
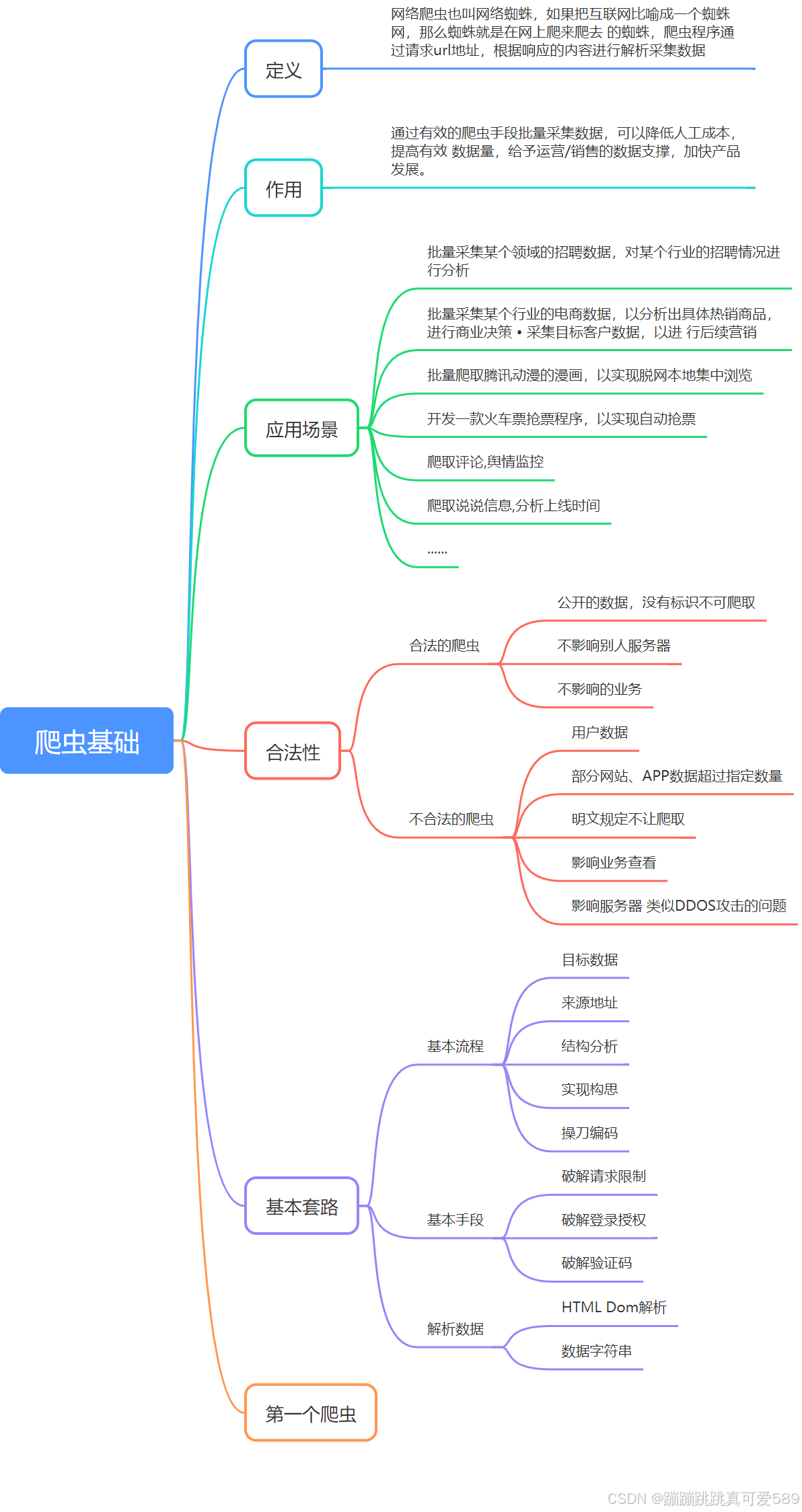
Python----爬虫基础
网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘 蛛就是在网上爬来爬去 的蜘蛛,爬虫程序通过请求url地址,根据响 应的内容进行解析采集数据。
一、爬虫的定义

网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘 蛛就是在网上爬来爬去 的蜘蛛,爬虫程序通过请求url地址,根据响 应的内容进行解析采集数据
二、爬虫的作用
通过有效的爬虫手段批量采集数据,可以降低人工成本,提高有效 数据量,给予运营/销售的数据支撑,加快产品发展。

三、应用场景
-
搜索引擎: 爬虫会扫描网络以索引新的网页,以便用户可以在搜索引擎(如Google、Bing)中快速找到相关内容。
-
数据分析: 企业使用爬虫工具自动从竞争对手的网站上收集数据,以进行市场分析和竞争情报。
-
价格监控: 在线零售商利用爬虫监控其竞争对手的价格变化,以调整自己的定价策略。
-
内容聚合: 新闻网站和门户网站会使用爬虫从多个来源抓取信息,并将其整理在一个平台上,提供多样化的新闻内容。
-
学术研究: 学者和研究人员利用爬虫收集大量研究数据或科学文献,进行数据挖掘和分析。
四、合法性

4.1、合法的爬虫
公开的数据,没有标识不可爬取
