
08 大模型学习——注意力机制
注意力机制 (Attention Is All You Need) ,基础认知及代码实现
注意力机制 (Attention Is All You Need)
一、注意力机制原理
从注意力模型的命名方式看,很明显其借鉴了人类的注意力机制,因此,我们首先简单介绍人类视觉的选择性注意力机制。
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
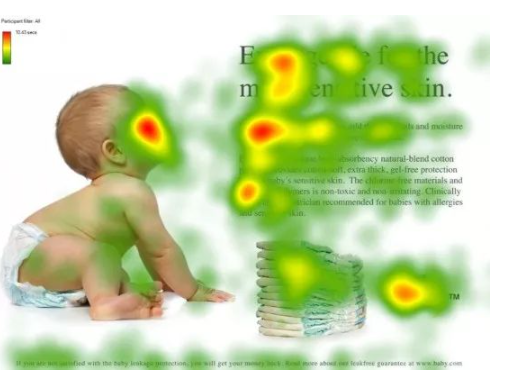
图1形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于图1所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是「从关注全部到关注重点」

Attention 机制很像人类看图片的逻辑,当我们看一张图片的时候,我们并没有看清图片的全部内容,而是将注意力集中在了图片的焦点上。大家看一下下面这张图,我们的视觉系统就是一种 Attention机制,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。其实,当我们看一张图片的时候,其实是右边这样的。



- 我们的视觉系统就是一种 Attention机制,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
- 人的注意力和模型的注意力本质是一样, 它是一个有限的资源,就看你怎么分配。
- 注意力机制就是一种有限分配的资源。
- 模型怎么知道该注意什么呢?
- 给谁注意力多,给谁注意力少,和模型的参数有关系,是模型训练的结果
- 不断调整模型的参数,模型的注意力, 是模型学习到的结果
二、注意力公式
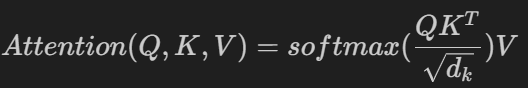
