
计算机毕业设计之基于Python的当当网书籍销售数据分析系统的设计与实现
本研究旨在构建一个基于Python的当当网书籍销售数据分析系统,通过对当当网海量的书籍信息进行深度挖掘和分析,为书籍行业提供数据支持和决策依据。系统采用Python编程语言、Django、Vue框架,结合大数据处理技术Spark、hadoop、MySQL数据库技术以及数据可视化工具,实现了数据爬取、清洗、存储、分析和可视化等一系列功能。通过对书籍销售数据、用户评价、出版社分布等多维度信息的分析,系
本研究旨在构建一个基于Python的当当网书籍销售数据分析系统,通过对当当网海量的书籍信息进行深度挖掘和分析,为书籍行业提供数据支持和决策依据。系统采用Python编程语言、Django、Vue框架,结合大数据处理技术Spark、hadoop、MySQL数据库技术以及数据可视化工具,实现了数据爬取、清洗、存储、分析和可视化等一系列功能。通过对书籍销售数据、用户评价、出版社分布等多维度信息的分析,系统展现了书籍市场的整体趋势、用户偏好以及出版社表现,为当当网及整个书籍行业提供了有价值的市场洞察。
该系统不仅提升了当当网的业务运营效率,优化了营销策略和库存管理,还增强了用户体验和市场竞争力。同时,系统为出版社、作者和读者提供了丰富的数据资源和分析工具,有助于他们更好地了解市场动态、把握创作方向和满足阅读需求。未来,随着大数据技术的不断进步和应用的深入,系统将进一步拓展功能、提升性能,成为书籍行业乃至整个文化产业的重要数据支撑平台,推动行业的持续创新和发展。
功能需求分析
系统使用收集书籍的基本信息、评论信息、价格对比、售价等行为数据的公开数据集,来构建书籍的数据分析。用户可以通过查询条件的方式,让系统实现对相关数据的筛选和查询,并将查询结果在前端以图表的可视化方式展示出来,进而帮助用户理解数据。系统通过对用户数据的分析与挖掘,实现了对于用户评论的解析和分类,系统提供了直观的当当网书籍数据展示界面,查看到相应的分析结果。
数据采集功能:实现对当当网平台公共数据的采集,识别数据来源、区分数据类型,并进行数据完整性的验证,确保数据的准确性以及可靠性。
分布式存储功能:实现对已经处理过的数据进行分布式存储,采用MySQL、HDFS进行对数据的存储,以及支持异构端存储和具备高容错性,高可用性以及易扩展性。
