
揭秘大数据 | 24、资源管理、高可用与自动化
比资源管理更贴近最终用户的是一系列的服务,正如软件定义数据中心分层模型(见图3-25)所示,这些服务可以是普通的邮件服务、文件服务、数据库服务,也可以是针对大数据分析的Hadoop集群等服务。业界通常将5个9以上的系统称为零死机时间系统——颇具讽刺意味的是,某公有云厂商动辄鼓吹自己的系统和服务达到11个9的可用性,但是一根光纤断了、一个服务接口的故障就可以导致整个机房下线数天。最常见的高可用集群是
今天是这个小系列的完结篇,还是老配方,将前5篇一 一列出,方便大家通读。
当服务器、存储和网络已经被抽象成虚拟机(含容器)、虚拟存储对象(块设备、文件系统、对象存储)、虚拟网络时,这些虚拟化资源从数量和表现形式上都与硬件有了明显的区别。
这个时候,数据中心至多可以被称为“软件抽象”的数据中心,但还不是软件定义的数据中。因为各种资源现在还无法建立起有效的联系,要统一管理虚拟化之后的资源,不仅仅是将状态信息汇总、显示在同一个界面,更需要能够进一步用一套统一的接口集中管理这些资源。例如VMware公司的vCenter和vCloud Director系列产品或Amazon AWS的Management Console能够让用户对其数据中心或云计算基础架构中的计算、存储、网络等资源进行集中管理,并能提供访问权限控制、数据备份、高可靠性等额外功能的支持。
软件定义数据中心中所有资源作为一个整体,根据用户的服务请求来提供可靠、安全、灵活、弹性以及自助控制(自动化)的管理。下表中列出了软件定义数据中心资源管理评价指标与实现策略。
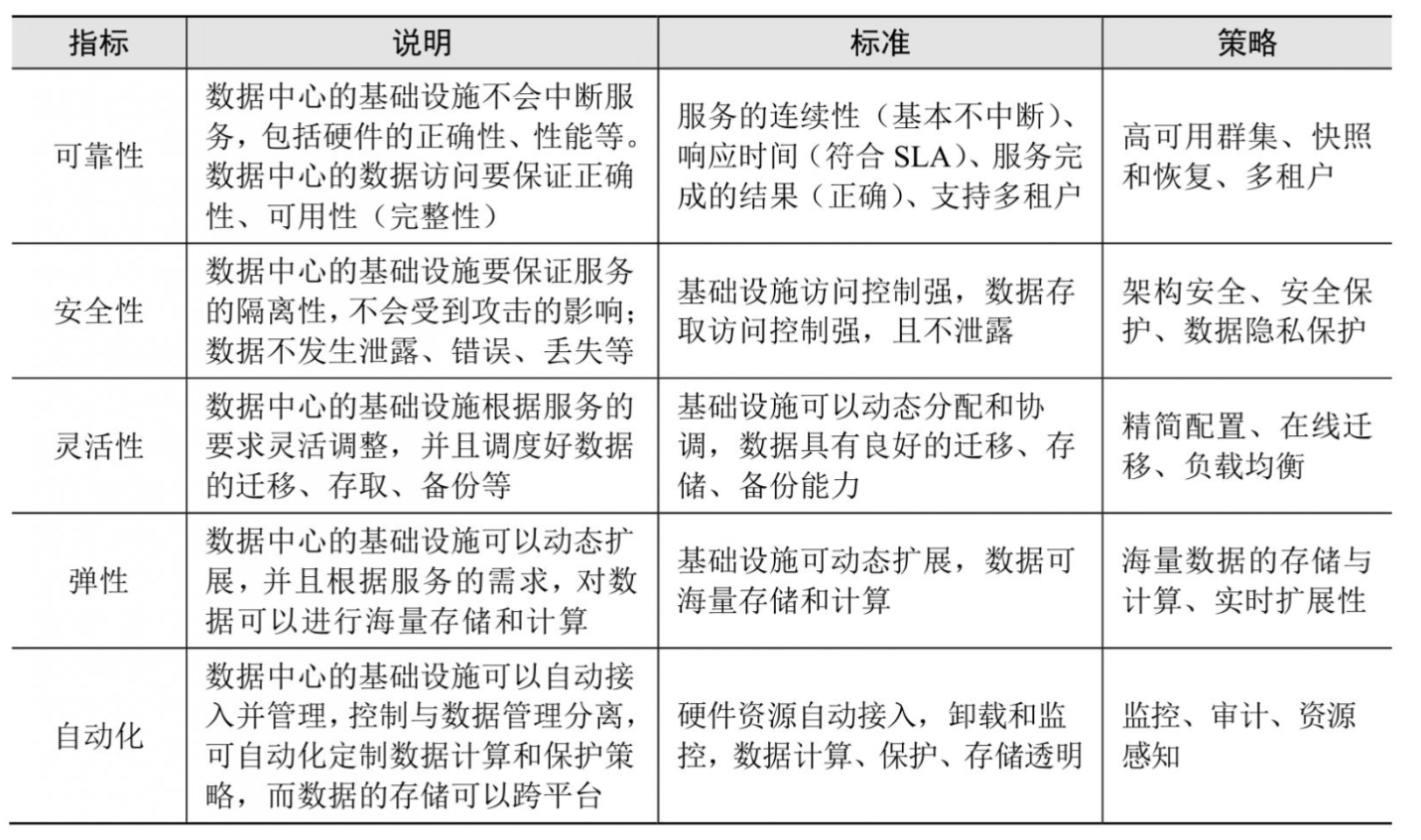
在这里,简要论述一下上表中列出的部分资源管理策略。
(1) 资源感知。当某个物理设备接入软件定义数据中心时,它需要被数据中心感知,资源感知采用的是物理资源服务器与设备驱动交互的方式。
某个物理资源的加载或者卸载分为以下几步:
① 设备驱动将指令、设备信息以及策略信息通过高速消息总线传给资源服务器;
② 资源服务器检查指令(加载/卸载),并将设备信息以及策略信息添加或删除;
③ 资源服务器定期轮询设备的资源使用情况,并提供API供上层对自己进行调用。
(2) 监控。监控包括资源监控、安全监控、性能监控及数据监控。资源监控是指对所管理的硬件资源进行监控,其中包括计算、网络、存储等。
监控的内容几乎包含了服务所关心的重要流程:
消息管理、访问管理、分配管理、用户管理、业务管理、故障管理等。不同的软件定义数据中心所采用的方法和模块工具不尽相同,以OpenStack为例,资源管理监控模块为Horizon。Horizon是一个基于Web接口的监控模块,它连接了计算管理模块Nova、存储管理模块Cinder、网络模块Quantum,以及访问控制模块KeyStone,提供了API供用户监控资源时使用。这样客户可以基于这些API对资源进行监控。
(3) 审计。审计是在资源监控的基础上,对资源和数据的使用状况及其状态进行汇总和记录,并产生报表,以供用户日后进行故障排除,以及动态性能调整时使用。常见的审计对象为数据信息和数据中心架构。
数据信息的审计方法有:
① 数据的有效性,数据产生的类型和质量及其产生的数据流依赖关系;
② 数据风险,根据数据管理的函数或结构类型,对数据的操作进行分析;
③ 数据访问及重用,对数据访问进行记录,并分析可重用数据。
数据中心架构的审计方法有:
① 系统日志,记录系统运行日志;
② 环境配置,记录环境配置信息;
③ 访问控制,对用户登录和资源的使用进行访问控制。
(4)高可用集群。高可用集群的主要目标是防止服务器设备出现故障(如网络、存储连接断开),在数据中心里增加一个备用节点,当主用节点突然出现故障,可使用备用节点保证数据服务的连续性。在正常服务处理客户请求时,仅有一台服务器处于激活状态。
高可用集群的实现方法可以不同,例如,根据存储设备共享方式的不同,可以分为以下3种:
① 使用镜像存储的集群。在集群中创建镜像存储,每个节点不仅在其对应的存储上执行写操作,还在其他节点的镜像存储上执行写操作。
② 不共享的集群,在任意时刻,仅有一个节点拥有存储。当前节点出现故障时,另一个节点开始使用存储,典型的例子包括IBM HACMP(High AvailabilityCluster Multiprocessing,高可用集群多处理)以及微软集群服务器(Microsoft Cluster Server,MSCS)。
③ 共享存储。所有的节点访问相同的存储,建立锁机制来保护竞争条件以防止数据损坏,典型的例子包括IBM Mainframe Sysplex Techology和Oracle RealApplication Cluster。
