
2024年最全深度学习(五)—— 卷积神经网络(CNN(1),大数据开发高级进阶学习资料
池化层降低了后续网络层的输入维度,缩减模型大小,提高计算速度,并提高了Feature Map 的鲁棒性,防止过拟合,它主要对卷积层学习到的特征图进行下采样(subsampling)处理,主要由两种。是一个较简单的卷积神经网络, 输入的二维图像,先经过两次卷积层,池化层,再经过全连接层,最后使用softmax分类作为输出层。卷积神经网络的输入要求是:N H W C ,分别是图片数量,图片高度,图片宽
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
2.5 卷积层 api 实现
tf.keras.layers.Conv2D(
filters, kernel_size, strides=(1, 1), padding='valid',
activation=None
)
主要参数说明如下:

3 池化层
池化层降低了后续网络层的输入维度,缩减模型大小,提高计算速度,并提高了Feature Map 的鲁棒性,防止过拟合,它主要对卷积层学习到的特征图进行下采样(subsampling)处理,主要由两种。
3.1 最大池化
Max Pooling,取窗口内的最大值作为输出,这种方式使用较广泛。
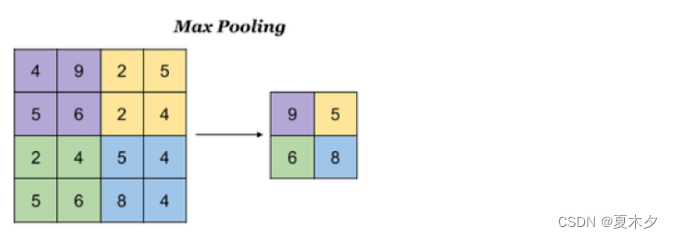
池化层最大池化的 api 实现如下:
tf.keras.layers.MaxPool2D(
pool_size=(2, 2), strides=None, padding='valid'
)
参数:
- pool_size:池化窗口的大小
- strides:窗口移动的步长,默认为1
- padding:是否进行填充,默认是不进行填充的
3.2 平均池化
Avg Pooling,取窗口内的所有值的均值作为输出
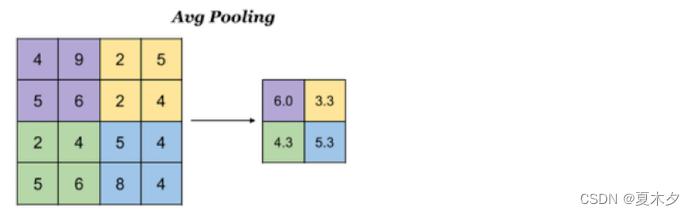
池化层平均池化的 api 实现如下:
tf.keras.layers.AveragePooling2D(
pool_size=(2, 2), strides=None, padding='valid'
)
4 全连接层
全连接层位于CNN网络的末端,经过卷积层的特征提取与池化层的降维后,将特征图转换成 一维向量 送入到全连接层中进行分类或回归的操作。
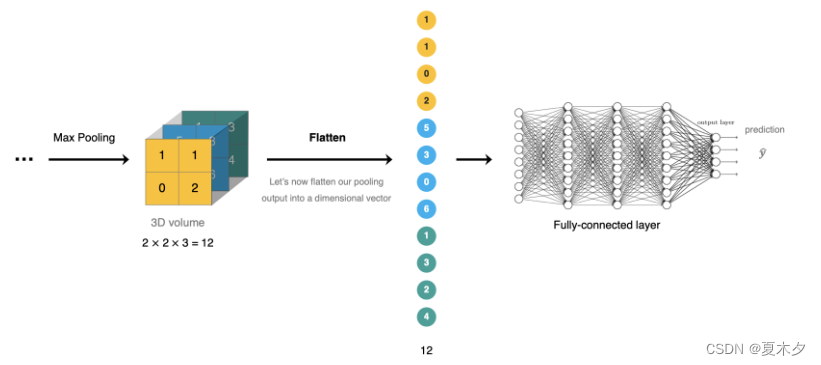
在 tf.keras 中全连接层使用 tf.keras.dense 实现
5 CNN的构建
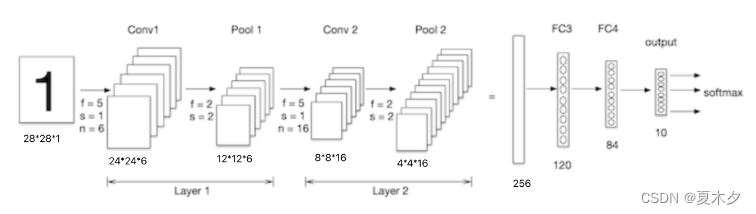
我们构建卷积神经网络在mnist数据集上进行处理,如下图所示:LeNet-5 是一个较简单的卷积神经网络, 输入的二维图像,先经过两次卷积层,池化层,再经过全连接层,最后使用softmax分类作为输出层。
5.1 数据加载
导入工具包:
import tensorflow as tf
# 数据集
from tensorflow.keras.datasets import mnist
加载数据集:
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
5.2 数据处理
卷积神经网络的输入要求是:N H W C ,分别是图片数量,图片高度,图片宽度和图片的通道,因为是灰度图,通道为1
# 数据处理:n,h,w,c
# 训练集数据
train_images = tf.reshape(train_images, (train_images.shape[0],train_images.shape[1],train_images.shape[2], 1))
print(train_images.shape) # (60000, 28, 28, 1)
# 测试集数据
test_images = tf.reshape(test_images, (test_images.shape[0],test_images.shape[1],test_images.shape[2], 1))
5.3 模型搭建
Lenet-5模型输入的二维图像,先经过两次卷积层、池化层,再经过全连接层,最后使用 softmax 分类作为输出层,模型构建如下:
# 模型构建
net = tf.keras.models.Sequential([
# 卷积层:6个5\*5的卷积核,激活是sigmoid
tf.keras.layers.Conv2D(filters=6,kernel_size=5,activation='sigmoid',input_shape= (28,28,1)),
# 最大池化
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
# 卷积层:16个5\*5的卷积核,激活是sigmoid
tf.keras.layers.Conv2D(filters=16,kernel_size=5,activation='sigmoid'),
# 最大池化
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
# 维度调整为1维数据
tf.keras.layers.Flatten(),
# 全卷积层,激活sigmoid
tf.keras.layers.Dense(120,activation='sigmoid'),
# 全卷积层,激活sigmoid
tf.keras.layers.Dense(84,activation='sigmoid'),
