
期货量化软件:神经网络变得轻松(第三十七部分):分散关注度
在上一篇文章中,我们讨论了在其架构中使用关注度机制的关系模型。我们用此模型创建了一个智能系统,成果 EA 展现出良好的结果。然而,我们注意到,与我们前的实验相比,该模型的学习率较低。这是因为模型中所用的变换器模块是一个相当复杂的架构解决方案,需执行大量操作。随着分析序列大小的增加,这些操作的数量以二次级数飙涨,导致内存消耗和模型训练时间增加。不过,我们认识到能用于改进模型的资源有限。故此,需要牺牲
概述
在上一篇文章中,我们赫兹量化讨论了在其架构中使用关注度机制的关系模型。 我们用此模型创建了一个智能系统,成果 EA 展现出良好的结果。 然而,我们注意到,与我们前的实验相比,该模型的学习率较低。 这是因为模型中所用的变换器模块是一个相当复杂的架构解决方案,需执行大量操作。 随着分析序列大小的增加,这些操作的数量以二次级数飙涨,导致内存消耗和模型训练时间增加。
不过,我们赫兹量化认识到能用于改进模型的资源有限。 故此,需要牺牲最小的品质来优化模型。
1. 分散关注度
当我们赫兹量化谈论优化模型的性能时,我们首先需要注意它的超参数。 考虑到资源消耗和模型品质,此类参数集应该是最优的。 在某个阈值后增加层中的神经元数量,实际上不会导致模型品质的提升。 神经层的数量也是如此。 不过,最优超参数集取决于特定任务及其复杂度。
所有这些都适用于多观察者自我关注度模块中的关注者数量。 有时两名关注者就足以获得良好的结果,但这并不是所有问题的最优值。 所有超参数,必须依据每个特定任务和模型架构经实验筛选。
本文讨论的体系结构方式,出于减少自我关注度模块中操作数量。 不过,在迈入优化算法之前,重要的是要记住自我关注度模块的工作原理。
首先,它计算三个实体:序列中每个元素的查询(Query)、键(Key)和值(Value)。 为此目的,描述序列元素的向量乘以相应的权重矩阵。 然后,我们将 Query 矩阵乘以转置的 Key 矩阵,得到序列元素之间的依赖系数。 然后使用 SoftMax 函数对这些系数进行常规化。
![]()
添加图片注释,不超过 140 字(可选)
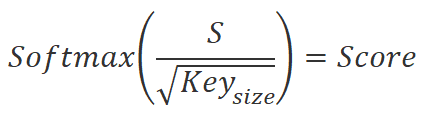
添加图片注释,不超过 140 字(可选)
依赖系数常规化之后,我们将它们乘以 Value 实体矩阵,从而得到序列中每个元素的输出值。 这些输出值是元素值的加权总和,并考虑了每个元素在问题上下文中的重要性。
![]()
添加图片注释,不超过 140 字(可选)
序列元素数量的增加导致使用关注度机制的算法中计算操作复杂性增加。 这是因为在每个阶段,需针对序列的每个元素执行实体计算、矩阵乘法和依赖系数常规化的操作。
如果序列包含的元素太多,这可能会导致计算时间和计算资源成本激增。 为了优化算法,并减少每个阶段的计算次数,我们可以运用各种方法,其一是分散关注度。 该方法由 Rewon Child 在 2019 年 4 月发表的文章《使用分散变换器生成长序列》中提出。
分散关注度是一种优化关注度机制,从而减少处理序列元素所需的计算量的技术。
该方法的思路是在计算序列元素之间的关注度系数时,仅参考序列中最重要的元素。 因此,取代计算序列中所有元素对的关注度系数,我们只需选择最重要的元素对。
分散关注度方法的优点之一,是它可以明显减少处理序列元素所需的计算量。 这在处理计算量非常庞大的大型序列时尤其重要。
此外,分散关注度可有助于解决“关注一切”问题,当关注度机制将注意力均匀地分配给序列的所有元素时,这会导致资源的低效利用,并减慢算法的速度。
实现分散关注度时可以采用多种方式。 一种是将序列分解为区块,并仅计算每个区块内的元素之间、以及不同区块的元素之间的关注度。 在这种情况下,只需考虑距离最近的元素,从而减少计算次数。
另一种方式是根据元素的相似性,选择序列中最重要的元素。 这可以通过运用不同的聚类分析方法来完成。
第三种方式则是运用一些启发式和算法来选择序列中最重要的元素,例如基于它们的频率、重要性或上下文。
作者指出,为了令分散关注度有效地工作,有必要采用一种将序列元素分布到区块中的算法,该算法为每位关注者提供不同的区块结构。 这种方式将令您能够更全面地判定序列中每个元素的影响度,并提高算法的效率。
分散关注度可应用于机器学习和自然语言处理的各个领域,包括机器翻译、文本生成、情感分析、及更多。 在上面提及的文章中,该方法的作者介绍了文本、图像和录音的算法应用结果。
此外,稀分散关注度可以与其它关注度引擎优化技术有效结合,在处理序列时获得更准确的结果。
尽管它有效,但分散关注度方法也有其缺点。 其一是序列中最重要的元素的选择可能不正确,这可能导致信息丢失。 因此,有必要为每个特定任务选择相应的的方法,并仔细调整算法参数。
我相信分散关注度方法对于解决金融市场分析相关的问题很实用。 在分析金融品种报价的历史时,我们通常需要在可参考深度分析数据,但往往只有历史当中的单个元素会影响当前情况。 在选择重要数据区块进行研究时,使用分散关注度方法将减少计算资源量。 该方法还有助于剔除未来操作中无关紧要的因素,从而提高金融市场分析的效率。
然而,金融市场报价具有可变结构,因此我们无法在分析序列中操控固定的元素区块。 为了加快模型学习过程,我们可以采用启发式 “80/20” 帕累托(Pareto)规则,其中我们仅从整个序列中获取 20% 最重要元素。 元素的重要性是根据元素之间的依赖系数判定的,这些系数由前面讲述的两个公式计算。 在第一次迭代之后,在数据常规化之前,可以准确地识别序列中最重要的元素,然后从进一步的操作中排除其余的元素。 这减少了常规化阶段的操作次数,并确定了自我关注度模块的结果。
由于每个关注者都用自己唯一的矩阵来判定查询和键,因此每个关注者所选取的元素可能会有所不同。
现在我们已经确定了优化算法的主要方向,我们可以迈入以 MQL5 语言实现该算法。
2. 利用 MQL5 实现
为了实现所提出的方法,我们将创建一个新的神经层类 CNeuronMLMHSparseAttention。 当然,我们不会重新创建所有类方法。 取而代之,我们将继承现有的 CNeuronMLMHAttentionOCL 类。 在此,我们分析一下需要修改哪些类方法和 OpenCL 程序内核,以便实现提议的优化。
如前所述,我们对算法的第一处修改涉及判定依赖系数的模块。 这些值是在 MHAttentionScore 内核中直接验算期间获得的。 对于我们的实现,我们将用 MHSparseAttentionScore 替换指定的内核。
在父类的内核参数中,我们将指针传递给 2 个数据缓冲区:Query、Key 和 Value 实体的级联张量作为源数据,以及保存以依赖系数形式的操作结果的缓冲区。 除了数据缓冲区之外,内部实体的维度也要传递给内核。 现在我们将添加分散系数 “sparse”。 我们将传递一个从 0 到 1 范围内的值,它指示对分析元素影响最大的选定序列元素的比例。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)