
【强化学习】第一讲——强化学习简介
强化学习指的是通过交互学习来实现目标的计算方法。机器和环境的一轮交互是指,机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器。这种交互是迭代进行的,机器的目标是最大化在多轮交互过程中获得的累积奖励的期望。强化学习用智能体(agent)这个概念来表示做决策的机器。相比于有监督学习中的“模型”,强化学习中的“智能体”强调机器不
1. 两种人工智能任务类型
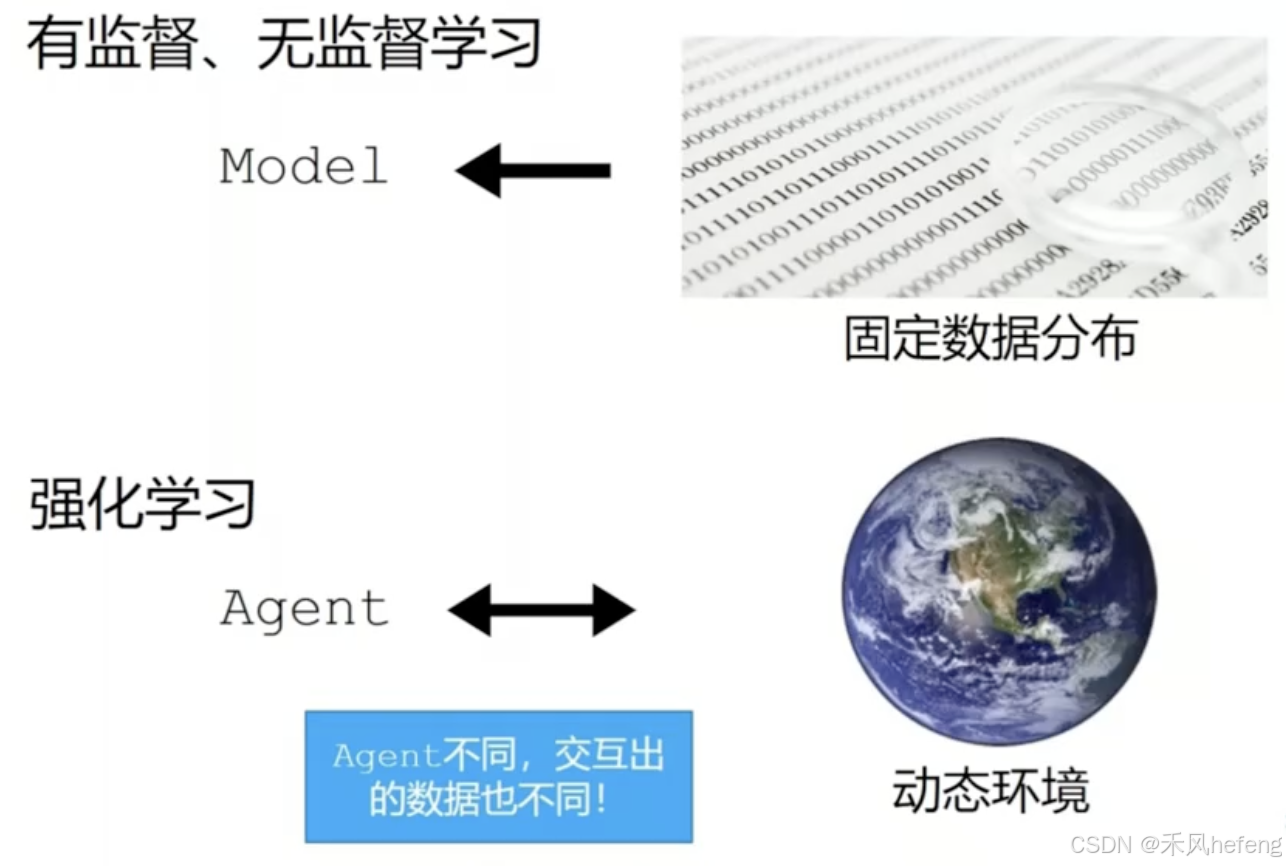
人工智能分为两种任务类型——预测型任务和决策型任务,预测型任务分为有监督学习(根据数据预测输出)和无监督学习(生成数据实例),决策型任务指的是强化学习()
生成式人工智能站结合预测型任务和决策型任务,大量静态数据收集好之后predict next token是一种预测型任务,但是与环境进行交互、与人进行交互的训练方式是一种决策型训练方式。
2. 决策智能任务和技术分类
静态环境还是动态环境关注点在于智能体所在的状态,如果说智能体状态不变,仍然可以做交互式任务,比如多臂老虎机;如果智能体状态接下来状态发生改变,比如无人机驾驶。
白盒环境指的是变量和目标之间的关系可以直接写出来,而黑盒环境中变量和目标之间的关系无法用公式进行表示。
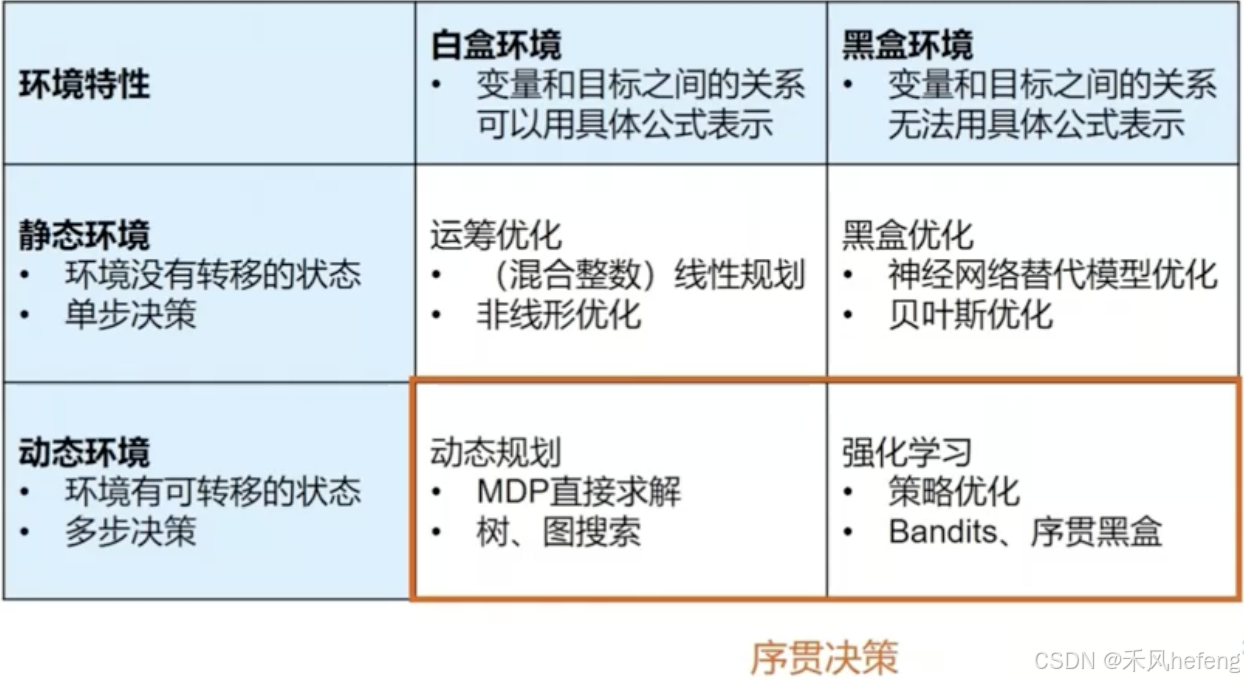
