
论文阅读:FACTSCORE: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
评估大语言模型(LMs)生成的长文本的事实性并不容易。一方面,生成的文本里往往既有真实信息,也有虚假信息,只用 “对” 或 “错” 来判断文本质量不够准确;另一方面,人工评估既费时间又费钱。在这篇论文里,研究人员提出了FACTSCORE(事实精确原子分数)这种新的评估方法。它会把模型生成的文本拆解成一个个 “原子事实”,然后计算这些原子事实里能在可靠知识来源里找到依据的比例。
总目录:大模型安全相关研究
b站视频:https://www.bilibili.com/video/BV1YP9MYDEi8/
文章目录
FACTSCORE:长文本生成中事实精度的细粒度原子级评估
FACTSCORE: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
https://aclanthology.org/2023.emnlp-main.741.pdf
红色字体代表在最后一章:知识点补充,有详细讲解
方法总览
作者们提出了一个叫FACTSCORE的方法,用来更精细地评估大模型(比如ChatGPT)生成的长文本(比如人物传记)是否准确。简单来说,这个方法像“放大镜”一样,把生成的一大段文字拆成一个个小事实(比如“张三1990年出生”),然后逐个检查这些小事实是否有可靠来源(比如维基百科)支持。
举个栗子🌰:
假设模型生成这样一段话:
“李四是科学家,2020年获得诺贝尔奖,养了3只猫。”
FACTSCORE会把它拆成:
- 李四是科学家 ✅(维基百科支持)
- 李四2020年获诺贝尔奖 ❌(维基显示他2021年获奖)
- 李四养了3只猫 ❓(维基没提)
最终得分 = 正确的小事实数量 / 总小事实数量 = 1/3 ≈ 33%
这个方法有两大亮点:
-
细粒度评估:
传统方法可能直接判断整段话“基本正确”或“错误”,而FACTSCORE能发现部分正确的情况(比如例子中1对2错)。 -
自动打分:
用AI+搜索引擎自动检查事实,错误率不到2%,比人工检查快100倍。比如评估6500段文本,人工要花26万人民币,用这个方法几乎免费。
实际测试发现🔍:
- 商业模型:ChatGPT事实准确率58%,加了搜索引擎的PerplexityAI也只有71%。
- 公开模型:Vicuna和Alpaca表现最好,但准确率仍远低于人类。
- 通病:模型写的内容越靠后错误越多,冷门人物传记错误率飙升(比如ChatGPT写冷门人物时准确率从80%暴跌到16%)。
总之,这个方法像“事实检测仪”,帮我们看清AI生成内容哪里靠谱、哪里在瞎编。论文还开源了工具包(pip install factscore),所有人都能直接用。
摘要
评估大语言模型(LMs)生成的长文本的事实性并不容易。一方面,生成的文本里往往既有真实信息,也有虚假信息,只用 “对” 或 “错” 来判断文本质量不够准确;另一方面,人工评估既费时间又费钱。在这篇论文里,研究人员提出了FACTSCORE(事实精确原子分数)这种新的评估方法。它会把模型生成的文本拆解成一个个 “原子事实”,然后计算这些原子事实里能在可靠知识来源里找到依据的比例。
研究人员对一些先进的商业大语言模型,像InstructGPT、ChatGPT,还有结合搜索引擎的PerplexityAI,进行了大量人工评估,得出它们生成人物传记的FACTSCORE。结果发现这些模型存在不少错误,比如ChatGPT的FACTSCORE只有58%。由于人工评估成本高,研究人员又引入了一个自动评估模型。这个模型利用检索技术和强大的语言模型来估算FACTSCORE,误差不到2%。最后,他们用这个自动评估指标对13个新的大语言模型生成的6500篇文本进行评估。如果人工评估这些文本要花2.6万美元。评估发现GPT-4和ChatGPT比开源模型更符合事实,而Vicuna和Alpaca在开源模型里表现较好。FACTSCORE可以通过 “pip install factscore” 命令供公众使用。
1. 引言
大语言模型生成的长文本应用广泛,但评估其事实精确性很困难。原因有两个:一是生成的文本包含大量信息,真假混杂,简单的二元判断(对或错)无法准确评估;二是逐一验证每条信息耗时又耗钱。
论文提出FACTSCORE来评估大语言模型。计算FACTSCORE需要两步:第一步,把模型生成的文本拆分成原子事实,原子事实就是只包含一条信息的简短陈述;第二步,给每个原子事实贴上 “支持” 或 “不支持” 的标签,以此实现对事实精确性的细致评估。研究人员选择评估人物传记生成任务中的FACTSCORE,因为人物传记里的陈述可验证,而且涵盖不同国籍、职业和知名度的人物,评估范围广。
研究人员对InstructGPT、ChatGPT和PerplexityAI进行了大量人工标注,得到它们的FACTSCORE。结果显示,这些商用大语言模型错误不少,InstructGPT的FACTSCORE是42%,ChatGPT是58%,PerplexityAI是71%。而且,涉及的实体越罕见,模型的FACTSCORE越低,比如ChatGPT在处理罕见实体时,FACTSCORE从80% 降到16%。
由于人工评估成本高,研究人员引入了自动评估模型。该模型将文本分解为原子事实,借助知识源检索和强大的语言模型进行验证,误差小于2%,可大规模评估新的大语言模型。通过对13个大语言模型的6500次生成结果进行评估(人工评估需花费2.6万美元),发现GPT-4和ChatGPT比开源模型更具事实性,但仍不如人类;开源模型之间差异大,Vicuna和Alpaca表现较好。
论文的主要贡献有三点:
一是提出FACTSCORE评估大语言模型的事实精确性,人工评估发现现有大语言模型的FACTSCORE较低;
二是引入自动评估模型,误差小于2%,可大规模评估新模型;
三是开源FACTSCORE和标注数据,方便公众使用,同时建议后续拓展FACTSCORE的应用范围并改进评估模型。