不影响别人服务器
不影响的业务
4.2、不合法的爬虫
用户数据
部分网站、APP数据超过指定数量
明文规定不让爬取:在域名后加上 /robots.txt 页面上标明
影响业务查看
影响服务器 类似DDOS攻击的问题
五、爬虫的基本套路
5.1、基本流程
目标数据:想要什么数据
来源地址
结构分析:具体数据在哪(网站、还是APP) 如何展示的数据
实现构思
操刀编码
5.2、基本手段
破解请求限制:
请求头设置,如:useragant为有效客户端
控制请求频率(根据实际情景)
IP代理
签名/加密参数从html/cookie/js分析
破解登录授权:请求带上用户cookie信息
破解验证码:简单的验证码可以使用识图读验证码第三方库
5.3、解析数据
HTML Dom解析:
正则匹配,通过的正则表达式来匹配想要爬取的数据,如:有些数据不是在html 标签 里,而是在html的script 标签的js变量中
使用第三方库解析html dom,比较喜欢类jquery的库
数据字符串:
正则匹配(根据情景使用)
转 JSON/XML 对象进行解析
六、第一个爬虫
6.1、爬虫的开发工具
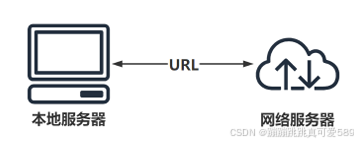
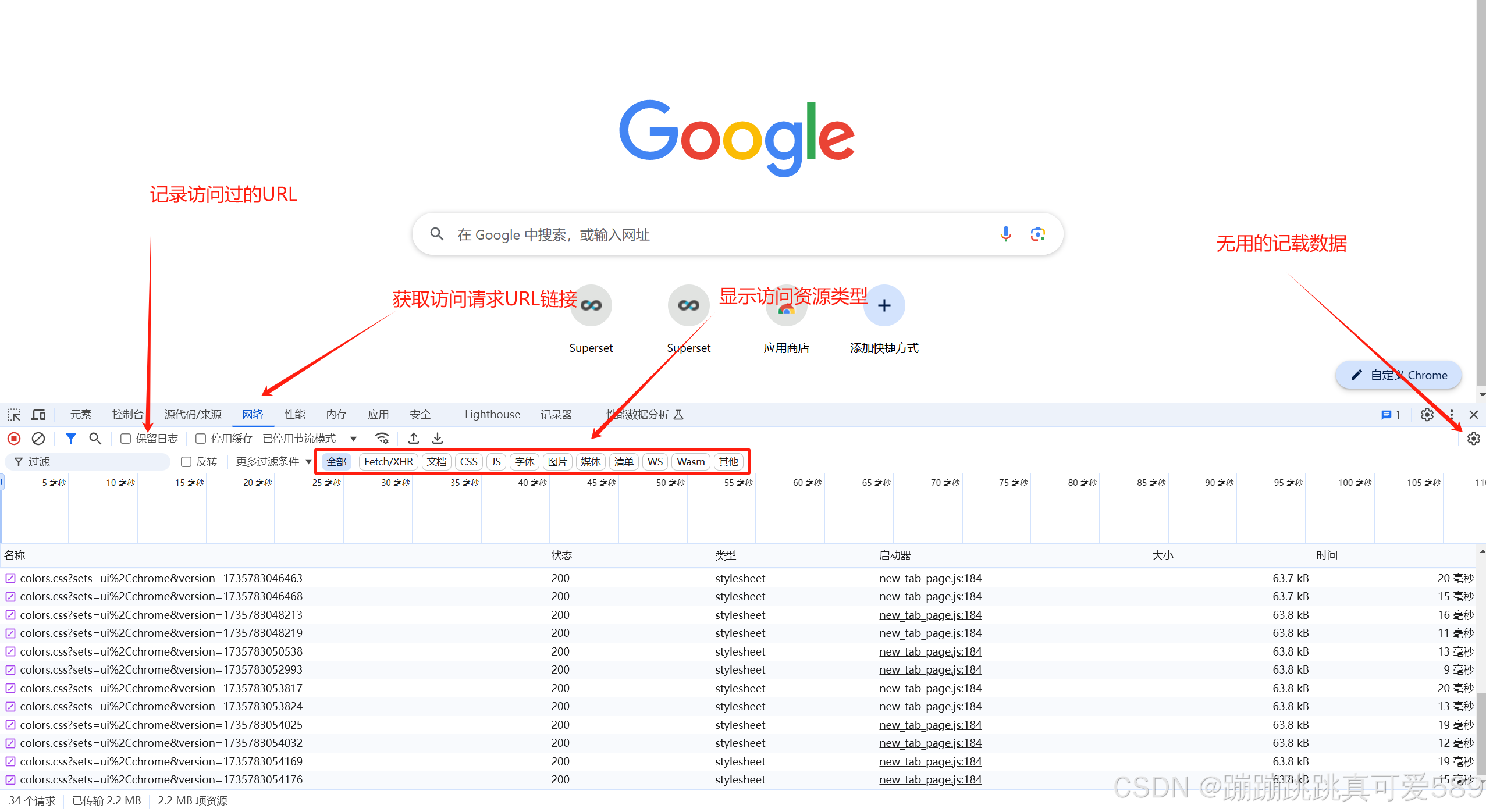
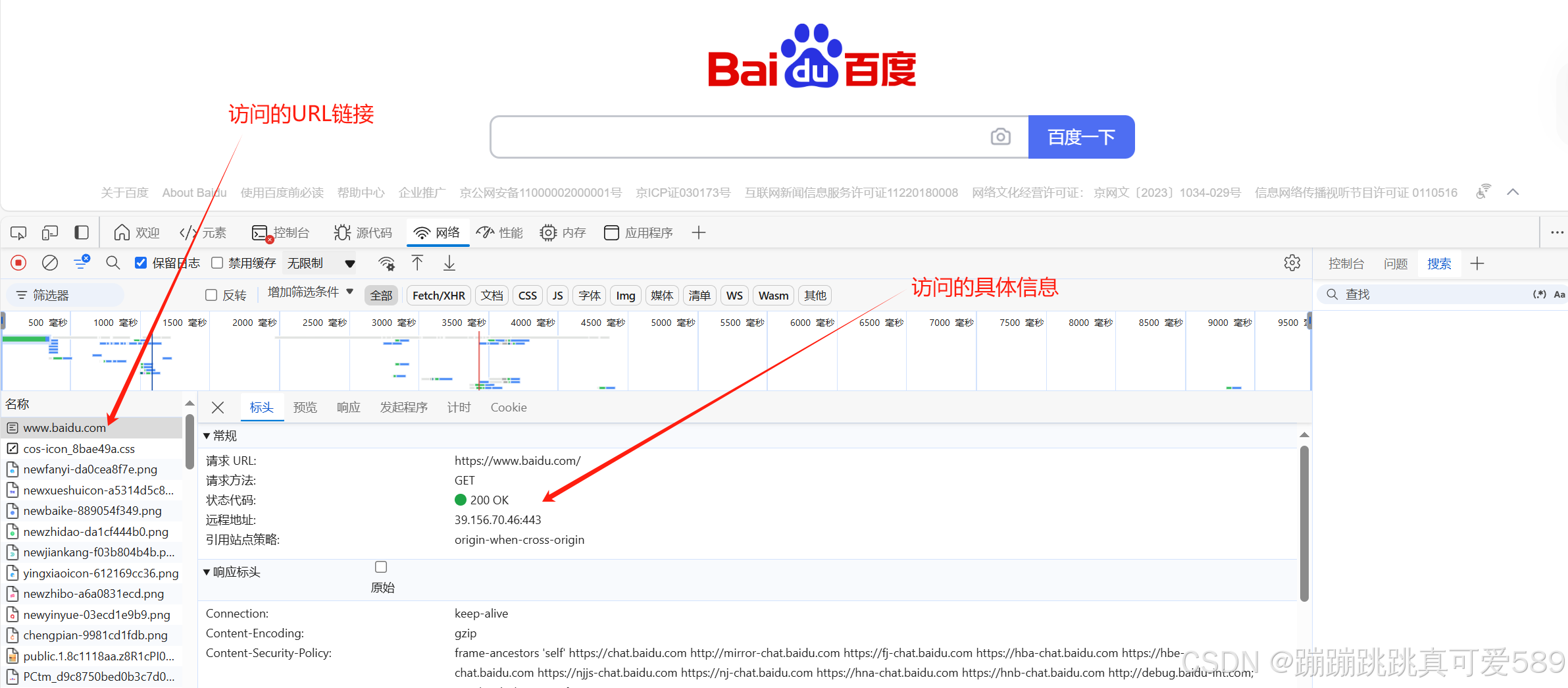
对于爬虫来说,最核心的就是发送请求,让网络服务器返回相应的 数据。而最为核心之一就是找到URL,这时就需要一个可以帮助我 们分析URL的工具,浏览器开发者工具
6.2、第一个爬虫
其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到 的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的, 实质它是一段HTML代码,加 JS、CSS。如果把网页比作一个人,那 么HTML便是他的骨架,JS便是他的肌肉,CSS便是它的衣服。所以 最重要的部分是存在于HTML
from urllib.request import urlopen
# 请求的地址
url = 'http://www.baidu.com/'
# 发送请求
resp = urlopen(url)
# 打印响应结果
print(resp.read().decode())
# 获取响应码
print(resp.getcode())
# 获取访问的url
print(resp.geturl())
# 获取响应头信息
print(resp.info())七、思维导图

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 15
15 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)