常是数值型的
-
模型选择:
星型模式:一个中心事实表,周围环绕着多个(通常是反规范化的)维度表。维度表直接连接到事实表。这是最常用、性能最好的结构
雪花模式:是星型模式的规范化版本。维度表自身也可能被进一步规范化,分解成多个关联的子维度表。这减少了维度表的冗余,但增加了JOIN的复杂度,可能影响查询性能
扩展提问
1. 既然维度建模是为了方便分析,为什么不直接把所有维度设计到一个表里,这样查询速度更快?(面试真题)
方案A直接将所有维度暴力堆砌到一张表里面

引发的问题:
-
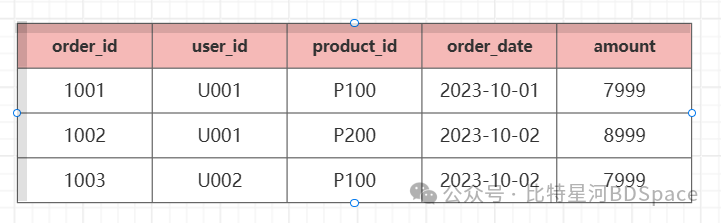
灾难性冗余:假如用户张三买了100次商品,“张三,28,北京,北京市”重复存100次!
-
更新异常:若张三搬家到深圳,需更新所有历史订单记录(数量可能上亿)。
-
存储爆炸:每行存储大量重复文本(用户/商品/地址信息),存储成本飙升。
-
维护地狱:新增维度(如“用户等级”)需修改全表结构,重刷历史数据。
方案B 采用星型模型维度建模
事实表(存储行为)
维度表(存储描述)
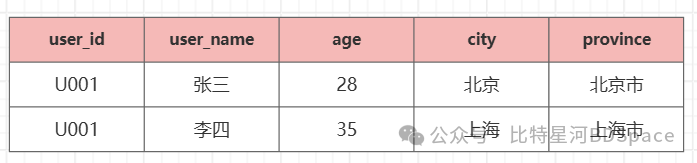
- 用户维度表
- 商品维度表

优势:
-
零冗余存储:用户/商品信息只存1次,事实表只存ID和数值。
-
更新安全:修改用户地址只需更新维度表1行,不影响历史事实。
-
查询性能高:分析时通过`user_id`关联维度表,数据库优化器可高效处理。
-
扩展灵活:新增维度属性(如商品颜色)只需在维度表加字段。
2. 以上所讨论的维度建模模型设计无非就是将业务系统的维度表围绕一个事实表组合一下,跟直接使用业务系统的数据也差不多,这也叫设计?请问你设计了什么?(面试真题)
以上讨论仅仅是在理想的情况下进行的,举个最简单的例子,user_id这个字段,在我们的例子中可以直接使用关联,但在真实的业务场景下,不同的业务系统可能对于user_id定义的格式不一致,那么我们想要在数仓中做到统一分析,是否就需要打通各业务线的用户数据,使用统一的标准来重新定义user_id!再比如用户维度表,我们是否还需要将其构建为拉链表来维护历史变化的信息!再比如还是用户维度表,现在只有一些基础分析属性,比如姓名:张三,年龄:28,在设计的时候是否还可以增加一些分析属性,如年龄分组!
建模到底“建”了什么!
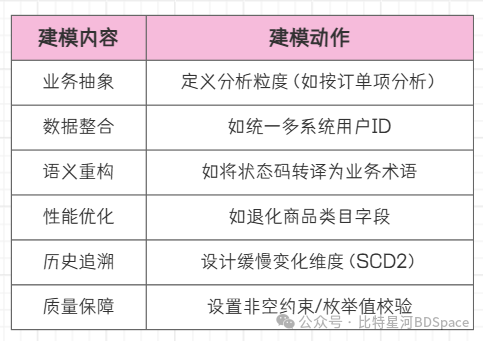
维度建模的本质:在混乱的业务数据之上,构建一个符合分析相对论的平行宇宙。代理主键是粒子坐标,维度表是引力场,事实表是运动轨迹。这才是真正的“设计”,而非简单的表合并。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)