d_k是Q,K矩阵的列数,即向量的维度
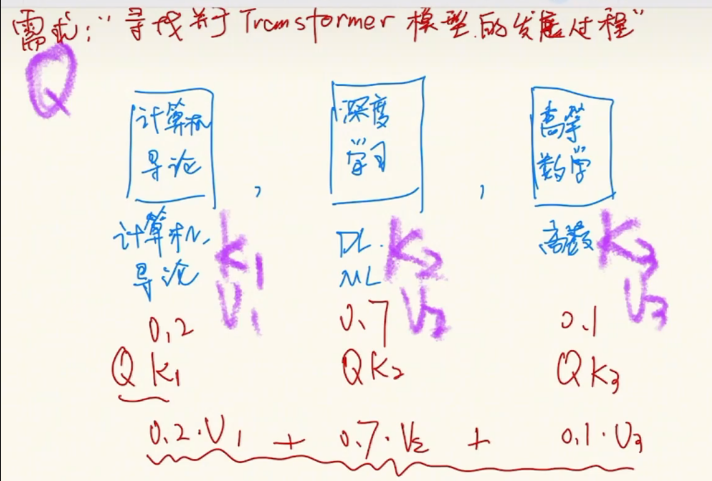
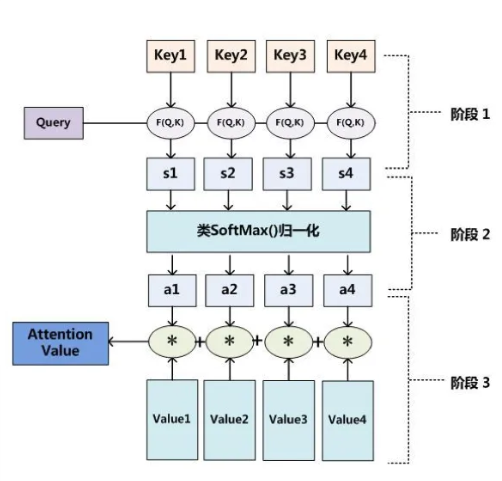
Attention 原理的3步分解:
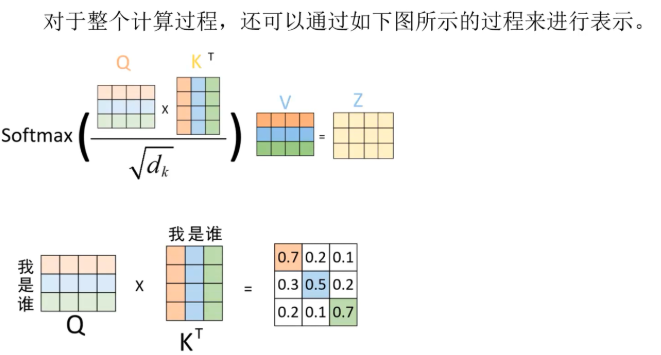
+ 第一步: query 和 key 进行相似度计算,除以根号d_k得到权值
+ 第二步:将权值进行softmax归一化,得到直接可用的权重
+ 第三步:将权重和 value 进行加权求和
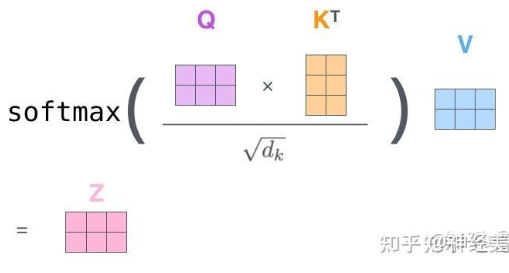
除以d_k开根号的原因:在Attention机制中,当向量维度dk较大时,点积结果可能变得非常大,导致softmax函数进入饱和区,梯度消失。为了解决这个问题,引入缩放因子dk来缩小点积结果,使softmax函数保持敏感。实验表明,这个缩放因子可以有效防止梯度消失。
公式:
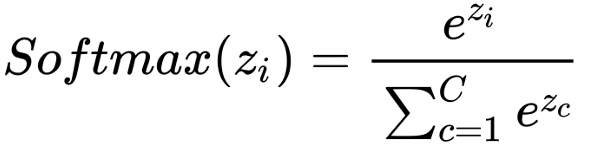
- y = np.exp(z) / np.sum(np.exp(z))
值域:[0, 1]
用途:softmax通常在多分类问题中用于神经网络的输出层。
曲线图:
三、注意力机制代码实现
import torch
import math
def attention(q, k, v, dropout=None):
# 将k矩阵的最后一个维度值作为d_k
d_k = k.size(-1)
# 将k矩阵的最后两个维度互换(转置),与q矩阵相乘,除以d_k开根号
scores = torch.matmul(q, k.transpose(-2,-1)) / math.sqrt(d_k)
p_attn = torch.softmax(scores, dim=-1) # dim=-1