(5)快照和恢复。软件定义数据中心利用虚拟化的资源提供服务,而快照信息可以帮助记录节点的状态。当节点发生故障时,工作人员可以利用先前保存的快照,选择回退点来恢复到之前的正确状态。保存快照的对象既可以是计算节点,也可以是网络设备或存储节点。由于在软件定义数据中心所有的对象都是虚拟对象,因此大部分的对象快照可以是虚拟机快照(计算虚拟机、存储虚拟机、网络设备虚拟机)。软件定义数据中心可以设定快照的间隔时间,连续保存快照,以当发生错误时,选择合适的快照进行恢复。常见的虚拟机平台Xen、KVM、VMware都有快照功能。而选择合适的回退点是一个较难的问题,选择的回退点不能离故障点太远,又要能保证恢复后状态正确。
(6)安全保护与数据隐私保护。计算节点的安全保护包括系统安全和软件安全,进一步又分为漏洞攻击防御和恶意代码阻止;网络安全包括网络协议安全性,如安全套接字层(Secure Socket Layer,SSL)密钥保护、网络包重放攻击防御、拒绝服务攻击防御等。在软件定义网络中,控制节点定义的规则及策略的完整性保护是一个新问题;存储安全包括存储系统的安全、连接安全以及数据安全。在软件定义数据中心中,用户的数据都被存储在云端,如何保证用户数据的隐私也是一个重要问题。越来越多的厂商开始关注这个问题,然而目前还没有一个全面的解决办法,已有的方法包括数字水印、数据模糊(加噪声)、数据加密等。
(7)负载均衡。目前常见的负载均衡策略有3种:
① 循环轮替域名系统(Domain Name System,DNS),令同一个域名对应不同的IP,在客户端实现IP轮换,当访问某个DNS时,选择排在第一位的IP进行访问;
② 软件负载平衡,如Apache/Nginx、Linux虚拟服务器(Linux Virtual Server,LVS)等;
③ 弹性负载平衡,其特点是可实现跨区域的负载平衡(例如,美国的东西海岸、中国的北方/南方)。
(8)精简配置。精简配置主要用于软件定义数据中心的存储资源分配,利用虚拟化、容器等技术,对用户服务所需要的存储物理资源进行分配,提供刚好满足用户服务所需的存储资源,而实际分配的资源等于用户服务实际使用的资源。
例如提供给用户服务150GB的存储,而用户当前实际使用了10GB,那么精简配置会按用户实际的使用情况来真实地分配资源。精简配置的优势是按需动态分配资源,可以最大化利用存储资源。特别是当软件定义数据中心集中管理存储资源时,精简配置可以帮助管理者有效管理有限的资源且提供良好的资源扩展性。目前一些虚拟化平台(如VMware公司的vsphere)已经提供了相关的技术实现。