序贯决策(sequential decision making)指的是智能体与动态环境持续地做出动态交互,最终优化一个目标,这个目标通常定义为智能体与环境交互得到奖励的期望值。

比如说机器狗操作轮子与地面进行交互越过障碍物。大多数的序贯决策都是通过强化学习解决的。

3. 强化学习的基本概念
3.1. 强化学习的简介流程
强化学习指的是通过交互学习来实现目标的计算方法。机器和环境的一轮交互是指,机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器。这种交互是迭代进行的,机器的目标是最大化在多轮交互过程中获得的累积奖励的期望。强化学习用智能体(agent)这个概念来表示做决策的机器。相比于有监督学习中的“模型”,强化学习中的“智能体”强调机器不但可以感知周围的环境信息,还可以通过做决策来直接改变这个环境,而不只是给出一些预测信号。
在每一轮交互中,智能体感知到环境目前所处的状态,经过自身的计算给出本轮的动作,将其作用到环境中;环境得到智能体的动作后,产生相应的即时奖励信号并发生相应的状态转移。智能体则在下一轮交互中感知到新的环境状态,依次类推。
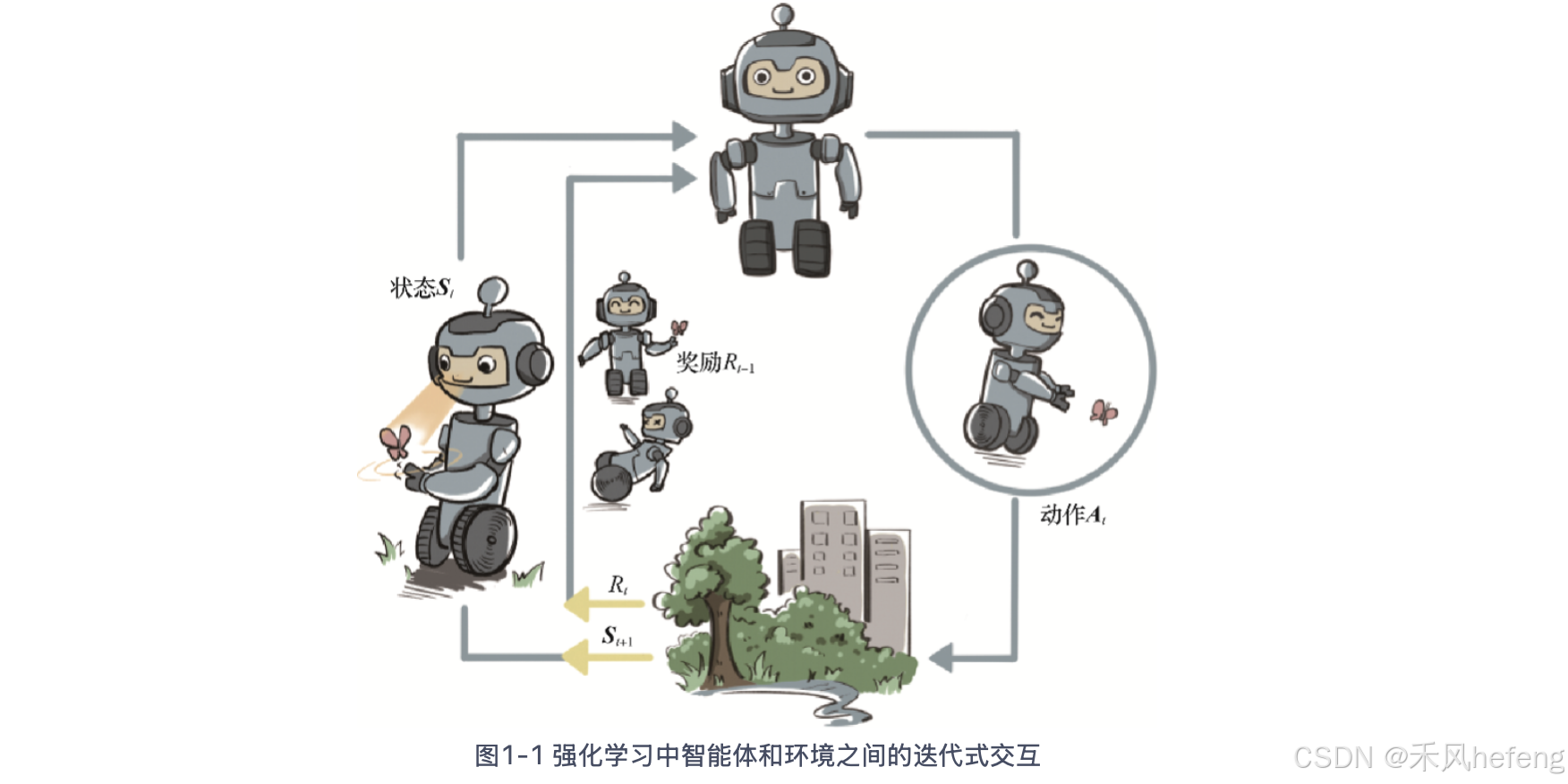
这里,智能体有3种关键要素,即感知、决策和奖励。
- 感知。智能体感知环境的状态,从而知道自己所处的现状。例如,下围棋的智能体感知当前的棋盘情况;无人车感知周围道路的车辆、行人和红绿灯等情况;机器狗通过摄像头感知面前的图像,通过脚底的力学传感器来感知地面的摩擦功率和倾斜度等情况。
