
故障诊断新方法!同步压缩小波变换-多尺度CNN-RIME-KELM一键实现西储大学轴承故障诊断!适合新手小白!
今天给大家带来一期关于西储大学故障诊断的新方法,这个方法既结合了一维信号转二维图像的处理方法,又结合近几年新提出的优化算法,最后利用小众机器学习模型实现故障诊断分类,精度可以达到近100%!可以说非常新颖,非常容易吸引审稿人。
声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
之前已经给大家带来过三期关于西储大学轴承故障诊断的文章:
独家原创!TCN-BiGRU-Attention一键实现西储大学故障诊断与讲解!附带处理好的Excel故障诊断数据集!
传统模型用腻了?GCN图卷积神经网络一键实现西储大学轴承故障诊断!发文新思路!
以及两篇关于东南大学齿轮箱故障诊断的文章:
东南大学齿轮箱故障诊断教程!SBOA-VMD-BiGRU模型直接运行!超多图!适合新手小白!
原创新方法!格拉姆角场-CNN-DOA-LSSVM一键实现东南大学齿轮箱故障诊断!超多图!适合新手小白!
以上方法都非常适合新手小白学习,里面的优化算法也可以任意替换。不过,今天给大家带来一期关于西储大学故障诊断的新方法,这个方法既结合了一维信号转二维图像的处理方法,又结合近几年新提出的优化算法,最后利用小众机器学习模型实现故障诊断分类,精度可以达到近100%!可以说非常新颖,非常容易吸引审稿人。
另外,为了方便新手小白学习,我们也几乎给每行代码都加上了注释,也有详细的使用说明。最关键的是,这个模型在知网和WOS都是搜不到的,如果大家想用这个模型写论文,都是完全没有问题的,不信的话看下图:
知网:
WOS:
您只需做的工作:下载压缩包,解压后运行main文件即可一键出图!无需配置环境!
