
基于python深度学习的舆情情感识别
随着全球互联网的快速发展,特别是当前移动互联网的大量普及,人们在社交平台、短视频平台等应用中大量的利用网络来表达自己的情感与观点,并且能迅速的发酵形成大规模的舆情事件,例如农夫山泉与娃哈哈的事件。目前网络舆情已经成为了一个重要的研究领域。因此,如何有效地分析和识别网络舆情中的情感倾向,成为了一个重要的研究问题。传统的情感分析方法往往基于词典或者规则来判断文本的情感倾向。而深度学习模型可以自动学习数
随着全球互联网的快速发展,特别是当前移动互联网的大量普及,人们在社交平台、短视频平台等应用中大量的利用网络来表达自己的情感与观点,并且能迅速的发酵形成大规模的舆情事件,例如农夫山泉与娃哈哈的事件。目前网络舆情已经成为了一个重要的研究领域。因此,如何有效地分析和识别网络舆情中的情感倾向,成为了一个重要的研究问题。传统的情感分析方法往往基于词典或者规则来判断文本的情感倾向。而深度学习模型可以自动学习数据中的特征,避免了人工特征工程的需求,大大提高了分析的效率和准确性。深度学习模型可以通过构建复杂的神经网络结构,捕捉文本中的深层次情感信息,从而更准确地识别舆情中的情感倾向。所以实现一个基于深度学习的舆情情感识别模型意义重大。
本文研究了基于深度学习的舆情情感识别模型,旨在从大量的文本数据中自动识别和分析公众的情感倾向。介绍了基于深度学习的舆情情感识别模型的构建过程。通过采用卷积神经网络(CNN)和长短时记忆网络(LSTM)的深度学习模型,收集到的社交媒体、新闻网站、论坛等数据,运用自然语言处理技术实现了对舆情文本的有效表示和情感倾向的准确识别。本文进行了大量的实验验证,对模型的性能进行了全面的评估。实验结果表明,基于深度学习的舆情情感识别模型在准确率和效率上都优于传统的情感分析方法。
关键词: 深度学习;情感识别;CNN;LSTM;TENSORFLOW;
课题研究的背景
随着互联网特别是移动互联网的普及,网络成为了人们获取信息、表达观点、交流情感的重要平台[1]。传统的舆情情感识别方法主要基于规则、模板或简单的机器学习算法,这些方法在处理复杂、多元化、语言表达混淆的社交媒体数据时,往往效果不佳[2]。随着大数据技术的发展,海量的网络数据为深度学习情感识别提供了丰富的数据资源。通过对这些数据的深度挖掘和分析,可以更加全面、深入地了解公众的情感倾向和态度[3],为政府决策、企业营销、个人行为等提供有力的支持。
因此,利用基于深度学习的舆情情感识别模型可以对网络舆情进行深入研究,挖掘其中的情感倾向和态度,通过自动学习特征和表征,能够实现对复杂数据的精准处理和分析,能够更好地适应复杂多变的网络舆情环境[4]。通过深入研究这一课题,可以推动舆情情感识别技术的进一步发展,为政府、企业和个人的应用提供更加准确、可靠的支持。
课题研究目的意义
基于深度学习的舆情情感识别模型研究的主要目的有以下几点
1、强化情感识别的精确度方面:传统情感识别方法在面对复杂多变的网络舆情数据时[5],常常难以精确捕捉和识别其中所蕴含的情感倾向。然而,深度学习模型通过模拟人脑神经元的复杂信息处理机制,能够自动学习并提炼出数据的深层次特征,进而显著提升情感识别的精确度。
2、应对大规模数据的处理挑战方面:随着大数据时代的迅猛发展,网络舆情数据呈现出迅猛增长的态势。幸运的是,基于深度学习的情感识别模型具备处理大规模数据的能力,它能够有效利用海量数据进行训练,从而更全面、细致地反映公众的情感倾向[6]。
3、挖掘舆情深层含义方面:舆情情感不仅仅是简单的正面或负面评价[7],往往蕴含着更复杂的情感倾向和深层含义,通过深度学习的技术,模型能够深入挖掘舆情数据中的潜在信息和规律,揭示公众对于特定事件或话题的深层次态度和看法,为政府和企业提供更深入、全面的舆情分析。
