
SEO:爬虫爬取的模型和策略
文章目录简易模型广度、深度优先遍历非完全PageRank算法OPIC策略大站优先策略简易模型首先,从互联网不断的抓取很多url到我们的待爬取队列中,然后经过某些规则通过下载器来下载这些url,最后将爬取的页面放在网页库里等待建立索引,并且在已抓取的url队列里存放一份,以防止重复的抓取。那么问题来了,这么多的url,我应该按什么样的规则去抓取呢?那么就有了接下来的这几种策略:这几种策略的核心就是:
简易模型
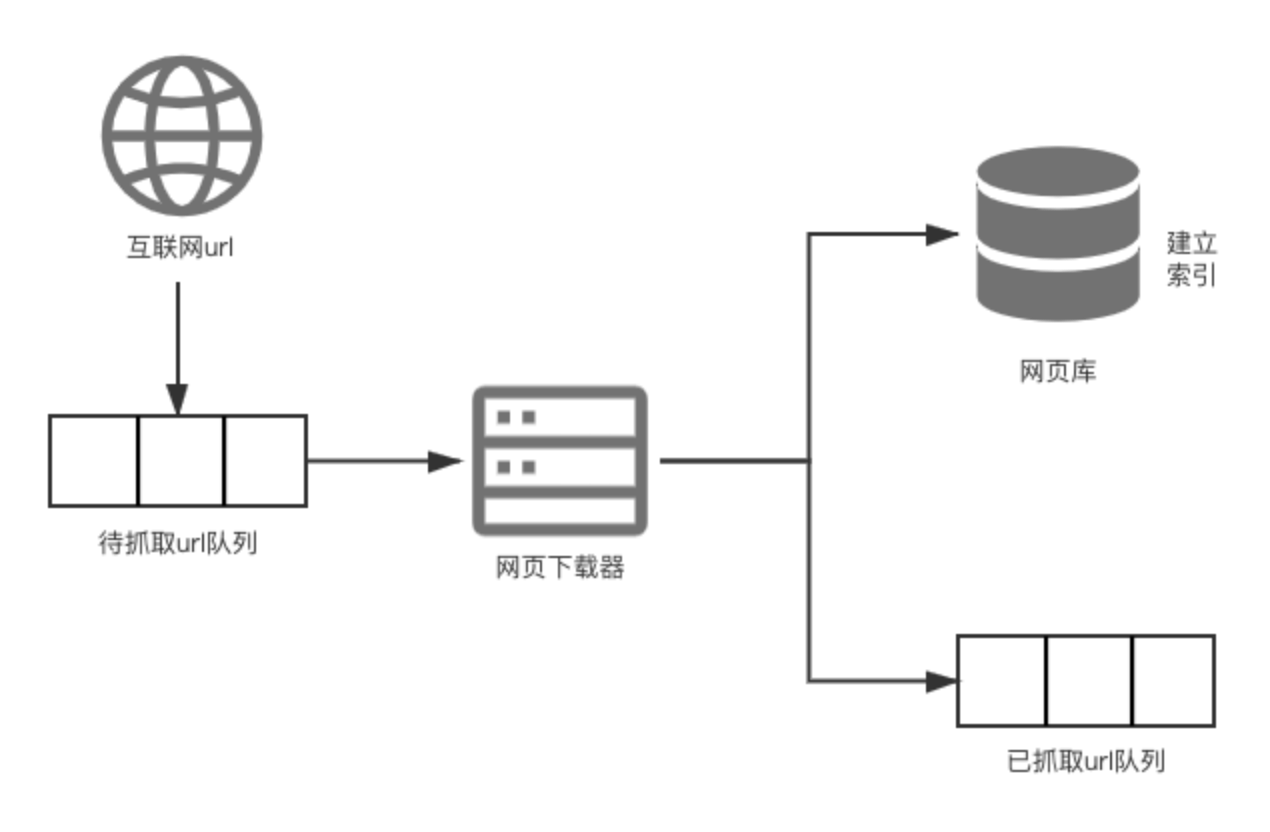
首先,从互联网不断的抓取很多url到我们的待爬取队列中,然后经过某些规则通过下载器来下载这些url,最后将爬取的页面放在网页库里等待建立索引,并且在已抓取的url队列里存放一份,以防止重复的抓取。
那么问题来了,这么多的url,我应该按什么样的规则去抓取呢?那么就有了接下来的这几种策略:
这几种策略的核心就是:优先抓取重要的网页。
广度、深度优先遍历