(9)在线迁移。在线迁移主要用于软件定义数据中心的计算资源和存储资源。在线迁移的对象包括虚拟机和存储的数据,一般出于性能或安全性考虑,例如负载均衡、灾备等。在线迁移已经被一些常见的虚拟化平台使用,包括VMware公司的vMotion、KVM公司的Live Migration。
在线迁移有两种技术:前复制和后复制。
前复制技术的原理是将虚拟机或者数据当前的快照全部从源端复制到目的端,再利用写时拷贝(Copy-On-Write,COW)技术将更新的数据复制到目的端。后复制技术的原理是将虚拟机或者数据主要部分(保证服务正常运行)先从源端复制到目的端,在目的端使用数据时,向源端索要未传递的数据。前复制的优势是速度较快,但在一开始快照传输时对服务暂停操作时间较长;而后复制的优势是一开始主要数据传输对服务暂停操作时间较短,但整体速度较慢,因为后续使用数据时要向源端索要缺失的数据。
比资源管理更贴近最终用户的是一系列的服务,正如软件定义数据中心分层模型(见图3-25)所示,这些服务可以是普通的邮件服务、文件服务、数据库服务,也可以是针对大数据分析的Hadoop集群等服务。对于配置这些服务来说,软件定义数据中心的独特优势是自动化。例如VMware公司的vCAC(vCloudAutomation Center)就可以按照管理员预先设定的步骤,自动部署任何传统服务,如从数据库到文件服务器。绝大多数的部署细节是预先定义的,管理员只需要调整几个参数就能完成配置。即使有个别特殊服务,例如用户自己开发的服务,管理员没有事先定义的部署流程,也可以通过图形化的工具编辑工作流程,并且在以后反复使用。
从底层硬件到提供服务给用户,资源经过了分割(虚拟化)、重组(资源池)、再分配(服务)的过程,看似增加了许多额外的层次,但从这个角度看,软件定义不是免费的,但层次化的设计有利于各种技术并行发展和协同工作,这与网络协议的发展非常类似。
TCP/IP协议簇正是因为清晰地定义了各协议层次的职责和互相的接口,才能够使参与的各方协同发展。研究以太网的专家可以关注提高传输速度和链路状态的维护,研究IP层的专家则可以只关心与IP路由相关的问题,让专家去解决各自领域内的专业问题,这无疑是效率最高的。
软件定义数据中心的每一个层次涉及许多关键技术。有些技术由来已久,但是被重新定义和发展,例如软件定义计算、统一的资源管理、安全计算和高可靠等;有些技术则是全新的,并仍在迅速发展,例如软件定义存储、软件定义网络、自动化的流程控制。这些技术是软件定义数据中心赖以运转的关键,也是软件定义数据中心的核心优势。