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, v)**Attention 的3大优点**
- 参数少 模型复杂度跟 CNN、RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。
- 速度快 Attention 解决了 RNN 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
- 效果好 在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
Attention 是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。
四、自注意力机制(Self-Attention)
注意力机制的Q和K来自不同的来源。例如,在中译英模型中,Q是中文单词的特征,而K是英文单词的特征。而**自注意力机制的查询和键则来自同一组元素**,即Q和K都是中文特征,彼此之间进行注意力计算。这可以理解为,同一句话中的词或同一张图像中的不同部分之间的相互作用。因此,自注意力机制(Self-Attention)也被称为内部注意力机制(Intra-Attention)。
句子:"The animal didn't cross the street because it was too tired." 在这个句子中,“it”指的"animal"
在自注意力机制中,当我们处理到“it”这个词时,模型会计算“it”与句子中其他所有词的关联度。这意味着“it”不仅会考虑前一个词“too”,还会考虑更早出现的词,比如“animal”。
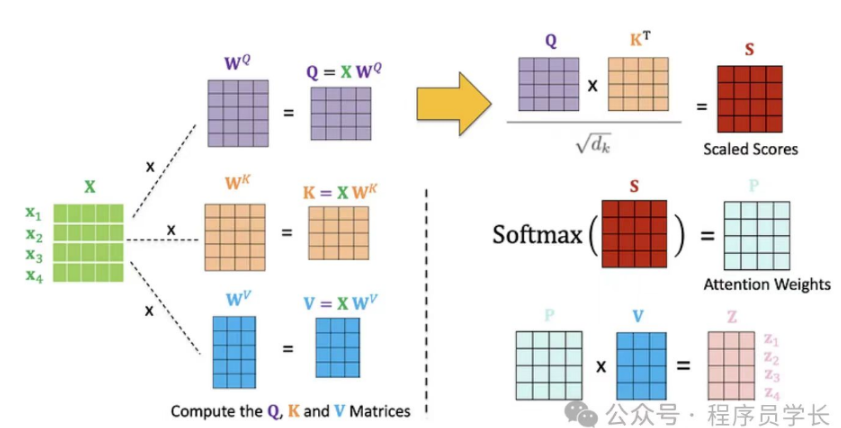
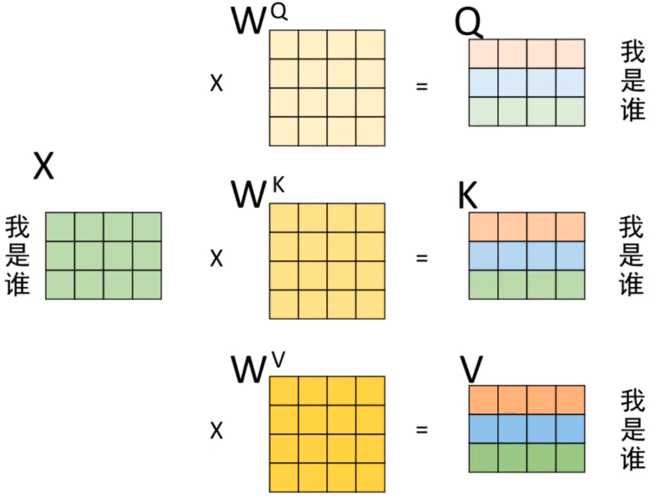
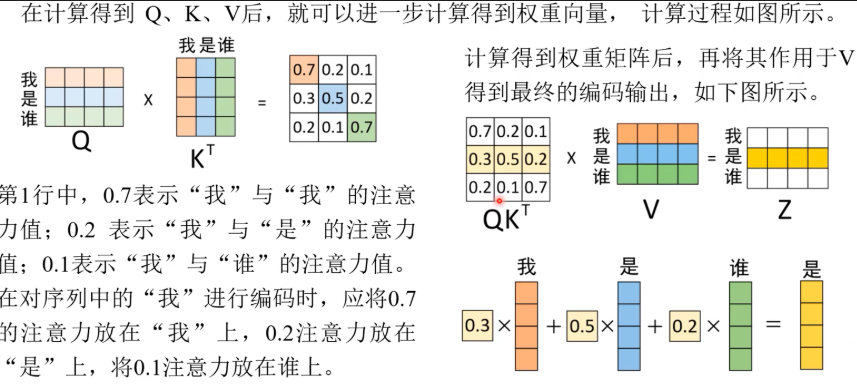
