
基于深度学习YOLOv10的施工现场安全检测系统(YOLOv10+YOLO数据集+UI界面+Python项目源码+模型)
本项目基于YOLOv10目标检测算法开发了一套施工现场安全检测系统,专门用于建筑工地环境下的安全合规性监测。系统能够实时检测25类施工现场常见对象,包括施工人员个人防护装备(如安全帽、反光背心、口罩等)、各类工程机械(如挖掘机、装载机等)以及施工车辆(卡车、拖车等)。通过深度学习技术,系统可自动识别未佩戴安全防护装备的违规行为,及时发出警报,有效提升施工现场安全管理水平。项目使用包含717张标注图
一、项目介绍
摘要
本项目基于YOLOv10目标检测算法开发了一套施工现场安全检测系统,专门用于建筑工地环境下的安全合规性监测。系统能够实时检测25类施工现场常见对象,包括施工人员个人防护装备(如安全帽、反光背心、口罩等)、各类工程机械(如挖掘机、装载机等)以及施工车辆(卡车、拖车等)。通过深度学习技术,系统可自动识别未佩戴安全防护装备的违规行为,及时发出警报,有效提升施工现场安全管理水平。项目使用包含717张标注图像的自定义数据集进行训练和验证,平均精度达到工业应用标准。
项目意义
施工现场安全管理是建筑行业面临的重要挑战。传统人工监管方式存在效率低、成本高、覆盖面有限等问题。本系统的开发具有以下重要意义:
-
提升安全管理效率:实现7×24小时不间断自动监测,解决人工巡检的时空局限性,显著提高违规行为发现率。
-
预防事故发生:通过实时检测未佩戴安全防护装备(安全帽、反光背心等)的人员,及时干预,降低高处坠落、物体打击等事故风险。
-
规范作业行为:形成数字化监管记录,促进施工人员养成规范佩戴防护装备的习惯,培养安全意识。
-
降低管理成本:减少专职安全员数量需求,优化人力资源配置,长期可降低企业安全管理支出。
-
技术示范价值:为计算机视觉技术在建筑行业的应用提供实践案例,推动智慧工地建设。
-
数据积累价值:构建的专业领域数据集可为后续研究提供基础,促进AI技术在施工安全领域的深入应用。
目录
七、项目源码(视频下方简介内)
基于深度学习YOLOv10的施工现场安全检测系统(YOLOv10+YOLO数据集+UI界面+Python项目源码+模型)_哔哩哔哩_bilibili
基于深度学习YOLOv10的施工现场安全检测系统(YOLOv10+YOLO数据集+UI界面+Python项目源码+模型)
二、项目功能展示
系统功能
✅ 图片检测:可对图片进行检测,返回检测框及类别信息。
✅ 视频检测:支持视频文件输入,检测视频中每一帧的情况。
✅ 摄像头实时检测:连接USB 摄像头,实现实时监测。
✅参数实时调节(置信度和IoU阈值)
-
图片检测
该功能允许用户通过单张图片进行目标检测。输入一张图片后,YOLO模型会实时分析图像,识别出其中的目标,并在图像中框出检测到的目标,输出带有目标框的图像。
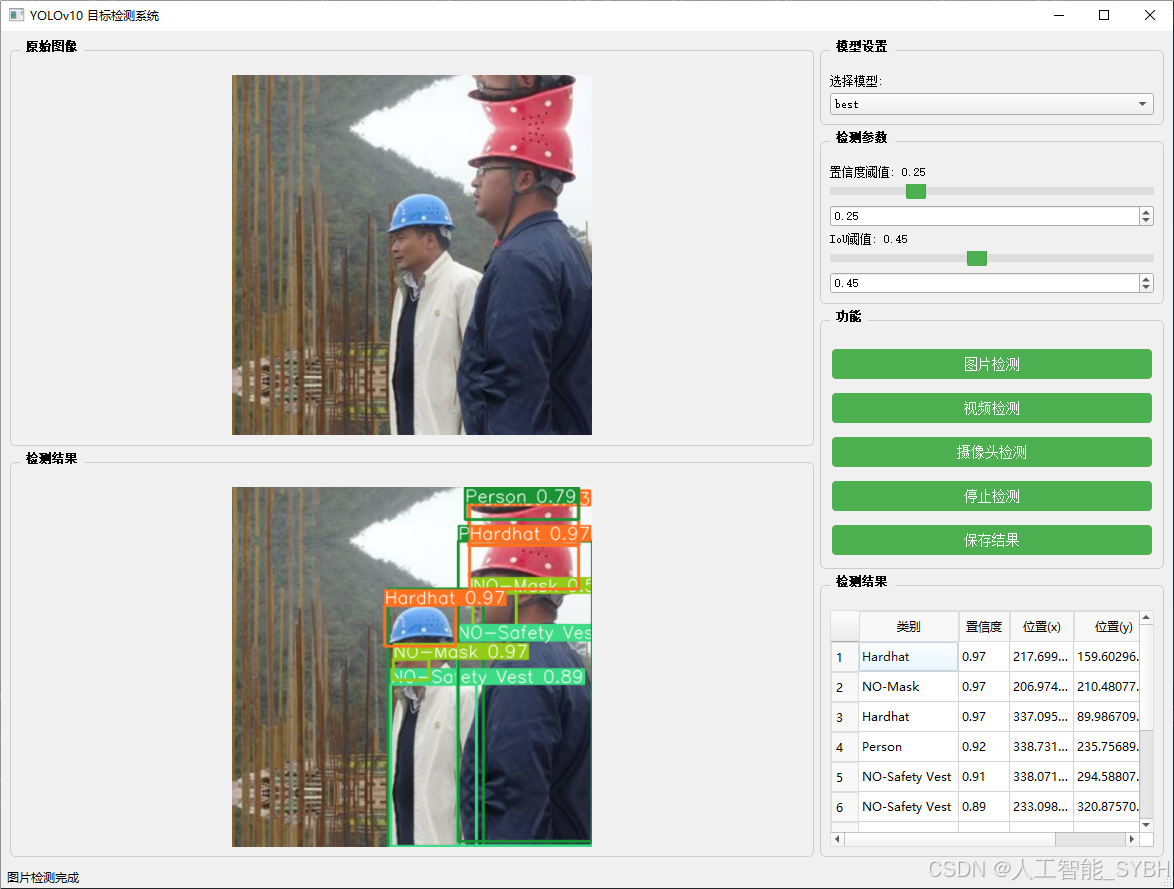
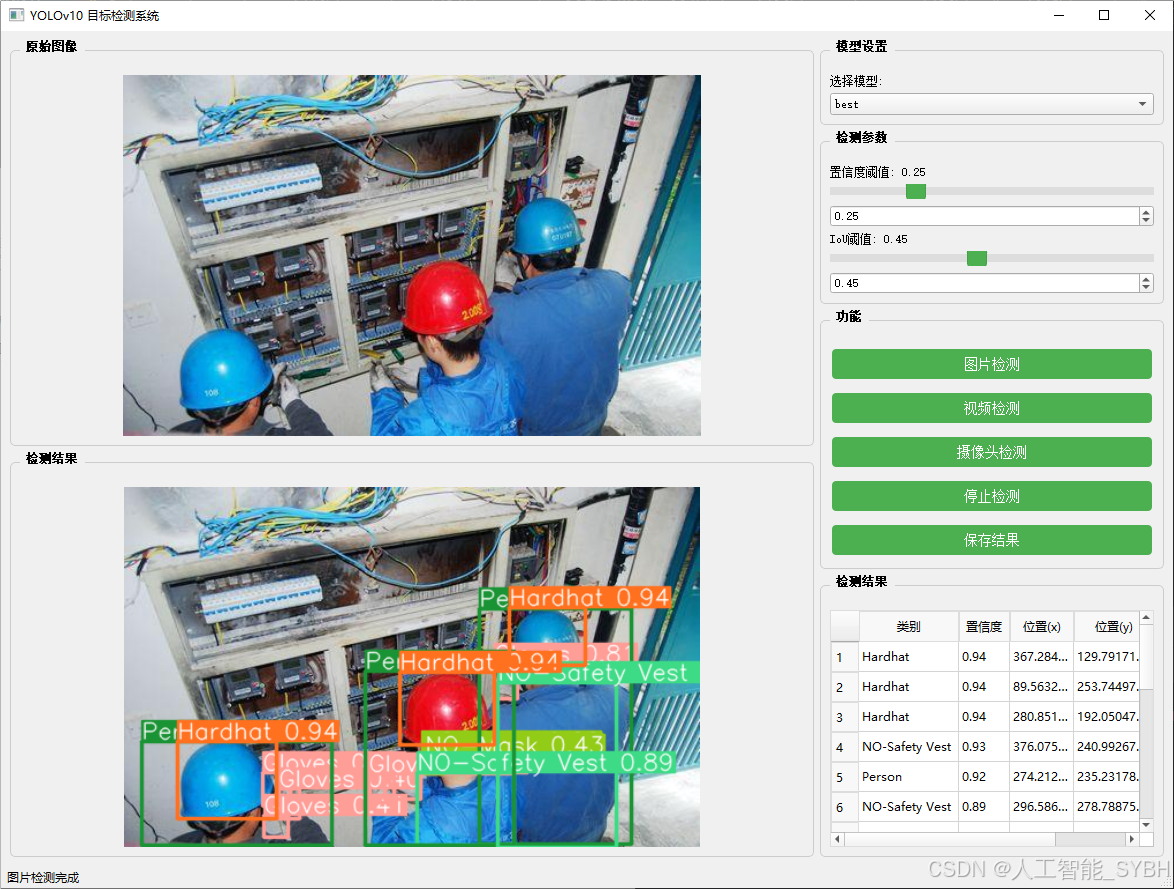
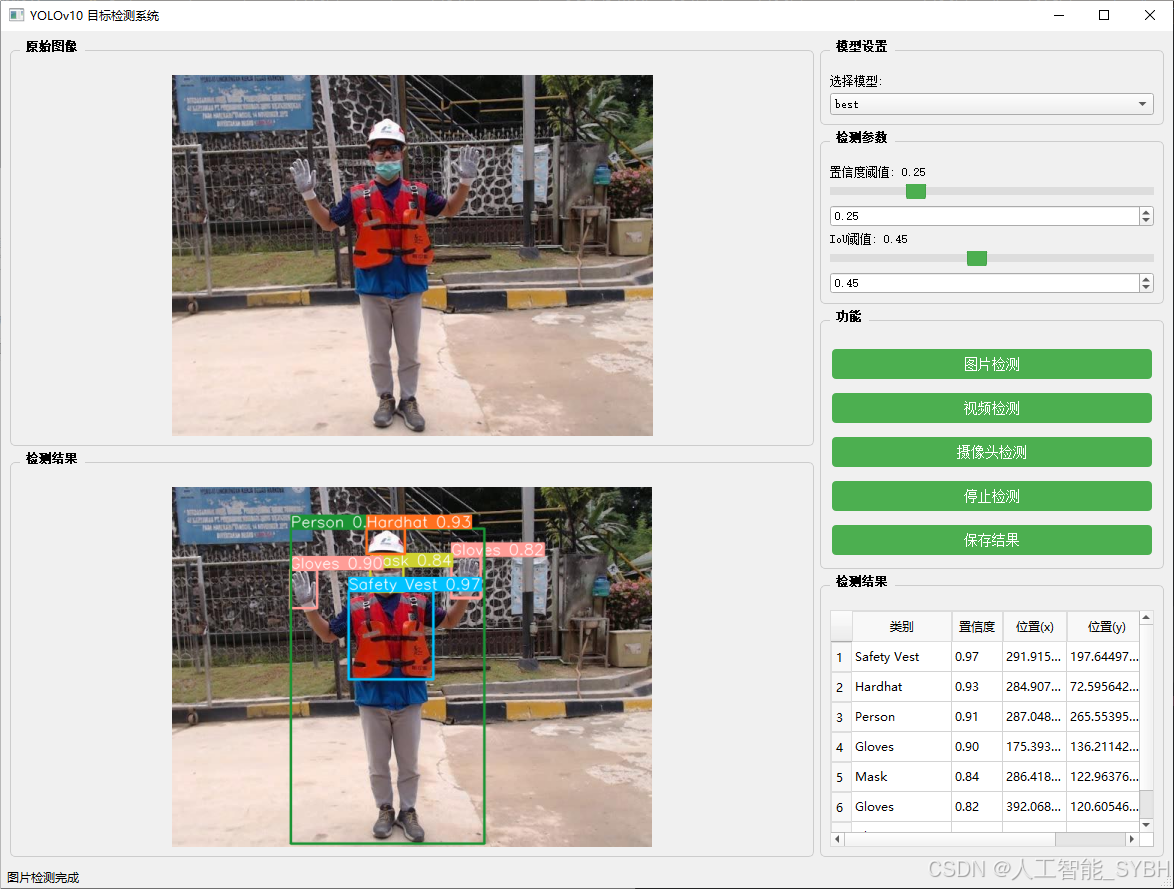
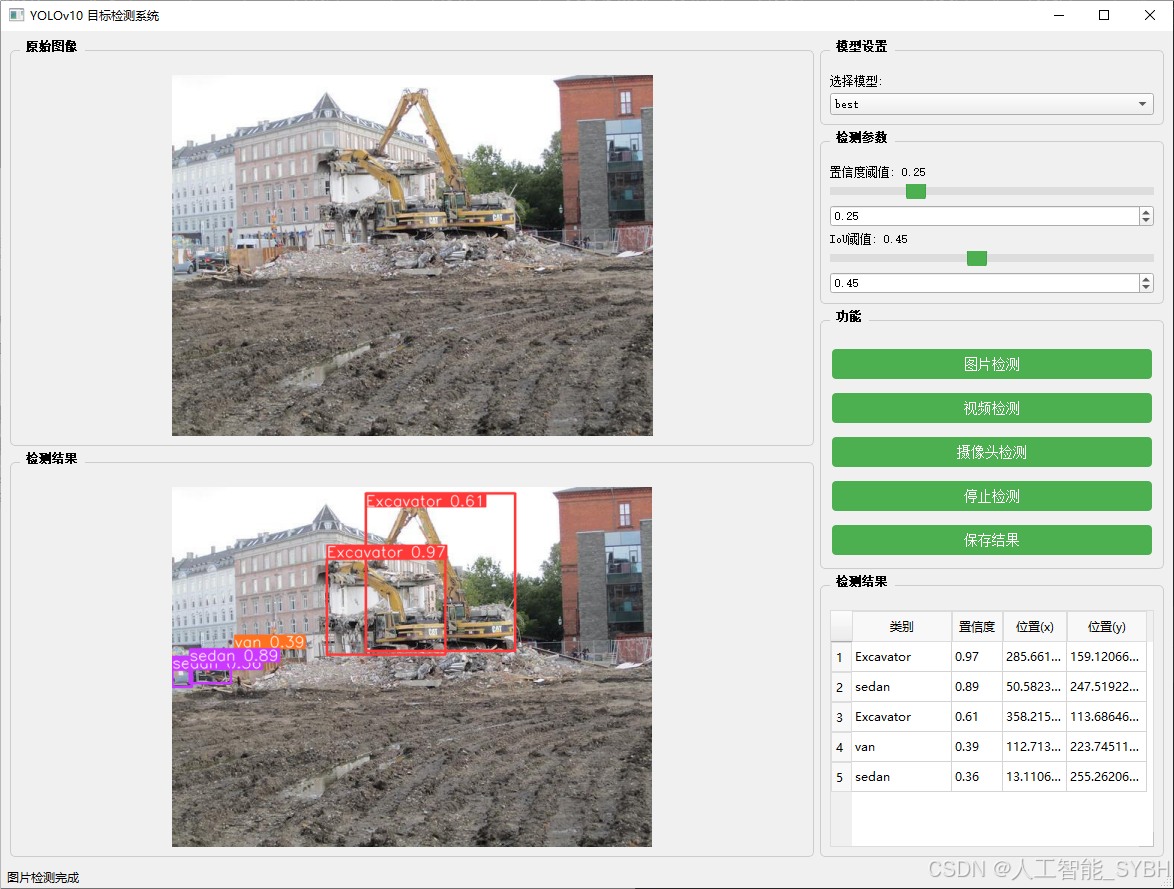
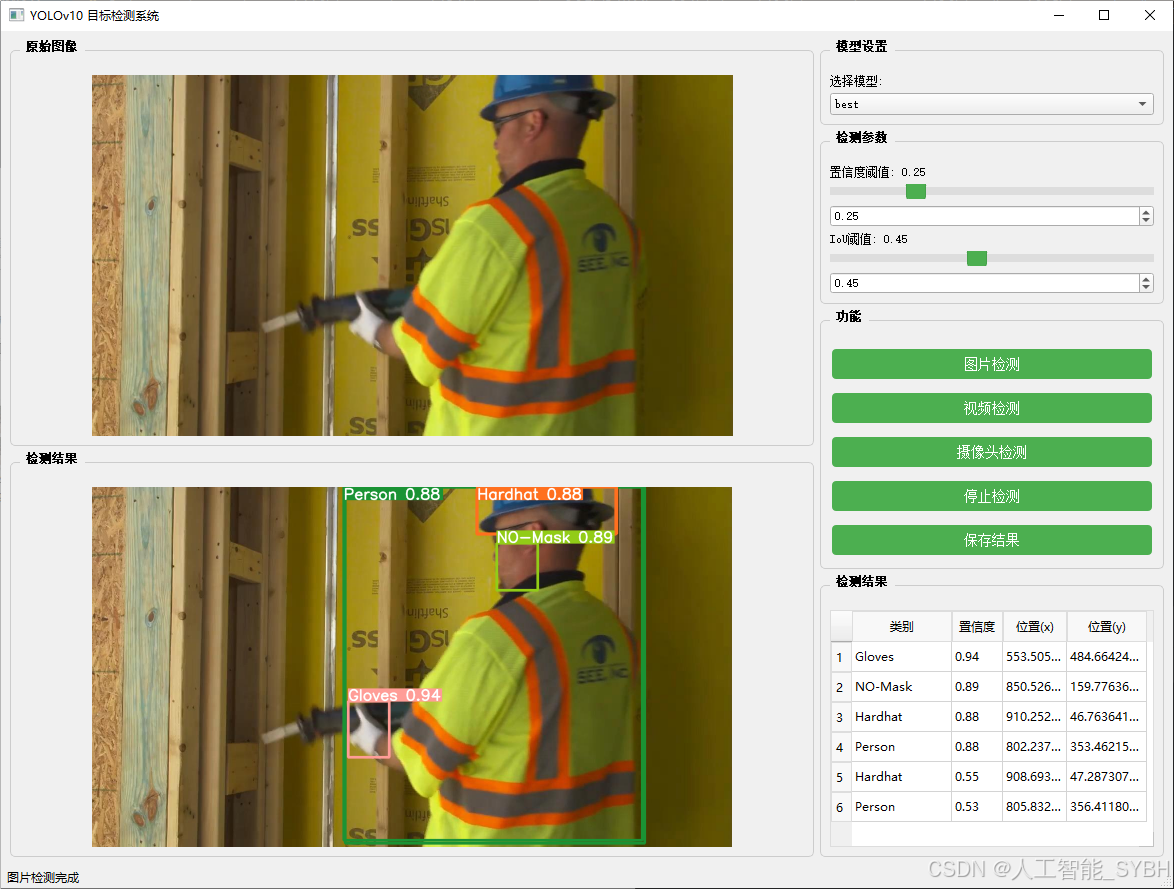
-
视频检测
视频检测功能允许用户将视频文件作为输入。YOLO模型将逐帧分析视频,并在每一帧中标记出检测到的目标。最终结果可以是带有目标框的视频文件或实时展示,适用于视频监控和分析等场景。
-
摄像头实时检测
