
静态网页爬取xpath模块(第六节课内容总结)
本文介绍了使用Python进行网页数据爬取与解析的若干实例。通过lxml库的XPath技术,实现了从人邮图书网站、酷狗音乐榜单和起点中文网等平台提取结构化数据,包括书名、作者、价格、歌曲名、小说简介等信息。关键点包括:1)使用requests获取网页内容;2)通过XPath精准定位节点并提取数据;3)采用csv/pandas保存数据;4)处理编码问题(utf-8-sig)和异常情况。文章还总结了X
1.主要代码:
import csv
from lxml import etree
# 1. 读取本地保存的网页(确保 debug.html 在同一目录)
html = open('debug.html', encoding='utf-8').read()
root = etree.HTML(html)
rows = []
# 2. 循环每一本书的 <li>
for li in root.xpath('//*[@id="book-img-text"]/ul/li'):
try:
# 书名(对应你复制的 h2/a)
title = li.xpath('./div[2]/h2/a/text()')[0].strip()
# 作者(对应你复制的 p[1]/a[1])
author = li.xpath('./div[2]/p[1]/a[1]/text()')[0].strip()
# 封面(对应你复制的 div[1]/a/img)
cover = li.xpath('./div[1]/a/img/@src')[0].strip()
# 简介(根据你页面结构,通常在同层 p,自行微调)
intro = li.xpath('./div[2]/p[2]/text()')[0].strip()
# 更新时间(若页面有,自行微调)
utime = li.xpath('./div[2]/p[3]/span/text()')[0].strip()
except IndexError:
# 如果某本书缺字段,留空
title = author = cover = intro = utime = ''
rows.append([title, author, intro, utime, cover])
# 3. 写入 CSV
with open('novels.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(['title', 'author', 'intro', 'update_time', 'cover'])
writer.writerows(rows)
print('已写入', len(rows), '条记录到 novels.csv')1.代码技术点:
1.文件操作
open(path, encoding='utf-8') → 读本地 HTML
open(path, 'w', newline='', encoding='utf-8-sig') → 写 CSV
2.解析 HTML
lxml.etree.HTML(str) → 把字符串变成可 XPath 的树对象
element.xpath('xpath 表达式') → 返回列表
3.写 CSV
csv.writer(file_obj) → 创建 writer
writer.writerow(headers) → 写一行表头
writer.writerows(list_of_rows) → 批量写多行
4.异常处理
try / except IndexError → 处理 XPath 结果为空
2.知识点(可迁移的理论)
| 场景 | 关键概念 | 一句话解释 |
|---|---|---|
| HTML 解析 | XPath 语法 | 用路径表达式在 XML/HTML 树中精确定位节点;以 / 为层级,// 为任意深度,@attr 取属性,text() 取文本 |
| CSV 文件 | newline='' | 防止 Windows 出现空行;官方推荐写法 |
| 编码 | utf-8-sig | 带 BOM 的 UTF-8,让 Excel 中文不乱码 |
| 列表索引 | [0] | XPath 永远返回 list;取不到元素时下标越界会抛 IndexError |
| strip() | 字符串方法 | 去掉首尾空白符(空格、换行、制表符) |
3.易错点/常见坑
1.XPath 层级写错 → 返回空列表,IndexError 触发
→ XPath,再手动改相对路径 ./ 开头。
2.Windows 直接写 CSV 出现空行 → 忘了加 newline=''
3.Excel 打开 CSV 中文乱码 → 忘了 encoding='utf-8-sig'
