
《TensorFlow深度学习》学习笔记
原文链接:https://github.com/dragen1860/Deep-Learning-with-TensorFlow-book目录基本概念TensorFlow 2.x与TensorFlow 1.x非线性模型与激活函数TensorFlow 万物皆可张量经典数据集加载随机打散与批训练模型预处理与循环训练基本概念epoch含义:把对数据集的所有样本训练一次称为一个 Epoch,共循环迭代nu
原文链接:https://github.com/dragen1860/Deep-Learning-with-TensorFlow-book
目录
基本概念
epoch含义:把对数据集的所有样本训练一次称为一个 Epoch,共循环迭代num_iterations个Epoch。
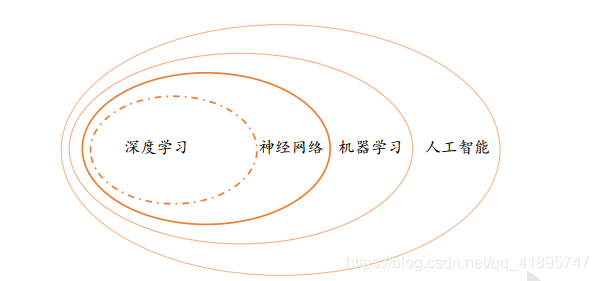
人工智能、 机器学习、 神经网络和深度学习的之间的关系
在机器学习中,有一门通过神经网络来学习复杂、抽象逻辑的方向,称为神经网络。神经网络方向的研究经历了两起两落。 2012 年开始,由于效果极为显著,应用深层神经网络技术在计算机视觉、 自然语言处理、机器人等领域取得了重大突破,部分任务上甚至超越了人类智能水平, 开启了以深层神经网络为代表的人工智能的第三次复兴。深层神经网络有了一个新名字,叫作深度学习。 一般来讲, 神经网络和深度学习的本质区别并不大,深度学习特指基于深层神经网络实现的模型或算法。 人工智能、 机器学习、 神经网络和深度学习的之间的关系。
深度学习与机器学习、浅层神经网络、基于规则的系统之间的区别
神经网络发展时间线
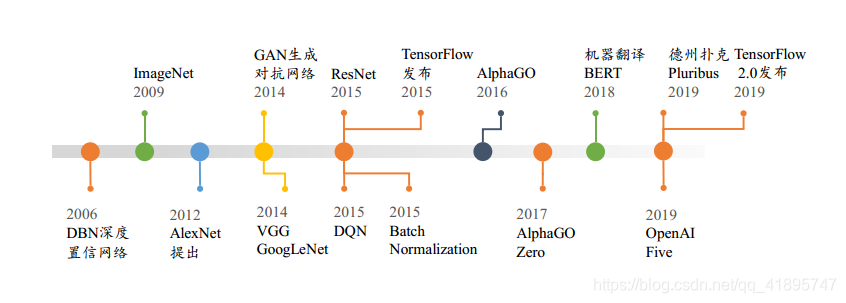
TensorFlow 2.x与TensorFlow 1.x
TensorFlow 2 是一个与 TensorFlow 1.x 使用体验完全不同的框架, TensorFlow 2 不兼容TensorFlow 1.x 的代码,同时在编程风格、 函数接口设计等上也大相径庭,TensorFlow 1.x的代码需要依赖人工的方式迁移,自动化迁移方式并不靠谱。 Google 即将停止更新TensorFlow 1.x,不建议学习 TensorFlow 1.x 版本。
TensorFlow 2 支持动态图优先模式,在计算时可以同时获得计算图与数值结果, 可以代码中调试并实时打印数据,搭建网络也像搭积木一样, 层层堆叠, 非常符合软件开发思维。
以简单的2.0 + 4.0的加法运算为例,在 TensorFlow 1.x 中,首先创建计算图,代码如下:
import tensorflow as tf
# 1.创建计算图阶段,此处代码需要使用 tf 1.x 版本运行
# 创建 2 个输入端子, 并指定类型和名字
a_ph = tf.placeholder(tf.float32, name='variable_a')
b_ph = tf.placeholder(tf.float32, name='variable_b')
# 创建输出端子的运算操作,并命名
c_op = tf.add(a_ph, b_ph, name='variable_c')
# 2.运行计算图阶段,此处代码需要使用 tf 1.x 版本运行
# 创建运行环境
sess = tf.InteractiveSession()
# 初始化步骤也需要作为操作运行
init = tf.global_variables_initializer()
sess.run(init) # 运行初始化操作,完成初始化
# 运行输出端子,需要给输入端子赋值
c_numpy = sess.run(c_op, feed_dict={a_ph: 2., b_ph: 4.})
# 运算完输出端子才能得到数值类型的 c_numpy
print('a+b=',c_numpy)TensorFlow 1.x当中的计算步骤如上面的代码所示,计算过程比较复杂,必须先建立算子,然后创建运行环境,然后执行运行环境初始化和运行环境,总的来说非常复杂。只是为了计算2.0+4.0这个运算步骤。
但是TensorFlow 2.x的计算方法就不一样了,如下:
import tensorflow as tf
# 此处代码需要使用 tf 2 版本运行
# 1.创建输入张量,并赋初始值
a = tf.constant(2.)