- 决策。智能体根据当前的状态计算出达到目标需要采取的动作的过程。例如,针对当前的棋盘决定下一颗落子的位置;针对当前的路况,无人车计算出方向盘的角度和刹车、油门的力度;针对当前收集到的视觉和力觉信号,机器狗给出4条腿的齿轮的角速度。策略是智能体最终体现出的智能形式,是不同智能体之间的核心区别。
- 奖励。环境根据状态和智能体采取的动作,产生一个标量信号作为奖励反馈。这个标量信号衡量智能体这一轮动作的好坏。例如,围棋博弈是否胜利;无人车是否安全、平稳且快速地行驶;机器狗是否在前进而没有摔倒。最大化累积奖励期望是智能体提升策略的目标,也是衡量智能体策略好坏的关键指标。
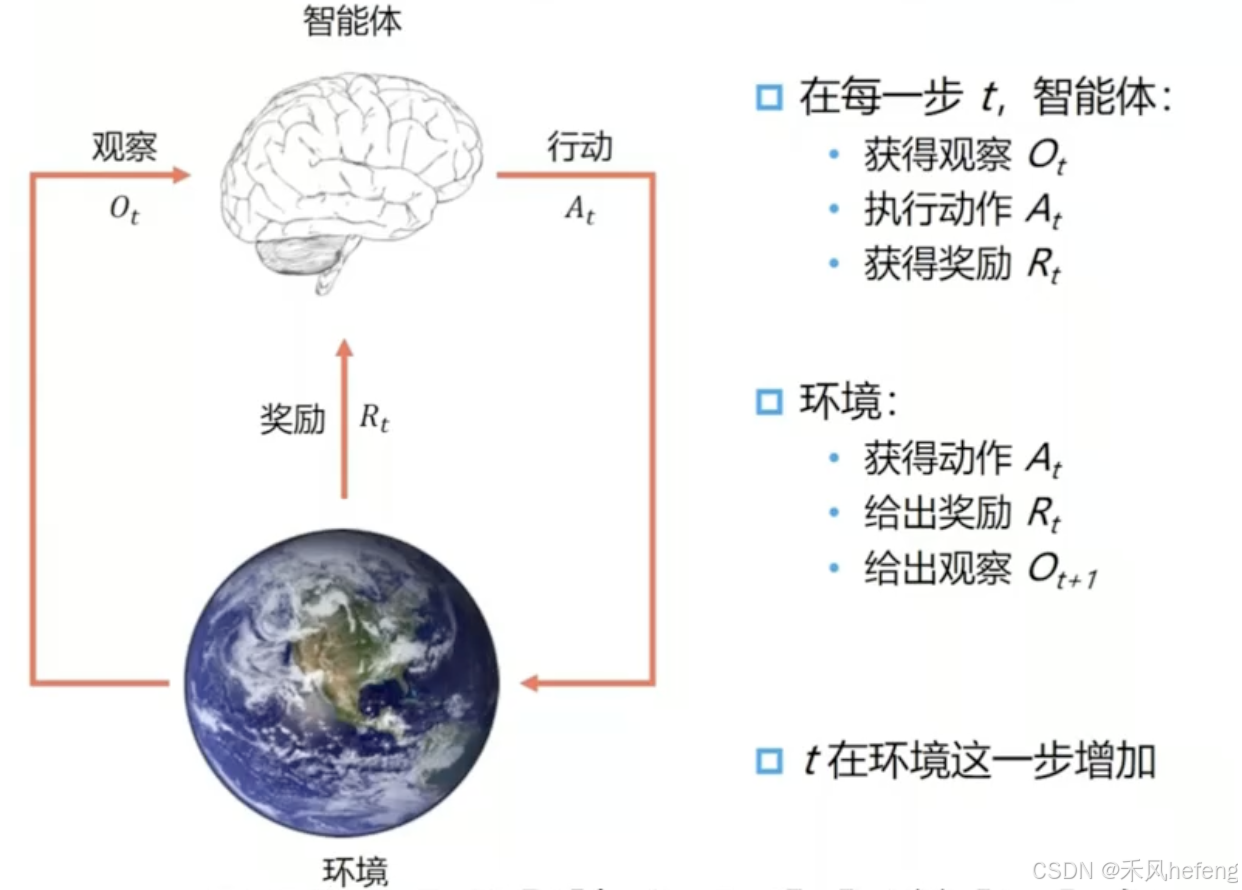
在这种任务当中,我们存在一些基本的假设。假设时间是离散的, 对于连续时间来说,通过增加帧率的方式将连续时间进行离散化。
面向决策任务的强化学习和面向预测任务的有监督学习在形式上是有不少区别的。首先,决策任务往往涉及多轮交互,即序贯决策;而预测任务总是单轮的独立任务。如果决策也是单轮的,那么它可以转化为“判别最优动作”的预测任务。其次,因为决策任务是多轮的,智能体就需要在每轮做决策时考虑未来环境相应的改变,所以当前轮带来最大奖励反馈的动作,在长期来看并不一定是最优的。最后,决策任务中环境是会变化的,而预测任务中的数据分布是固定的。
3.2. 强化学习的基本要素
下面来看一下强化学习中的一些基本要素:
- 历史(History):在当前时间t之前所有它交互出来的数据,具体来说,历史包括每个时间步的观察(observation)、动作(action)和奖励(reward)。形式上,历史可以表示为:
,其中,
是第 i 个时间步的观察,
是第 i 个时间步的动作,
是第 i 个时间步的奖励。 历史是智能体与环境交互的完整记录,它包含了智能体从开始到当前时间步的所有经验。然而,在实际应用中,智能体通常不会直接使用完整的历史,而是通过状态(state)来总结历史信息。
- 状态(state):用来确定接下来会发生的事情(动作、观察、奖励)的信息。状态是对历史的某种总结或抽象,它包含了足够的信息来预测未来的观察、动作和奖励。形式上,状态
可以是历史
的某种函数:
状态的设计对于强化学习的性能至关重要。理想情况下,状态应该是一个马尔可夫状态(Markov State),即当前状态包含了所有必要的信息,未来的状态和奖励只依赖于当前状态和动作,而不依赖于之前的历史:
。
- 策略(policy):智能体在给定状态下选择动作的规则。策略可以是确定性的,也可以是随机性的。形式上,策略
可以表示为:
其中,
表示在状态 s 下选择动作 a 的概率。 策略是强化学习的核心,智能体的目标就是找到一个最优策略,使得在长期内累积的奖励最大化。策略可以通过多种方法进行优化,如基于值函数的方法(如Q-learning)、策略梯度方法(如REINFORCE)等。
