
【推荐大模型】HLLM论文解读
各位技术大佬们,大家好!今天咱们来聊点硬核的——推荐系统。这玩意儿,大家都不陌生吧?从刷抖音到逛淘宝,从看电影到听音乐,它无处不在,默默地影响着我们的每一个选择。可以说,推荐系统就是我们数字生活里的“贴心小棉袄”(也可能是“剁手小恶魔”)。传统的推荐系统,大家最熟悉的就是基于ID的那些模型了。简单来说,就是把用户和商品都变成一串串ID,然后用各种花式算法去学习这些ID之间的关系。比如协同过滤、矩阵
HLLM:当大模型遇上推荐系统,效果炸裂!
GitHub: https://github.com/bytedance/HLLM
论文: HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling
前言:推荐系统,你还好吗?
各位技术大佬们,大家好!今天咱们来聊点硬核的——推荐系统。这玩意儿,大家都不陌生吧?从刷抖音到逛淘宝,从看电影到听音乐,它无处不在,默默地影响着我们的每一个选择。可以说,推荐系统就是我们数字生活里的“贴心小棉袄”(也可能是“剁手小恶魔”)。
传统的推荐系统,大家最熟悉的就是基于ID的那些模型了。简单来说,就是把用户和商品都变成一串串ID,然后用各种花式算法去学习这些ID之间的关系。比如协同过滤、矩阵分解、深度学习模型(像SASRec、DIN、DIEN这些),它们在过去几年里确实立下了汗马功劳。但是,这些传统模型也有自己的“小烦恼”:
- 冷启动问题:新用户、新商品一来,模型就懵圈了,因为没历史数据啊!就像你刚到一个新城市,人生地不熟,想找个好吃的都得靠蒙。
- 模型规模受限:这些模型通常参数量不大,对于复杂多变的用户兴趣,有时候显得力不从心。就像你用个小水桶去接瀑布,总感觉差点意思。
大模型:推荐系统的新救星?
就在大家为推荐系统的“小烦恼”挠头的时候,ChatGPT横空出世,大语言模型(LLM)以摧枯拉朽之势席卷了整个AI界。那强大的世界知识、逆天的推理能力,简直让人惊掉下巴!于是乎,大家开始琢磨了:LLM这么牛,能不能也来推荐系统里“掺一脚”呢?
当然,前人已经做了不少尝试,大致可以分为三类:
- LLM当“辅助”:让LLM帮忙总结用户行为、扩展商品信息,给推荐系统提供更丰富的特征。就像给推荐系统请了个“智囊团”。
- LLM当“客服”:把推荐系统变成聊天机器人,用户直接跟LLM对话,告诉它想买啥、想看啥。这感觉就像有个私人导购。
- LLM当“主力”:直接改造LLM,让它能处理ID特征,甚至直接优化点击率(CTR)等推荐指标。这可是要让LLM“C位出道”啊!
然而,理想很丰满,现实有点骨感。这些尝试虽然有进展,但也面临不少挑战:
- 输入序列太长:如果把用户历史行为都变成文本喂给LLM,那序列长度分分钟爆炸,LLM的自注意力机制可是平方级复杂度,算力分分钟不够用!
- 效率问题:推荐一个商品可能需要生成好几个文本token,这效率,在线上系统可吃不消。
- 效果提升不明显:最让人头疼的是,很多时候LLM带来的效果提升并不显著,让人不禁怀疑:LLM的潜力真的被挖掘出来了吗?
而且,还有几个“灵魂拷问”一直悬而未决:
- LLM预训练权重里那些“世界知识”,到底对推荐系统有多大用?
- LLM在推荐任务上,到底需不需要精调(Fine-tuning)?
- LLM在推荐系统里,还能像在其他领域那样展现出惊人的“规模效应”吗?
别急,今天咱们要介绍的这篇论文——《HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling》就来回答这些问题,并提出了一个“分层大语言模型”(HLLM)架构,简直是给推荐系统打了一剂强心针!
