
如何Step-by-Step蒸馏一个LLM模型?
本文逐步Step-by-Step介绍,如何蒸馏一个LLM模型,并且结合Python代码讲解。
文章目录
1. 背景
大型语言模型(LLM)对计算资源的需求极为庞大,依赖于专用硬件支持,并且能耗极高,以至于在处理简单任务时也显得极不经济。
模型蒸馏(Distill)技术在此背景下应运而生,在大型语言模型领域,蒸馏技术旨在将大型模型(常被称为“教师模型”)的知识与能力,提炼并转移至更小、更高效的“学生模型”中。这一过程的数学原理、工程实现以及潜在优势,已成为当前人工智能研究的重要课题。
什么是蒸馏,请参考这篇文章:
《深度学习的知识蒸馏:Distilling the Knowledge in a Neural Network》
传统蒸馏方法主要关注于通过“软标签”(soft labels)或中间表示的学习,使学生模型模仿教师模型的输出行为。虽然这些方法在模型小型化和效率提升方面取得了一定成功,但在传递复杂的推理能力时,往往存在明显不足。
我们看下由谷歌研究团队与学术界合作发表的论文《Distilling Step-by-Step! Outperforming Larger Language Models
with Less Training Data and Smaller Model Sizes》提出了一种蒸馏方法。该方法突破性地关注于推理过程的蒸馏,不仅提取教师模型的答案,更着重于其背后的推理逻辑与步骤。这种对推理过程的深度挖掘,使得学生模型不仅能学习“是什么”,更能理解“为什么”,从而在某些情况下实现对教师模型的性能超越。
2. 介绍 Step-by-Step 蒸馏
核心创新在于视角的根本性转变。该方法不再将大型语言模型仅视为输出答案的黑箱,而是充分认识到并利用了其卓越的推理能力。这相当于我们不再仅向“教师”索要答案,而是要求其展示解题步骤,阐释思维过程。
论文中所描述的蒸馏过程分为两个相互关联却又截然不同的阶段。
2.1 推理提取阶段
在这个阶段,我们使用思维链(CoT)提示,巧妙地要求模型不仅给出答案,还要提供逐步推理过程。
论文通过“少样本” CoT 提示,向大型语言模型提供少量输入-推理-标签三元组(input-rational-label)示例,引导模型生成推理过程。该三元组可以定义为:
{ x i , r ^ i , y ^ i } \{x_i, \hat r_i, \hat y_i\} {xi,r^i,y^i}
数据示例如下: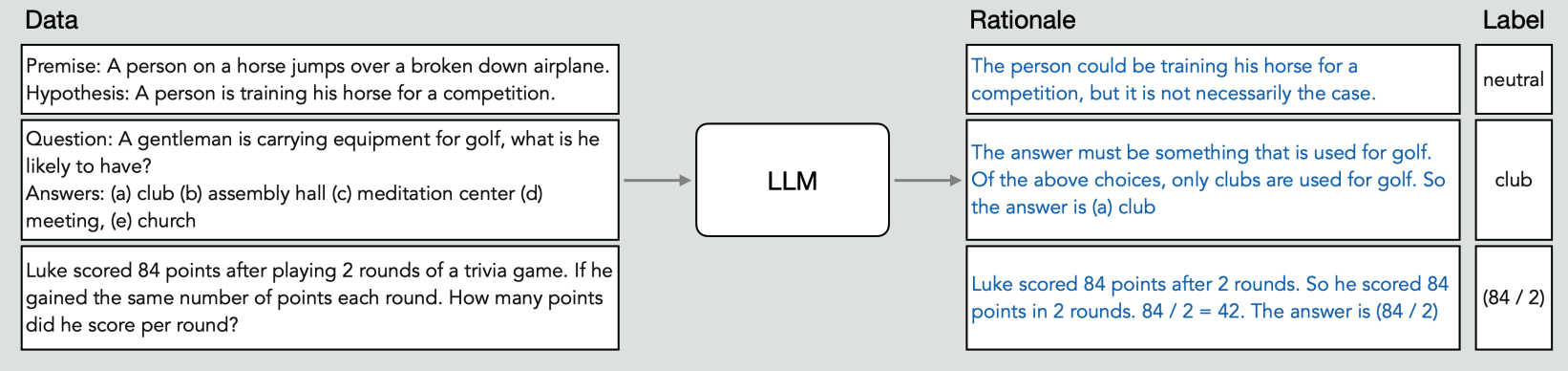
例如,对于“若火车以每小时60英里的速度行驶2小时,行驶距离为多少?”这类简单问题,传统提示仅要求答案,思维链提示则鼓励模型生成中间推理步骤:“速度为每小时60英里,时间为2小时。距离等于速度乘以时间。距离等于每小时60英里乘以2小时,即120英里。”此时输出的不仅是“120英里”这一答案,还有推理依据。这些自然语言表述的推理过程,就是本阶段所挖掘的关键信息。该阶段的输出是一个珍贵的数据集,每个输入不仅对应大型语言模型预测的标签(答案),还有自然语言推理。
2.2 多任务训练阶段
在此阶段,我们使用先前创建的数据集对小型“学生”模型进行训练。与传统蒸馏不同,我们不仅训练学生预测最终标签,还同时训练其生成推理过程。
论文将此表述为多任务学习问题,学生模型需最小化两个损失函数:
- 标签预测准确性。这个与通用的蒸馏方法一致,计算预测值和标准答案的交叉熵作为损失函数。
L label = 1 N ∑ i = 1 N ℓ ( f ( x i ) , y ^ i ) , \mathcal{L}_\text{label} = \frac{1}{N} \sum _ {i=1} ^N \ell (f(x_i), \hat{y} _i), Llabel=N1i=1∑Nℓ(f(xi),y^i), - 推理生成质量。计算推理过程的差异性作为损失函数。
L rationale = 1 N ∑ i = 1 N ℓ ( f ( x i ) , r ^ i ) . \mathcal{L}_\text{rationale} = \frac{1}{N} \sum _ {i=1} ^N \ell (f(x_i), \hat{r}_i). Lrationale=N1i=1∑Nℓ(f(xi),r^i).