原理详解
此处使用的数据是凯斯西储大学官方的齿轮箱数据!首先说一下该数据集的处理步骤以及来源:
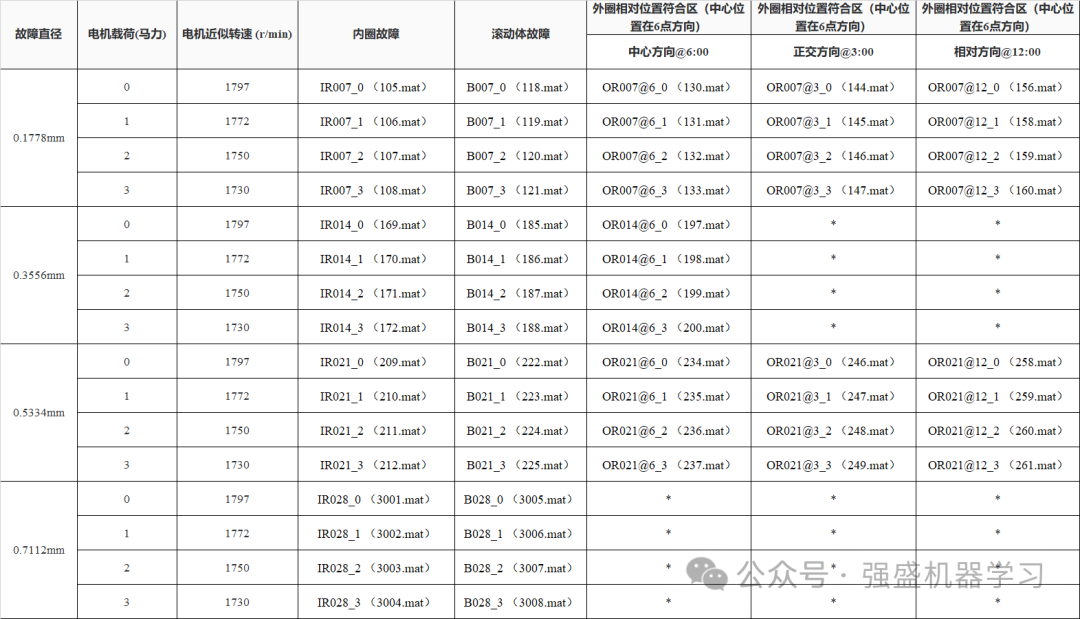
1.数据预处理。取官方下载的驱动端(DE)振动数据,分别为97.mat、107.mat、120.mat、132.mat、171.mat、187.mat、199.mat、211.mat、224.mat、236.mat,即转速为1750时的10种故障诊断类型(包括正常情况)。下图即为12K采样频率下的驱动端轴承故障数据(*表示数据不可用)。
设置滑动窗口w为1000,每个数据的故障样本点个数s为2048, 每个故障类型的样本量m为10。将所有的数据滑窗设置完毕之后,将所有的数据和类别综合到一个mat文件中,方便后续调用。
2.同步压缩小波变换。采用SWT方法将其转换为二维同步压缩小波变换时频图 像,在削弱无关频率干扰的情况下实现信号的二维表达。它先求取信号的连续小波变换,再计算信号的瞬时频率,最后压缩重组获得同步压缩小波变换值,得到的结果如下图所示:
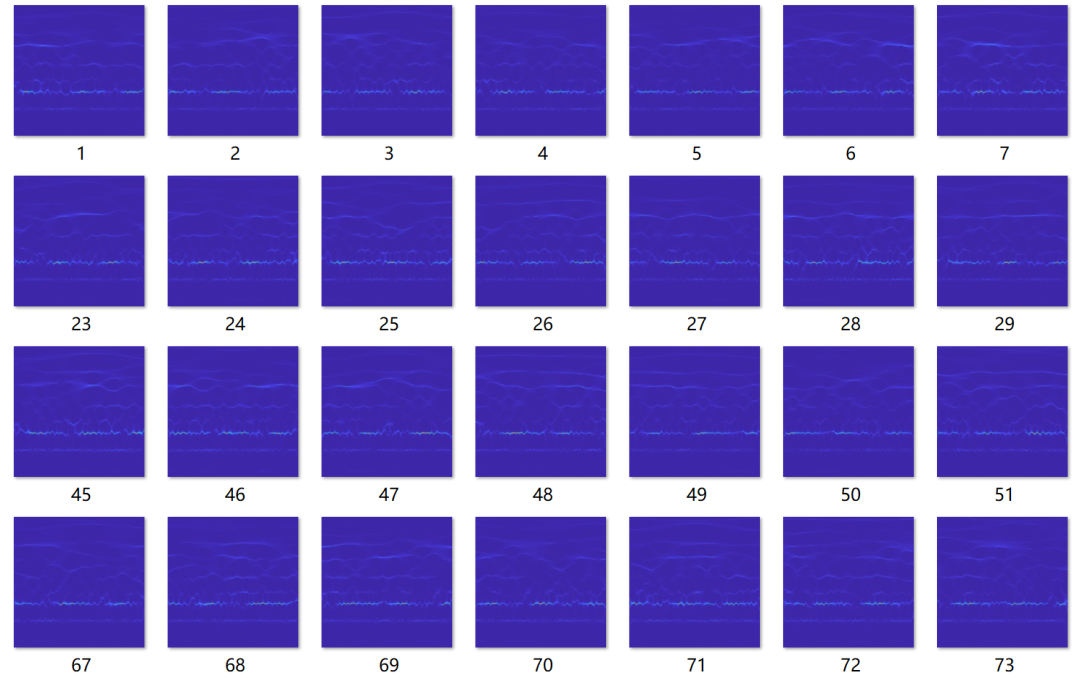
图片比较多,都会自动放到一个文件夹里,这边就只展示一部分~
3.故障诊断。按照上述流程处理完数据集后,就是我们常见的机器学习分类数据集了。此处,我们划分70%为训练集,30%为测试集,将数据送入非常新颖的MCNN中进行特征提取,再取MCNN的全连接层结果作为KELM模型的输入,并利用SCI高被引算法——霜冰优化算法RIME对KELM的核函数参数和正则化系数实现自适应寻优,就能得到故障诊断结果!
创新点
如果有小伙伴想要拿这个模型写论文,这里的文字都是可以借鉴和参考的!