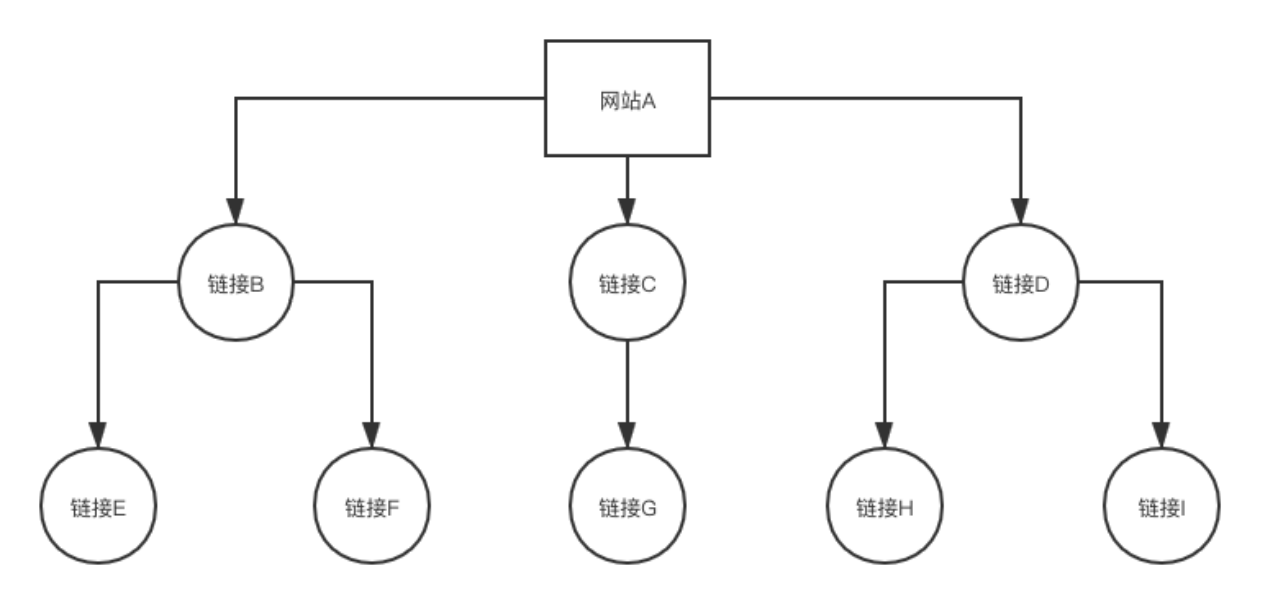
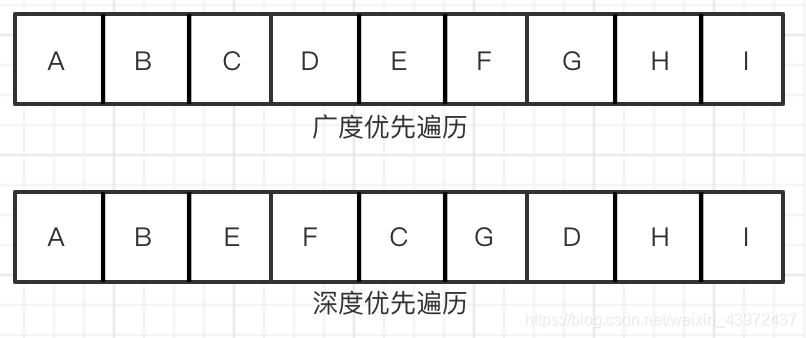
广度优先遍历:
将下载网页所包含的链接直接追加到待抓取URL末尾。
深度优先遍历:
把整个子链接走完再走下一个子链接,直到抓取完成。
缺点:
- 无目的
- 不管网页重要性排名
- 造成质量高的网站可能被滞后下载。
非完全PageRank算法
pageRank算法:
pageRank是著名的网页重要性分析算法。
Google创始人拉里·佩奇和谢尔盖·布林于1997年构建早期的搜索系统原型时提出的链接分析算法。
重点 pageRank主要参考:
入链数量:有多少个链接跳到该页面
入链质量:这些链接的质量好坏(PR值)
综合评估得分PR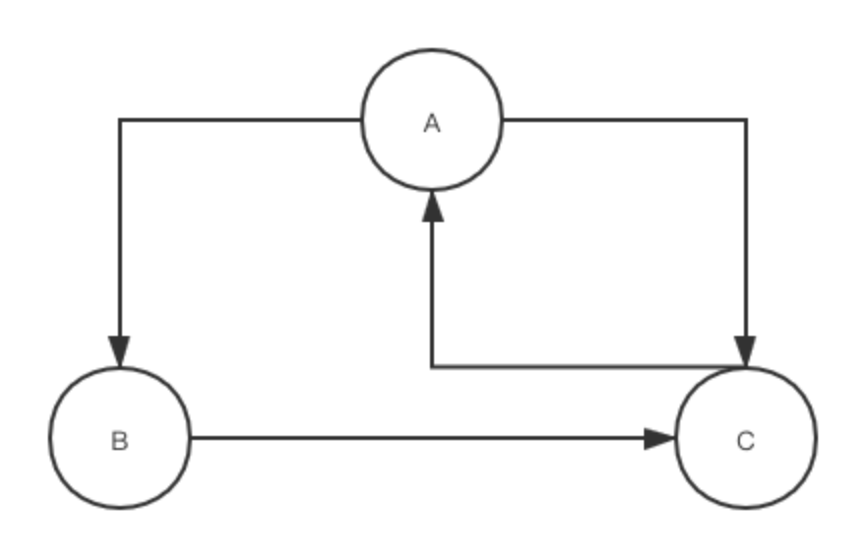
非完全pageRank:
因为计算pagerank需要确定每个链接的入链和出链,所以无法在抓取过程中计算的pagerank。