在自注意力机制中,词向量矩阵通常不会直接用于计算,而是需要通过一个全连接层(线性变换)后再进行计算(d_model, d_model)。这种做法主要有以下几个原因:
- 维度匹配:注意力机制中,查询(Query)、键(Key)和值(Value)的维度可能不一致。通过全连接层,可以将词向量映射到一个统一的维度空间,确保后续计算的一致性。
- 特征提取:全连接层可以看作是一种特征提取工具,它能够将原始词向量转换为更高级的语义表示,从而更好地捕捉句子中的上下文信息。
- 参数学习:全连接层的参数可以通过训练过程进行优化,使得模型能够根据任务需求自动调整词向量的表示,从而提升模型的性能。
- 注意力权重:注意力机制的核心是计算注意力权重,这些权重决定了每个词在上下文中的重要性。通过全连接层,可以更好地计算这些权重,使得模型能够更准确地捕捉到句子中的重要信息。增强模型的表达能力、灵活性。
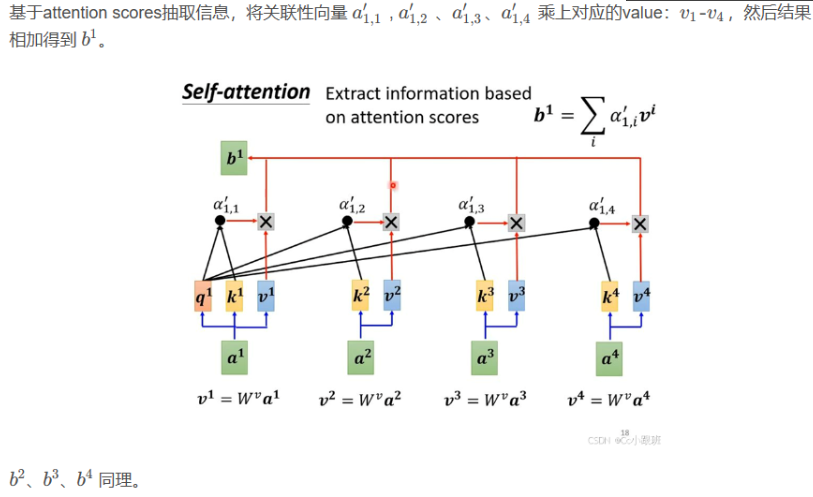
- 每个词都会被编码为三个向量:Query(查询)、Key(键)和Value(值)。这些向量是通过将原始词嵌入分别乘以三个不同的权重矩阵得到的。
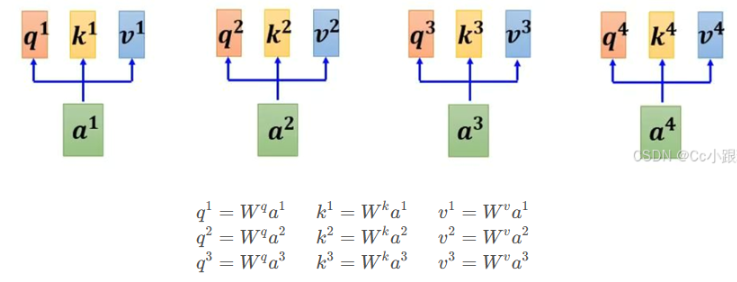
- 对于每个位置上的词(例如“it”),我们会用它的Query向量和其他所有词的Key向量进行点积运算,然后除以某个缩放因子(通常是根号下Key向量的维度)
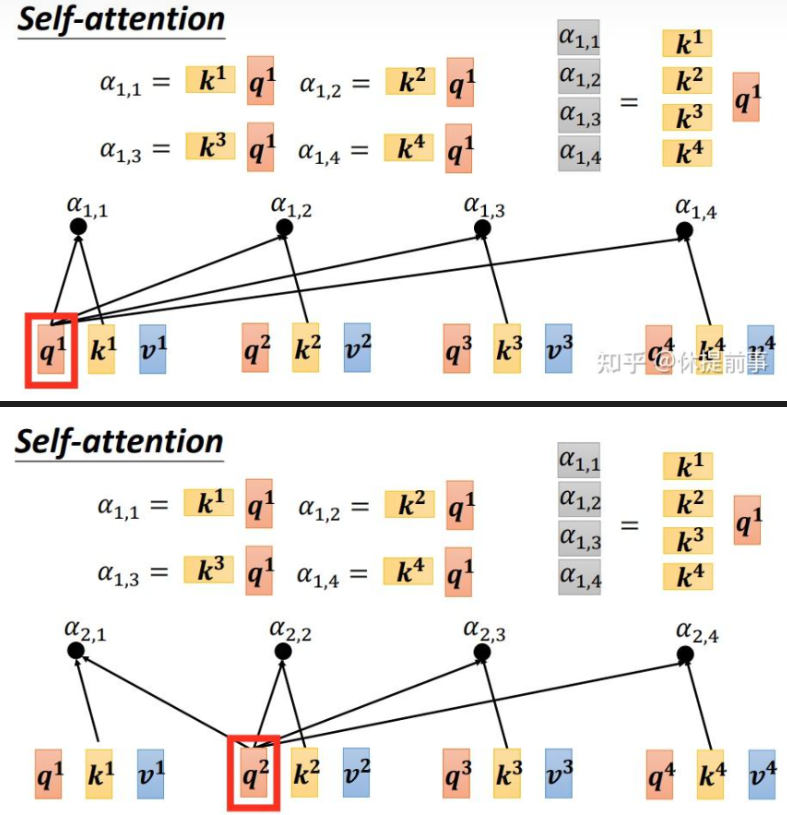
- 以此来衡量它们之间的相关性或相似度。接下来,我们将上述得到的相关性分数通过softmax函数转换成概率分布,这样就能确保所有分数加起来等于1,并且可以解释为“it”与其他词的相对重要性。
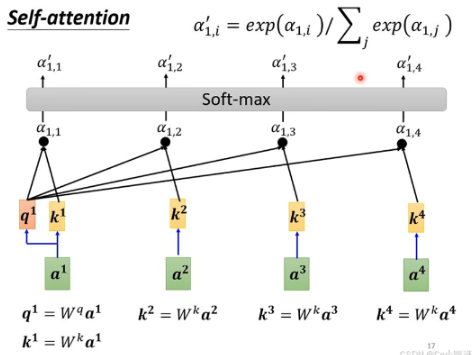
五、自注意力机制代码实现