①创新点一:同步压缩变换驱动的信号视觉化增强
我们创新性地采用同步压缩小波变换(SWT)技术,将原始的一维振动信号转化为信息密度更高、时频分辨率更优的二维图像。相较于传统的短时傅里叶变换或连续小波变换,SWT能够生成能量更为集中的时频谱图,有效抑制了能量模糊,使得图像中的故障特征纹理更加清晰、突出。这种高质量的“信号图像化”预处理方法,不仅保留了信号的非平稳性和瞬态特性,更为后续深度学习模型的特征学习提供了信息熵更高、判别性更强的输入,为整个模型的性能奠定了坚实基础。
②创新点二:融合局部-全局感知的多尺度特征提取架构
在深度特征学习的网络架构设计上,我们摒弃了传统的单路径串行卷积网络,设计并实现了一种新颖的多尺度并行卷积神经网络(MCNN)。该网络包含两个并行的特征提取分支:一个分支采用小尺寸卷积核(如2x2, 3x3),专注于捕捉时频谱图中的局部细节和高频精细纹理特征;另一个分支则使用大尺寸卷积核(如7x7, 5x5),旨在捕获更大感受野下的全局轮廓和低频结构化信息。这种多尺度并行结构极大地增强了网络对复杂故障特征的综合表征能力,相较于单一路径网络,能够学习到更加鲁棒和全面的深度特征。
③创新点三:深度特征提取+智能优化分类新颖混合架构
我们并未直接使用MCNN的Softmax层进行端到端分类,而是将其作为一个高效的深度特征提取器,提取其全连接层输出的高维、高判别性的特征。随后,将这些深度特征输入到KELM中进行分类。为解决KELM性能受超参数(正则化系数C与核参数S)影响显著的问题,我们引入了新颖的RIME优化算法对KELM进行自动寻优。通过RIME算法的全局搜索能力,能够自适应地找到KELM的最佳参数组合,从而确保了分类器能够达到最优性能,融合了CNN强大的特征自学习能力与KELM训练速度快、泛化性能强的优点。
结果展示
此处采用的MCNN-RIME-KELM模型,知网上还没人用过,大家也可以留言找我或者自行替换成想要的优化算法!
首先看一下模式识别前后的样本分布情况:
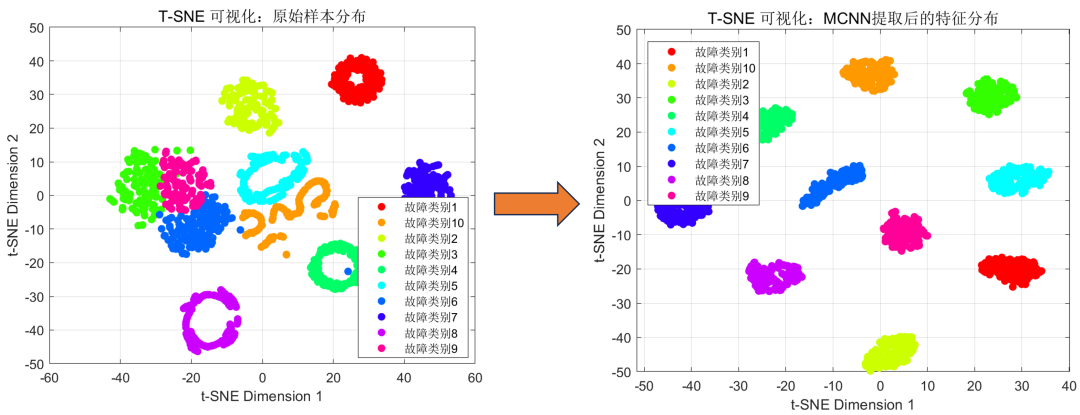
可以看到,模型识别前,故障类别较为无序,无法很好地区分。经过模型识别后,各个故障类别都独立成块,能够很好地区分与辨识!