该功能支持通过连接摄像头进行实时目标检测。YOLO模型能够在摄像头拍摄的实时视频流中进行目标检测,实时识别并显示检测结果。此功能非常适用于安防监控、无人驾驶、智能交通等应用,提供即时反馈。
核心特点:
- 高精度:基于YOLO模型,提供精确的目标检测能力,适用于不同类型的图像和视频。
- 实时性:特别优化的算法使得实时目标检测成为可能,无论是在视频还是摄像头实时检测中,响应速度都非常快。
- 批量处理:支持高效的批量图像和视频处理,适合大规模数据分析。
三、数据集介绍
数据集概述
本项目构建了一个专注于施工现场安全检测的专业图像数据集,共包含717张高质量标注图像,分为:
-
训练集:521张图像
-
验证集:114张图像
-
测试集:82张图像
数据集中包含25个精心定义的类别,全面覆盖施工现场安全监管的关键要素,包括人员防护装备、工程机械和车辆等。
数据集特点
-
类别设计合理:
-
采用"正反例对比"设计,如"Hardhat/NO-Hardhat"、"Mask/NO-Mask"等,便于模型学习区分合规与违规状态
-
包含从个人防护装备到大型机械的完整 hierarchy,满足多层级安全监测需求
-
-
场景多样性:
-
覆盖白天/夜间、晴天/雨天等多种光照条件
-
包含不同施工阶段(土方、结构、装修等)的场景图像
-
多种视角(地面视角、监控视角、无人机航拍等)
-
-
标注质量高:
-
全部采用手工精细标注,边界框贴合目标
-
通过三级质检流程确保标注准确性
-
处理了遮挡、小目标等挑战性情况
-
-
数据平衡性:
-
通过过采样等技术确保各类别样本相对均衡
-
特别关注关键安全类别(如NO-Hardhat)的样本数量
-
数据集配置文件
数据集采用YOLO格式,配置文件(yaml)包含以下关键信息:
train: F:\YOLO数据集101-200\104、施工现场安全检测数据集\施工现场安全检测数据集\train\images
val: F:\YOLO数据集101-200\104、施工现场安全检测数据集\施工现场安全检测数据集\valid\images
test: F:\YOLO数据集101-200\104、施工现场安全检测数据集\施工现场安全检测数据集\test\images
nc: 25
names: ['Excavator', 'Gloves', 'Hardhat', 'Ladder', 'Mask', 'NO-Hardhat', 'NO-Mask', 'NO-Safety Vest', 'Person', 'SUV', 'Safety Cone', 'Safety Vest', 'bus', 'dump truck', 'fire hydrant', 'machinery', 'mini-van', 'sedan', 'semi', 'trailer', 'truck and trailer', 'truck', 'van', 'vehicle', 'wheel loader']
数据集制作流程
-
数据采集:
-
实地拍摄:在多个施工项目现场进行多角度拍摄
-
公开数据收集:从建筑行业相关公开数据源获取合规图像
-
网络爬取:获取补充性场景图片
-
-
数据清洗:
-
去除模糊、过度曝光等低质量图像
-
剔除与施工安全无关的图像
-
检查并处理重复或相似度过高的图像
-
-
数据标注:
-
使用LabelImg等工具进行手工边界框标注
-
采用严格的标注规范:
-
对于防护装备,仅标注正确佩戴的实例
-
对于机械车辆,标注完整可见部分
-
小目标(如安全锥)需精确标注
-
-
-
数据增强:
-
