
“看一眼就足够!”KAIST提出零样本单目深度估计模型:高分辨率深度图高效生成,告别边界断层!
基于Patch的高分辨率深度估计方法虽能缓解内存问题,但在重新组装估计的深度Patch时会引入深度不连续问题,即边界伪影,且为解决该问题采用的测试时集成平均方法会降低推理速度,在实际应用中存在局限性。:零样本深度估计模型在大规模数据集上训练,泛化性强,但训练数据分辨率低,处理高分辨率图像时,直接处理会导致内存消耗大且精度下降,下采样则会丢失边缘细节,影响深度估计的准确性,使整体结构出现低频伪影。在

论文标题:One Look is Enough: A Novel Seamless Patchwise Refinement for Zero-Shot Monocular Depth Estimation Models on High-Resolution Images
论文地址:https://arxiv.org/abs/2503.22351
项目地址:https://kaist-viclab.github.io/One-Look-is-Enough_site/
导读 : 论文提出了 Patch Refine Once (PRO) 模型,旨在解决现有模型在处理高分辨率图像时存在的内存消耗高和深度不连续的问题。
研究动机
分辨率差异问题:零样本深度估计模型在大规模数据集上训练,泛化性强,但训练数据分辨率低,处理高分辨率图像时,直接处理会导致内存消耗大且精度下降,下采样则会丢失边缘细节,影响深度估计的准确性,使整体结构出现低频伪影。
基于Patch方法的缺陷:基于Patch的高分辨率深度估计方法虽能缓解内存问题,但在重新组装估计的深度Patch时会引入深度不连续问题,即边界伪影,且为解决该问题采用的测试时集成平均方法会降低推理速度,在实际应用中存在局限性。
训练数据问题:高分辨率深度估计需要精细深度细节和低标签噪声的数据集。真实世界数据集深度标签稀疏,获取密集深度数据困难;合成数据集虽提供密集深度标签,但存在领域差距,模型在合成数据上训练后对真实世界数据零样本推理效果不佳,如UnrealStereo4K数据集中透明物体深度标注不准确。
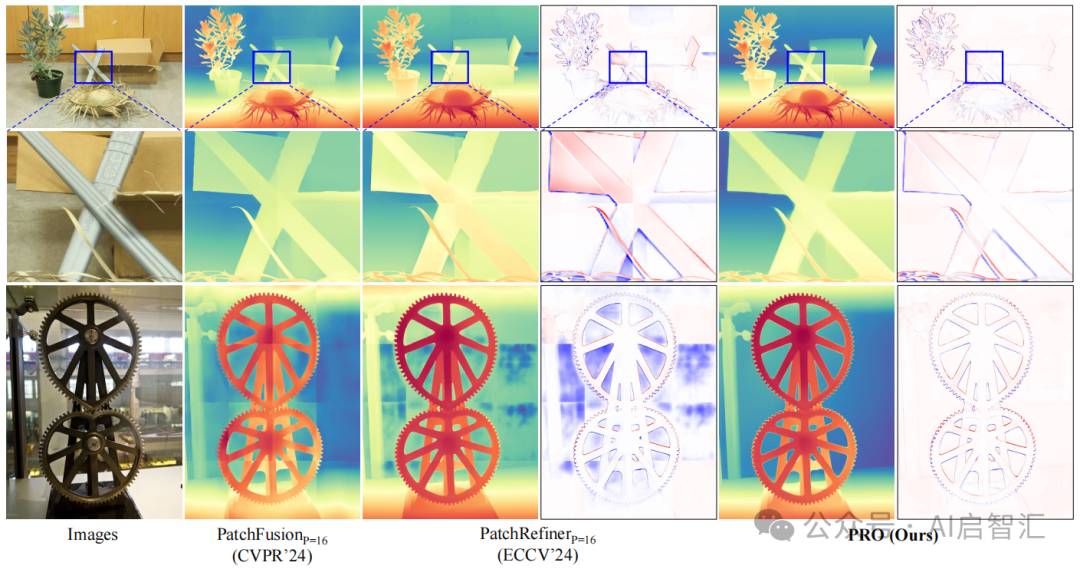