高可用性指的是一个系统在约定的时间段内能够为用户提供的服务满足或超过约定的服务级别,如访问接入、任务调度、任务执行、结果反馈、状态查询等。而服务级别通常表述为系统不可用的时间低于某个阈值。如果任何一个关键环节出错或停止响应,则称目前系统状态为不可用。人们通常将系统处于不可用状态的时间称为停机时间(死机时间)。
可用性的量化衡量:可用性通常表述为系统可用时间占衡量时间段的百分比,通常可以采用一年或一个月作为衡量时间段,具体选择取决于服务合约、计量收费等实际需求。下表中给出了不同的可用性指标。由下表可见,宣称达到11个9的系统每年的死机时间降低到0.3ms,殊为惊人。业界通常将5个9以上的系统称为零死机时间系统——颇具讽刺意味的是,某公有云厂商动辄鼓吹自己的系统和服务达到11个9的可用性,但是一根光纤断了、一个服务接口的故障就可以导致整个机房下线数天。不知道这种可用性是怎么计算出来的。
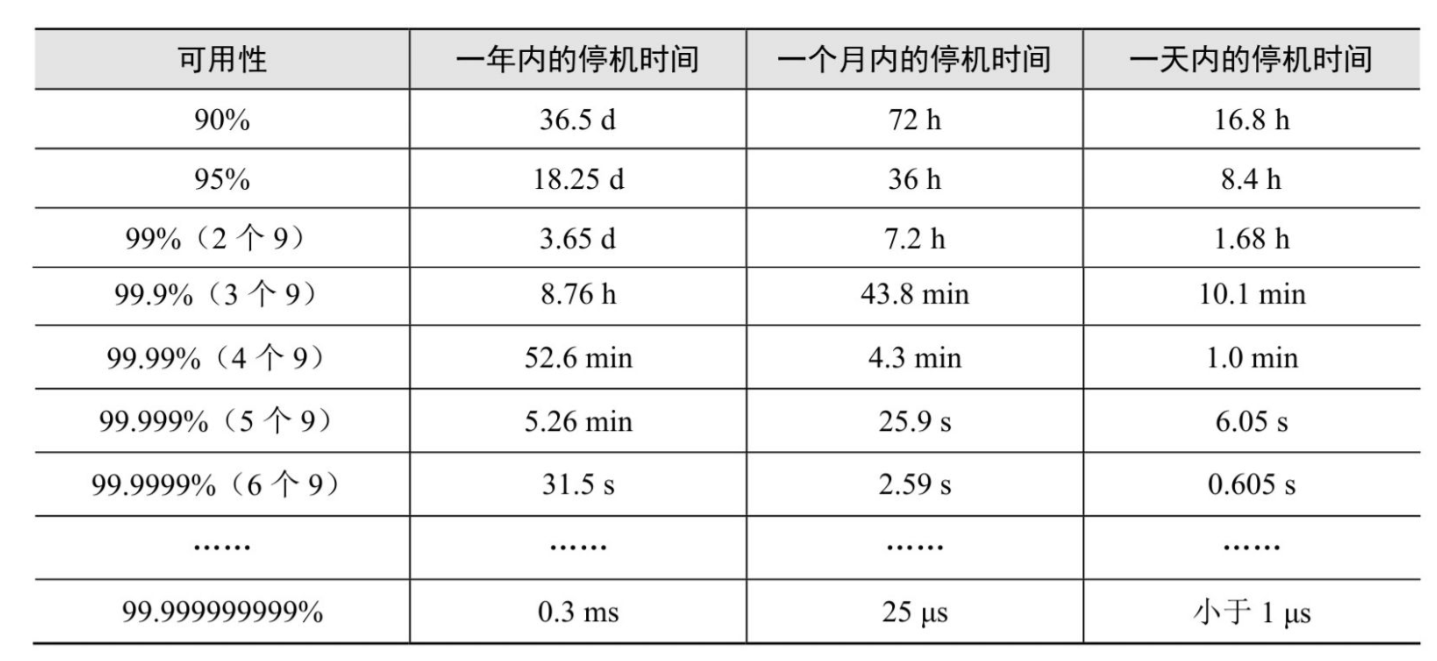
零死机时间系统设计意味着一个系统的平均失效间隔时间大大超过了系统的维护周期(死机时间)。在这样的系统中,平均失效间隔时间是通过合理的建模与模拟执行计算得到的。零死机时间系统通常需要大规模的组件冗余,在软件、硬件、工程领域屡见不鲜。例如,我们熟知的GPS通常使用5颗及以上数量的卫星来实现定位、时间与系统冗余,还有悬索桥的多根竖索就是典型的高冗余设计。
高可用系统通常致力于最小化两个指标:系统死机时间与数据丢失。高可用系统至少需要保证在单个节点失效/死机的情况下,能够保持足够短的死机时间和最少量的数据丢失;同时在下一个可能的单节点失效出现之前,利用热备节点修复集群,将系统恢复到高可用状态。
单点失效(单点瓶颈),即系统中任何一个独立的硬件或软件出现问题,会导致不可控的系统死机或者数据丢失。高可用系统一个关键的职责就是要避免出现单点失效。为此,系统中的所有组件要保证足够的冗余率,包括存储、网络、服务器、电源供应、应用程序等。在更复杂的情况下,系统可能会出现多点失效,即系统中出现超过两个节点同时失效(失效时间段重叠,且互相独立)。很多高可用系统在这种情况下无法幸存;当问题出现的时候,通常避免数据丢失具有更高的优先级,这是相对于系统死机时间而言的。
为了达到99%甚至更高的可用性,高可用系统需要一个快速的错误检测机制,以及保证相对很短的恢复时间。当然尽量长的平均失效间隔时间对保证高可用性来说也是至关重要的。简言之,尽量减少出错的次数,出错后快速检测,检测到后尽快修复。