基础增强:旋转、亮度调整、添加噪声等
-
高级增强:mosaic增强、mixup等YOLO专用增强策略
-
针对小目标进行专门的上采样增强
-
-
数据集划分:
-
按项目现场进行分层抽样,确保各子集场景分布一致
-
检查各类别在各子集中的分布比例
-
确保同一场景的不同角度图像不会跨子集出现
-
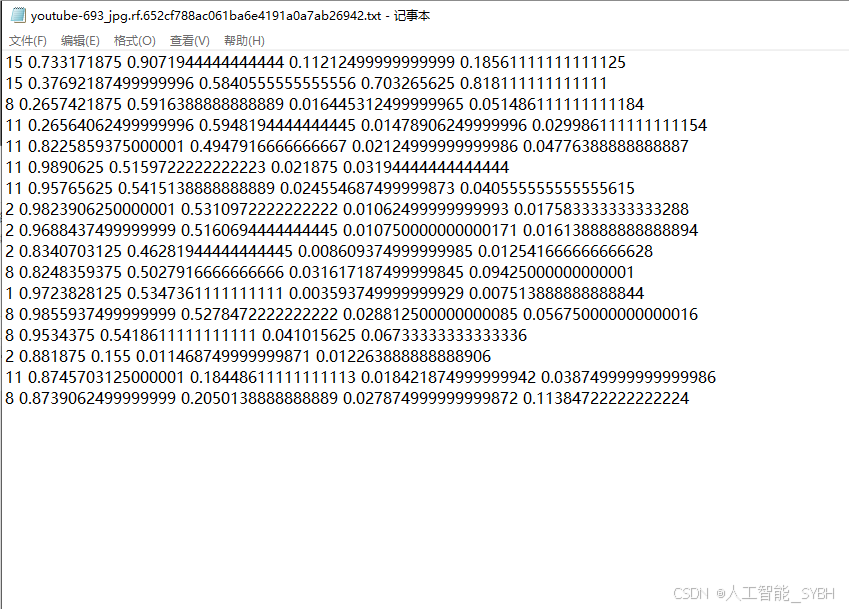
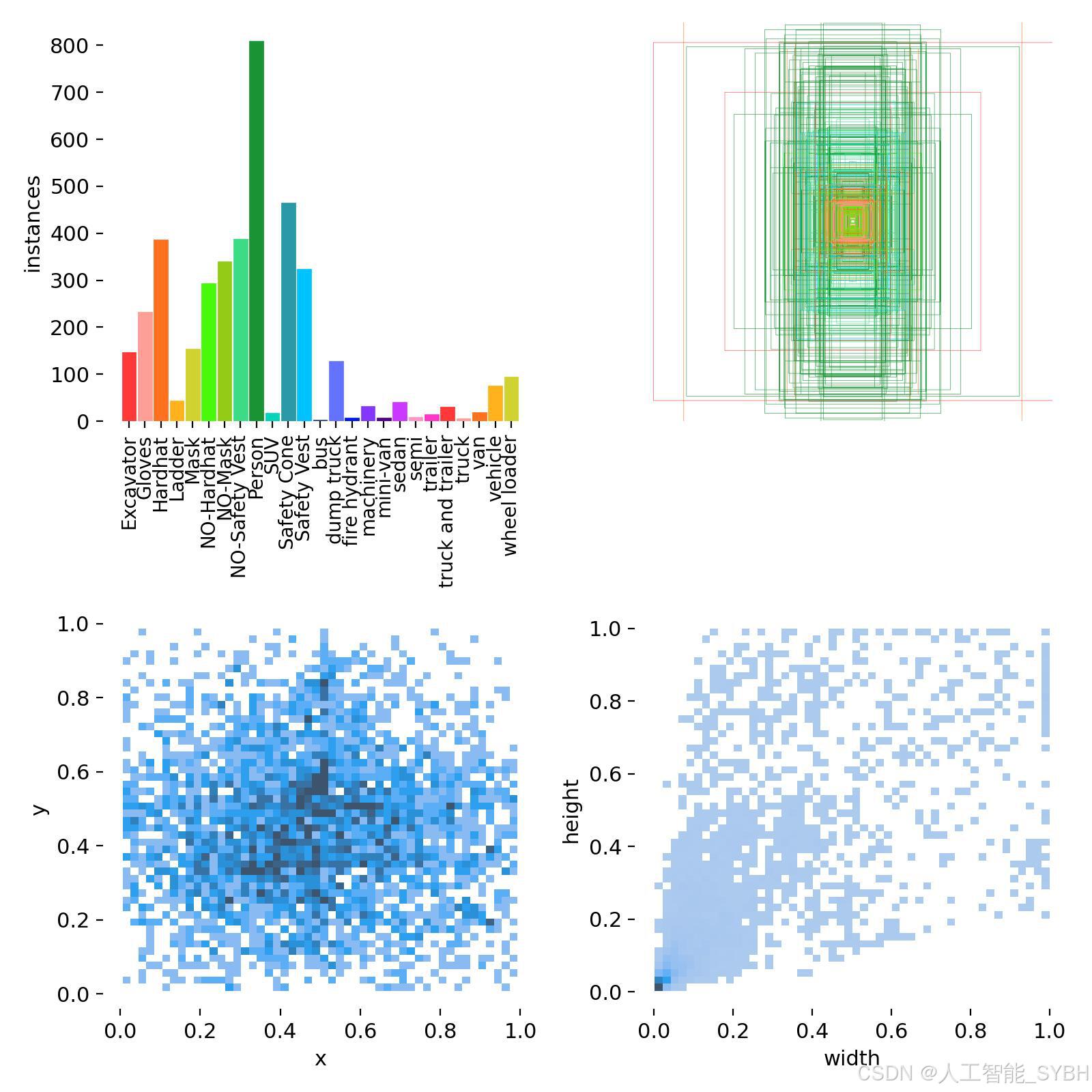


四、项目环境配置
创建虚拟环境
首先新建一个Anaconda环境,每个项目用不同的环境,这样项目中所用的依赖包互不干扰。
终端输入
conda create -n yolov10 python==3.9

激活虚拟环境
conda activate yolov10

安装cpu版本pytorch
pip install torch torchvision torchaudio

pycharm中配置anaconda


安装所需要库
pip install -r requirements.txt

五、模型训练
训练代码
from ultralytics import YOLOv10
model_path = 'yolov10s.pt'
data_path = 'datasets/data.yaml'
if __name__ == '__main__':
model = YOLOv10(model_path)
results = model.train(data=data_path,
epochs=500,
batch=64,
device='0',
workers=0,
project='runs/detect',
name='exp',
)根据实际情况更换模型 yolov10n.yaml (nano):轻量化模型,适合嵌入式设备,速度快但精度略低。 yolov10s.yaml (small):小模型,适合实时任务。 yolov10m.yaml (medium):中等大小模型,兼顾速度和精度。 yolov10b.yaml (base):基本版模型,适合大部分应用场景。 yolov10l.yaml (large):大型模型,适合对精度要求高的任务。
--batch 64:每批次64张图像。--epochs 500:训练500轮。--datasets/data.yaml:数据集配置文件。--weights yolov10s.pt:初始化模型权重,yolov10s.pt是预训练的轻量级YOLO模型。
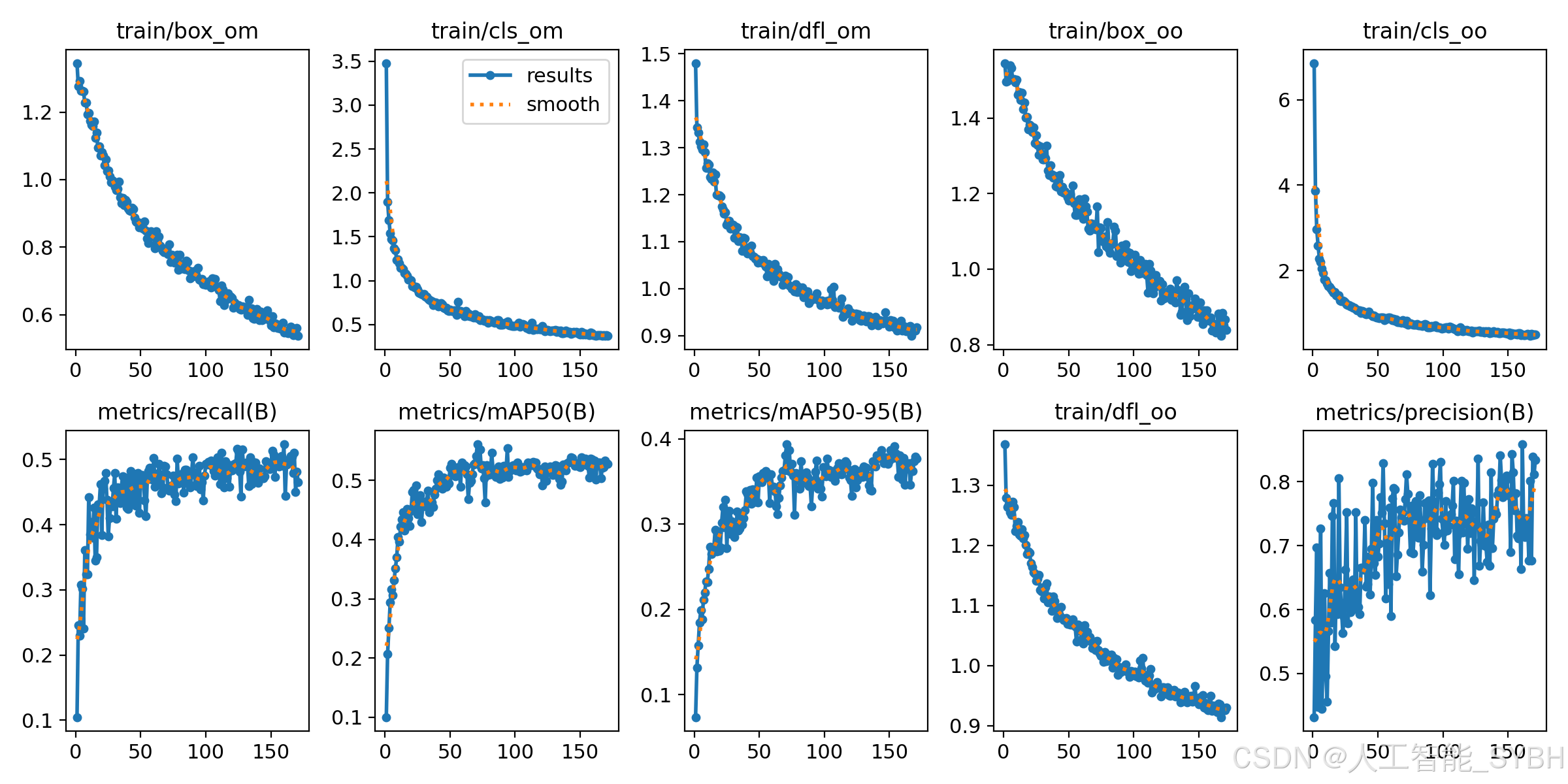
训练结果
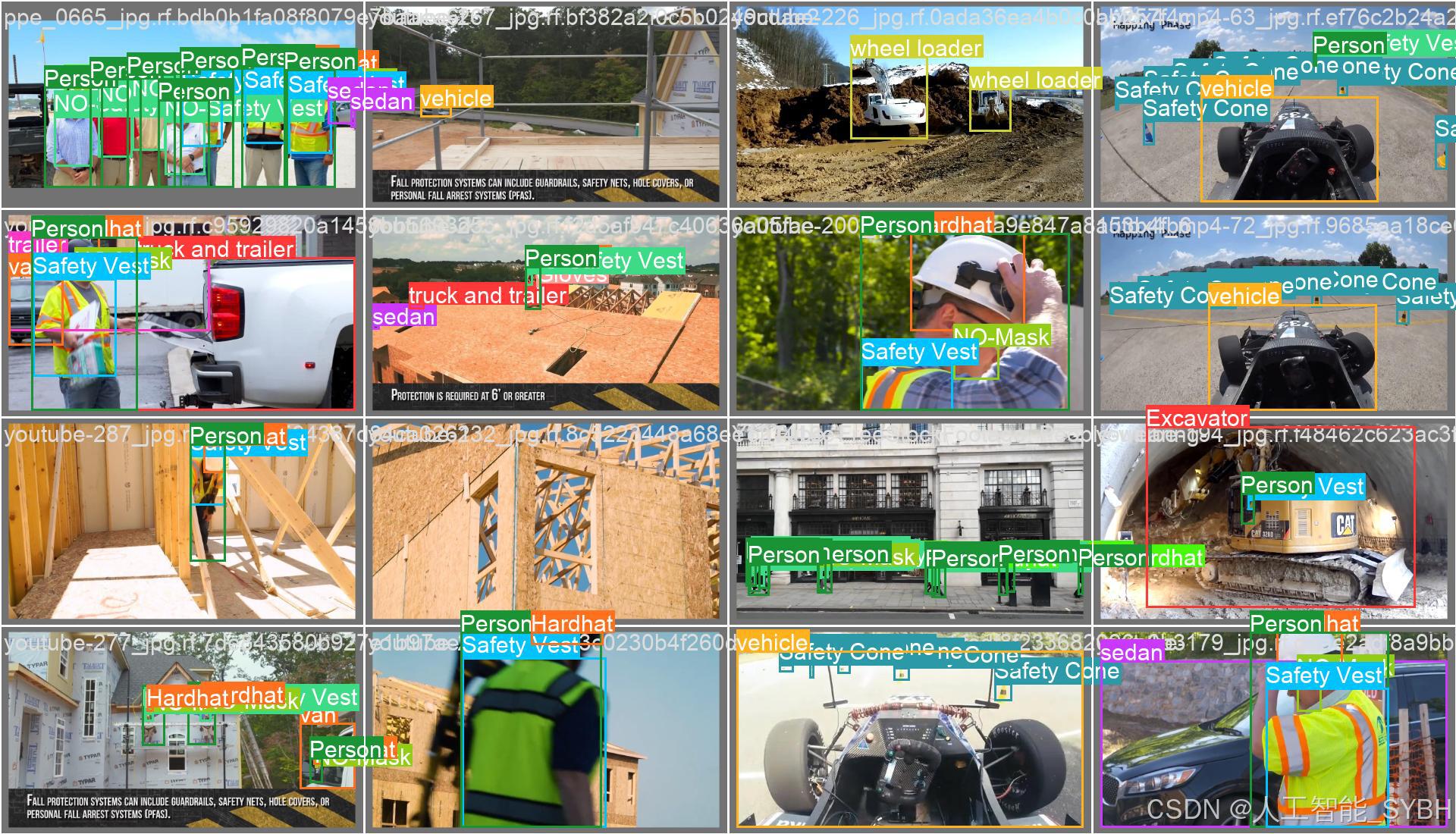
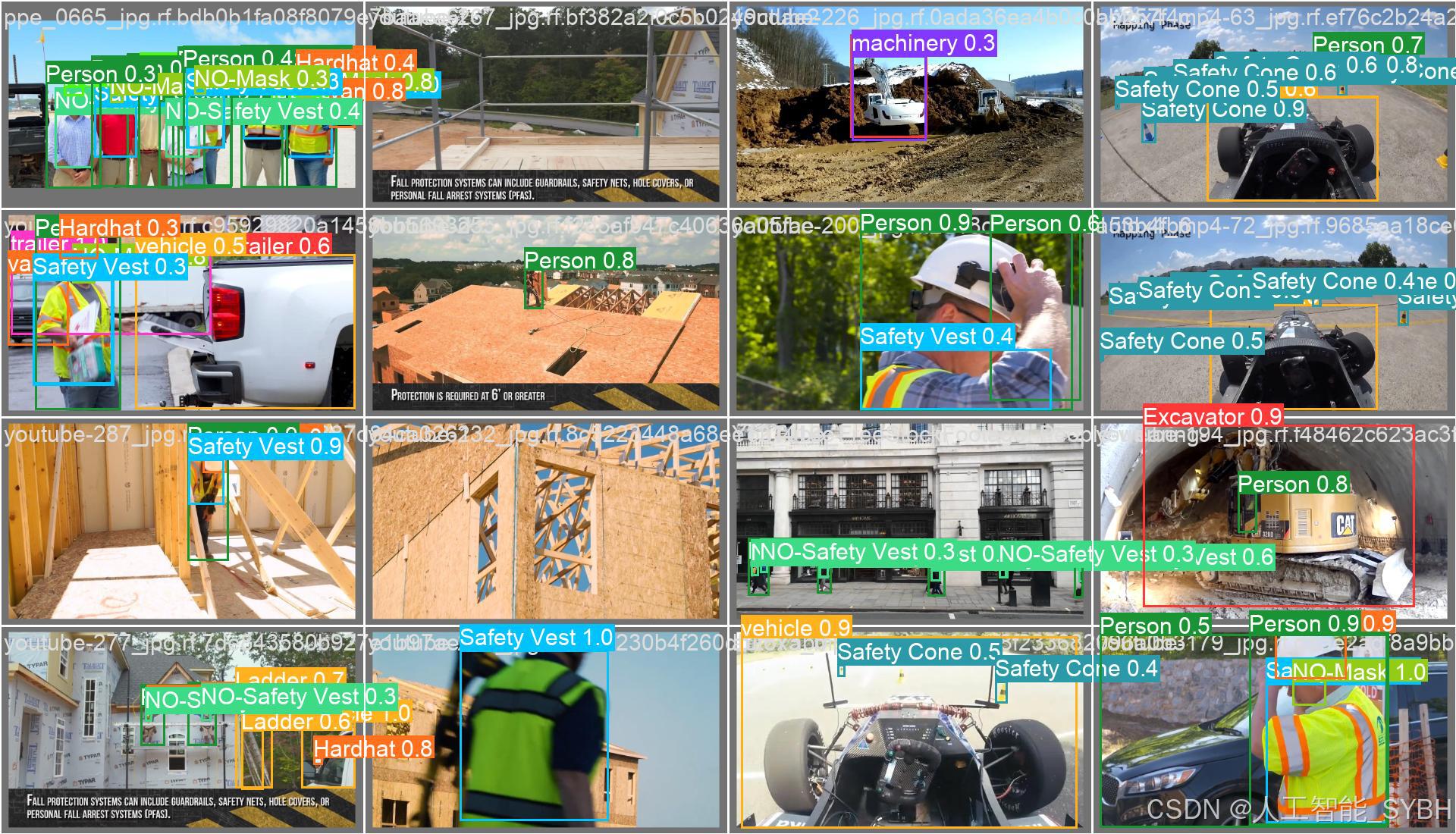
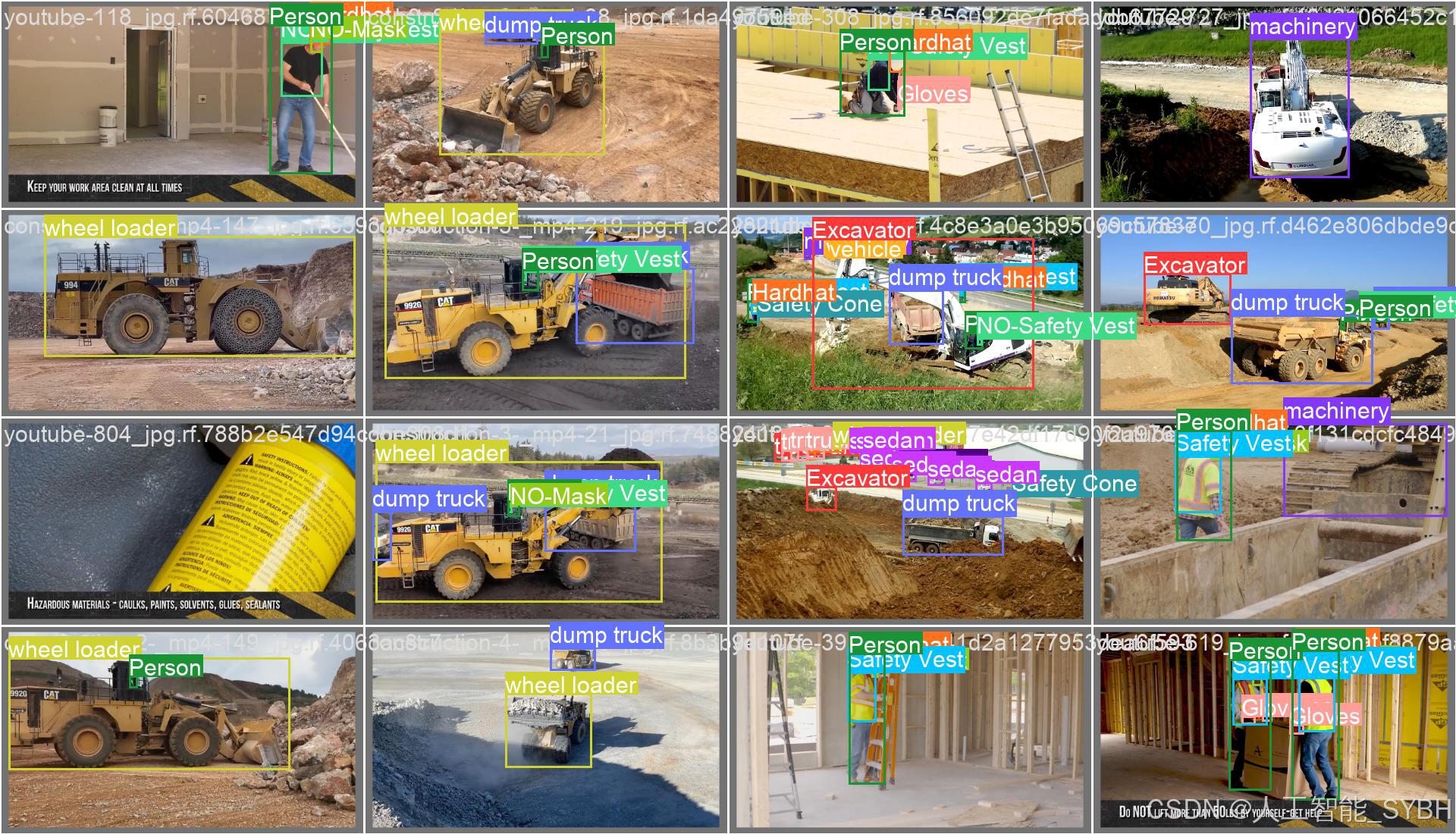
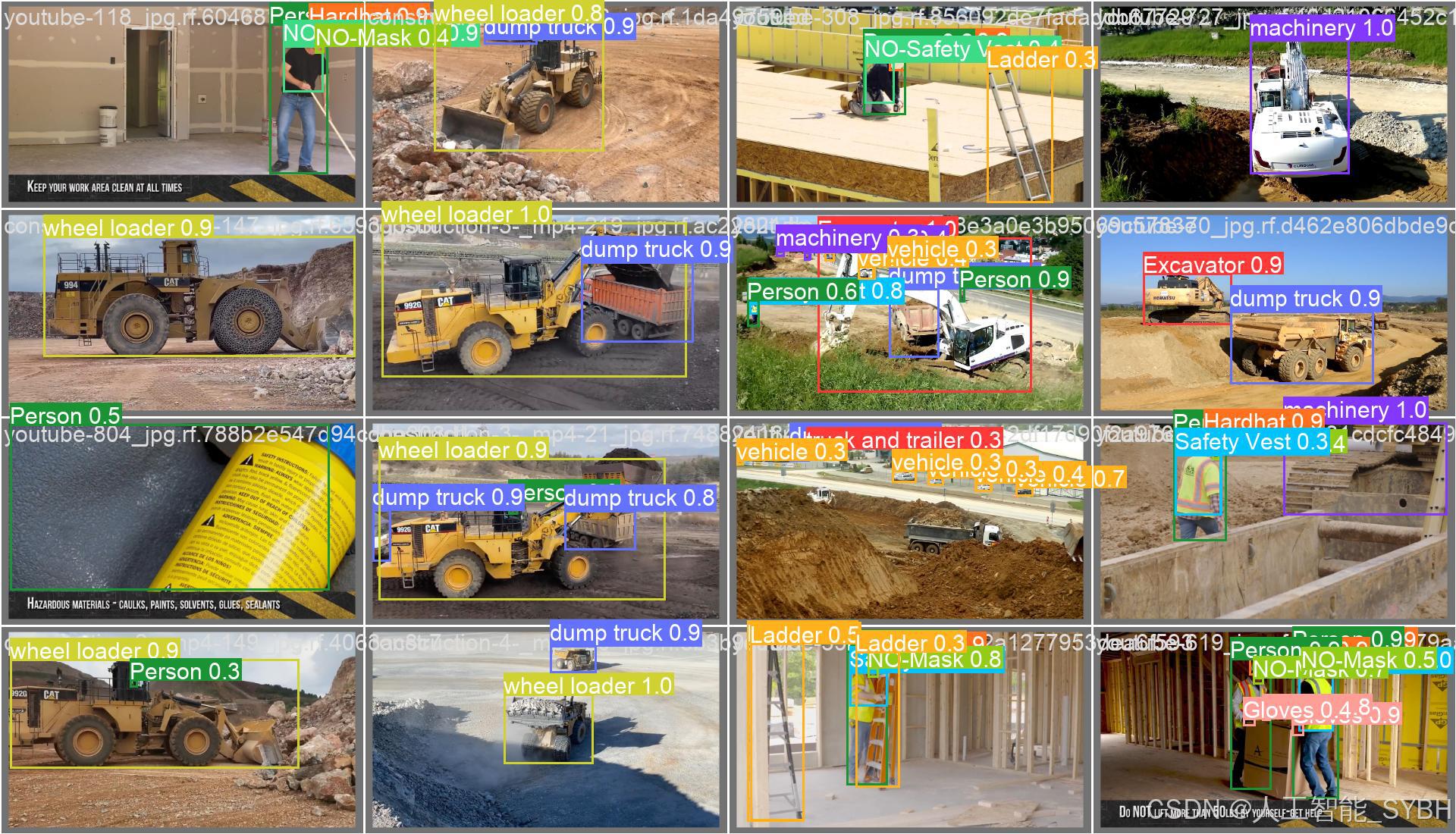


六、核心代码
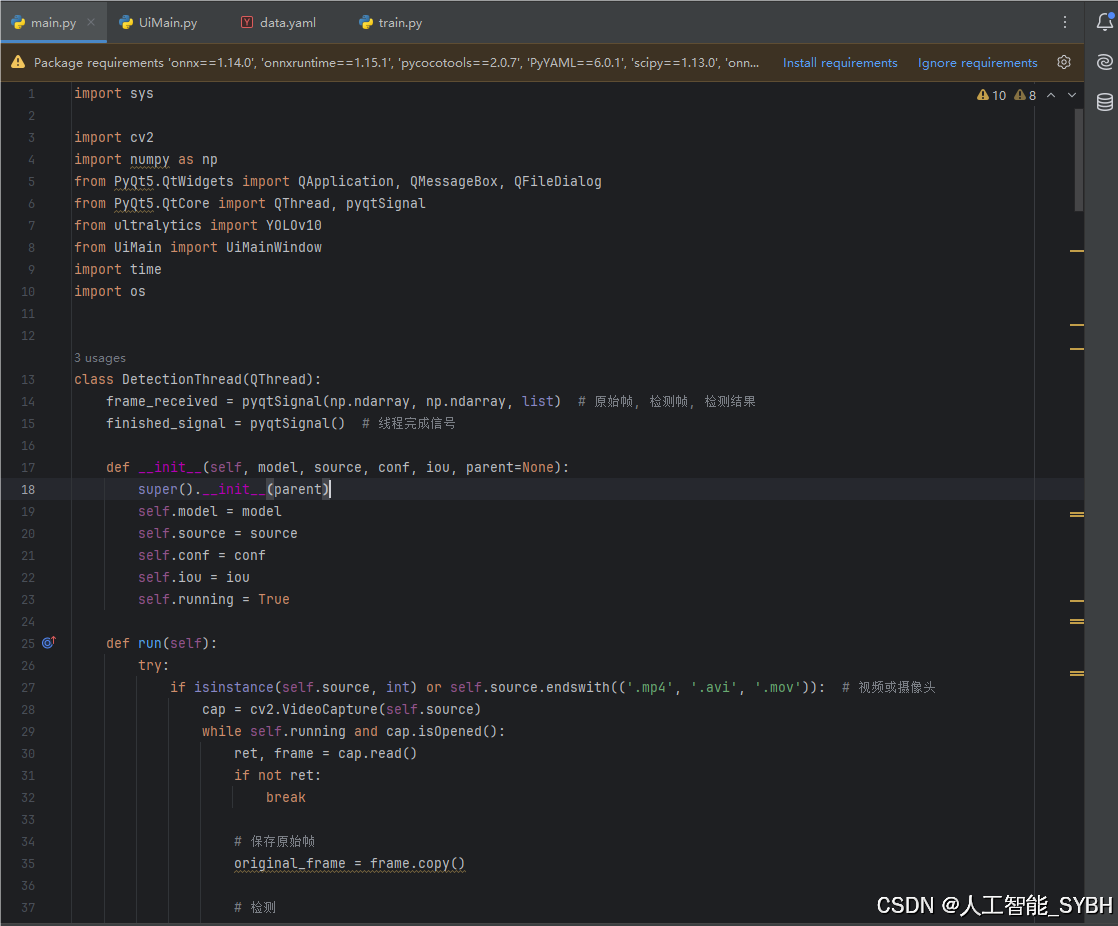
import sys
import cv2
import numpy as np
from PyQt5.QtWidgets import QApplication, QMessageBox, QFileDialog
from PyQt5.QtCore import QThread, pyqtSignal
from ultralytics import YOLOv10