这里本质上是要求学生模仿老师的推理,这可能并不总是最佳或最有效的推理形式。学生模型可能有其他甚至更好的方法来得出正确答案,但这种损失函数使其倾向于复制教师的推理过程。
最终的损失函数如下:
L = L label + λ L rationale \mathcal{L} = \mathcal{L}_\text{label} + \lambda \mathcal{L}_\text{rationale} L=Llabel+λLrationale
其中:
- x i x_i xi 表示文本输入
- y ^ \hat{y} y^ 表示教师模型的标准答案
- r ^ i \hat{r}_i r^i 表示教师模型的标准推理
- L \mathcal{L} L 表示交叉熵函数
传统方法往往侧重模仿教师的表面行为——输出。“逐步蒸馏”则试图捕捉更深层的东西:底层推理过程。通过迫使小型模型生成推理,我们实际上是在鼓励其学习更抽象、更通用的任务理解。它不是在记忆输入输出对,而是在学习连接输入输出的原则。
3. Python 实现 Step-by-Step 蒸馏
GitHub:参考 Distilling Step-by-Step
3.1 数据预处理:data_utils.py
在 data_utils.py 对数据处理:
- 加载数据集。加载Hugging Face数据集、从自定义JSON文件加载;
- 准备输入和输出;
- 整合LLM的输出。加载器可以从 JSON 文件中读取这些数据(用于 PaLM 或 GPT 预测),并将其结构化解析。
class DatasetLoader(object):
def __init__(self, dataset_name, source_dataset_name, dataset_version, has_valid, split_map,
batch_size, train_batch_idxs, test_batch_idxs, valid_batch_idxs=None):
self.data_root = DATASET_ROOT
self.dataset_name = dataset_name
self.source_dataset_name = source_dataset_name
self.dataset_version = dataset_version
self.has_valid = has_valid
self.split_map = split_map
self.batch_size = batch_size
self.train_batch_idxs = train_batch_idxs
self.test_batch_idxs = test_batch_idxs
self.valid_batch_idxs = valid_batch_idxs
assert self.split_map is not None
def load_from_source(self):
if self.source_dataset_name is None:
self.source_dataset_name = self.dataset_name
if self.dataset_version is None:
datasets = load_dataset(self.source_dataset_name)
else:
datasets = load_dataset(self.source_dataset_name, self.dataset_version)
return datasets
def to_json(self, datasets):
for k, v in self.split_map.items():
datasets[v].to_json(f'{self.data_root}/{self.dataset_name}/{self.dataset_name}_{k}.json')
....