这些目标的实现将有助于更好地理解和应对网络舆情,为政府决策、企业运营等提供有力支持。
论文的主要工作及结构
本文利用收集到数据,对数据进行清洗和预处理工作,利用该数据将构建的卷积神经网络(CNN)和长短期记忆网络(LSTM)模型进行了训练。本文具体结构如下。
第一章是前言,介绍基于深度学习的舆情情感识别模型的背景、目的、意义,并分析当前国内外基于深度学习的舆情情感识别模型的研究现状,阐述本文的结构。
第二章对舆情情感识别模型研究所涉及到到的关键技术进行介绍,介绍了卷积神经网络、长短期记忆网络、TensorFlow。
第三章数据的处理,重点叙述了舆情情感数据的收集与预处理。
第四是模型的实现,重点介绍了卷积神经网络模型的和长短期记忆网络模型的构建。
第五章是模型指标的评估对比,对比了卷积神经网络模型的和长短期记忆网络模型的的准确度、召回值和F1值。
第六章是结论,对基于深度学习的舆情情感识别模型课题的研究过程进行总结,展望未来的研究方向。
舆情情感数据的收集
社交媒体平台,如微博、微信朋友圈、抖音短视频等,无疑已成为舆情数据的宝贵资源。在这些平台上,用户们每天都会分享和创造大量的文字、图片和视频内容,这些内容蕴含着丰富的情感信息,为本次进行情感分析提供了丰富的素材。
在数据收集的过程中,首先需要明确我们的收集目标。这可以是对某个特定事件的舆论反应,也可以是对某个产品或品牌的用户评价。只有明确了目标,我们才能更有针对性地收集数据,提高数据的利用价值。
为了实现这一目标,可以采用多种数据收集方式。其中,爬虫技术是一种常见且有效的方法。通过模拟人类访问网站的行为,爬虫能够自动抓取网页上的信息,包括用户发布的文本、图片和视频等。这种方式可以快速地获取大量的数据,但要确保数据的合法性和合规性。
另一种数据收集方式是使用API接口。许多社交媒体平台都提供了API接口,允许开发者通过编程的方式获取平台上的数据。这种方式相比爬虫技术更为正规和稳定,且通常能够获取到更为详细和全面的数据。
舆情情感数据的预处理
以某次社会热点事件的舆情数据收集为例,得到了大量的原始数据,但这些数据往往混杂着噪音、无关信息和格式上的千差万别。为了确保这些数据能够被有效地用于情感分析,必须进行一系列的数据预处理操作。
首先,进行文本清洗。在这一步中,需要专注于去除文本中的无关字符、特殊符号和URL链接等。这些元素在原始数据中可能占据了相当大的比例,但它们对于情感分析来说并没有实际贡献,甚至可能成为干扰因素。通过清洗,才能确保了数据的纯净度,为后续的分析工作打下了坚实的基础。
紧接着,进行了分词处理。由于中文的词语之间没有明确的分隔符,因此分词成为了舆情数据预处理中不可或缺的一步。利用现有的分词工具或算法,将连续的文本切分成独立的词汇单元。这样,每个词汇都能够被模型单独识别和处理,从而提高了情感分析的准确性。
接下来,去除停用词。这些停用词通常是出现频率极高但对情感分析没有实际意义的词汇,如“的”、“了”等。它们的存在会增加数据的稀疏性,降低模型的效率。通过去除这些停用词,就可以进一步精炼了数据,使其更加符合情感分析的需求。
然后,进行了词性标注。这一步是为了给文本中的每个词汇标注其词性,如名词、动词、形容词等。词性标注不仅可以帮助模型更好地理解文本的结构和语义信息,还能够为后续的文本分类和情感分析提供有力的支持。关键代码如下:
#舆情中文文本数据清洗、中文分词、去掉停用词,结合情感词典提取舆情中文文本关键词
def Xitxtcon(self):
#list=self._ShuiSQL.GethQtxtList("and txtconx='' and del='0'")
list = self._ShuiSQL.GethQtxtList("")
#list = self._ShuiSQL.GethQtxtList(" and txtconkeys like '%开心%' and del='0' ")