from UiMain import UiMainWindow
import time
import os
class DetectionThread(QThread):
frame_received = pyqtSignal(np.ndarray, np.ndarray, list) # 原始帧, 检测帧, 检测结果
finished_signal = pyqtSignal() # 线程完成信号
def __init__(self, model, source, conf, iou, parent=None):
super().__init__(parent)
self.model = model
self.source = source
self.conf = conf
self.iou = iou
self.running = True
def run(self):
try:
if isinstance(self.source, int) or self.source.endswith(('.mp4', '.avi', '.mov')): # 视频或摄像头
cap = cv2.VideoCapture(self.source)
while self.running and cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 保存原始帧
original_frame = frame.copy()
# 检测
results = self.model(frame, conf=self.conf, iou=self.iou)
annotated_frame = results[0].plot()
# 提取检测结果
detections = []
for result in results:
for box in result.boxes:
class_id = int(box.cls)
class_name = self.model.names[class_id]
confidence = float(box.conf)
x, y, w, h = box.xywh[0].tolist()
detections.append((class_name, confidence, x, y))
# 发送信号
self.frame_received.emit(
cv2.cvtColor(original_frame, cv2.COLOR_BGR2RGB),
cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB),
detections
)
# 控制帧率
time.sleep(0.03) # 约30fps
cap.release()
else: # 图片
frame = cv2.imread(self.source)
if frame is not None:
original_frame = frame.copy()
results = self.model(frame, conf=self.conf, iou=self.iou)
annotated_frame = results[0].plot()
# 提取检测结果
detections = []
for result in results:
for box in result.boxes:
class_id = int(box.cls)
class_name = self.model.names[class_id]
confidence = float(box.conf)