图1展示了FACTSCORE的基本概念。它是指模型生成文本中的原子事实,能在给定知识源中得到支持的比例,用于更细致地评估大语言模型生成文本的事实精确性。比如图中有两个模型,上面的模型得到了66.7% 的分数,下面的模型得到10.0% 的分数。要是按照以前的评估方法,可能会认为这两个模型都不合格,都给0分,但实际上上面的模型比下面的模型生成的内容准确得多,FACTSCORE就能体现出这种差异。而且,FACTSCORE既可以通过人工评估得出,也能通过自动评估模型计算,自动评估可以在不需要人工干预的情况下,对大量的大语言模型进行评估。
2 相关工作
文本生成中的事实精确性
文本生成中的事实精确性一直是自然语言处理(NLP)领域的研究热点。早期的研究主要集中在特定问题上的模型,比如对话系统(Shuster et al., 2021)或者短答案问答系统(Kadavath et al., 2022; Kandpal et al., 2022; Mallen et al., 2023; Nori et al., 2023)。这些研究通常关注模型在特定任务上的表现,比如对话系统中的事实性错误或者问答系统中的答案准确性。
近期的研究开始关注更长文本生成的事实精确性。例如,Lee et al. (2022) 使用代理指标来评估生成文本的事实精确性,比如检查生成文本中的命名实体是否出现在相关主题的文章中。还有一些研究关注模型提供的引用(attributions)的准确性(Gao et al., 2022; Liu et al., 2023a; Yue et al., 2023; Gao et al., 2023)。这些研究通常通过检查模型生成的引用是否与知识源一致来评估事实精确性。
与这些工作不同,论文的研究有以下几点创新:
- 论文考虑了更长的文本生成,涵盖了多种最先进的语言模型(有无搜索功能)。
- 论文通过人类专家和自动化评估器对这些模型进行了细致的评估。
- 论文将这种方法应用于大量新的语言模型,提供了更广泛的见解。
事实验证
论文的工作与事实验证领域密切相关。事实验证通常涉及自动检查声明句子是否与大型知识源(如维基百科或科学文献)一致(Thorne et al., 2018; Wadden et al., 2020)。大多数文献假设每个声明是一个单一的、原子的事实,有时会结合上下文进行建模(Nakov et al., 2018; Mihaylova et al., 2019; Shaar et al., 2022)。也有一些工作通过将长句子或文本分解为原子事实来进行验证(Fan et al., 2020; Wright et al., 2022; Chen et al., 2022; Kamoi et al., 2023),论文的工作从这些研究中汲取了灵感。
与这些文献的主要区别在于,论文关注的是长篇模型生成的文本,而不是人类书写的句子级声明。例如,论文不仅关注单个句子是否正确,而是关注整个段落或文章中的事实是否准确。
基于模型的评估
先前的研究使用学习模型来定义自动化评估指标(Zhang et al., 2020; Liu et al., 2023b)。这包括在摘要任务中使用问答(QA)或自然语言推理(NLI)来评估摘要与源文档之间的一致性(Kryscinski et al., 2020; Wang et al., 2020; Fabbri et al., 2022; Deutsch et al., 2021; Laban et al., 2022)。论文的工作从这些研究中汲取了灵感,通过检查生成文本中的信息是否由大型文本语料库支持来评估语言模型生成的事实精确性。
例如,作者可以使用一个模型来评估生成的摘要是否与原始文档中的信息一致。如果生成的摘要中的每个事实都能在原始文档中找到支持,那么这个摘要就被认为是事实准确的。这种方法可以应用于各种文本生成任务,包括长篇文本生成。
3 FACTSCORE:评估长文本生成的事实精确性
这部分内容介绍了一种新的评估大语言模型(LM)的方法——FACTSCORE,该方法用于考量大语言模型生成的原子事实的事实精确性。研究人员通过人工评估来计算当前先进大语言模型的FACTSCORE(在3.3节中阐述),并对结果进行讨论(在3.4节中展开)。虽然FACTSCORE能够对事实精确性进行严格且细粒度的评估,但它耗时又费钱,这也促使了第4节中自动评估方法的产生。
3.1 定义
FACTSCORE基于两个关键的理念:
- 关键理念1:将原子事实作为评估单元:长文本包含很多信息,这些信息有的是真的,有的是假的。以前的研究尝试把句子当作评估单元,可问题是,哪怕只是一个句子,里面也可能既有真实的信息,又有虚假的信息,比如使用ChatGPT生成的句子中,40%都存在这种情况。之前和同期的研究,要么(1)定义一个 “部分支持” 的额外标签(像Manakul等人在2023年、Liu等人在2023年的研究 ),但这个定义可能比较主观,不同人看法难以统一;要么(2)采用最严格的 “支持” 定义,要求句子里的每一条信息都必须有依据(比如Rashkin等人在2021年、Gao等人在2022年的研究),这样就忽略了部分信息有依据的情况,比如图1里的两个文本生成结果,即便第一个比第二个准确得多,但按照这种严格定义,都会给0分。
在本文中,研究人员把原子事实定义为传达一条信息的简短句子(如图1中的例子所示),这类似于文本摘要里的内容单元(Nenkova和Passonneau在2004年提出的概念)。对于一条信息来说,原子事实是比句子更基本的单元,能提供更细粒度的评估,例如在图1中,就能给第一个生成结果更高的评价。
- 关键理念2:事实精确性取决于给定的知识源:以前的研究常常把事实精确性看作一个绝对的、全局的真理(如Manakul等人在2023年的研究 )。但本文持有不同观点,认为一个陈述是否真实,应该取决于终端用户认为值得信赖和可靠的特定知识源。所以,不关注原子事实在全局上是真还是假,而是看它是否能在给定的知识源中找到支持依据。这在事实验证的相关研究中也有应用(Wadden等人在2022年的研究 ),因为不同知识源之间信息冲突的情况很常见。
下面是FACTSCORE的具体定义:
设 M M M为要评估的语言模型, X \mathcal{X} X为一组提示(prompt), C \mathcal{C} C为知识源。对于 x ∈ X x \in \mathcal{X} x∈X,模型的响应为 y = M ( x ) y = M(x) y=M(x), A y \mathcal{A}_y Ay是 y y y中的原子事实列表。 M M M的FACTSCORE定义如下:
f ( y ) = 1 ∣ A y ∣ ∑ a ∈ A y I [ a is supported by C ] f(y)=\frac{1}{|\mathcal{A}_y|}\sum_{a\in\mathcal{A}_y}\mathbb{I}[a \text{ is supported by } \mathcal{C}] f(y)=∣Ay∣1a∈Ay∑I[a is supported by C]
FACTSCORE ( M ) = E x ∈ X [ f ( M x ) ∣ M x responds ] \text{FACTSCORE}(M)=\mathbb{E}_{x\in\mathcal{X}}[f(M_x)|M_x \text{ responds}] FACTSCORE(M)=Ex∈X[f(Mx)∣Mx responds]
这里 M ( x ) responds M(x) \text{ responds} M(x) responds表示 M M M对提示 x x x做出了响应。这个定义基于以下假设:
- 原子事实是否能得到知识源 C \mathcal{C} C的支持是明确的,不存在争议。
- 依据Krishna等人在2023年的研究, A y \mathcal{A}_y Ay中的每个原子事实都具有同等重要性。
- 知识源 C \mathcal{C} C中的信息之间不会相互冲突或重叠。
在论文的后续部分,研究人员建议使用人物传记作为 X \mathcal{X} X,维基百科作为 C \mathcal{C} C,因为它们在一定程度上合理地满足了这些假设(在3.3节中有相关内容)。在 “局限性” 部分,会更详细地讨论在哪些情况下这些假设成立,哪些情况下可能不成立。
需要注意的是,FACTSCORE只考虑了精确性,没有考虑召回率。例如,一个经常不回答问题,或者生成的文本包含较少事实的模型,可能会有较高的FACTSCORE,即便这并不是我们想要的结果。关于事实召回率的评估,会留到未来的研究中(在 “局限性” 部分有更多讨论)。
3.2 研究的大语言模型
这部分介绍了用于评估的三个大语言模型(用 L M S U B J LM_{SUBJ} LMSUBJ 表示,即作为研究对象的大语言模型):
- InstructGPT:它基于text-davinci-003,是在Ouyang等人2022年的研究基础上更新而来的。你可以把它当作一个经过特殊训练的智能工具,能按照你的指令生成内容。比如你让它写一篇关于环保的短文,它就会根据学到的知识和训练模式输出相应文字。
- ChatGPT:由OpenAI在2022年推出,这个模型很有名,能和人进行各种主题的对话交流。无论是问它文学作品的解读,还是生活中的小窍门,它都能给出回答。
- PerplexityAI:它比较特别,把搜索引擎和语言模型结合在一起了。想象一下,你有一个助手,它不仅肚子里有很多知识,还能快速上网查找新信息。当你问它一些比较新或者复杂的问题,比如 “最近的人工智能技术有哪些突破” ,它就能一边用自己的语言模型能力思考,一边通过搜索引擎找资料,然后给出更全面的答案。
3.3 数据
这部分讲的是如何基于之前提出的定义,通过人工评估来判断大语言模型生成文本的事实精确性。之所以选择让模型生成人物传记,并和维基百科的内容进行对比评估,有以下几个原因:
- 客观性和明确性:人物传记记录的是客观事实,不是主观感受或者有争议的内容,而且里面的信息很具体,比如人物的出生日期、职业等,这就满足了3.1节中提到的假设1,也就是原子事实是否能得到知识源支持是明确无争议的。
- 评估范围广:人物传记涵盖了不同国籍、职业,以及不同知名度的人。从著名的科学家、政治家,到一些相对小众领域的专业人士,都能通过人物传记来评估模型,这样可以更全面地考察模型的能力。
- 维基百科的优势:维基百科关于人物的信息覆盖面比较广,而且内容相对一致,不会自相矛盾,满足了假设3,即知识源中的信息不会相互冲突或重叠。
接下来是数据收集的过程,研究人员设计了一个详细的标注流程,通过以下几个步骤来给模型生成的长文本确定事实精确性:
- 步骤0:选取人物实体:从Wikidata(一个免费的知识库)里选了183个在维基百科上有对应页面的人物。选这些人物是按照附录A.1里定义的类别,均匀抽样的。比如从不同职业类别,像科学家、艺术家、运动员等里面都选一些人。
- 步骤1:获取生成内容:给前面提到的三个大语言模型输入提示 “Tell me a bio of ”(也就是 “给我讲讲<某个人物>的生平” ),然后直接获取模型生成的内容。同时,还制定了一些规则,把那些模型没有做出回答的情况筛选出去。
- 步骤2:生成原子事实:人工标注人员把模型生成的内容拆分成一个个原子事实。为了节省标注时间,先用InstructGPT把内容拆分成原子事实,标注人员可以在此基础上进行修改和完善,具体细节在附录A.2里。比如模型生成的人物传记里有 “他出生在纽约,是一位著名作家,写过很多小说” ,标注人员就可以把它拆成 “他出生在纽约”“他是一位著名作家”“他写过很多小说” 这些原子事实。
- 步骤3:标注事实精确性和编辑:找另一组人工标注人员给每个原子事实贴上三个标签中的一个。如果某个原子事实明显和提示无关,比如问的是某个科学家的生平,模型却提到了一个不相关的电影情节,那就直接标记为 “Irrelevant(不相关)” ,不需要再去验证。如果相关,就根据英文维基百科来验证,然后标记为 “Supported(有依据)” 或者 “Not-supported(无依据)” 。
研究人员通过Upwork(一个自由职业者平台)招募了自由职业者来做标注工作,每小时支付15 - 25美元。因为标注工作很费时间和精力,所以平均每个模型生成的内容标注成本是4美元。为了保证标注的质量,对10%的数据安排了两个自由职业者分别标注,然后计算他们标注结果的一致率,InstructGPT的一致率是96%,ChatGPT是90%,PerplexityAI是88%,更多细节在附录A.3里。