for row in list:
id = row[0]
#舆情中文文本
txtcon= row[1]
#清洗舆情中文文本
txtconx = self.GShuiCha(txtcon).replace(" ","")
#中文分词
txtconci = self.GShuiWord(txtconx)
txtconci_f = txtconci.split() # 读取分词列
#提取情感词
txtstate=row[3]
_shuikey = ""
if txtstate=="积极":
_shuikey = self.GShuiDaLianQGGood()
if txtstate == "消极":
_shuikey = self.GShuiDaLianQGBad()
txtconkeys = '' # 输出结果为shustr
for objShuiCi in txtconci_f: # 读取关键词
if objShuiCi in _shuikey:
if objShuiCi != '\t':
txtconkeys += objShuiCi
txtconkeys += " "
ctxtcon = {
"id": id,
"txtconx": txtconx,
"txtconci": txtconci,
"txtconkeys": txtconkeys,
}
self._ShuiSQL.UpdatehQtxt(ctxtcon)
print("舆情中文文本数据内容为:" + txtcon + "的样本数据处理中")
最后,进行了文本编码。在这一步中,我将文本数据转换为计算机能够处理的数值形式。这通常涉及将每个词汇映射到一个唯一的数字标识符上,以便模型能够轻松地处理这些文本数据。通过文本编码,我成功地将舆情数据转化为了适合模型处理的形式,为后续的情感分析工作做好了准备。
经过以上一系列预处理步骤后,我得到了一个干净、整洁、结构化的舆情数据集。其中得到的数据集的分词词云图以及结果统计图如下。

文本表示
在舆情情感识别中,文本表示是一个至关重要的环节。它涉及到将原始的文本数据转换为模型可以处理的数值形式,从而有效地提取出文本中的情感信息。以下是几种常用的文本表示方法及其在舆情情感识别模型中的应用举例:
1. 词袋模型(Bag of Words)
词袋模型是一种简单的文本表示方法,它将文本视为一系列词的集合,而不考虑词序。每个词在模型中都被表示为一个独立的特征,而文本则是由这些特征组成的向量。在舆情情感识别中,我们可以使用词袋模型将文本转换为词频向量,然后利用机器学习算法进行分类。例如,对于一条关于某产品的评论,我们可以统计其中正面词汇和负面词汇的出现频率,从而判断评论的情感倾向。
2. TF-IDF 表示
TF-IDF(词频-逆文档频率)是一种基于统计的文本表示方法。它考虑了词在文档中的出现频率(TF)以及词在整个语料库中的分布(IDF)。TF-IDF 值越高,说明该词在文档中越重要。在舆情情感识别中,我们可以使用 TF-IDF 表示法来提取文本中的关键信息。例如,通过计算 TF-IDF 值,我们可以确定哪些词或短语在特定话题下具有较高的重要性,从而帮助识别情感倾向。
3. 词嵌入(Word Embeddings)
词嵌入是一种将词转换为连续向量表示的方法,如 Word2Vec、GloVe 和 FastText 等。这些向量能够捕捉词之间的语义和语法关系,使得相似的词在向量空间中具有相近的表示。在舆情情感识别中,我们可以利用预训练的词嵌入模型将文本中的每个词转换为向量表示,然后利用深度学习模型进行情感分析。这种方法能够充分利用文本的语义信息,提高情感识别的准确性。
4. 句子嵌入或文档嵌入