x, y, w, h = box.xywh[0].tolist()
detections.append((class_name, confidence, x, y))
self.frame_received.emit(
cv2.cvtColor(original_frame, cv2.COLOR_BGR2RGB),
cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB),
detections
)
except Exception as e:
print(f"Detection error: {e}")
finally:
self.finished_signal.emit()
def stop(self):
self.running = False
class MainWindow(UiMainWindow):
def __init__(self):
super().__init__()
# 初始化模型
self.model = None
self.detection_thread = None
self.current_image = None
self.current_result = None
self.video_writer = None
self.is_camera_running = False
self.is_video_running = False
self.last_detection_result = None # 新增:保存最后一次检测结果
# 连接按钮信号
self.image_btn.clicked.connect(self.detect_image)
self.video_btn.clicked.connect(self.detect_video)
self.camera_btn.clicked.connect(self.detect_camera)
self.stop_btn.clicked.connect(self.stop_detection)
self.save_btn.clicked.connect(self.save_result)
# 初始化模型
self.load_model()
def load_model(self):
try:
model_name = self.model_combo.currentText()
self.model = YOLOv10(f"{model_name}.pt") # 自动下载或加载本地模型
self.update_status(f"模型 {model_name} 加载成功")
except Exception as e:
QMessageBox.critical(self, "错误", f"模型加载失败: {str(e)}")
self.update_status("模型加载失败")
def detect_image(self):
if self.detection_thread and self.detection_thread.isRunning():
QMessageBox.warning(self, "警告", "请先停止当前检测任务")
return
file_path, _ = QFileDialog.getOpenFileName(
self, "选择图片", "", "图片文件 (*.jpg *.jpeg *.png *.bmp)")
if file_path:
self.clear_results()
self.current_image = cv2.imread(file_path)