上图展示了基于 Patch 的高分辨率图像深度估计模型(PatchFusion、PatchRefiner 和本文提出的 PRO)的定性对比结果。突出了PRO模型在处理高分辨率图像时,在避免深度不连续伪影、实现平滑边界过渡方面的优势。
创新点
分组Patch一致性训练(GPCT):通过同时处理四个重叠Patch并在单个反向传播步骤中对重叠区域施加一致性损失,增强测试时效率,减轻深度不连续问题,相比基于 Patch 的 SOTA 方法,推理速度快 12 倍。
无偏差掩蔽(BFM):利用预训练零样本 MDE 模型的先验知识,屏蔽合成数据集中不可靠区域,防止深度细化模型过度拟合数据集特定偏差,使模型在合成数据训练后对真实世界数据集具有更好的泛化能力。
方法
整体框架:
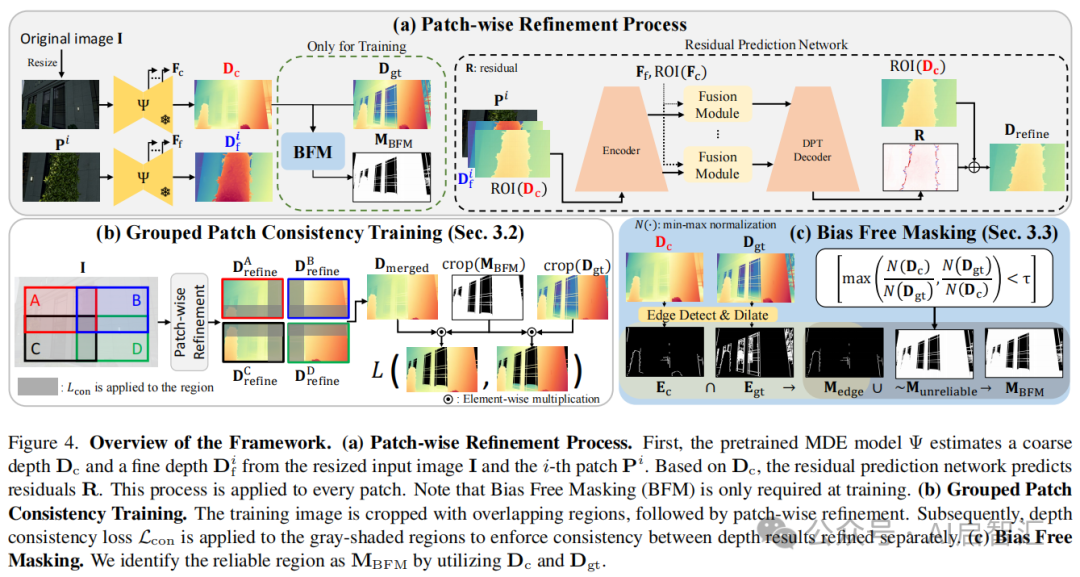
Patch Refine Once(PRO)模型概述:首先将原始输入图像I调整大小后输入预训练的零样本MDE网络![]() ,得到粗深度图
,得到粗深度图![]() ,然后将I裁剪为N个基于网格的 Patch,每个 Patch 调整大小后输入
,然后将I裁剪为N个基于网格的 Patch,每个 Patch 调整大小后输入![]() 得到精细深度图
得到精细深度图![]() ,从
,从![]() 的解码器提取两组五级特征,经 ROI 操作和融合模块处理后,由残差预测网络
的解码器提取两组五级特征,经 ROI 操作和融合模块处理后,由残差预测网络![]() 得到细化深度图
得到细化深度图![]() ,公式为
,公式为
![]()
分组 Patch 一致性训练(GPCT):同时使用四个重叠 Patch(A、B、C、D),对每个 Patch 独立细化后,应用深度一致性损失:
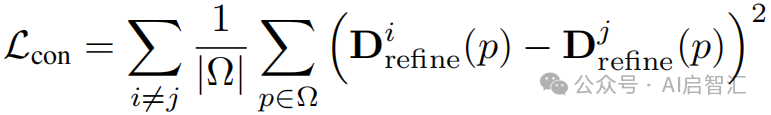
,其中![]() 和
和![]() 是重叠Patch的深度预测,
是重叠Patch的深度预测,![]() 是重叠区域。合并深度图:
是重叠区域。合并深度图:
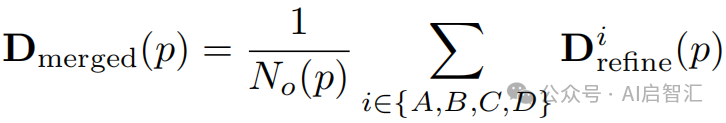
通过计算![]() 与