除了词级别的嵌入,我们还可以将整个句子或文档转换为向量表示。这通常通过深度学习模型(如 LSTM、GRU 或 Transformer)实现,这些模型能够捕捉文本中的长期依赖关系和上下文信息。在舆情情感识别中,我们可以使用这些模型将文本转换为句子或文档嵌入,然后利用这些嵌入进行情感分类。这种方法能够更好地捕捉文本的整体意义,提高情感识别的性能。
模型的精确度指标对比
在舆情情感识别模型的评估中,准确率(Accuracy)是一个关键指标,用于衡量模型正确分类样本的能力。准确率是正确分类的样本数与总样本数之比。
具体计算步骤如下:
混淆矩阵的构建:首先,我们需要构建一个混淆矩阵(Confusion Matrix),它是一个表格,用于记录模型对各个类别的分类结果。混淆矩阵的行通常代表实际的情感标签(真实值),列代表模型预测的情感标签(预测值)。对于情感识别任务,通常会有三个类别:正面、负面和中性(或者根据具体任务可能有所不同)。其中混淆矩阵截图如下:
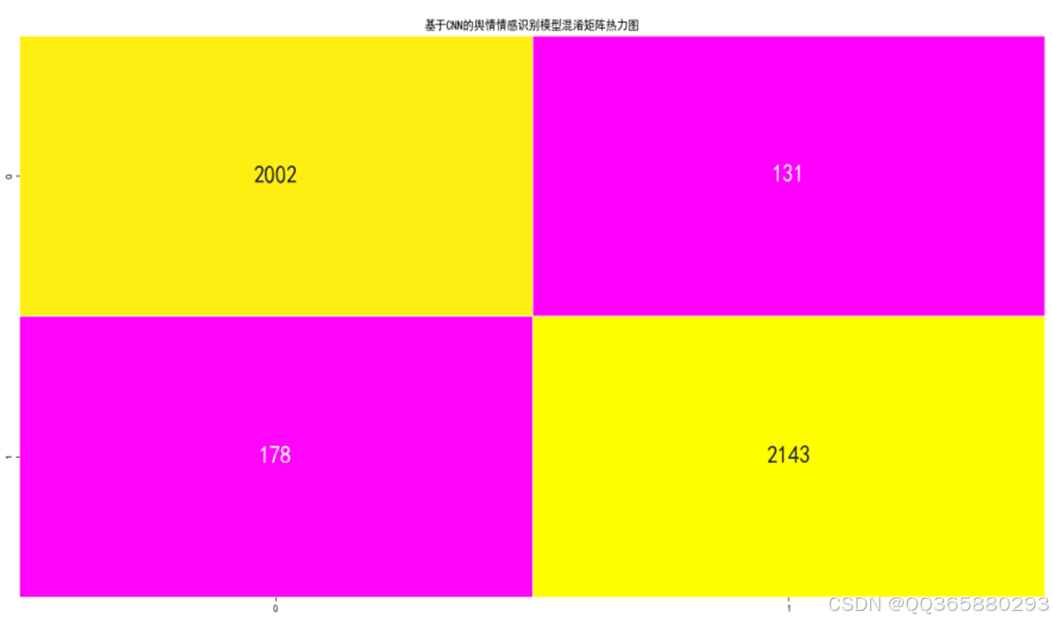
模型的查全率指标对比
查全率的计算公式为:
查全率 = 真正例数量(TP) / (真正例数量(TP) + 假负例数量(FN))
其中:
真正例(True Positive,TP)是模型正确预测为正面的样本数,即实际为正面且模型也预测为正面的样本数。
假负例(False Negative,FN)是模型错误地将正面样本预测为负面的样本数,即实际为正面但模型预测为负面的样本数。
查全率的取值范围为0到1。值越接近1,表示模型的预测正例的漏报率越低,即模型能够尽可能多地找到所有的正面样本;而值越接近0,表示模型的预测正例的漏报率越高,即模型可能漏掉了很多实际为正面的样本。
本次课题研究的模型对比结果
卷积神经网络(CNN)模型的查全率为:0.9309
长短时记忆网络(LSTM)模型的查全率为:0.9341
模型的F1指标对比
情感识别领域,它用于衡量模型的精确率和查全率的平衡。F1值越高,说明模型在精确率和查全率两方面的表现都越好。
F1值的计算公式如下:
F1 = 2 * (精确率 * 查全率) / (精确率 + 查全率)
其中,精确率(Precision)是模型预测为正例的样本中真正为正例的比例,查全率(Recall)则是实际为正例的样本中被模型正确预测出来的比例。
在情感识别任务中,F1值的重要性体现在它能够综合考虑模型对正面情感的识别能力(通过查全率体现)以及模型在识别正面情感时的准确性(通过精确率体现)。一个高F1值的模型意味着它不仅能够有效地找出大部分正面情感的文本,而且在识别这些文本时犯的错误也较少。
此外,F1值在处理数据不平衡的情况时特别有用。在实际应用中,正面情感的文本可能相对较少,这时单独依赖准确率或查全率可能无法全面反映模型的性能。而F1值则能够提供一个更全面的评估,帮助我们更好地理解和改进模型。
本次课题研究的模型对比结果
卷积神经网络(CNN)模型的F1值为:0.9305
长短时记忆网络(LSTM)模型的F1值为:0.9334
《基于python深度学习的舆情情感识别》该项目采用技术Python的django框架、mysql数据库 ,项目含有源码、文档、PPT、配套开发软件、软件安装教程、项目发布教程、核心代码介绍视频等
软件开发环境及开发工具:
开发语言:python
使用框架:Django
前端技术:JavaScript、VUE.js(2.X)、css3
开发工具:pycharm、Visual Studio Code、HbuildX
数据库:MySQL 5.7.26(版本号)
数据库管理工具:phpstudy/Navicat或者phpstudy/sqlyog

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)