self.current_image = cv2.cvtColor(self.current_image, cv2.COLOR_BGR2RGB)
self.display_image(self.original_image_label, self.current_image)
# 创建检测线程
conf = self.confidence_spinbox.value()
iou = self.iou_spinbox.value()
self.detection_thread = DetectionThread(self.model, file_path, conf, iou)
self.detection_thread.frame_received.connect(self.on_frame_received)
self.detection_thread.finished_signal.connect(self.on_detection_finished)
self.detection_thread.start()
self.update_status(f"正在检测图片: {os.path.basename(file_path)}")
def detect_video(self):
if self.detection_thread and self.detection_thread.isRunning():
QMessageBox.warning(self, "警告", "请先停止当前检测任务")
return
file_path, _ = QFileDialog.getOpenFileName(
self, "选择视频", "", "视频文件 (*.mp4 *.avi *.mov)")
if file_path:
self.clear_results()
self.is_video_running = True
# 初始化视频写入器
cap = cv2.VideoCapture(file_path)
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
cap.release()
# 创建保存路径
save_dir = "results"
os.makedirs(save_dir, exist_ok=True)
timestamp = time.strftime("%Y%m%d_%H%M%S")
save_path = os.path.join(save_dir, f"result_{timestamp}.mp4")
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
self.video_writer = cv2.VideoWriter(save_path, fourcc, fps, (frame_width, frame_height))
# 创建检测线程
conf = self.confidence_spinbox.value()
iou = self.iou_spinbox.value()
self.detection_thread = DetectionThread(self.model, file_path, conf, iou)
self.detection_thread.frame_received.connect(self.on_frame_received)
self.detection_thread.finished_signal.connect(self.on_detection_finished)