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, hidden_dim):
super(SelfAttention, self).__init__()
# 一般 Linear 都是默认有 bias
# 一般来说, input dim = hidden dim ,即词向量的维度
self.q_linear = nn.Linear(hidden_dim,hidden_dim)
self.k_linear = nn.Linear(hidden_dim,hidden_dim)
self.v_linear = nn.Linear(hidden_dim,hidden_dim)
def forward(self, x):
# X shape is: (batch, seq_len, hidden_dim), 一般是和 hidden_dim 相同
# 但是 X 的 final dim 可以和 hidden_dim 不同
q = self.q_linear(x)
k = self.q_linear(x)
v = self.q_linear(x)
output = attention(q,k,v)
return output
x = torch.rand(3,2,4)
net = SelfAttention(4)
y = net(x)
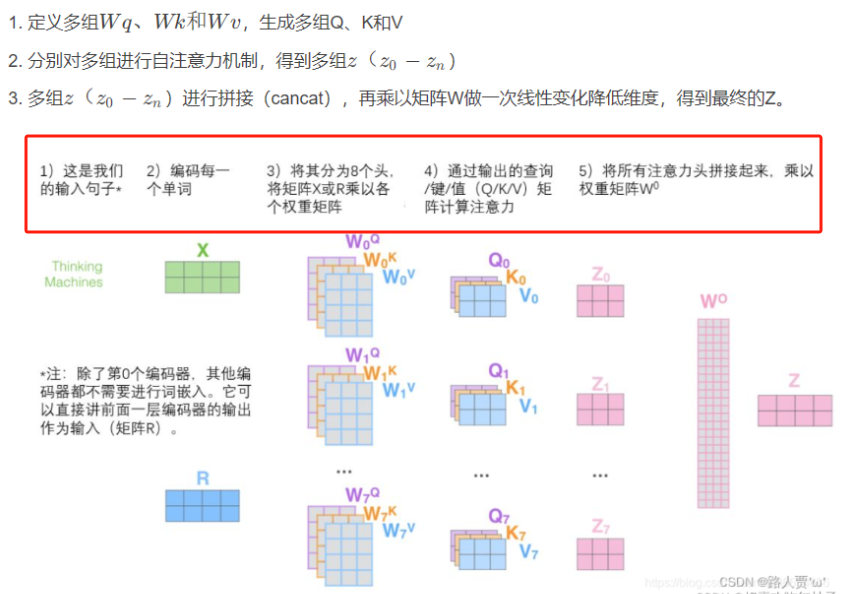
print(y.shape) # (3,2,4)六、多头自注意力机制(Multi-Head Self-Attention)
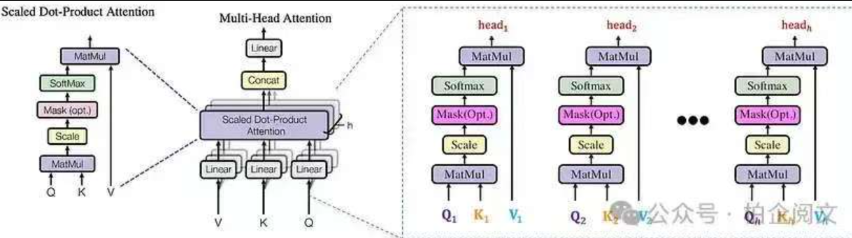
计算机可能需要执行好几次注意力才能真正观察到图片中有效的信息,因此执行多头注意力,然后把多头注意力的值进行concat融合。
在自注意力机制的基础上,增加可训练的线性变换(即矩阵相乘),以提高模型的拟合能力.