b = tf.constant(4.)
# 2.直接计算, 并打印结果
print('a+b=',a+b)这种运算时同时创建计算图a=b+c和数值结果6.0 = 2.0 + 4.0的方式叫做命令式编程,也称为动态图模式。 TensorFlow 2 和 PyTorch 都是采用动态图(优先)模式开发,调试方便,所见即所得。一般来说,动态图模式开发效率高,但是运行效率可能不如静态图模式。 TensorFlow 2 也支持通过 tf.function 将动态图优先模式的代码转化为静态图式,实现开发和运行效率的双赢。
非线性模型与激活函数
为什么要非线性模型?
线性模型的缺点:线性模型是机器学习中间最简单的数学模型之一,参数量少, 计算简单, 但是只能表达线性关系。即使是简单如数字图片识别任务, 它也是属于图片识别的范畴,人类目前对于复杂大脑的感知和决策的研究尚处于初步探索阶段, 如果只使用一个简单的线性模型去逼近复杂的人脑图片识别模型,很显然不能胜任。
用激活函数将线性模型转化成非线性模型
既然线性模型不可行, 我们可以给线性模型嵌套一个非线性函数, 即可将其转换为非线性模型。 我们把这个非线性函数称为激活函数(Activation Function)![]()
常见的两种激活函数sigmoid和ReLU函数如下:
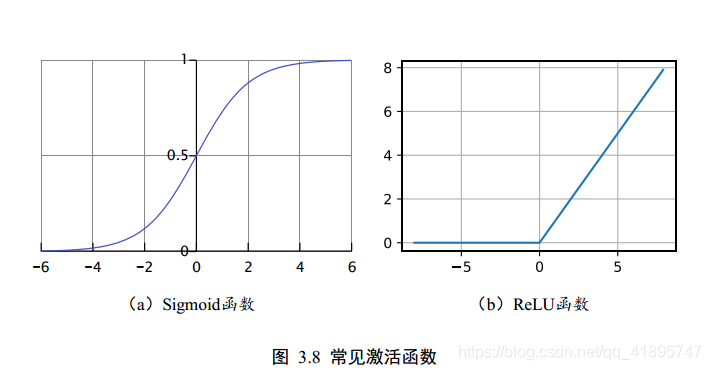
ReLU 函数非常简单,在y = x 的基础上面截去了 x = 0 的部分, 可以直观地理解为ReLU 函数仅保留正的输入部份, 清零负的输入,具有单边抑制特性。 虽然简单, ReLU 函数却有优良的非线性特性, 而且梯度计算简单, 训练稳定,是深度学习模型使用最广泛的激活函数之一。
TensorFlow 万物皆可张量
TensorFlow 是一个面向深度学习算法的科学计算库, 内部数据保存在张量(Tensor)对象上,所有的运算操作(Operation,简称 OP)也都是基于张量对象进行的。复杂的神经网络算法本质上就是各种张量相乘、相加等基本运算操作的组合。
数据类型分类:
- 标量(Scalar)。 单个的实数,如 1.2, 3.4 等,维度(Dimension)数为 0, shape 为[]。
- 向量(Vector)。n个实数数的有序集合,通过中括号包裹,如[1.2], [1.2, 3.4]等,维度数为 1,长度不定, shape 为[n]。
- 矩阵(Matrix)。n行m列实数的有序集合,如[[1,2],[3,4]]。
- 张量(Tensor)。 所有维度数dim > 2的数组统称为张量。 张量的每个维度也作轴(Axis),一般维度代表了具体的物理含义, 比如 Shape 为[2,32,32,3]的张量共有 4 维,如果表示图片数据的话,每个维度/轴代表的含义分别是图片数量、 图片高度、 图片宽度、 图片通道数,其中 2 代表了 2 张图片, 32 代表了高、 宽均为 32, 3 代表了RGB 共 3 个通道。张量的维度数以及每个维度所代表的具体物理含义需要由用户自行定义。
在 TensorFlow 中间,为了表达方便,一般把标量、向量、矩阵也统称为张量,不作区分,需要根据张量的维度数或形状自行判断。
创建张量:
a = 1.2 # python 语言方式创建标量
aa = tf.constant(1.2) # TF 方式创建标量
type(a), type(aa), tf.is_tensor(aa)
输出:
(float, tensorflow.python.framework.ops.EagerTensor, True)待优化张量 tf.Variable
为了区分需要计算梯度信息的张量与不需要计算梯度信息的张量, TensorFlow 增加了一种专门的数据类型来支持梯度信息的记录: tf.Variable。 tf.Variable 类型在普通的张量类型基础上添加了 name, trainable 等属性来支持计算图的构建。 由于梯度运算会消耗大量的计算资源,而且会自动更新相关参数,对于不需要的优化的张量,如神经网络的输入X不需要通过 tf.Variable 封装;相反,对于需要计算梯度并优化的张量, 如神经网络层的W和B,需要通过 tf.Variable 包裹以便 TensorFlow 跟踪相关梯度信息。
通过 tf.Variable()函数可以将普通张量转换为待优化张量,例如:
a = tf.constant([-1, 0, 1, 2]) # 创建 TF 张量
aa = tf.Variable(a) # 转换为 Variable 类型
aa.name, aa.trainable # Variable 类型张量的属性