最常见的高可用集群是两节点的集群,包括主节点与冗余节点各一个,也就是100%的冗余率,这也是集群构建的最小规模。主节点与冗余节点可以采用单活机制,也可以采用双活机制,具体取决于应用程序的特性与性能需求。也有其他很多的集群采用了多节点的设计,有时规模达到几十甚至上百个节点;多节点的集群设计起来相对复杂。常见的高可用集群配置大致有以下几种。
(1) 单活:冗余节点平时处于备用状态,并不对外提供服务。一旦主节点发生故障,冗余节点在最短的时间内上线并接管余下的任务。这种配置需要较高的设备冗余率,通常见于两节点集群。常见的备用方式有热备和冷备两种。以Hadoop系统的NameNode为例,它采用的就是典型的单活策略——两个NameNode,主节点处于活跃状态,备用节点处于热备状态。
(2) 双活或多活:负载被复制或分发到所有的节点上;所有的节点都是活跃节点(或主节点)。对于完全复制的模式来说需要的节点相对较少,当运行结果出现不一致时,可以采用多数投票生出原则。任何一个节点的失效都不会引起性能下降。此种模式也兼顾了负载均衡的考虑,当某个节点失效时,任务会被重新分配到其他活跃节点上。节点失效可能会带来一定的系统性能损失,具体比例则取决于死机节点的数量,但不会引起全部节点死机。以存储系统为例,EMC公司的VPLEX与NetApp MetroCluster都实现的是双活或多活高可用性。VPLEX甚至支持3种不同模式:数据中心内的跨存储设备、跨数据中心同步以及跨数据中心异步的双活/多活、高可用与数据移动。
(3)单节点冗余(N+1):类似于单活机制,提供一个处于备用状态的冗余节点。不同的是,主节点可能有多个;一旦某个主节点发生故障,冗余节点马上上线替换。这种模式多用于某些服务本来就需要多实例运行的用户系统。前面的单活模式实际上是这种模式的一种特例。
(4)多节点冗余(N+M):作为对单节点冗余机制的一种扩展,提供多个处于备用状态的冗余节点。这种模式适用于包含多种(多实例运行的)服务的用户系统。具体的冗余节点数取决于成本与系统可用性的权衡。
理论上还有其他一些设计模式,例如双活或多活与单/多节点冗余的结合,这种模式主要是基于冗余率与性能保障的双重考虑。然而正如前文提到过的,增加冗余组件以及采用更复杂的系统设计,对整体系统的可用性来说未必是个好消息,某些时候负面效应甚至是主导的,因此在设计高可靠性系统时,还是要多遵循简单性原则。