数据分析功能:基于Spark分布式计算框架,实现对存储的数据进行了数据分析和挖掘。
数据可视化功能:使用ECharts、Vue、BootStrap等前端技术,对数据分析结果进行了可视化展示,以图表等可视化方式将数据展示,方便了用户分析和观察。系统功能模块图如图3-1所示。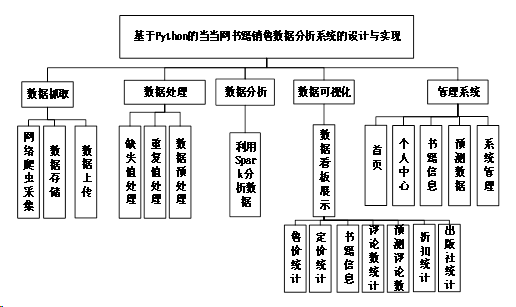
图3-1 系统功能模块图
数据可视化实现
在数据可视化面板界面可以查看到所有数据的详情。数据看板集成了多个功能模块,为用户提供直观的数据展示和分析能力。数据可视化模块的实现依赖于多种技术的协同工作,使用Python编写的爬虫程序负责从当当网网站上抓取海量书籍和评论数据,将这些非结构化数据导入到Hadoop分布式文件系统中进行存储和管理,利用Spark框架对这些大规模数据进行快速的计算和分析,将处理后的结果存入Hive数据库中以方便后续查询和检索,后端采用Django框架搭建Web应用服务器,前端则使用Vue.js库来创建交互式界面,并通过Echarts图表库绘制各种可视化图形。
数据可视化面板作为当当网书籍销售数据分析系统的核心组成部分,涵盖了多个关键功能模块,共同构成了一个全面而直观的数据展示与分析平台。首先,售价统计模块通过条形图清晰地展示了不同作者书籍的售价分布,使得管理者能够迅速把握市场定价趋势。其次,定价统计模块则以柱状图的形式详细列出了每本书籍的原价、折扣价及当前售价,便于对比分析各书的销售策略 effectiveness。再者,评论数统计模块利用折线图描绘了各书获得的评价数量随时间的变化情况,为评估书籍受欢迎程度提供了动态视角。此外,出版社统计模块通过漏斗图形象地展现了不同出版社的市场占有率及其销售表现,有助于优化供应链合作。最后,预测评论数模块则运用线性回归等技术手段对未来一段时间的评论增长进行了科学预测,为企业制定精准营销计划提供了有力支撑。综上所述,数据可视化面板不仅显著提升了数据的可读性与洞察力,更为企业的经营决策注入了新的活力与智慧。可视化效果图如下所示:
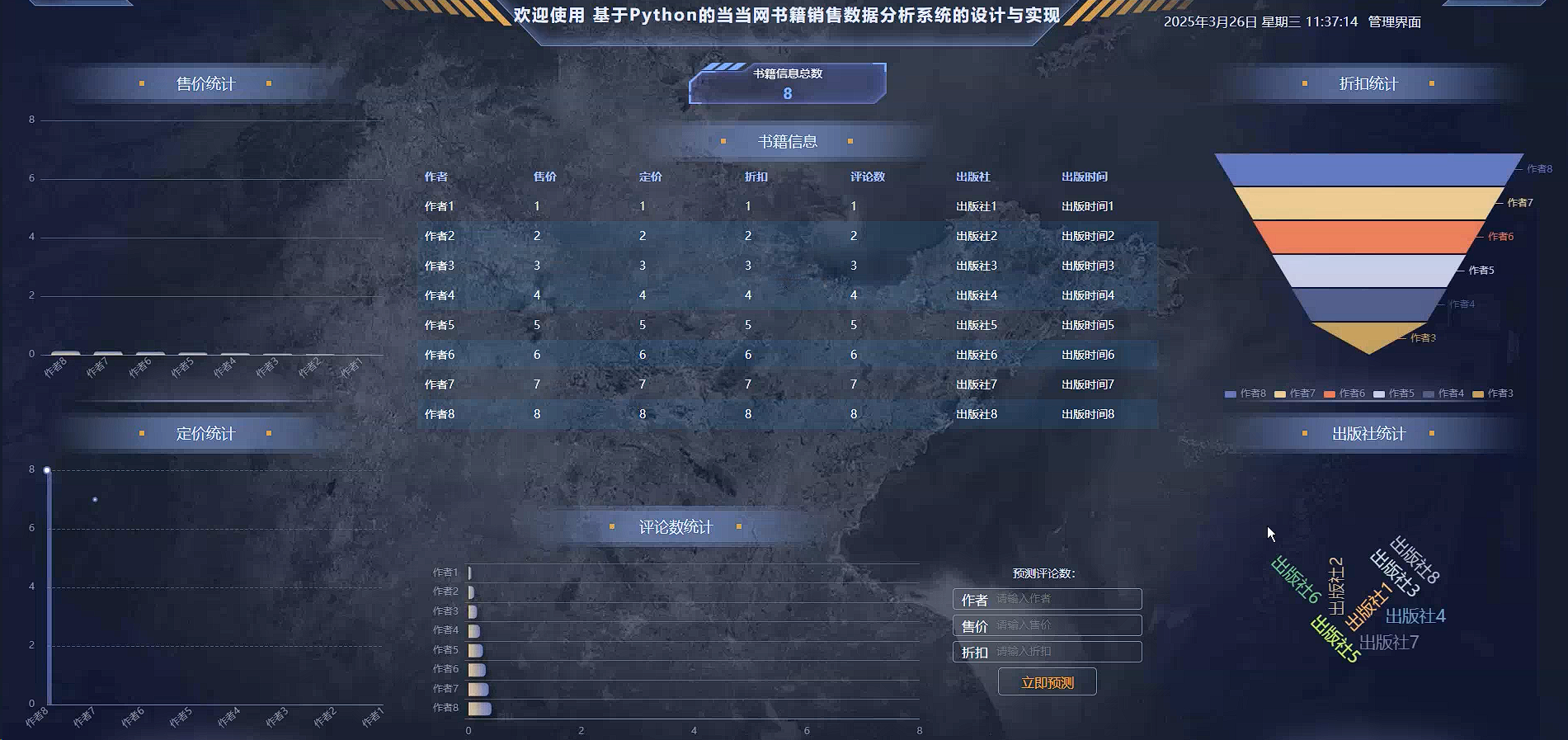
图5-1 数据可视化看板

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)