与![]() 的损失,在每次反向传播中增强 Patch 间一致性,减少边界伪影。在图 4-(b) 中,训练样本被划分为重叠 Patch,对每个 Patch 独立细化后,应用深度一致性损失,确保 Patch 边界处的深度一致性。
的损失,在每次反向传播中增强 Patch 间一致性,减少边界伪影。在图 4-(b) 中,训练样本被划分为重叠 Patch,对每个 Patch 独立细化后,应用深度一致性损失,确保 Patch 边界处的深度一致性。
无偏差掩蔽(BFM):
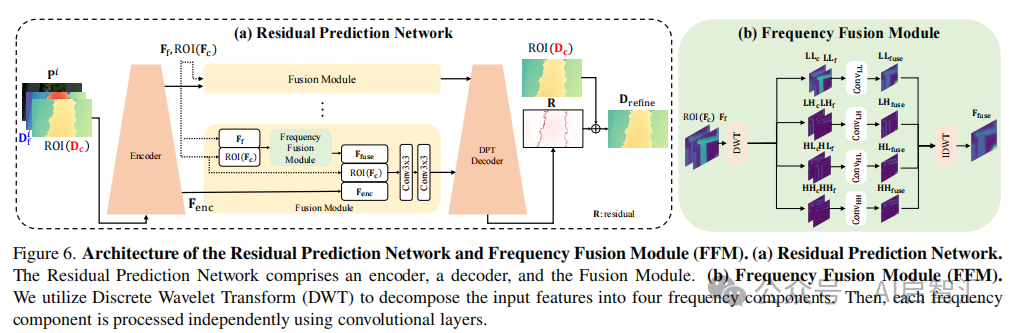
在训练深度细化模型时,利用预训练零样本 MDE 模型![]() ,通过测量
,通过测量![]() 和
和![]() 的相对一致性,确定不可靠区域:
的相对一致性,确定不可靠区域:
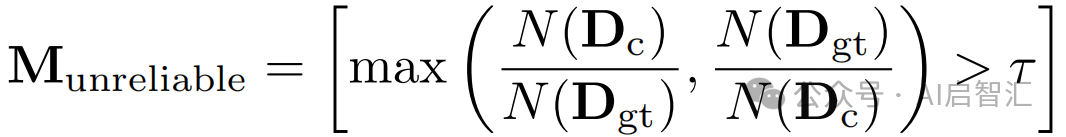
,结合![]() 和
和![]() 的边缘信息生成可靠掩码
的边缘信息生成可靠掩码
![]()
通过掩码损失
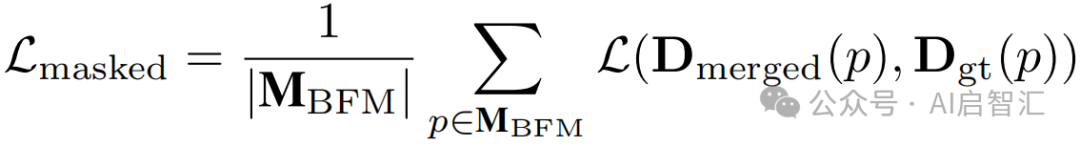
,仅在可靠区域进行训练,防止模型对透明区域错误细化。在图 4-(c) 中,通过测量和的相对一致性确定不可靠区域,结合边缘信息生成可靠掩码,在训练时仅对可靠区域应用监督。
实验
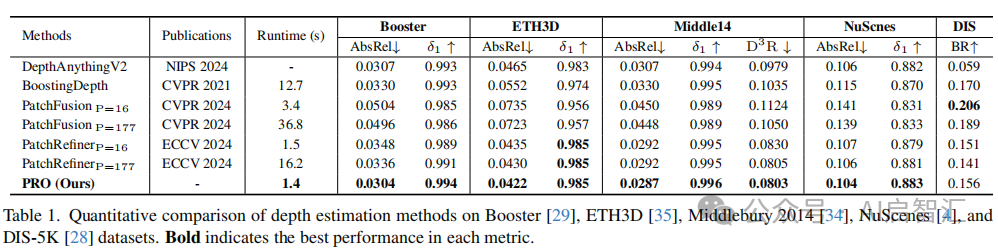
数据集和评估指标:使用 UnrealStereo4K合成数据集训练模型,利用其密集的GT深度。测试数据集包括Booster、ETH3D、Middlebury 2014、NuScenes和DIS-5K。采用边界召回率(BR)评估 DIS-5K 数据集的边缘精度,采用一致性误差(CE)评估深度估计结果在Patch间的一致性。
实现细节:采用预训练的 DepthAnythingV2(DA2)作为基线模型,PRO、PatchFusion 和 PatchRefiner 基于 DA2 重新训练,BoostingDepth 直接使用 DA2。输入\(\Psi\)的分辨率固定为 518×518,使用 GPCT 策略时,相邻 Patch 重叠 224 像素,BFM 中膨胀核大小设为 (10, 20),在 7,592 个 UnrealStereo4K 样本上训练 8 个 epoch,批量大小为 64,在单个 RTX 4090 GPU 上训练耗时 10 小时。