在软件定义的云计算中心中,计算、网络、存储的实现都演化为面向服务(一切即服务)的模型。各个模块的集中控制器向外提供API,使模块具备了可编程能力,而且控制器使各个模块具备了中央控制的功能,让自动化的工作流能够集中部署、集中控制。
此外,随着各个模块控制器的控制接口向开放性、灵活性和标准化方向发展,自动化工作流也会朝着标准化方向发展,使工作流能够实现跨平台、跨厂商使用。以软件定义存储解决方案Ceph与ViPR/CoprHD为例,这两者都是以标准化的方式允许第三方存储系统接入,从而为用户提供一个统一的软件定义存储管理平台。
通过对数据中心的硬件、软件和流程协调与组合,数据中心建立自定义的工作流程,跨越多个模块帮助自动完成IT系统管理流程,提高IT运营水平。数据中心的自动化消除了绝大多数手工操作流程,帮助IT操作和IT服务管理队伍提供从设计到运行与维护的服务。数据中心的自动化运维如图3所示。
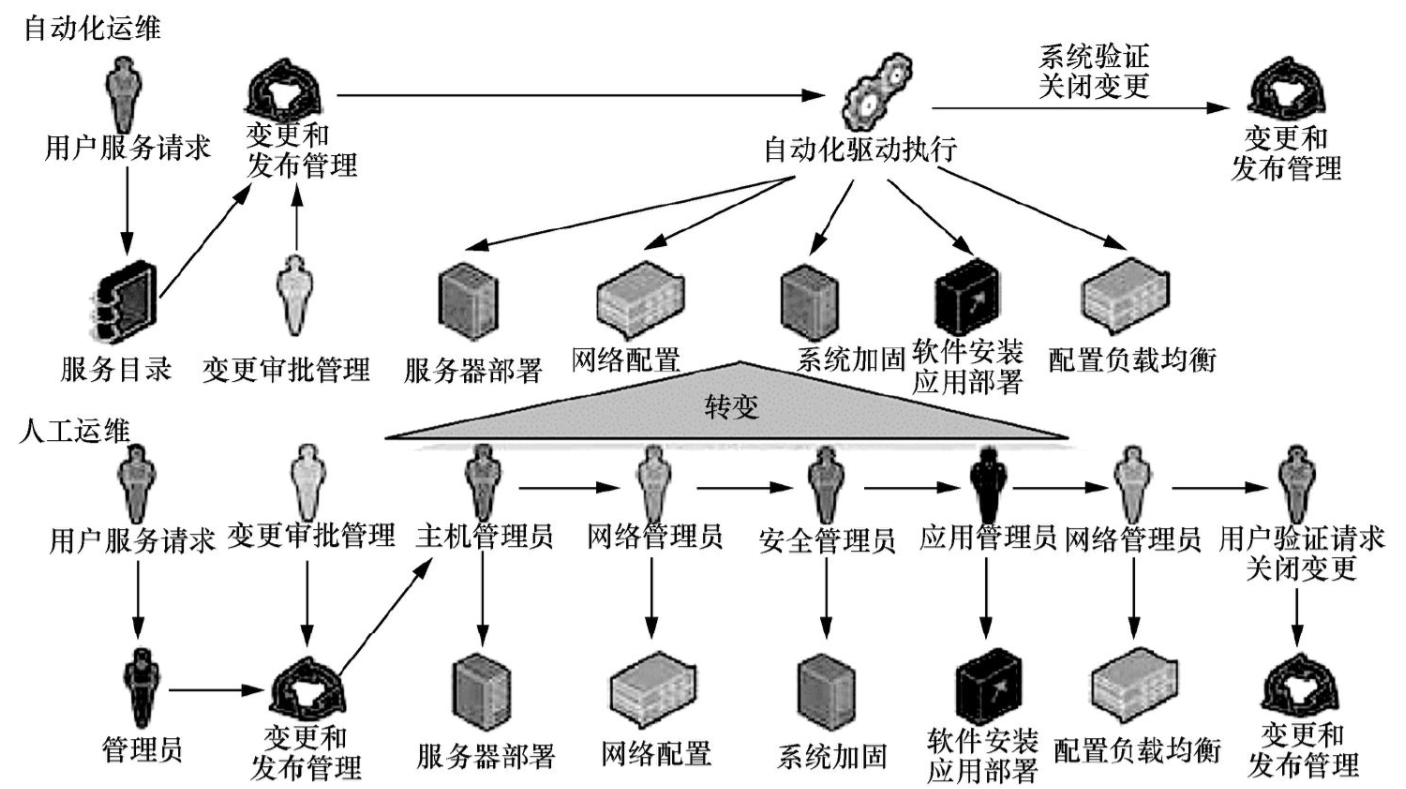
数据中心的自动化(工作流)可以实现跨多模块、多服务的部署和实施,在当前的数据中心中,可以对计算、网络、存储、安全、管理与编排等方面实施自动化。
(1) 软件安装:集中管理服务器操作系统和安装脚本,批量安装多种操作系统,包括Windows、Linux、Solaris、AIX、ESX等。可实现跨越操作系统的统一服务器管理,为物理、虚拟和公共云基础设施提供统一的支持,其中包括裸机安装、应用程序部署和系统配置的即开即用能力。借助软件打包和操作系统安装管理功能,IT团队能够实现服务部署任务标准化,并提高一致性,缩短供给周期。
(2) 补丁管理:集中管理服务器补丁,对当前的补丁列表进行分析,提供需安装的补丁建议,并批量下发补丁。
(3) 配置自动化:一般具有变更检测和配置合规检查的功能。用户可以创建配置基线,利用它对服务器进行比较。配置基线是管理员规定的适用于特定环境的正确配置与设置信息。一台服务器可以有多个配置基线。用户指定配置基线之后,可以利用这个配置基线来比较服务器之间的区别,并查看比较结果。比较结果将给出每台服务器所安装的组件以及两个服务器之间的区别。
(4) 系统配置与拓扑发现:在各种操作系统批量地、自动化地进行参数调整,例如,网络策略配置可自动地批量下发路由表和防火墙策略。数据中心自动化可实现自动发现和采集网络设备的配置,比如设备类型、设备型号、硬件信息、操作系统版本、Startup Config、Running Config、VLAN等,以及跟踪它们的变化。
(5) 操作审计:自动记录所有对网络设备执行的变更,并提供回退机制。