3.4 结果
这部分主要介绍了对三个大语言模型(InstructGPT、ChatGPT、PerplexityAI)生成人物传记进行评估后的相关结果。
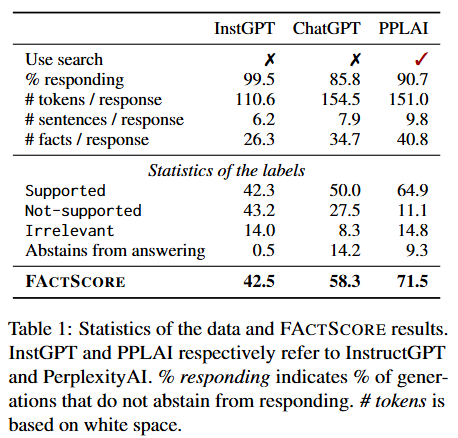
Table 1(数据统计和FACTSCORE结果)
- 模型是否使用搜索功能:InstructGPT和ChatGPT都不使用搜索功能,而PerplexityAI使用搜索功能。
- 做出响应的比例:InstructGPT有99.5%的情况做出了响应;ChatGPT是85.4% ;PerplexityAI为90.1%。这意味着ChatGPT和PerplexityAI经常不回答问题。
- 每次响应的相关数据:比如每个响应的token数量(可以理解为文字数量),InstructGPT平均是110.6,ChatGPT是154.5,PerplexityAI是151.0;每个响应的句子数量,InstructGPT是6.2,ChatGPT是7.9,PerplexityAI是9.8 ;每个响应包含的事实数量,InstructGPT是26.3,ChatGPT是34.7,PerplexityAI是40.8。
- 标注统计:被标记为 “Supported(有依据)” 的比例,InstructGPT是50.0%,ChatGPT是64.9%,PerplexityAI是71.5%;“Not-supported(无依据)” 的比例,InstructGPT是43.2%,ChatGPT是27.5%,PerplexityAI是11.1%;“Irrelevant(不相关)” 的比例,InstructGPT是14.0%,ChatGPT是8.3%,PerplexityAI是14.8%;“Abstains from answering(不回答)” 的比例,InstructGPT是0.5%,ChatGPT是14.2%,PerplexityAI是9.3% 。
- FACTSCORE:InstructGPT的FACTSCORE是42.5%,ChatGPT是58.3%,PerplexityAI是71.5%。说明这三个模型在事实精确性上都存在问题,即使PerplexityAI使用了搜索引擎,也没有达到理想的完全准确的状态。
模型在事实精确性上的整体表现
所有被研究的大语言模型都存在事实精确性错误。InstructGPT和ChatGPT的FACTSCORE较低,PerplexityAI虽然相对较高,但也没有达到满分。ChatGPT和PerplexityAI经常不回答问题,这可能是它们提高事实精确性的一种方式,而InstructGPT很少不回答,可能是因为没有经过相关训练。此外,PerplexityAI经常直接复制搜索结果,导致出现很多与提示不相关的事实,而InstructGPT和ChatGPT很少出现这种情况。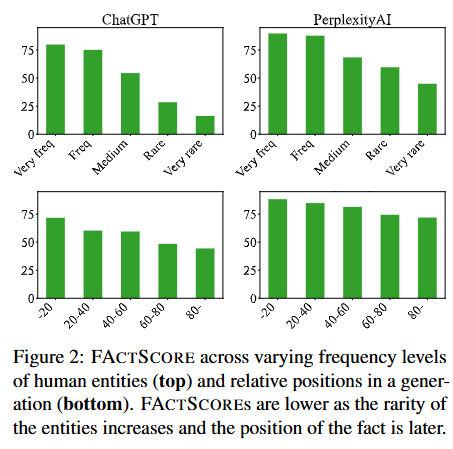
Figure 2(FACTSCORE在不同情况下的表现)
- 按人物实体出现频率划分(图2上半部分):展示了在预训练语料库中,不同频率的主题实体(人物)下的事实精确性。可以看到,随着实体的稀有程度增加,所有大语言模型的FACTSCORE都明显下降。比如对于非常常见的人物,模型的FACTSCORE较高,但对于非常稀有的人物,FACTSCORE就变得很低。这和之前一些研究中提到的短问答准确性与预训练数据中实体频率高度相关的结论一致。不过,与其他研究中提到的带有检索功能的模型对稀有实体的问答准确性较稳定不同,PerplexityAI的FACTSCORE随着实体稀有度增加显著下降,在原子级别和句子级别分别下降了50%和64% 。
- 按生成内容中的相对位置划分(图2下半部分):显示了在模型生成的内容中,不同相对位置的事实精确性。结果表明,所有模型生成内容的后半部分精确性明显更差。这可能是因为前半部分提到的信息在预训练数据中更常见,而且错误会向后传播影响后续内容。这也说明仅基于短答案评估大语言模型,可能无法全面评估它们的事实精确性,因为这样会忽略生成后期出现的错误。

Table 2(PerplexityAI “无依据” 错误的分类)
为了更好地理解PerplexityAI虽然使用了搜索引擎,但FACTSCORE却低于预期的原因,研究人员对30个标记为 “Not-supported(无依据)” 的随机样本进行了分类:
- 单句矛盾:维基百科中的单个句子与模型生成的内容直接矛盾,可能是在词汇层面(如数字、日期或实体),也可能是更广泛的层面。例如,模型说 “2023年11月25日,格洛弗·特谢拉成为美国公民” ,但维基百科显示是 “2020年11月” 。
- 页面级矛盾:阅读整个维基百科页面后发现的错误,通常是如果某个事实为真,维基百科应该提及但却没有提及。比如模型说某个演员出演了某部电影,但在维基百科相关页面却没有提到。
- 主观性内容:模型生成的内容具有主观性,通常是因为PerplexityAI从维基百科复制了主观性文本,比如直接复制了记者的一句话却没有意识到。
- 事实不相关:由于搜索错误,生成的内容与主题不相关。
- 维基百科内容不一致且错误:例如维基百科中关于某个人从电影《Kick》中获得奖项的信息不一致,有的说获得一个奖项,有的说获得多个奖项,而且引用的新闻文章也不支持相关说法。
- 标注错误:标注人员错误地分配了标签,通常是因为相关信息在主题的维基百科页面中没有提及(可能是因为这些信息不重要)。
此外,研究还发现,虽然PerplexityAI提供了引用,但引用与事实精确性几乎没有关联,有依据和无依据的句子中分别有36.0%和37.6% 带有引用。这表明结合搜索并提供引用的商业大语言模型可能并不像预期的那样可靠。
4 自动评估FACTSCORE的估算方法
人工评估事实精确性成本很高(每个生成内容4美元),原因在于要拿每个原子事实和大型知识源进行验证,这非常耗时,而且一个生成内容里包含很多(26 - 41个)原子事实。这就导致大语言模型的开发者和从业者没办法大规模地评估新模型在长文本生成方面的事实精确性。在这种情况下,论文提出了一个估算FACTSCORE的模型。这个估算模型能接收一组模型生成的内容,自动计算出FACTSCORE,并且可以应用到任何大语言模型上。