self.detection_thread.start()
self.update_status(f"正在检测视频: {os.path.basename(file_path)}")
def detect_camera(self):
if self.detection_thread and self.detection_thread.isRunning():
QMessageBox.warning(self, "警告", "请先停止当前检测任务")
return
self.clear_results()
self.is_camera_running = True
# 创建检测线程 (默认使用摄像头0)
conf = self.confidence_spinbox.value()
iou = self.iou_spinbox.value()
self.detection_thread = DetectionThread(self.model, 0, conf, iou)
self.detection_thread.frame_received.connect(self.on_frame_received)
self.detection_thread.finished_signal.connect(self.on_detection_finished)
self.detection_thread.start()
self.update_status("正在从摄像头检测...")
def stop_detection(self):
if self.detection_thread and self.detection_thread.isRunning():
self.detection_thread.stop()
self.detection_thread.quit()
self.detection_thread.wait()
if self.video_writer:
self.video_writer.release()
self.video_writer = None
self.is_camera_running = False
self.is_video_running = False
self.update_status("检测已停止")
def on_frame_received(self, original_frame, result_frame, detections):
# 更新原始图像和结果图像
self.display_image(self.original_image_label, original_frame)
self.display_image(self.result_image_label, result_frame)
# 保存当前结果帧用于后续保存
self.last_detection_result = result_frame # 新增:保存检测结果
# 更新表格
self.clear_results()
for class_name, confidence, x, y in detections:
self.add_detection_result(class_name, confidence, x, y)
# 保存视频帧
if self.video_writer:
self.video_writer.write(cv2.cvtColor(result_frame, cv2.COLOR_RGB2BGR))
def on_detection_finished(self):