4.图片地址是相对路径 → 拿到的 cover 只有 /img/xxx.jpg,需要 urljoin 补全
5.网站改版 → 只要改 XPath;其余代码不用动,这是「表现与逻辑分离」的好处
2.复现代码1(人邮图书爬取案例):
主要代码:
import requests
import csv
from lxml import etree
def get_html(url):
try:
r = requests.get(url)
r.encoding = r.apparent_encoding
r.raise_for_status()
return r.text
except Exception as error:
print(error)
result_list = [] # 存放爬取内容
def parse(html):
html = etree.HTML(html)
for row in html.xpath('//*[@id="tag-book"]/div/ul/li/div[2]'):
name = row.xpath('h4/a/text()')[0] # 书名
url = row.xpath('h4/a/@href')[0] # 链接
author = row.xpath('div/span/text()')[0].strip() # 作者
price = row.xpath('span/span/text()')[0] # 价格
item = [name, url, author, price]
result_list.append(item)
return result_list
def save(item, path):
with open(path, "w+", newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(["书名", "链接", "作者", "价格"])
writer.writerows(item)
if __name__ == "__main__":
base_url = "https://www.ryjiaoyu.com/tag/details/7?page={}"
page = 1
while len(result_list) < 30: # 够30条为止
url = base_url.format(page)
html = get_html(url)
if not html:
break
parse(html)
page += 1
save(result_list[:30], "./test.csv") # 只写前30条实现结果:
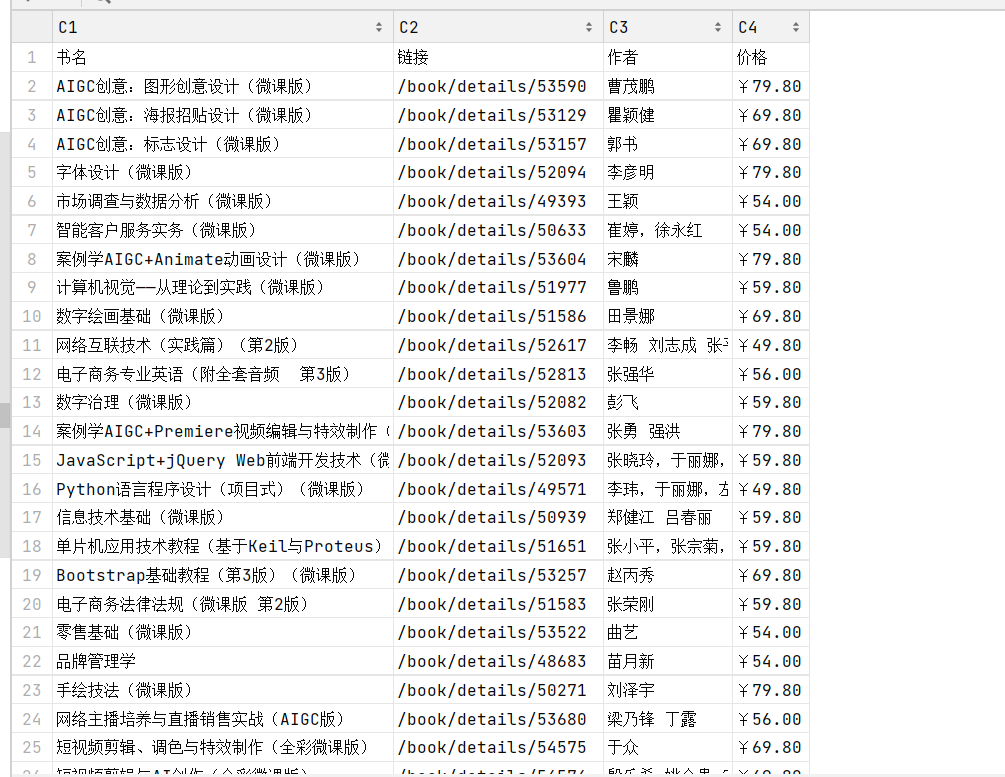
3.复现代码2(酷狗音乐华语新歌榜爬取案例):
主要代码:
import requests
def get_html(url, time=30):
try:
r = requests.get(url, timeout=time) # 带超时设置的GET请求
r.encoding = r.apparent_encoding # 设置编码
r.raise_for_status() # 非200状态码抛出异常
return r.text # 返回网页文本
except Exception as error:
print(error)
from lxml import etree
def parser(html):
doc = etree.HTML(html) # 解析HTML
title = doc.xpath("//div[@id='rankWrap']//li/@title") # 歌曲名
href = doc.xpath("//div[@id='rankWrap']//li/a/@href") # 播放链接
out_dict = {"歌曲": title, "地址": href} # 用字典存储
return out_dict
import pandas
def save_dict2csv(item, path):
df = pandas.DataFrame(item) # 转换为DataFrame
df.to_csv(path) # 保存为CSVv
if __name__ == "__main__":
url = "http://www.bspider.top/kugou/"
html = get_html(url) # 获取网页数据
out_dict = parser(html) # 解析数据
save_dict2csv(out_dict, "test music.csv") # 保存数据实现结果:
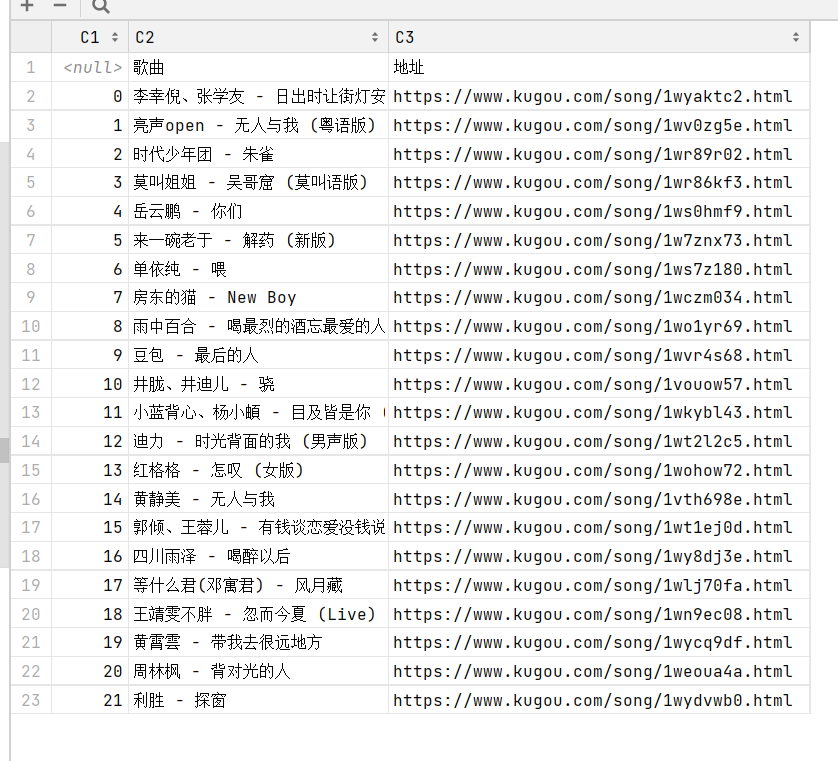
4.复现代码3(起点中文网原创风云榜爬取案例):
主要代码:
import requests
def get_html(url, time=30):
try:
r = requests.get(url, timeout=time) # 带超时设置的GET请求
r.encoding = r.apparent_encoding # 设置编码
r.raise_for_status() # 非200状态码抛出异常
return r.text # 返回网页文本
except Exception as error:
print(error)
from lxml import etree
def parser(html):
doc = etree.HTML(html) # 解析HTML
out_list = [] # 存储解析结果
# 遍历每个小说节点
for row in doc.xpath("//*[@class='book-img-text']//li/*[@class='book-mid-info']"):
row_data = [
row.xpath("h4/a/text()")[0], # 小说名称
row.xpath("p[@class='author']/a/text()")[0], # 作者
row.xpath("p[2]/text()")[0].strip(), # 摘要(去除空格)
row.xpath("p[@class='update']/span/text()")[0] # 更新日期
]
out_list.append(row_data)
return out_list
import csv
def save_csv(item, path):
# 打开文件(utf-8编码,避免中文乱码)
with open(path, "at", newline='', encoding="utf-8") as f:
csv_write = csv.writer(f) # 创建写入对象
csv_write.writerows(item) # 批量写入
if __name__ == "__main__":
# 爬取1-5页(可根据需求调整页码范围)
for i in range(1, 6):
url = "http://www.bspider.top/qidian/?page={0}".format(i) # 拼接分页URL
html = get_html(url) # 获取网页数据
out_list = parser(html) # 解析数据
save_csv(out_list, "test novel.csv") # 保存数据实现结果:

5.课堂内容总结
1.使用 requests.Session() 维持会话,自动处理 Cookies
常用方法:get()、post()、cookies()、headers()
2.使用 files 参数上传文件:
files = {'file': open('data.txt', 'rb')}
requests.post(url, files=files)
3.使用 verify=False 跳过SSL证书验证
4.使用 proxies 参数设置代理
5.XPath(XML Path Language)用于在XML/HTML中定位节点
支持路径表达式、谓语、函数、通配符等
6. 表达式 说明
nodename 选取该节点的所有子节点
/ 从根节点选取
// 选取所有匹配的节点(不限位置)
. 当前节点
.. 父节点
@ 选取属性
7. 谓语(条件筛选):使用 [] 添加条件:
/bookstore/book[1]:第一个book
//title[@lang='eng']:lang属性为eng的title
//book[price>35]:price大于35的book
8. XPath提取方式:
//li/a:所有li下的a标签
//a[@href="link4.html"]/../@class:获取父节点的class属性
//li[@class="item-1"]/a/text():获取文本
//li/a/@href:获取属性值
//div[contains(@id, "ID")]/a/text():模糊匹配属性
9.lxml库与etree模块基本用法:
导入:from lxml import etree
解析HTML:
etree.HTML(html_str):自动补全结构
etree.fromstring(html_str):不自动补全

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)