其中,CQADatasetLoader、SVAMPDatasetLoade是具体数据集加载类的实现。
3.2 评估数据:metrics.py
在 metrics.py 中,计算文本和方程式预测准确性的函数:
- 文本准确性:将预测与标签进行比较。
- 方程式准确性:计算字符串表达式(可控方式使用Python的eval函数),查看计算出的答案是否匹配。
例如,方程式精度函数如下:
def compute_equation_acc(preds, labels):
preds = [eval_equation(pred) for pred in preds]
labels = [eval_equation(label) for label in labels]
return np.mean(np.array(preds) == np.array(labels))
def eval_equation(equation):
try:
answer = eval(equation)
except:
answer = np.nan
return answer
当推理任务不仅是分类,还涉及更复杂的推理,如数学问题解决时,这个模块至关重要。
3.3 多任务模型和训练器设置:model_utils.py
3.3.1 自定义数据收集器
TaskPrefixDataCollator 会将一批示例分割成两个字典:
- 一个用于主要预测任务。
- 一个用于解释(辅助)任务。
class TaskPrefixDataCollator(DataCollatorForSeq2Seq):
def __call__(self, features, return_tensors=None):
features_df = pd.DataFrame(features)
pred_features = features_df.loc[:, ~features_df.columns.isin(['aux_labels', 'expl_input_ids', 'expl_attention_mask'])].to_dict('records')
expl_features = features_df.loc[:, ~features_df.columns.isin(['labels', 'input_ids', 'attention_mask'])].rename(
columns={'aux_labels': 'labels', 'expl_input_ids': 'input_ids', 'expl_attention_mask': 'attention_mask'}).to_dict('records')
pred_features = super().__call__(pred_features, return_tensors)
expl_features = super().__call__(expl_features, return_tensors)
return {
'pred': pred_features,
'expl': expl_features,
}
3.3.2 自定义训练器
TaskPrefixTrainer 通过重写 compute_loss 方法扩展了 Hugging Face 的 Seq2SeqTrainer。这允许使用加权和(由参数 alpha 控制)结合主要预测任务和辅助解释生成任务的损失。
class TaskPrefixTrainer(Seq2SeqTrainer):
def __init__(self, alpha, output_rationale, **kwargs):
super().__init__(**kwargs)
self.alpha = alpha
self.output_rationale = output_rationale
def compute_loss(self, model, inputs, return_outputs=False):
pred_outputs = model(**inputs['pred'])
expl_outputs = model(**inputs['expl'])
loss = self.alpha * pred_outputs.loss + (1. - self.alpha) * expl_outputs.loss
return (loss, {'pred': pred_outputs, 'expl': expl_outputs}) if return_outputs else loss
这一设计优雅地融合了两项任务:指导学生模型不仅学习答案,还学习推理过程。
3.4 运行蒸馏流程:run.py
主要入口点 run.py。它解析命令行参数以选择数据集(CQA、SVAMP、ESNLI、ANLI1 或甚至 ASDiv 用于数据增强)、要使用的 LLM 预测类型(PaLM 或 GPT)以及其他超参数。
3.4.1 数据集准备
根据所选数据集,实例化相应的加载器。例如:
if args.dataset == 'cqa':
dataset_loader = CQADatasetLoader()
elif args.dataset == 'svamp':
dataset_loader = SVAMPDatasetLoader()
# 依此类推。
4.4.2 整合 LLM 预测
如果你正在从 LLM 中进行蒸馏,代码会加载外部推理和标签并将它们作为新列添加:
datasets['train'] = datasets['train'].add_column('llm_label', train_llm_labels)
datasets['train'] = datasets['train'].add_column('llm_rationale', train_llm_rationales)
3.4.3 标记化和任务前缀
使用预训练的标记器(例如,来自 google/t5-v1_1-base),代码对标记示例进行处理。对于任务前缀模型,它甚至在输入文本前添加 “predict:” 和 “explain:”。
def tokenize_function(examples):
model_inputs = tokenizer(['predict: ' + text for text in examples['input']], max_length=args.max_input_length, truncation=True)
expl_model_inputs = tokenizer(['explain: ' + text for text in examples['input']], max_length=args.max_input_length, truncation=True)
model_inputs['expl_input_ids'] = expl_model_inputs['input_ids']
model_inputs['expl_attention_mask'] = expl_model_inputs['attention_mask']
# (Encode labels and rationales as targets)
return model_inputs
3.4.4 训练和评估
最后,run.py 调用 train_and_evaluate 函数(位于 train_utils.py 中),传入标记化的数据集和指标函数。该函数设置好一切并启动训练。
3.5 训练:train_utils.py
在 train_utils.py 中,执行训练任务。
函数 get_config_dir(args) 根据当前超参数构建保存检查点和日志的目录路径。这使得跟踪不同运行变得容易。
函数train_and_evaluate()中,通过 T5ForConditionalGeneration.from_pretrained(args.from_pretrained) 加载 T5 模型。如有需要,可以将模型并行化到多个 GPU 上。
我们使用 Seq2SeqTrainingArguments 指定训练参数(例如,学习率、批量大小)。
根据使用任务前缀模型还是标准模型,实例化自定义 TaskPrefixTrainer(支持双重损失)或标准的 Seq2SeqTrainer。
最后,使用以下代码启动训练:
trainer.train()
从数据加载到模型训练,整个过程体现了我们的逐步蒸馏理念:指导学生模型不仅学习正确的输出,还学习背后的推理过程。
参考
[1] https://medium.com/data-science-collective/how-to-distill-a-llm-step-by-step-58f06fcf4bfa
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎/CSDN:SmallerFL
也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤


GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)