**多头自注意力机制就是同时通过多个"自注意力机制"进行特征提取**


import torch
import torch.nn as nn
class MultHeadedAttention(nn.Module):
def __init__(self, d_model, n_head, dropout=0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
# 断言,必须能被整除
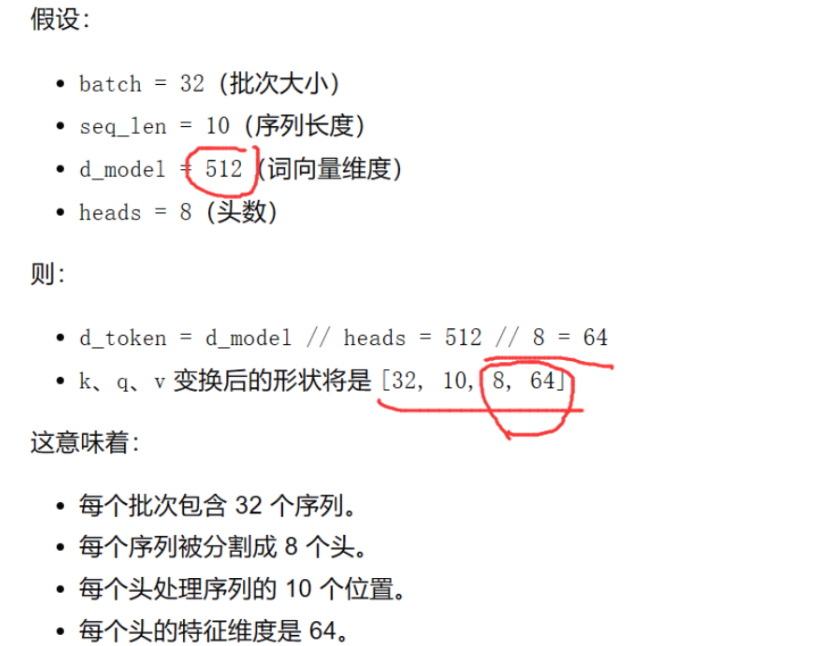
assert d_model % n_head == 0
self.d_token = d_model // n_head
self.n_head = n_head
self.W_Q = nn.Linear(d_model, d_model, bias=False)
self.W_K = nn.Linear(d_model, d_model, bias=False)
self.W_V = nn.Linear(d_model, d_model, bias=False)
self.linear = nn.Linear(d_model, d_model, bias=False)
def forward(self,q,k,v):
# 分头的主要目的是让模型能够同时关注输入序列的不同部分,从而捕捉更丰富的特征
# q,k,v shape ==> batch_size,seq_len,d_mdoel
batch = q.size(0)
q_seq_len = q.size(1)
k_seq_len = k.size(1)
v_seq_len = v.size(1)
# (batch_size, seq_len, d_model) ===> (batch_size, seq_len, n_head, d_token)
# 其中 n_head 是头的数量,d_token 是每个头的维度
# 为了方便attention计算,需要将头的维度移到前面,变成 (batch_size, n_head, seq_len, d_token)
# 矩阵运算(如 torch.matmul)通常对最后两个维度进行操作。
# 将头的维度移到前面后,可以直接对 seq_len 和 d_token 维度进行矩阵乘法
q = self.W_Q(q).view(batch,q_seq_len,self.n_head,self.d_token).transpose(1,2)
k = self.W_K(k).view(batch,k_seq_len,self.n_head,self.d_token).transpose(1,2)
v = self.W_V(v).view(batch,v_seq_len,self.n_head,self.d_token).transpose(1,2)
# 计算注意力
att = attention(q,k,v,self.dropout)
# 拼接
# contiguous()确保张量在内存中是连续存储的,提高计算效率
concat = att.transpose(1,2).contiguous().reshape(batch,-1,self.n_head*self.d_token)
output = self.linear(concat)
return output
mha = MultHeadedAttention(8,2)
q=k=v= torch.randn(2,3,8)
mha_out = mha(q,k,v)
print(mha_out.shape) # torch.Size([2, 3, 8])七、在卷积神经网络中加入注意力机制
import torch
import torch.nn as nn
class CNNWithAttention(nn.Module):
def __init__(self,num_classes):
super().__init__()
self.conv_layers = nn.Sequential(
nn.Conv2d(3,16,3,bias=False),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16,32,3,bias=False),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32,64,3,bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,128,3,bias=False),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128,256,3,bias=False),
nn.BatchNorm2d(256),
nn.ReLU()
)
# 多头注意力机制
# self.attention = nn.MultiheadAttention(embed_dim=32,num_heads=1)
self.attention = MultHeadedAttention(d_model=256,n_head=4)
# 全连接层
self.fc = nn.Linear(400*256,num_classes)
def forward(self,x):
# 卷积层前向传播
x = self.conv_layers(x) # 输出形状: [1, 256, 20, 20] (N, C, H, W)
# 调整形状以适应注意力机制
x = x.permute(0,2,3,1) # 形状: [1, 20, 20, 256] (N, H, W, C)
# 调整为(batch_size,seq_len,embedding_dim)
x = x.reshape(x.size(0),-1,x.size(-1)) # 形状: [1, 400, 256] (N, V, C)
# 多头自注意力 q=k=v=x
x= self.attention(x,x,x) # 形状: [1, 400, 256]
x = x.reshape(x.size(0), -1) # 形状: [1, 400 * 256]
# x = x.reshape(-1,400*256) # 形状: [1, 400 * 256]
x = self.fc(x) # 形状: [1, num_classes]