接下来,论文会介绍这个模型(4.1节),并展示它和人工评估相比的准确性(4.2节)。之后,用这个模型估算出的FACTSCORE去评估12个大语言模型(4.3节)。
4.1 模型
这个FACTSCORE估算模型分两步:首先把模型生成的内容拆分成一系列原子事实,然后拿每个原子事实和给定的知识源进行验证。研究人员发现,使用InstructGPT生成的原子事实(在3.3节数据收集里用过)效果不错,而且和人工拆分的结果很接近,这和之前的研究结论一致(Chen等人在2022年的研究)。所以这部分主要讲讲怎么拿每个原子事实和给定的知识源进行验证。
验证是基于一种叫 “零样本提示” 的方法,这里用一个专门用来评估的大语言模型 L M E V A L LM_{EVAL} LMEVAL (和被评估的大语言模型 L M S U B J LM_{SUBJ} LMSUBJ 区分开)。具体来说,就是构造一个提示,不同的验证方法构造提示的方式不一样,然后把提示输入到 L M E V A L LM_{EVAL} LMEVAL 里。 L M E V A L LM_{EVAL} LMEVAL 会分别给出 “正确” 和 “错误” 的概率,通过比较这两个概率来做出判断。如果没办法获取概率值(比如像ChatGPT这样的商业大语言模型),就看生成的文本里有没有出现 “正确” 或者 “错误” 这两个词来判断。
研究人员考虑了四种验证方法:
- 无上下文大语言模型法(No-context LM): 提示就是 “<原子事实> 是正确还是错误?” ,这种方法和Kadavath等人在2022年的研究很像。比如原子事实是 “牛顿发现了电” ,提示就是 “牛顿发现了电 是正确还是错误?” 然后把这个提示输入到 L M E V A L LM_{EVAL} LMEVAL 里判断。
- 检索 + 大语言模型法(Retrieve→LM):先从给定的知识源里检索相关的段落,然后构造提示输入到 L M E V A L LM_{EVAL} LMEVAL 。具体步骤是先检索出 k k k 个段落,把这些段落、给定的原子事实和 “是正确还是错误?” 连起来组成提示,再把提示输入到 L M E V A L LM_{EVAL} LMEVAL 得到判断结果。比如要验证 “爱因斯坦提出了相对论” 这个原子事实,就先从知识源(像维基百科)里找和爱因斯坦、相对论有关的段落,然后和原子事实一起组成提示,让 L M E V A L LM_{EVAL} LMEVAL 判断。
- 非参数概率法(Nonparametric Probability,NP):基于非参数似然来做判断。先把原子事实里的每个词都盖住,用一个非参数掩码大语言模型(Min等人在2023年的研究)计算每个被盖住词出现的可能性,再把所有词的概率求平均,最后根据一个设定的阈值来判断原子事实是正确还是错误。
- 检索 + 大语言模型 + 非参数概率法(Retrieve→LM + NP):是前面检索 + 大语言模型法和非参数概率法的结合,只有这两种方法都判断原子事实是 “有依据” 的时候,才最终判定为 “有依据” 。
研究人员用在Super Natural Instructions数据集上训练过的LLAMA 7B模型(Inst-LLAMA,Touvron等人在2023年、Wang等人在2022年的研究)和ChatGPT作为 L M E V A L LM_{EVAL} LMEVAL ,用基于T5的通用检索器(Generalizable T5-based Retrievers,GTR,Ni等人在2022年的研究)来检索段落。更多实现细节在附录B.1里。
4.2 估算模型的评估
这部分主要介绍了如何评估估算FACTSCORE的模型,以及评估的结果。
评估指标
研究人员使用了两种评估指标:
- 错误率(Error Rate,ER):指的是估算出来的FACTSCORE和真实的FACTSCORE之间的差值。比如,一个模型估算出某个大语言模型的FACTSCORE是60%,但真实的FACTSCORE是50%,那么错误率就是10%。
- 排名一致性:看估算出来的FACTSCORE能不能保持三个被评估的大语言模型(InstructGPT、ChatGPT、PerplexityAI)之间的真实排名顺序。比如真实情况下PerplexityAI的FACTSCORE最高,ChatGPT其次,InstructGPT最低,那么估算出来的结果也应该是这个顺序。
附录B.2中还讨论了其他考虑单个判断而非综合判断的评估指标的结果。评估使用的是3.3节中的数据。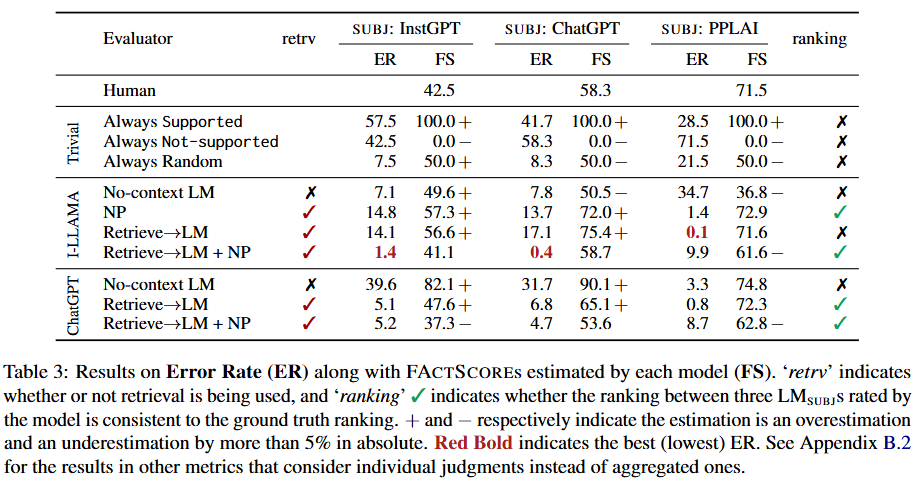
Table 3(评估结果表)
表格展示了不同估算模型的错误率(ER)以及它们估算出的FACTSCORE(FS),还包括是否使用了检索功能(retrv)以及估算结果是否保持了三个大语言模型的真实排名(ranking) :
- 人工评估结果:作为对比基准,InstructGPT、ChatGPT、PerplexityAI的真实FACTSCORE分别是42.5%、58.3%、71.5%。
- 简单基准模型:
- Always Supported(总是支持):不管实际情况如何,都判定所有原子事实都有依据。对InstructGPT、ChatGPT、PerplexityAI估算的FACTSCORE都是100%+(这里 “+” 表示高估),错误率分别是57.5、41.7、28.5。
- Always Not-supported(总是不支持):不管怎样都判定所有原子事实都没有依据。估算的FACTSCORE都是0% -(“-” 表示低估),错误率分别是42.5、58.3、71.5。
- Always Random(总是随机判断):随机判定原子事实是否有依据。估算的FACTSCORE是50%左右,错误率分别是7.5、8.3、21.5。
- 基于Inst-LLAMA的估算模型:
- No-context LM(无上下文大语言模型法):不使用检索功能(表格中 “retrv” 栏为 “X” )。对InstructGPT、ChatGPT、PerplexityAI估算的错误率分别是7.1、7.8、34.7,估算的FACTSCORE有高有低,并且没有保持三个模型的真实排名(“ranking” 栏为 “X” )。
- NP(非参数概率法):不使用检索功能。错误率分别是14.8、13.7、1.4,对InstructGPT和ChatGPT估算的FACTSCORE有高估情况。
- Retrieve→LM(检索 + 大语言模型法):使用检索功能(“retrv” 栏有对勾)。错误率分别是14.1、17.1、0.1,对InstructGPT和ChatGPT估算的FACTSCORE有高估情况。
- Retrieve→LM + NP(检索 + 大语言模型 + 非参数概率法):使用检索功能。错误率分别是1.4、0.4、9.9,对InstructGPT和ChatGPT的估算效果较好,能保持排名(“ranking” 栏有对勾)。
- 基于ChatGPT的估算模型:
- No-context LM(无上下文大语言模型法):不使用检索功能。错误率分别是39.6、31.7、3.3,估算的FACTSCORE有高估情况,没有保持排名。
- Retrieve→LM(检索 + 大语言模型法):使用检索功能。错误率分别是5.1、6.8、0.8,对InstructGPT估算的FACTSCORE有高估情况。
- Retrieve→LM + NP(检索 + 大语言模型 + 非参数概率法):使用检索功能。错误率分别是5.2、4.7、8.7,对InstructGPT和ChatGPT的估算结果有低估情况。
评估结果分析
- 检索功能很有帮助:使用检索功能的模型普遍比无上下文大语言模型法表现好。无上下文大语言模型法要么错误率很高,要么不能保持三个大语言模型的真实排名。这可能是因为用来评估的大语言模型((LM_{EVAL}) )没办法记住关于主题实体的所有事实信息,所以检索相关内容来提供事实背景很有帮助。不过,只使用检索 + 大语言模型法可能会高估FACTSCORE,比如对InstructGPT或ChatGPT进行评估时,用Inst-LLAMA模型最多能高估17%。在这种情况下,结合检索 + 大语言模型法和非参数概率法能显著降低错误率。但对于PerplexityAI,单独使用检索 + 大语言模型法或非参数概率法错误率就很低,而结合的方法会因为低估FACTSCORE导致错误率升高。
- ChatGPT并非总是最佳:结果显示ChatGPT不一定比Inst-LLAMA好。ChatGPT在验证单个原子事实方面表现较好,但它的大多数错误是把没有依据的事实错误地判定为有依据,从而高估了FACTSCORE。相比之下,LLAMA + NP这种组合对事实精确性既不会高估也不会低估,所以综合的事实精确性更接近真实值。这就像在文本摘要评估中,系统层面和片段层面的相关性之间的权衡,它们常常会产生不同的排名结果。
- 最佳估算模型取决于被评估的大语言模型:虽然使用检索功能的模型总是比无上下文大语言模型法好,但最佳的估算模型变体取决于被评估的大语言模型。对于InstructGPT和ChatGPT,LLAMA + NP组合更好;对于PerplexityAI,ChatGPT单独估算更好。不过,这两种评估方式都能正确保持三个大语言模型的排名顺序,并且4.3节显示在对10多个大语言模型进行评估时,这两种估算器给出的分数相关性很高(皮尔逊相关系数为0.99)。所以研究人员建议用户在评估新的大语言模型时,尝试这两种估算变体,并报告它们之间的相关性。
4.3 新大语言模型的评估
这部分主要介绍了如何利用前面提出的估算模型,大规模、自动地评估一系列新的大语言模型在长文本生成方面的事实精确性,还展示了评估的具体设置和结果。
4.3.1 评估设置
- 被评估的模型:研究人员评估了10个新发布的大语言模型(具体信息在Table 4中)。比如GPT-4是OpenAI发布的多模态大语言模型,可以通过API使用;Alpaca基于LLAMA,按照特定方法在InstructGPT的指令数据上进行了微调;Vicuna同样基于LLAMA,在通过ShareGPT获取的ChatGPT输出数据上进行了微调;Dolly是Pythia 12B在DataBricks Dolly(由Databricks创建的人工编写数据)上微调得到的;Oasst-pythia是Pythia 12B在通过Open Assistant收集的人工编写数据上微调得到的;StableLM-tuned-alpha基于StableLM-base-alpha,在多种数据上进行了微调;MPT Chat基于MPT 7B,在多种数据上进行了微调 。除了这10个新模型,还包括InstructGPT、ChatGPT,以及通过DBPedia获取的人工撰写的人物传记。
- 评估数据和过程:和3.3节一样,研究人员让每个被评估的大语言模型( L M S U B J LM_{SUBJ} LMSUBJ )生成500个人物的传记,但选择的人物和之前没有重复。对于人工撰写的传记,有11%的人物数据无法获取,这部分被视为 “不回答” 。具体的统计信息在Table 5中。总共评估了来自13个对象(12个大语言模型和人工撰写的传记)的6500个生成内容,如果人工评估这些内容,预计要花费2.6万美元。
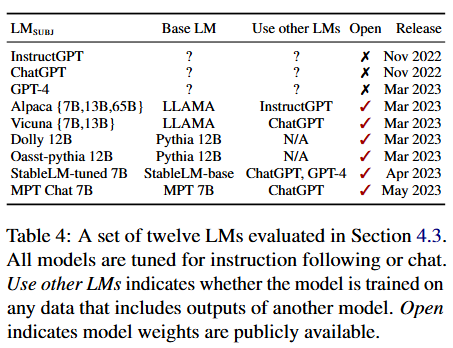
Table 4(被评估的12个大语言模型信息表)
表格展示了12个大语言模型的相关信息: - L M S U B J LM_{SUBJ} LMSUBJ:被评估的大语言模型名称,包括InstructGPT、ChatGPT、GPT-4、Alpaca(有7B、13B、65B不同规模)、Vicuna(有7B、13B )、Dolly 12B、Oasst-pythia 12B、StableLM-tuned 7B、MPT Chat 7B等。
- Base LM:基础大语言模型,比如Alpaca和Vicuna的基础模型都是LLAMA,Dolly的基础模型是Pythia 12B等。
- Use other LMs:表示模型是否在包含其他模型输出的数据上进行训练,例如Alpaca是基于InstructGPT的指令数据微调,Vicuna是基于ChatGPT的输出数据微调。