HLLM:分层建模,各司其职
为了解决LLM在推荐系统中面临的挑战,特别是输入序列过长的问题,HLLM(Hierarchical Large Language Model)架构横空出世!它的核心思想就是“分层建模”,把商品建模和用户建模这两个任务解耦开来,让它们各司其职,效率更高。
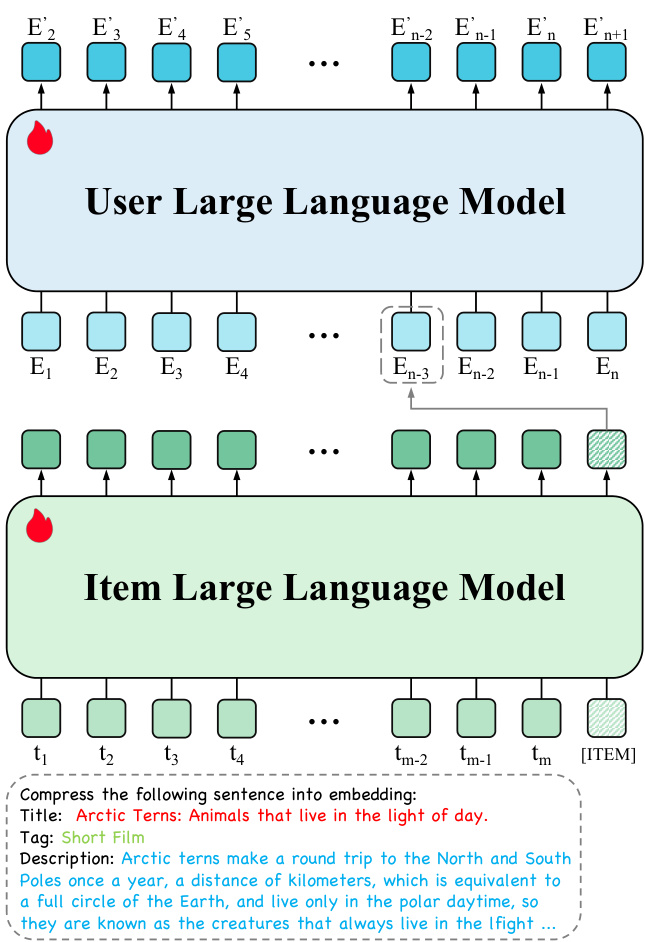
图1:HLLM架构概览
从图1我们可以清晰地看到,HLLM主要由两部分组成:
-
Item LLM(商品大模型):顾名思义,这个模型专门负责从商品的详细文本描述中提取丰富的特征。想象一下,一个商品可能有标题、标签、详细介绍等等一大堆文本信息,Item LLM就是要把这些复杂的文本信息“压缩”成一个简洁的向量表示(Item Embedding)。为了让LLM更好地完成这个任务,作者们还玩了个小花招:在每个商品文本描述的末尾,加上一个特殊的
[ITEM]标记。然后把整个文本(包括这个标记)喂给Item LLM,最后取出[ITEM]标记对应的输出向量,就是这个商品的Embedding了。这样一来,商品再复杂,也能被“浓缩”成一个固定长度的向量,大大降低了后续处理的复杂度。 -
User LLM(用户大模型):有了Item LLM提取的商品Embedding,User LLM就登场了。它的任务是根据用户历史交互的商品Embedding序列,来预测用户未来的兴趣。传统的LLM是文本输入、文本输出,但User LLM有点特别,它的输入和输出都是商品Embedding。这意味着,它抛弃了LLM预训练时的词嵌入层,但保留了其他所有预训练权重。实验证明,这些预训练权重对于理解用户兴趣、进行推理非常有帮助。
这种分层设计的好处显而易见:
- 序列长度大大缩短:商品文本描述被压缩成Embedding后,用户历史行为序列的长度就和传统的ID-based模型差不多了,避免了LLM自注意力机制带来的平方级复杂度爆炸问题,计算效率蹭蹭往上涨!