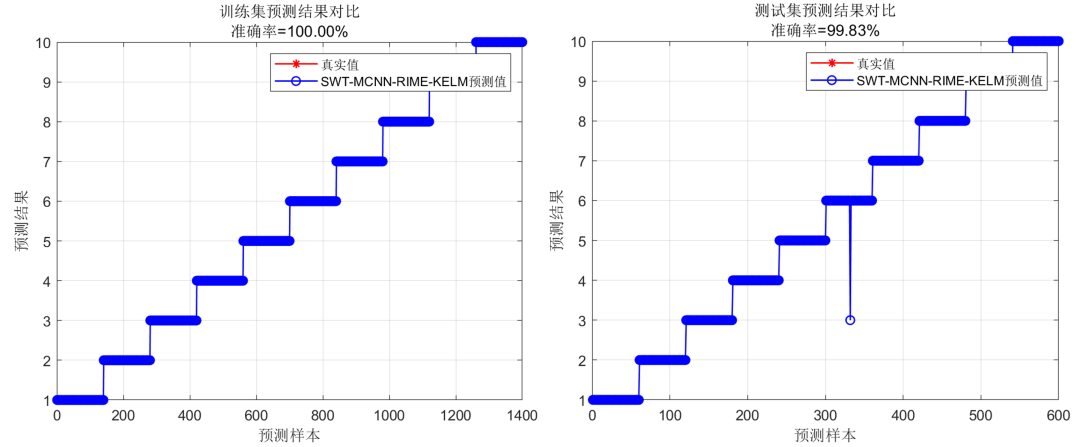
接着是分类效果图,包括训练集与测试集:
其次是混淆矩阵图,包括训练集与测试集:
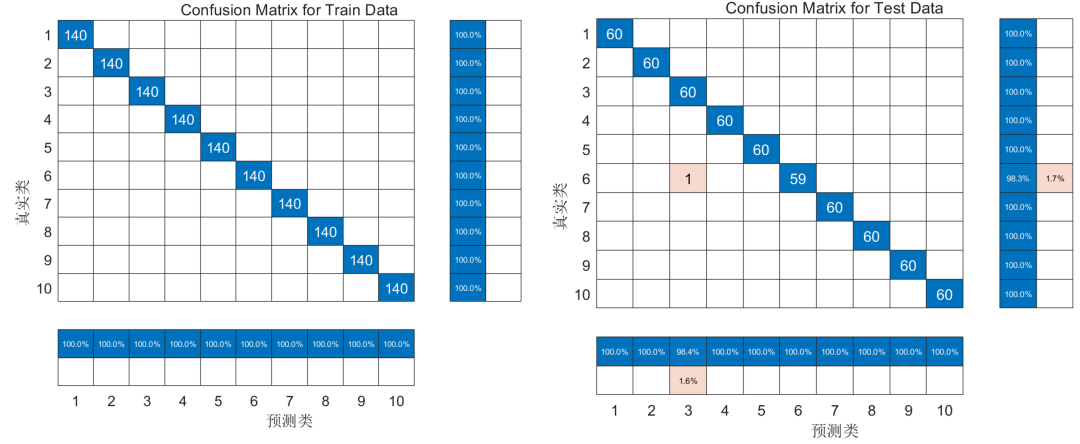
可以看到,经过我们新方法得到的故障诊断准确率结果相当之高,训练集预测结果准确率能够达到100%,而测试集预测结果也在99%以上,超越了绝大部分论文中的结果!
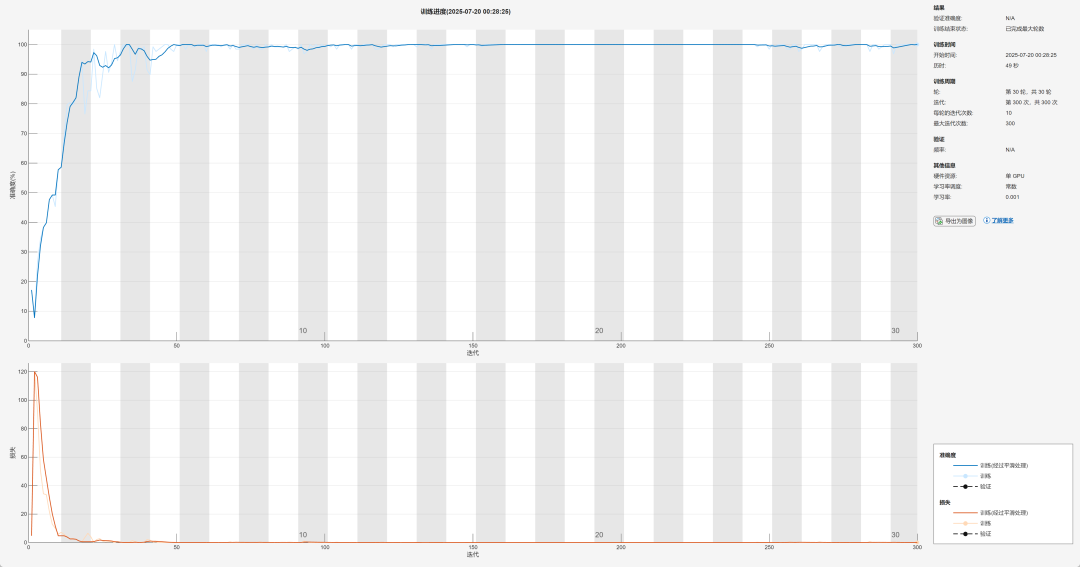
以及MCNN网络结构图:
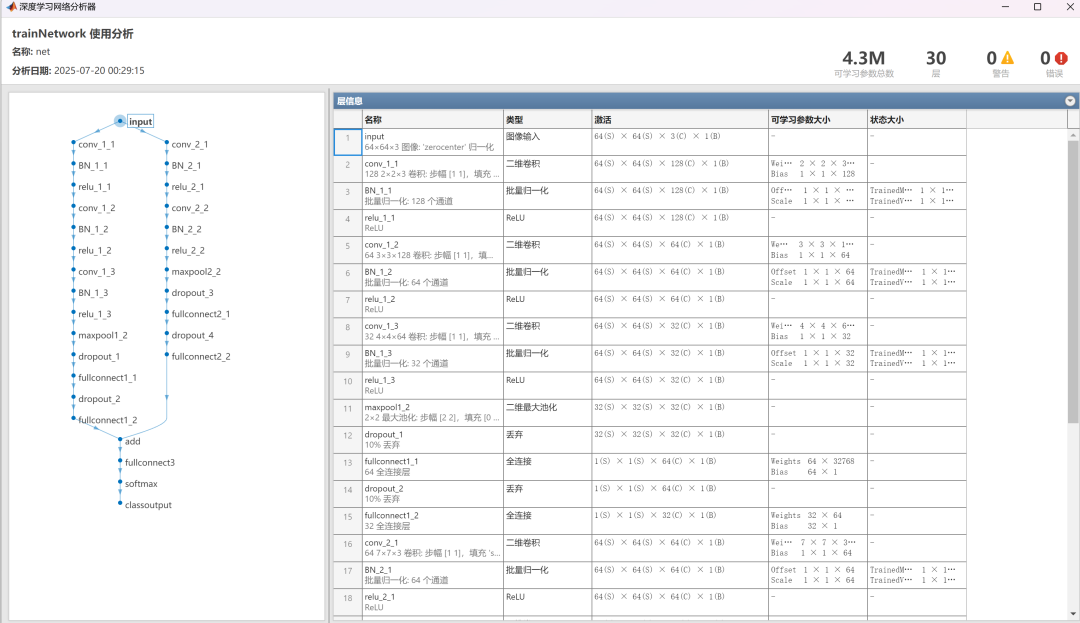
以上所有图片,作者都已精心整理过代码,都可以一键运行main直接出图,使用起来非常方便!
不信的话可以看下面文件夹截图,非常清晰明了,并且有使用说明!
%% 导入图像数据与标签
load SWT_resizeimg.mat; % 导入预处理后的图像数据
resizeimg = SWT_resizeimg; % 将加载的数据赋给通用变量名,便于后续处理
%% 分析数据并进行随机分层抽样
res = resizeimg'; % 转置数据,使每一行代表一个样本 [图像, 标签]
num_res = size(res, 1); % 获取样本总数
res = res(randperm(num_res), :); % 随机打乱整个数据集的顺序
num_size = 0.7; % 设定训练集占总数据集的比例
allLabels = cell2mat(res(:, 2)); % 提取所有打乱后的标签,用于分层
uniqueLabel = unique(allLabels); % 获取所有唯一的类别标签
num_class = length(uniqueLabel); % 计算类别总数
%% 设置变量存储划分后的数据
P_train = {}; T_train = {};
P_test = {}; T_test = {};
%% 按比例划分数据集
for i = 1 : num_class
currentClass = uniqueLabel(i); % 获取当前要处理的类别
idx_this = find(allLabels == currentClass); % 找到该类别在打乱后数据集中的所有样本
mid_res = res(idx_this, :); % 提取出该类别的所有样本
mid_size = size(mid_res, 1); % 获取该类别的样本总数
mid_tiran = round(num_size * mid_size); % 根据比例计算该类别的训练样本数
% 前 mid_tiran 个样本用于训练
P_train = [P_train; mid_res(1 : mid_tiran, 1)]; % 存入训练集图像
T_train = [T_train; mid_res(1 : mid_tiran, 2)]; % 存入训练集标签
% 剩余的样本用于测试
P_test = [P_test; mid_res(mid_tiran + 1 : end, 1)]; % 存入测试集图像
T_test = [T_test; mid_res(mid_tiran + 1 : end, 2)]; % 存入测试集标签
end完整代码获取
如果需要以上完整代码,只需点击下方小卡片,再后台回复关键字,不区分大小写:
GZZDF

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)