
SongGen:三秒克隆音色!开源AI一键生成专业级歌曲,创作人必备神器
SongGen是由上海AI Lab、北京航空航天大学和香港中文大学联合推出的单阶段自回归Transformer模型,能够通过文本生成高质量歌曲,支持混合模式和双轨模式,显著提升生成歌曲的自然度和人声清晰度。
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦
🎧 “AI作曲新突破!SongGen一键生成高质量歌曲,支持声音克隆和双轨编辑”
大家好,我是蚝油菜花。你是否也遇到过——
- 👉 音乐创作灵感枯竭,难以快速生成歌曲雏形
- 👉 视频配乐找不到合适的背景音乐,版权问题让人头疼
- 👉 想要个性化定制歌曲,却苦于没有专业工具…
今天揭秘的 SongGen ,用AI彻底颠覆音乐创作方式!这个由上海AI Lab、北京航空航天大学和香港中文大学联合推出的单阶段自回归Transformer模型,能够通过文本生成高质量歌曲,支持混合模式和双轨模式,显著提升生成歌曲的自然度和人声清晰度。无论是音乐创作、视频配乐,还是个性化定制,SongGen都能轻松应对——你的音乐创作之旅即将迎来革命性突破!
🚀 快速阅读
SongGen是一个基于自回归Transformer的歌曲生成模型,能够通过文本生成高质量歌曲。
- 核心功能:支持混合模式和双轨模式,提供细粒度控制和声音克隆功能。
- 技术原理:基于创新的音频标记化策略和训练方法,显著提升生成歌曲的自然度和人声清晰度。
SongGen 是什么
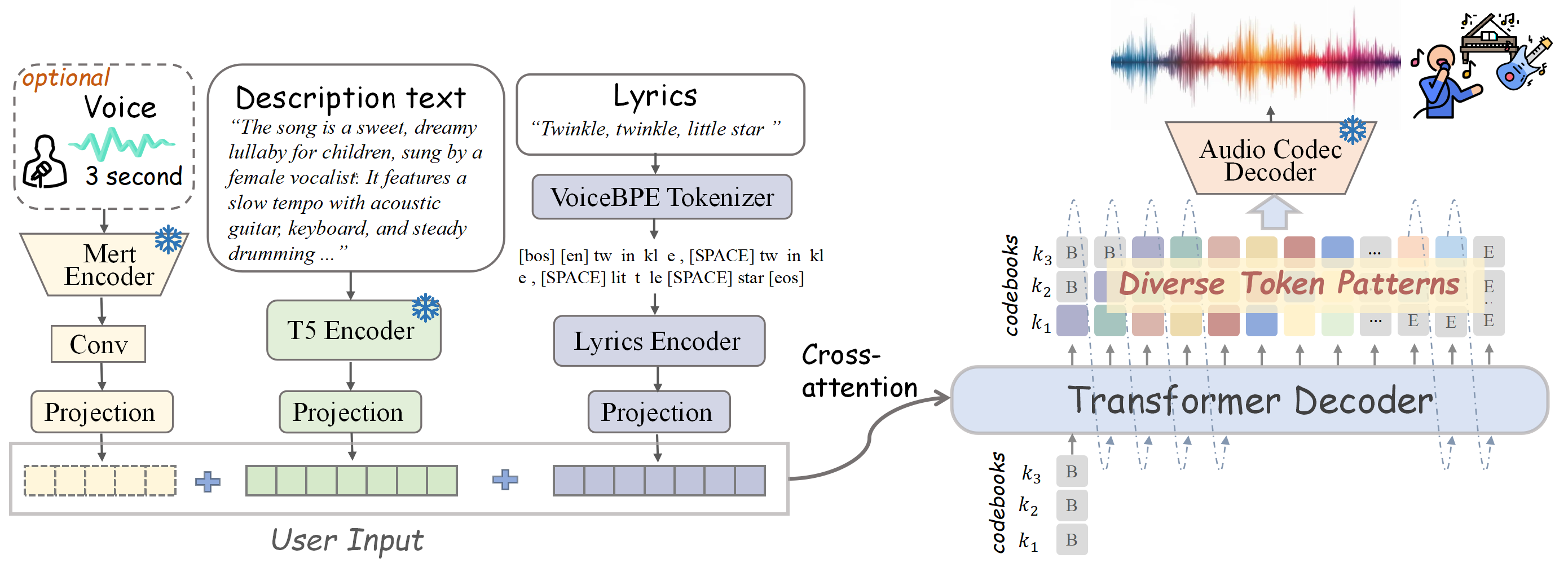
SongGen是由上海AI Lab、北京航空航天大学和香港中文大学联合推出的单阶段自回归Transformer模型,能够通过文本生成高质量歌曲。SongGen基于歌词和描述性文本(如乐器、风格、情感等)作为输入,支持混合模式和双轨模式两种输出方式,分别用于直接生成人声与伴奏的混合音频,及分别合成人声和伴奏方便后期编辑。
SongGen基于创新的音频标记化策略和训练方法,显著提升生成歌曲的自然度和人声清晰度,解决传统多阶段方法中训练和推理流程繁琐的问题。SongGen的开源性和高质量数据集为未来音乐生成研究提供了新的基准。
SongGen 的主要功能
- 细粒度控制:用户基于歌词、描述性文本(如乐器、风格、情感等)对生成的歌曲进行控制。
- 声音克隆:支持基于三秒参考音频实现声音克隆,使生成的歌曲具有特定歌手的音色。
- 两种生成模式:提供“混合模式”(直接生成人声和伴奏的混合音频)和“双轨模式”(分别合成人声和伴奏,便于后期编辑)。
- 高质量音频输出:基于优化的音频标记化和训练策略,生成具有高自然度和清晰人声的歌曲。
SongGen 的技术原理
- 自回归生成框架:基于自回归Transformer解码器,将歌词和描述性文本编码为条件输入,用交叉注意力机制引导音频标记的生成。
- 音频标记化:用X-Codec将音频信号编码为离散的音频标记,基于代码本延迟模式处理多代码序列,支持高效生成。
- 混合模式与双轨模式:
- 混合模式:直接生成混合音频标记,引入辅助人声音频标记预测目标(Mixed Pro),增强人声清晰度。
- 双轨模式:基于平行或交错模式分别生成人声和伴奏标记,确保两者在帧级别上的对齐,提升生成质量。
- 条件输入编码:
- 歌词编码:VoiceBPE分词器将歌词转换为音素级标记,基于小型Transformer编码器提取关键发音信息。
- 声音编码:MERT模型提取参考音频的音色特征,支持声音克隆。
- 文本描述编码:FLAN-T5模型将描述性文本编码为特征向量,提供音乐风格、情感等控制。
- 训练策略:
- 多阶段训练:包括模态对齐、无参考声音支持和高质量微调,逐步提升模型性能。
- 课程学习:逐步调整代码本损失权重,优化模型对音频细节的学习。
- 数据预处理:开发自动化数据预处理管道,从多个数据源收集音频,分离人声和伴奏,生成高质量的歌词和描述性文本数据集。
如何运行 SongGen
1. 安装环境和依赖
git clone https://github.com/LiuZH-19/SongGen.git
cd SongGen
# 推荐使用conda创建新环境
conda create -n songgen python=3.9.18
conda activate songgen
# 安装cuda >= 11.8
conda install pytorch torchvision torchaudio cudatoolkit=11.8 -c pytorch -c nvidia
如果仅使用SongGen的推理模式,可以通过以下命令安装:
pip install .
2. 下载xcodec和songgen的检查点
3. 运行推理
(1). 混合模式
import torch
import os
from songgen import (
VoiceBpeTokenizer,
SongGenMixedForConditionalGeneration,
SongGenProcessor
)
import soundfile as sf
ckpt_path = "..." # 预训练模型的路径
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = SongGenMixedForConditionalGeneration.from_pretrained(
ckpt_path,
attn_implementation='sdpa').to(device)
processor = SongGenProcessor(ckpt_path, device)
# 定义输入文本和歌词
lyrics = "..." # 歌词文本
text="..." # 音乐描述文本
ref_voice_path = 'path/to/your/reference_audio.wav' # 参考音频路径,可选
separate= True # 是否从参考音频中分离人声
model_inputs = processor(text=text, lyrics=lyrics, ref_voice_path=ref_voice_path, separate=True)
generation = model.generate(**model_inputs,
do_sample=True,
)
audio_arr = generation.cpu().numpy().squeeze()
sf.write("songgen_out.wav", audio_arr, model.config.sampling_rate)
(2). 双轨模式
import torch
import os
from songgen import (
VoiceBpeTokenizer,
SongGenDualTrackForConditionalGeneration,
SongGenProcessor
)
import soundfile as sf
ckpt_path = "..." # 预训练模型的路径
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = SongGenDualTrackForConditionalGeneration.from_pretrained(
ckpt_path,
attn_implementation='sdpa').to(device)
processor = SongGenProcessor(ckpt_path, device)
# 定义输入文本和歌词
lyrics = "..." # 歌词文本
text="..." # 音乐描述文本
ref_voice_path = 'path/to/your/reference_audio.wav' # 参考音频路径,可选
separate= True # 是否从参考音频中分离人声
model_inputs = processor(text=text, lyrics=lyrics, ref_voice_path=ref_voice_path, separate=True)
generation = model.generate(**model_inputs,
do_sample=True,
)
acc_array = generation[0].cpu().numpy()
vocal_array = generation[1].cpu().numpy()
min_len =min(vocal_array.shape[0], acc_array.shape[0])
acc_array = acc_array[:min_len]
vocal_array = vocal_array[:min_len]
audio_arr = vocal_array + acc_array
sf.write("songgen_out.wav", audio_arr, model.config.sampling_rate)
资源
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 12
12 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)