- 解耦更灵活:商品建模和用户建模分开,可以独立优化,也方便缓存商品Embedding,进一步提升线上服务的效率。
训练目标:让LLM更懂推荐
虽然LLM自带“世界知识”光环,但毕竟是通用模型,要让它在推荐系统里大放异彩,还得进行任务特定的精调(Fine-tuning)。HLLM的训练目标可以根据推荐系统的类型分为两种:
1. 生成式推荐(Generative Recommendation)
生成式推荐的目标是预测用户接下来会和哪个商品互动。HLLM在这里采用的是“下一项预测”(Next Item Prediction),也就是根据用户历史交互序列,预测下一个商品的Embedding。训练时用的是InfoNCE损失函数,这是一种对比学习的损失,简单来说就是让模型学会区分“正样本”(用户真正交互的下一个商品)和“负样本”(随机采样的其他商品)。
2. 判别式推荐(Discriminative Recommendation)
判别式推荐在工业界更为常见,它的目标是判断用户对某个目标商品是否感兴趣(比如会不会点击、会不会购买)。HLLM在这里提供了两种“融合”方式:
-
早期融合(Early Fusion):把目标商品的Embedding直接拼接到用户历史序列的末尾,然后User LLM一起处理,生成一个高阶的交叉特征,最后喂给预测头。这种方式融合得深,效果通常更好,但计算量大,不适合同时处理大量候选商品。
-
晚期融合(Late Fusion):User LLM先独立提取用户特征(不包含目标商品信息),然后用户特征和目标商品Embedding一起喂给预测头。这种方式效率高,因为不同候选商品可以共享同一个用户特征,但效果可能会略有下降。
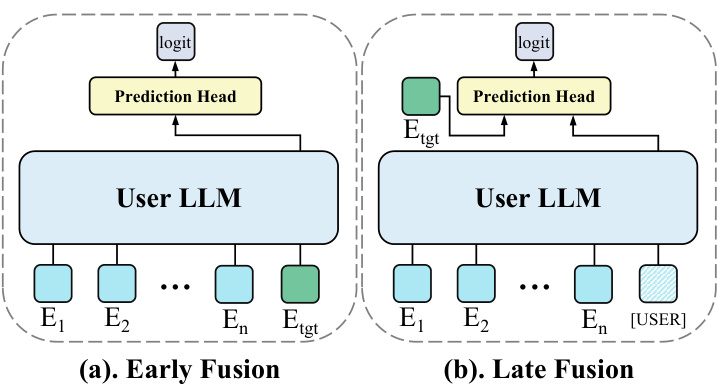
图2:判别式推荐的两种User LLM变体
判别式推荐的训练目标通常是分类任务,比如预测点击率,用的是经典的交叉熵损失。有时候,还可以把“下一项预测”作为辅助损失加进来,进一步提升模型性能。
实验结果:HLLM,YYDS!
光说不练假把式,HLLM到底行不行,还得看实验数据!论文中在两个大规模数据集(PixelRec和Amazon Book Reviews)上进行了大量离线实验,并在真实线上环境进行了A/B测试。结果嘛,只能说:HLLM,YYDS(永远的神)!
RQ1: 预训练和精调,到底有没有用?
答案是:有用,而且非常重要!
- 预训练权重是基石:实验表明,LLM的预训练权重对于HLLM来说是实打实的好处,无论是商品特征提取还是用户兴趣建模,都能从中受益。而且,预训练token的数量越多,性能越好,说明预训练的质量直接影响推荐效果。
- 精调是点睛之笔:虽然LLM自带“世界知识”,但针对推荐任务的精调是必不可少的。精调能让模型更好地适应推荐场景,实现性能的显著提升。不过,在对话数据上进行SFT(Supervised Fine-tuning)反而可能带来负面影响,因为对话能力和推荐任务关系不大。
RQ2: HLLM的扩展性如何?
答案是:扩展性极佳!
-
模型参数越多越强:无论是Item LLM还是User LLM,增加模型参数量都能带来性能的持续提升。从10亿参数扩展到70亿参数,HLLM的性能依然在稳步增长,这说明HLLM具有出色的规模效应。
-
数据量越大越好:HLLM在不同数据规模下都表现出卓越的扩展性。随着训练数据量的增加,性能显著提升,而且在当前的数据规模下,还没有观察到性能瓶颈。这意味着,只要有足够的数据,HLLM就能持续“变强”!
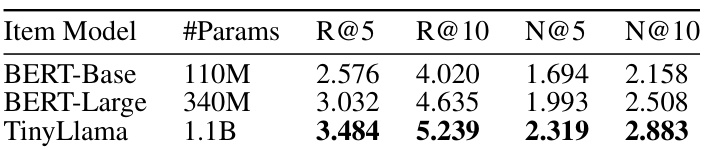
图3:HLLM在不同数据规模下的性能表现
RQ3: HLLM vs. SOTA模型,谁是王者?
答案是:HLLM是当之无愧的王者!