- Open:表示模型的权重是否公开可用,打勾的表示公开可用。
- Release:模型的发布时间,比如InstructGPT和ChatGPT是2022年11月发布,GPT-4是2023年3月发布等。
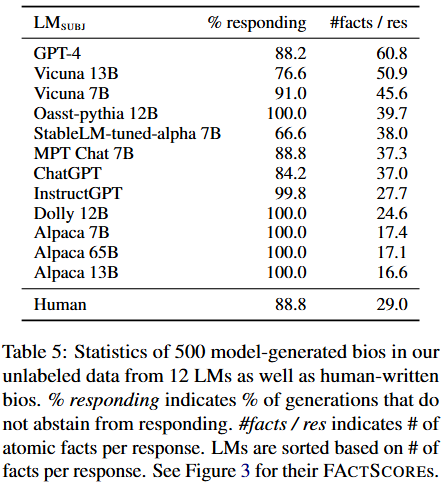
Table 5(模型生成传记的统计信息表)
表格展示了12个大语言模型生成的500个人物传记以及人工撰写传记的统计信息:
- L M S U B J LM_{SUBJ} LMSUBJ:被评估的大语言模型名称和 “Human”(人工撰写)。
- % responding:做出响应的比例,即不 “不回答” 的比例。比如GPT-4是88.2%,表示有11.8%的情况不回答;Vicuna 13B是76.6% ;人工撰写的是88.8% 。
- #facts / res:每个响应包含的原子事实数量。例如GPT-4平均每个响应包含60.8个原子事实,Vicuna 13B是50.9个,人工撰写的平均每个响应包含29.0个原子事实。模型按照每个响应包含的原子事实数量进行了排序。
4.3.2 评估结果
Figure 3展示了由两种最佳的估算模型变体(基于ChatGPT和基于LLAMA + NP,都使用了检索功能)给出的13个对象(12个大语言模型和人工撰写的传记)的排名,这两种评估分数的相关性很高,皮尔逊相关系数达到0.99。通过评估得到以下结论:
- 大语言模型事实精确性不如人类:所有大语言模型在事实精确性上都远不如人类撰写的内容。即便撰写人物传记是相对简单的任务,但这和之前一些研究声称大语言模型在复杂任务上接近人类表现的结论不同。
- GPT-4和ChatGPT事实精确性相近:不过从Table 5可知,GPT-4 “不回答” 的情况较少(12%对比16% ),并且每个响应生成的事实明显更多(61个对比37个)。
- GPT-4和ChatGPT比开源模型更具事实精确性:它们在事实精确性上显著优于其他开源大语言模型。
- 同系列不同规模模型的相关性:在同一系列不同规模的模型中,模型规模和事实精确性有明显关联。比如Alpaca模型中,65B规模的 > 13B规模的 > 7B规模的;Vicuna模型中,13B规模的 > 7B规模的 。
- Alpaca和Vicuna的对比:相同规模下,Alpaca和Vicuna的性能非常接近,可能是因为它们使用了相同的基础模型和相似的训练数据。但从Table 5能看到,Vicuna每个响应生成的原子事实比Alpaca多(51个对比17个),而且Alpaca从不 “不回答” ,Vicuna会有 “不回答” 的情况。
- 开源模型间的差异:即使模型规模相似,开源模型在事实精确性上也存在很大差距。比如在7B规模的模型中,Alpaca和Vicuna(约40% )的事实精确性高于MPT - Chat(30%)和StableLM(17%),这可能和基础大语言模型的选择、训练数据以及训练方法等因素有关。
研究人员强调,这次评估只考虑了人物传记生成方面的事实精确性,对大语言模型的全面评估还应包括生成内容的流畅性、连贯性、相关性、一致性和创造性等方面,不过这些不在本文的研究范围内。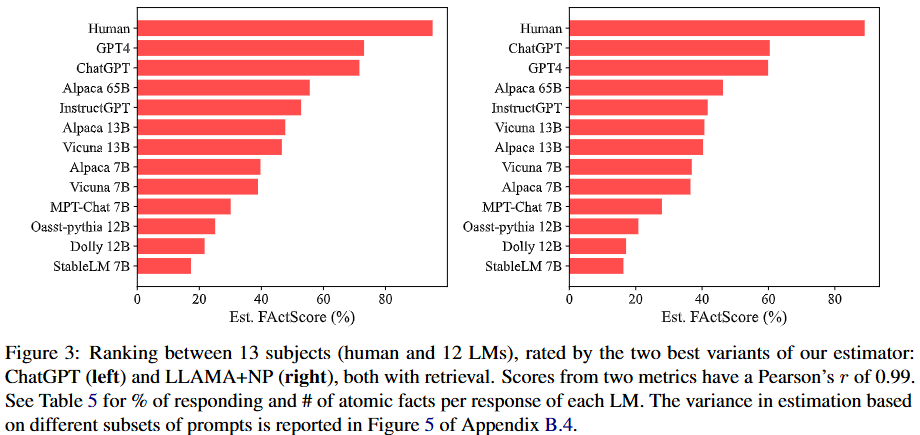
Figure 3(13个对象的排名图)
图中用条形图展示了基于两种最佳估算模型变体(基于ChatGPT和基于LLAMA + NP,都使用了检索功能)对13个对象(12个大语言模型和人工撰写的传记)的排名。横坐标是估算的FACTSCORE(%),纵坐标是对象名称。从图中可以直观地看出不同大语言模型和人工撰写内容在事实精确性上的相对位置,比如人类撰写的内容FACTSCORE最高,StableLM 7B最低等,并且两种评估方式给出的排名结果很相似。
5 结论与未来工作
在这篇论文中,研究人员提出了FACTSCORE,这是一种评估大语言模型长文本生成事实精确性的新方法。具体做法是把模型生成的文本拆分成一系列原子事实,然后计算这些原子事实中能在给定知识源里找到支持依据的比例。
研究人员先是进行了大量的人工评估,结果发现像InstructGPT、ChatGPT,还有结合搜索引擎的PerplexityAI这些先进的商用大语言模型,都存在不少错误。比如ChatGPT的FACTSCORE只有58%,这说明它生成的内容里,只有58%的原子事实能在知识源里找到依据。
由于人工评估既费时间又费钱,所以研究人员又提出了一个估算FACTSCORE的模型,这样就能自动评估大语言模型的FACTSCORE了。这个估算模型基于从知识源检索信息,再结合有竞争力的大语言模型,估算出来的FACTSCORE和真实情况很接近。研究人员还用这个模型评估了12个新发布的大语言模型,如果人工评估这些模型,得花费6.5万美元。通过评估,研究人员对这些模型有了更深入的了解。
FACTSCORE自首次发布后的四个月内,已经被后续的研究积极使用,用于评估新提出的模型的事实精确性(如Ye等人在2023年、Sun等人在2023年、Malaviya等人在2023年、Dhuliawala等人在2023年的研究 )。
对于未来的研究工作,研究人员提出了三点建议:
- 考虑事实性的其他方面:比如召回率,也就是生成内容中事实信息的覆盖程度。举个例子,假如要介绍一位科学家,不仅要保证介绍的内容是真实的(精确性),还要尽量把这位科学家的主要成就、重要事件都涵盖进去(召回率) 。
- 进一步改进估算模型:让它能更好地估算事实精确性,使评估结果更准确。
- 利用FACTSCORE纠正模型生成的内容:在附录C中已经对此进行了初步探索,未来可以更深入地研究。
局限性
FACTSCORE的适用范围
论文里所有的实验都围绕人物传记和维基百科展开。这是因为很多大语言模型能生成包含客观、具体事实的人物传记(而不是主观模糊的内容),而且维基百科对人物信息的覆盖度很高。虽然FACTSCORE可以应用到更广泛的领域,比如以新闻文章集合为知识源来评估关于近期事件的文本,或以科学文献集合为知识源来评估关于科学发现的文本,论文在附录B.5中给出了概念验证,但进一步的研究还需要留到未来。