输出:
('Variable:0',True)其中张量的 name 和 trainable 属性是 Variable 特有的属性, name 属性用于命名计算图中的变量,这套命名体系是 TensorFlow 内部维护的, 一般不需要用户关注 name 属性; trainable属性表征当前张量是否需要被优化,创建 Variable 对象时是默认启用优化标志,可以设置trainable=False 来设置张量不需要优化。
打印含义
打印结果:
Tensor("add_2:0", shape=(2,), dtype=float32)
add_2:0代表我们计算图中要加的个数,0——2+1 一共四个数。(我一直不太明白这里的add_2:0代表什么意思,可以放在这里以后研究)
经典数据集加载
在 TensorFlow 中, keras.datasets 模块提供了常用经典数据集的自动下载、 管理、 加载与转换功能,并且提供了 tf.data.Dataset 数据集对象, 方便实现多线程(Multi-threading)、 预处理(Preprocessing)、 随机打散(Shuffle)和批训练(Training on Batch)等常用数据集的功能。
常用经典数据集如下:
- Boston Housing, 波士顿房价趋势数据集,用于回归模型训练与测试。
- CIFAR10/100, 真实图片数据集,用于图片分类任务。
- MNIST/Fashion_MNIST, 手写数字图片数据集,用于图片分类任务。
- IMDB, 情感分类任务数据集,用于文本分类任务
这些数据集在机器学习或深度学习的研究和学习中使用的非常频繁。对于新提出的算法,一般优先在经典的数据集上面测试,再尝试迁移到更大规模、更复杂的数据集上。
通过 datasets.xxx.load_data()函数即可实现经典数据集的自动加载,其中 xxx 代表具体的数据集名称,如“CIFAR10”、“MNIST”。 TensorFlow 会默认将数据缓存在用户目录下的.keras/datasets 文件夹, 如图 5.6 所示,用户不需要关心数据集是如何保存的。 如果当前数据集不在缓存中,则会自动从网络下载、 解压和加载数据集;如果已经在缓存中, 则自动完成加载。例如,自动加载 MNIST 数据集:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets # 导入经典数据集加载模块
# 加载 MNIST 数据集
(x, y), (x_test, y_test) = datasets.mnist.load_data()
print('x:', x.shape, 'y:', y.shape, 'x test:', x_test.shape, 'y test:',
y_test)通过 load_data()函数会返回相应格式的数据,对于图片数据集 MNIST、 CIFAR10 等,会返回 2 个 tuple,第一个 tuple 保存了用于训练的数据 x 和 y 训练集对象;第 2 个 tuple 则保存了用于测试的数据 x_test 和 y_test 测试集对象,所有的数据都用 Numpy 数组容器保存。
数据加载进入内存后,需要转换成 Dataset 对象, 才能利用 TensorFlow 提供的各种便捷功能。通过 Dataset.from_tensor_slices 可以将训练部分的数据图片 x 和标签 y 都转换成Dataset 对象:
train_db = tf.data.Dataset.from_tensor_slices((x, y)) # 构建 Dataset 对象将数据转换成 Dataset 对象后,一般需要再添加一系列的数据集标准处理步骤,如随机打散、 预处理、 按批装载等。
随机打散与批训练
随机打散
通过 Dataset.shuffle(buffer_size)工具可以设置 Dataset 对象随机打散数据之间的顺序,防止每次训练时数据按固定顺序产生,从而使得模型尝试“记忆”住标签信息,代码实现如下:
train_db = train_db.shuffle(10000) # 随机打散样本,不会打乱样本与标签映射关系其中, buffer_size 参数指定缓冲池的大小,一般设置为一个较大的常数即可。 调用 Dataset提供的这些工具函数会返回新的 Dataset 对象,可以通过
db = db. step1(). step2(). step3. ()的方式按序完成所有的数据处理步骤, 实现起来非常方便。
批训练