(6) 自动巡检:可自动收集各种软硬件信息并生成报表,包括服务器的制造商/型号、BIOS、板卡、存储、操作系统版本、软件列表、补丁列表、安全设置、网络设备的型号、模块、版本、启动配置、运行配置等。
(7) 虚拟机、容器操作:可以自动化虚拟机的创建、配置、删除、迁移等。
(8) 巡检和合规检查:可通过内置的合规性检查策略,针对全面内网安全(Comprehensive Intranet Security,CIS)、防御信息系统机构(Defense InformationSystem Agency,DISA)、非独立组网(NSA),对系统、设备等进行自动化的合规检查,并给出检查报告。同时用户也可以定义自己的合规策略。
通过数据中心自动化的技术,我们把管理物理基础架构与应用程序这些烦琐的工作以分层的方式封装到IaaS与PaaS系统中,从而能够专注于创新和为企业提供价值。
最后,老夫来总结一下云计算与大数据时代IT体系架构的主要趋势、主要特点及核心组件:
(1)主要趋势软件定义数据中心、基于服务的架构(SoA)。
(2)主要特点:
①自动化(流程与资源管理)
②高可用性
③弹性+敏捷性
④精细化管理(监控、计费、多租户支持等)
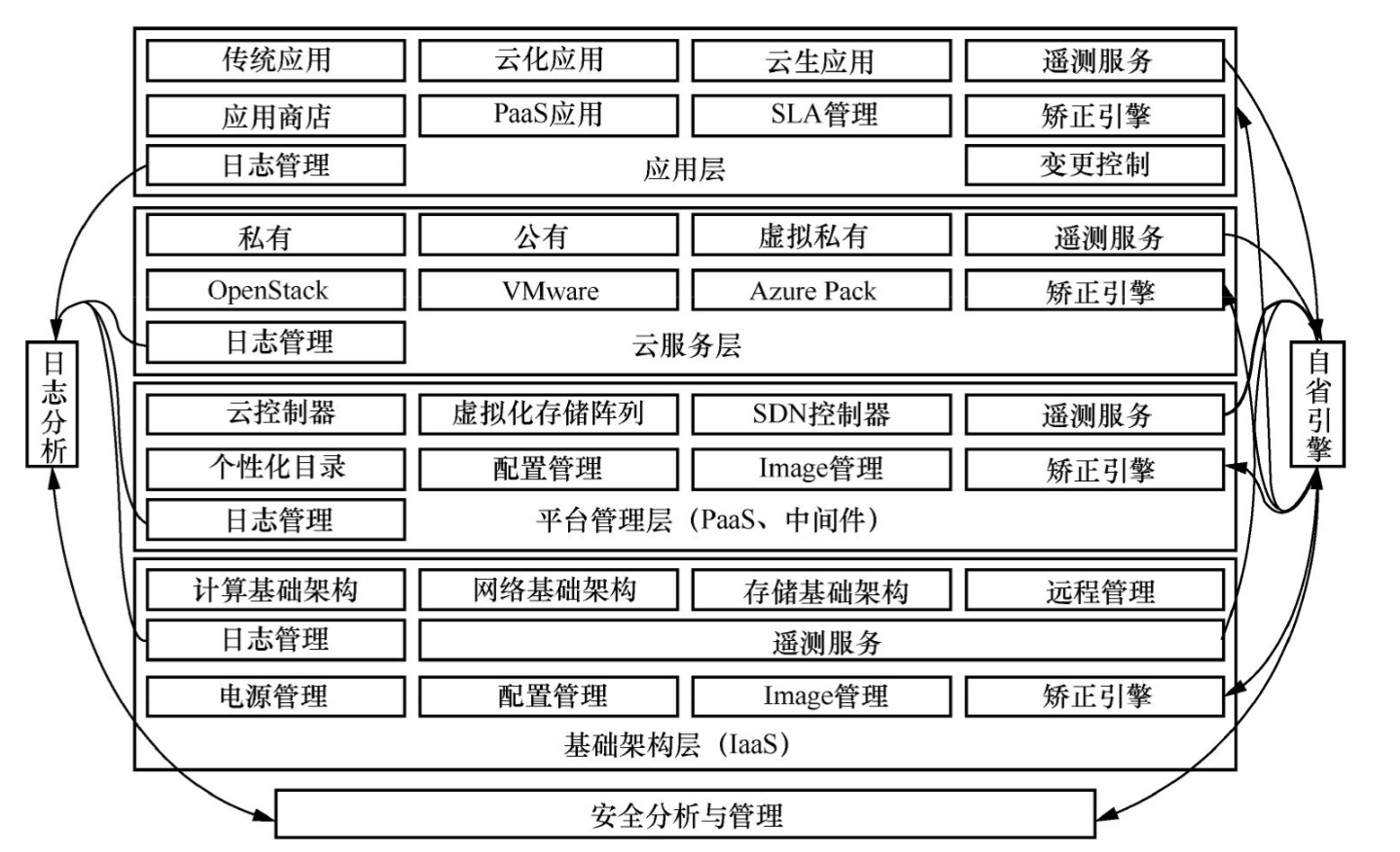
(3)核心组件软件定义数据中心的分层服务架构与核心组件如图4所示,具体核心组件如下:
①软件定义计算。
②软件定义存储。
③软件定义网络。
④软件定义数据中心安全。
⑤软件定义数据中心管理与编排。
上述这5个核心组件与图4(以及下图5)中所示的技术栈各层存在着如下对应关系。
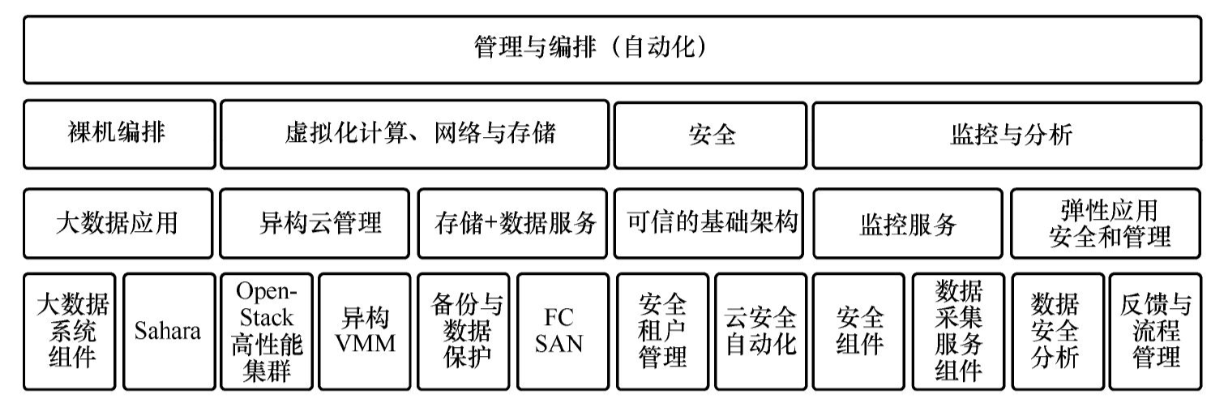
①IaaS:接入计算、存储、网络硬件设备,并经过虚拟化、抽象化把软件、可编程接口向上提供。
②PaaS(平台管理层+云服务层):
对上层(应用、用户)提供各种弹性服务接口;
对下层(基础设施)实施自动部署与运维。
③应用层:调用底层提供的服务、编程接口,面向各级管理员与用户的管理中心(Control Center、Management Console)。
在后面文章中,老夫会就如何构建可扩展的、服务驱动的大数据与云平台展开论述。88。
(文/Ricky - HPC高性能计算与存储专家、大数据专家、数据库专家及学者)
· END ·

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)