由于3.1节中提到的假设,当事实更加微妙、开放且有争议时(如Chen等人在2019年、Xu等人在2023年的研究 ),或者知识源中的文本经常相互冲突时(如Wadden等人在2022年的研究),FACTSCORE就不适用了。此外,对于那些微妙且包含有意或隐含欺骗的人工撰写文本,FACTSCORE可能也不适合。比如,一些带有夸张、虚构成分的故事性文本,就很难用FACTSCORE来评估。
估算模型的局限性
虽然这个估算模型的评估结果和人工评估很接近,并且能对大量大语言模型给出一致的排名,但在单个判断上并不完美。而且,最佳的估算模型变体取决于模型生成的文本与人工撰写文本的接近程度,以及文本的语言复杂程度。未来的研究可以探究模型生成内容的分布情况是如何影响估算模型的性能,并进一步改进它。比如,不同类型的大语言模型生成的文本风格差异很大,这些差异可能会导致估算模型的评估结果出现偏差。
超出事实精确性的问题
FACTSCORE主要关注事实精确性,也就是模型生成内容中的每条信息是否能在可靠知识源中找到依据,但这只是更广泛的事实性问题的一个方面。例如,FACTSCORE没有考虑事实召回率,即生成内容中信息的覆盖程度。而且,它也不会对经常不回答问题或者生成事实较少的模型进行惩罚,这可能不太公平,因为精确性和召回率之间本身就存在一种内在的权衡关系。此外,精确性和召回率之间的界限往往很模糊。比如,即使模型生成的内容中每条信息都有依据,但如果遗漏了一些关键信息,按照FACTSCORE可能认为是正确的,但实际上它并没有完整回应输入提示。例如,要求介绍一部电影,模型只提到了主演,却没说剧情,虽然主演信息是准确的,但整体回应并不完整。因此,更全面的事实性评估还需要留到未来的研究中,研究人员建议在报告FACTSCORE时,同时报告 “不回答” 的比例和平均原子事实数量(就像在4.3节中所做的那样)。
补充内容
1)关于3.1 定义FACTSCORE公式通俗解释:
为了方便理解,咱们先设定一些具体的例子,假设你有一个大语言模型叫 “小话痨” ,这就是要评估的语言模型 M M M ;然后有一堆问题,比如 “请介绍一下牛顿”“请讲讲李白的故事” 等,这些问题合在一起就是提示集合 X \mathcal{X} X ;知识源 C \mathcal{C} C 就好比是一个超级靠谱的大百科全书,这里用维基百科。下面来解释定义:
计算单个响应的得分 f ( y ) f(y) f(y)
当你拿 “请介绍一下牛顿” 这个提示 x x x 去问 “小话痨” 模型,它给出的回答 y y y 就是模型的响应 ,比如 “牛顿是英国物理学家,发现了万有引力,还爱吃苹果” 。我们把这个回答拆分成一个个只包含一条信息的短句子,也就是原子事实,这里的原子事实列表 A y \mathcal{A}_y Ay 就有 “牛顿是英国物理学家”“牛顿发现了万有引力”“牛顿爱吃苹果” 。
∣ A y ∣ |\mathcal{A}_y| ∣Ay∣ 就是原子事实的数量,这里是3 。然后我们拿着每一个原子事实,去知识源维基百科里找依据。如果在维基百科里能找到支持某个原子事实的内容,比如 “牛顿是英国物理学家” 和 “牛顿发现了万有引力” 都能找到依据,那对于这两个原子事实, I [ a is supported by C ] \mathbb{I}[a \text{ is supported by } \mathcal{C}] I[a is supported by C] 的值就是 1 1 1 ;要是找不到,比如 “牛顿爱吃苹果” 找不到确切依据,那这个原子事实对应的 I [ a is supported by C ] \mathbb{I}[a \text{ is supported by } \mathcal{C}] I[a is supported by C] 的值就是 0 0 0 。
把所有原子事实对应的这个值加起来,再除以原子事实的总数,也就是 f ( y ) = 1 3 × ( 1 + 1 + 0 ) = 2 3 f(y)=\frac{1}{3}×(1 + 1+0)=\frac{2}{3} f(y)=31×(1+1+0)=32 ,这就是 “小话痨” 模型针对 “请介绍一下牛顿” 这个提示给出的回答的得分。
计算模型的FACTSCORE
我们不会只拿一个问题去问 “小话痨” 模型,会用提示集合 X \mathcal{X} X 里的很多问题去问它。对于每个问题 x x x ,模型给出回答 M x M_x Mx ,然后按照上面的方法算出每个回答的得分 f ( M x ) f(M_x) f(Mx) 。但要是模型对某个问题不回答,那就不算它。
把所有模型做出响应的回答的得分 f ( M x ) f(M_x) f(Mx) 加起来,再除以模型做出响应的问题的数量,得到的平均值就是这个模型 “小话痨” 的FACTSCORE,也就是 FACTSCORE ( M ) = E x ∈ X [ f ( M x ) ∣ M x responds ] \text{FACTSCORE}(M)=\mathbb{E}_{x\in\mathcal{X}}[f(M_x)|M_x \text{ responds}] FACTSCORE(M)=Ex∈X[f(Mx)∣Mx responds] 。
定义基于的假设
- 假设1:对于每个原子事实,能不能在维基百科里找到支持依据,是很明确的,不会有人有不同看法。比如 “牛顿是英国物理学家” 能找到依据,大家都认可这一点。
- 假设2: “牛顿是英国物理学家”“牛顿发现了万有引力”“牛顿爱吃苹果” 这些原子事实,在评估的时候,它们的重要性是一样的。
- 假设3:维基百科里的信息不会自相矛盾,也不会重复说同一件事。
论文后面说用人物传记当提示集合 X \mathcal{X} X ,维基百科当知识源 C \mathcal{C} C ,是因为它们基本能满足这些假设,但在某些情况下,这些假设可能也不成立,在 “局限性” 部分会详细说。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 26
26 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)