与SASRec、HSTU等SOTA(State-of-the-Art)ID-based模型以及基于文本的LEARN模型相比,HLLM展现出压倒性的性能优势。在所有数据集的所有指标上,HLLM都显著优于其他模型。
- 性能提升巨大:HLLM-1B在Pixel8M数据集上平均提升22.93%,在Books数据集上更是达到了惊人的108.68%!而ID-based模型最多也只提升了5.37%和64.96%。
- 参数扩展收益更高:当ID-based模型增加负样本数量和batch size时,性能提升微乎其微。而HLLM-1B在相同设置下,R@200指标提升了2.44,远超HSTU-large的0.76。当模型参数进一步扩展到70亿时,HLLM-7B相比基线模型更是提升了169.58%!
- ID-based模型瓶颈明显:即使是充分收敛的ID-based模型,增加参数带来的收益也微乎其微,甚至在某些情况下还会下降。这再次证明了HLLM架构的优越性。
RQ4: 训练和服务效率如何?
答案是:效率惊人!
- 训练数据效率高:HLLM只需要ID-based模型六分之一到四分之一的数据量,就能达到相近的性能。这意味着,在数据量有限的情况下,HLLM能更快地达到优秀效果。
- 推理效率高:HLLM通过解耦商品和用户编码,可以提前缓存商品Embedding,大大降低了推理时的计算复杂度。虽然冻结Item LLM会导致一些性能下降,但仍然优于ID-based模型,证明了商品缓存的可行性和有效性。在工业场景中,用户行为远超商品数量,因此HLLM的训练和服务成本可以与ID-based模型持平。
线上A/B测试:真金不怕火炼!
HLLM不仅在离线实验中表现出色,更在真实世界的线上A/B测试中取得了显著成果!为了兼顾性能和效率,线上采用了HLLM-1B的判别式推荐,并结合了晚期融合策略。整个训练过程分为三个阶段:
- 阶段一:端到端训练HLLM所有参数,包括Item LLM和User LLM,使用判别式损失。为了加速训练,用户历史序列长度截断为150。
- 阶段二:冻结Item LLM,用阶段一训练好的Item LLM编码并存储所有商品的Embedding。然后只训练User LLM,从存储中检索商品Embedding。由于只训练User LLM,大大降低了训练需求,可以将用户序列长度从150扩展到1000,进一步提升User LLM的效果。
- 阶段三:前两个阶段充分训练后,HLLM模型参数不再更新。提取所有用户的特征,结合商品LLM Embedding和其他现有特征,喂给线上推荐模型进行训练。
在服务方面,商品Embedding在创建时提取,用户Embedding每天只对前一天有活动的用户进行更新。商品和用户Embedding都会存储起来,供线上模型训练和提供服务。这种方式几乎不增加线上推荐系统的推理时间。
最终,线上A/B测试结果显示,关键指标显著提升了0.705%!这可不是个小数目,在推荐系统这种“寸土必争”的领域,0.705%的提升足以带来巨大的商业价值!
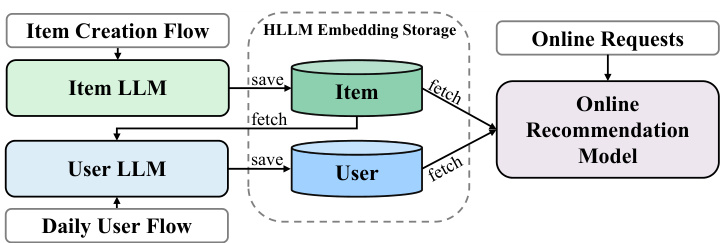
图4:线上系统概览
总结:HLLM,未来已来!
总的来说,HLLM这个分层大语言模型架构,简直是给推荐系统领域注入了一股清流!它巧妙地利用了LLM强大的文本理解和特征提取能力,同时又通过分层设计解决了LLM在推荐系统中面临的效率和序列长度问题。更重要的是,它不仅在学术数据集上取得了SOTA(State-of-the-Art)的成绩,还在真实世界的线上A/B测试中证明了其强大的实用价值。
HLLM的成功,再次印证了LLM在更广阔领域应用的巨大潜力。它告诉我们:
- LLM的预训练知识,对于推荐系统来说是宝贵的财富。
- 任务特定的精调,是释放LLM在推荐领域潜力的关键。
- LLM的规模效应,在推荐系统领域同样适用,而且效果惊人!
未来,我们可以期待HLLM在更多推荐场景中大显身手,比如短视频推荐、广告推荐等等。也许,它就是我们通往更智能、更个性化推荐系统的“任意门”!
各位技术同仁,大模型与推荐系统的结合,才刚刚开始,未来可期!让我们一起期待更多激动人心的突破吧!

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)