因此对已经下载了的网页,加上待抓取的URL列表里的网页一起,形成一个汇总。在这个汇总内进行pagerank的计算。
最终得到PR值,高的值代表越重要优先抓取。
OPIC策略
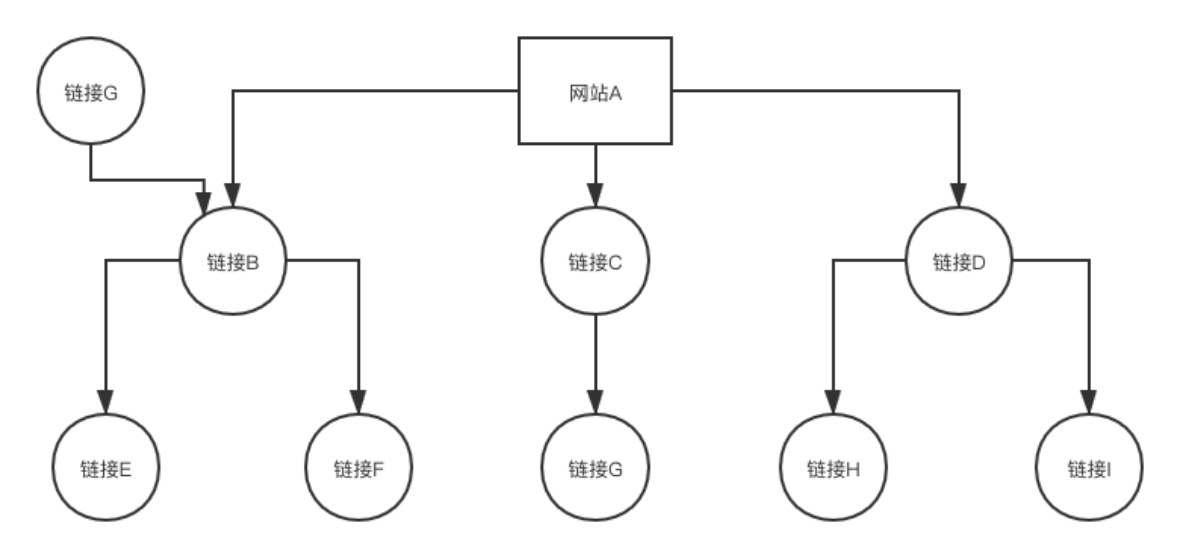
OPIC是online page importance computation的缩写,意思是“在线页面重要性计算”,这个是pagerank的升级版本。
1、所有的URL都赋予一个初始的分值
2、每当下载一个网页就把这个网页的分值平均分摊给这个页面内的所有链接。
3、清空这个页面的分值。
4、对于待抓取的URL列表里,则根据谁的分值最高就优先抓取谁。
优点:实时计算
大站优先策略
爬虫会根据待抓取列表中的URL进行归类,然后判断域名对应的网站级别。例如权重越高的网站所属域名越应该优先抓取。
具体怎么判断是大站的方式,未到资料说明。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)