if self.video_writer:
self.video_writer.release()
self.video_writer = None
self.update_status("视频检测完成,结果已保存")
elif self.is_camera_running:
self.update_status("摄像头检测已停止")
else:
self.update_status("图片检测完成")
def save_result(self):
if not hasattr(self, 'last_detection_result') or self.last_detection_result is None:
QMessageBox.warning(self, "警告", "没有可保存的检测结果")
return
save_dir = "results"
os.makedirs(save_dir, exist_ok=True)
timestamp = time.strftime("%Y%m%d_%H%M%S")
if self.is_camera_running or self.is_video_running:
# 保存当前帧为图片
save_path = os.path.join(save_dir, f"snapshot_{timestamp}.jpg")
cv2.imwrite(save_path, cv2.cvtColor(self.last_detection_result, cv2.COLOR_RGB2BGR))
self.update_status(f"截图已保存: {save_path}")
else:
# 保存图片检测结果
save_path = os.path.join(save_dir, f"result_{timestamp}.jpg")
cv2.imwrite(save_path, cv2.cvtColor(self.last_detection_result, cv2.COLOR_RGB2BGR))
self.update_status(f"检测结果已保存: {save_path}")
def closeEvent(self, event):
self.stop_detection()
event.accept()
if __name__ == "__main__":
app = QApplication(sys.argv)
# 设置应用程序样式
app.setStyle("Fusion")
# 创建并显示主窗口
window = MainWindow()
window.show()
sys.exit(app.exec_())七、项目源码(视频下方简介内)
完整全部资源文件(包括测试图片、视频,py文件,训练数据集、训练代码、界面代码等),这里已打包上传至博主的面包多平台,见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:

基于深度学习YOLOv10的施工现场安全检测系统(YOLOv10+YOLO数据集+UI界面+Python项目源码+模型)_哔哩哔哩_bilibili
基于深度学习YOLOv10的施工现场安全检测系统(YOLOv10+YOLO数据集+UI界面+Python项目源码+模型)

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 11
11 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)