性能比较:测试时将输入图像划分为 4×4 的 Patch 网格,独立细化每个 Patch 深度后重新组装得到最终深度图。
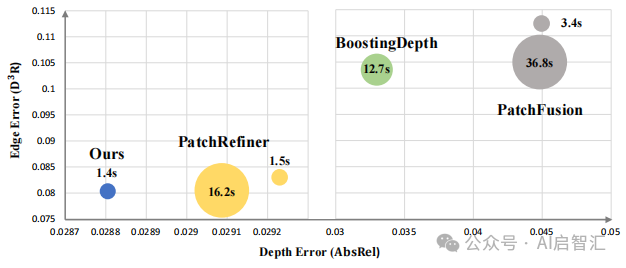
在上图中,PRO 模型在 Middlebury 2014 数据集上,相比其他模型,在边缘误差和深度误差方面表现最优,且推理时间最短。
在Booster数据集上,BFM防止模型过拟合,AbsRel 提高 9.5% ;在一致性方面,PRO 模型的CE改善了85.9% ,优于其他模型。
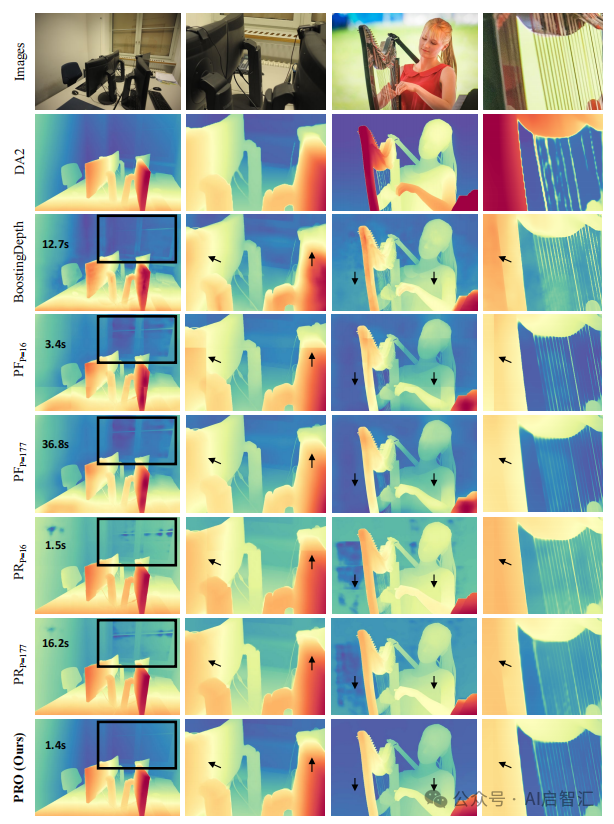
在上图中,定性比较显示PRO模型在处理透明物体和Patch边界时,深度不连续现象最少,推理速度最快。
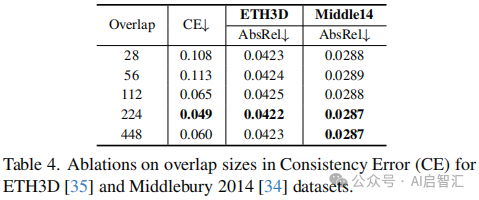
消融研究:研究 GPCT 和 BFM 的有效性,结果表明 BFM 在包含透明物体的 Booster 数据集上显著提高 AbsRel 指标,GPCT 有效降低一致性误差,同时使用两者的模型在大多数指标上表现最佳。研究 GPCT 中不同重叠大小的影响,发现重叠增加一般会降低 CE,但重叠达到 448 像素时,CE 开始增加。结果如下图表。


总结
该论文提出了一种名为 PRO(Patch Refine Once) 的高效零样本单目深度估计框架,旨在解决现有模型在处理高分辨率图像时存在的两大问题:内存消耗高 和 深度不连续。
核心方法:Grouped Patch Consistency Training (GPCT):通过同时处理四个重叠的图像块(patch),并在重叠区域施加一致性损失,减少深度不连续问题,避免测试时的多次集成,提升推理效率。Bias Free Masking (BFM):利用预训练模型的先验知识,识别并掩蔽合成数据集中标注不可靠的区域(如透明物体),防止模型过拟合到合成数据的偏差,提升对真实场景的泛化能力。
以上仅供学习交流参考。
感谢阅读!可微信搜索公众号【AI启智汇】获取更多AI干货分享。


GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)