# 全卷积层,激活softmax
tf.keras.layers.Dense(10,activation='softmax')
])
我们通过 net.summary() 查看网络结构:
Model: "sequential_11"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 24, 24, 6) 156
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 12, 12, 6) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 16) 2416
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 4, 4, 16) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 256) 0
_________________________________________________________________
dense_25 (Dense) (None, 120) 30840
_________________________________________________________________
dense_26 (Dense) (None, 84) 10164
dense_27 (Dense) (None, 10) 850
=================================================================
Total params: 44,426
Trainable params: 44,426
Non-trainable params: 0
______________________________________________________________
关于参数量计算:
- conv1中的卷积核为5x5x1,卷积核个数为6,每个卷积核有一个bias,所以参数量为:5x5x1x6+6=156
- conv2中的卷积核为5x5x6,卷积核个数为16,每个卷积核有一个bias,所以参数量为:5x5x6x16+16 = 2416
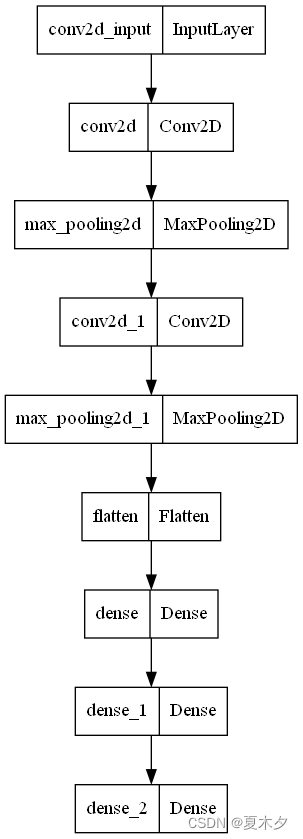
绘制模型结构图:
tf.keras.utils.plot_model(net)
5.4 模型编译
设置优化器和损失函数:
# 优化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.9)
# 模型编译:损失函数,优化器和评价指标
net.compile(optimizer=optimizer,
loss='sparse\_categorical\_crossentropy',
metrics=['accuracy'])
5.5 模型训练
# 模型训练
net.fit(train_images, train_labels, epochs=5, validation_split=0.1)# 省略verbose参数,默认verbose=1
训练流程:
Epoch 1/5
1688/1688 [==============================] - 10s 6ms/step - loss: 0.8255 - accuracy: 0.6990 - val_loss: 0.1458 - val_accuracy: 0.9543
Epoch 2/5
1688/1688 [==============================] - 10s 6ms/step - loss: 0.1268 - accuracy: 0.9606 - val_loss: 0.0878 - val_accuracy: 0.9717
Epoch 3/5
1688/1688 [==============================] - 10s 6ms/step - loss: 0.1054 - accuracy: 0.9664 - val_loss: 0.1025 - val_accuracy: 0.9688
Epoch 4/5
1688/1688 [==============================] - 11s 6ms/step - loss: 0.0810 - accuracy: 0.9742 - val_loss: 0.0656 - val_accuracy: 0.9807
Epoch 5/5
1688/1688 [==============================] - 11s 6ms/step - loss: 0.0732 - accuracy: 0.9765 - val_loss: 0.0702 - val_accuracy: 0.9807
5.6 模型评估
# 模型评估
score = net.evaluate(test_images, test_labels, verbose=1)
print('Test accuracy:', score[1])
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
链图片转存中…(img-ICUbkXGr-1715293395347)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)