为了利用显卡的并行计算能力,一般在网络的计算过程中会同时计算多个样本,我们把这种训练方式叫做批训练,其中一个批中样本的数量叫做 Batch Size。为了一次能够从Dataset 中产生 Batch Size 数量的样本,需要设置 Dataset 为批训练方式,实现如下:
train_db = train_db.batch(128) # 设置批训练, batch size 为 128其中 128 为 Batch Size 参数,即一次并行计算 128 个样本的数据。 Batch Size 一般根据用户的 GPU 显存资源来设置,当显存不足时,可以适量减少 Batch Size 来减少算法的显存使用量。
模型预处理与循环训练
预处理:
从 keras.datasets 中加载的数据集的格式大部分情况都不能直接满足模型的输入要求,因此需要根据用户的逻辑自行实现预处理步骤。 Dataset 对象通过提供 map(func)工具函数, 可以非常方便地调用用户自定义的预处理逻辑, 它实现在 func 函数里。例如,下方代码调用名为 preprocess 的函数完成每个样本的预处理:
# 预处理函数实现在 preprocess 函数中,传入函数名即可
train_db = train_db.map(preprocess)考虑 MNIST 手写数字图片,从 keras.datasets 中经.batch()后加载的图片 x shape 为 [b, 28, 28],像素使用 0~255 的整型表示; 标签 shape 为[b],即采样数字编码的方式。实际的神经网络输入,一般需要将图片数据标准化到[0,1]或[-1,1]等 0 附近区间,同时根据网络的设置,需要将 shape 为[28,28]的输入视图调整为合法的格式;对于标签信息,可以选择在预处理时进行 One-hot 编码,也可以在计算误差时进行 One-hot 编码。
根据下一节的实战设定,我们将 MNIST 图片数据映射到![]() 区间内,调整为[b, 28*28],对于标签数据,我们选择在预处理函数里面进行 One-hot 编码。 preprocess 函
区间内,调整为[b, 28*28],对于标签数据,我们选择在预处理函数里面进行 One-hot 编码。 preprocess 函
数实现如下:
def preprocess(x, y): # 自定义的预处理函数
# 调用此函数时会自动传入 x,y 对象, shape 为[b, 28, 28], [b]
# 标准化到 0~1
x = tf.cast(x, dtype=tf.float32) / 255.
x = tf.reshape(x, [-1, 28*28]) # 打平
y = tf.cast(y, dtype=tf.int32) # 转成整型张量
y = tf.one_hot(y, depth=10) # one-hot 编码
# 返回的 x,y 将替换传入的 x,y 参数,从而实现数据的预处理功能
return x,y循环训练:
对于 Dataset 对象, 在使用时可以通过
for step, (x,y) in enumerate(train_db): # 迭代数据集对象,带 step 参数
或者:
for x,y in train_db: # 迭代数据集对象方式进行迭代,每次返回的 x 和 y 对象即为批量样本和标签。 当对 train_db 的所有样本完成一次迭代后, for 循环终止退出。 这样完成一个 Batch 的数据训练,叫做一个 Step;通过多个 step 来完成整个训练集的一次迭代,叫做一个 Epoch。在实际训练时,通常需要对数据集迭代多个 Epoch 才能取得较好地训练效果。例如,固定训练 20 个 Epoch,实现如下:
for epoch in range(20): # 训练 Epoch 数
for step, (x,y) in enumerate(train_db): # 迭代 Step 数
# training...此外, 也可以通过设置 Dataset 对象,使得数据集对象内部遍历多次才会退出,实现如下:
train_db = train_db.repeat(20) # 数据集迭代 20 遍才终止上述代码使得 for x,y in train_db 循环迭代 20 个 epoch 才会退出。不管使用上述哪种方式,都能取得一样的效果。
未完待续……
PS:最近的时间可能少一些,但是我感觉还是要把自己的知识经常管理,否则过段时间就记混了或者忘记了,写blog管理知识的习惯不能丢呀~

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)