return x
# 创建模型实例
model = CNNWithAttention(6)
x = torch.randn(1,3,112,112)
y = model(x)
print(y.shape) # torch.Size([1, 6])#把图片转成 张量(tensor)
import numpy as np
from torch.utils.data import Dataset,DataLoader
import os
import torch
from PIL import Image
from torchvision import transforms
# transform = transforms.Compose(
# [transforms.ToTensor(),
# transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
class Mydataset(Dataset):
def __init__(self,path):
super().__init__()
self.path = path
self.dataset=[]
label_dir_list = os.listdir(path)
for label_name in label_dir_list:
img_list = os.listdir(os.path.join(path,label_name))
for img_name in img_list:
self.dataset.append((os.path.join(path,label_name,img_name),int(label_name)))
def __len__(self):
#返回dataset列表的长度
return len(self.dataset)
def __getitem__(self, index):
data=self.dataset[index]
img_path = data[0]
img = Image.open(img_path)
img = img.resize((112,112))
img_data = transforms.ToTensor()(img)
label = torch.tensor(data[1])
return img_data,label
if __name__ == '__main__':
mydata = Mydataset("./data/bird_data_set")
data_loader =DataLoader(mydata,batch_size=20,shuffle=True)
for i,(img,label) in enumerate(data_loader):
x = img[0]
y = label[0]
#训练代码
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 超参数
num_epochs = 10
batch_size = 64
learning_rate = 0.001
num_classes = 6
writer = SummaryWriter("logs")
# train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True,
# download=True, transform=transform)
# train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size,
# shuffle=True)
# test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False,
# download=True, transform=transform)
# test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size,
# shuffle=False)
train_dataset = Mydataset("./data/bird_data_set")
train_loader = DataLoader(train_dataset, batch_size=batch_size,shuffle=True)
# 创建模型实例
model = CNNWithAttention(num_classes)
# 定义损失函数和优化器
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 训练循环
train_sum_loss=0
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# 前向传播
outputs = model(images)
loss = loss(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_sum_loss += loss.item()
train_avg_loss = train_sum_loss / len(train_loader)
writer.add_scalar("train_avg_loss",train_avg_loss,epoch)
print(f"Epoch {epoch}, Loss {train_avg_loss}")
# # 在测试集上进行评估
# model.eval()
# with torch.no_grad():
# correct = 0
# total = 0
# for images, labels in test_loader:
# outputs = model(images)
# _, predicted = torch.max(outputs.data, 1)
# total += labels.size(0)
# correct += (predicted == labels).sum().item()
# accuracy = 100 * correct / total
# print(f"Test Accuracy: {accuracy:.2f}%")
GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)