- 奖励(reward):是智能体在每个时间步执行动作后从环境中获得的反馈信号。奖励通常是一个标量值,表示智能体在某个时间步的表现好坏。形式上,奖励
是在时间步 t 执行动作
后获得的反馈。 奖励的设计对于强化学习的成功至关重要。奖励信号应该能够准确地反映智能体的目标。例如,在游戏中,奖励可以是得分;在机器人控制中,奖励可以是任务完成的程度。智能体的目标是通过学习策略来最大化累积奖励(通常是折扣累积奖励):
其中,
是折扣因子,用于平衡即时奖励和未来奖励的重要性。
3.3. 强化学习的目标
智能体和环境每次进行交互时,环境会产生相应的奖励信号,其往往由实数标量来表示。这个奖励信号一般是诠释当前状态或动作的好坏的及时反馈信号,好比在玩游戏的过程中某一个操作获得的分数值。整个交互过程的每一轮获得的奖励信号可以进行累加,形成智能体的整体回报(return),好比一盘游戏最后的分数值。根据环境的动态性我们可以知道,即使环境和智能体策略不变,智能体的初始状态也不变,智能体和环境交互产生的结果也很可能是不同的,对应获得的回报也会不同。因此,在强化学习中,我们关注回报的期望,并将其定义为价值(value),这就是强化学习中智能体学习的优化目标。
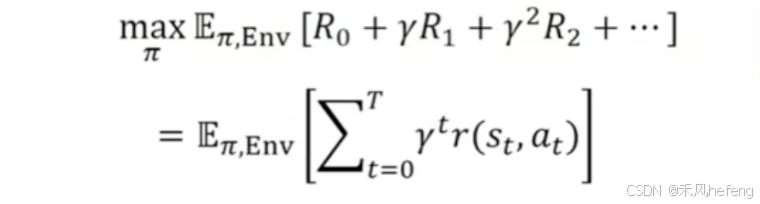
价值的计算有些复杂,因为需要对交互过程中每一轮智能体采取动作的概率分布和环境相应的状态转移的概率分布做积分运算。强化学习和有监督学习的学习目标其实是一致的,即在某个数据分布下优化一个分数值的期望。不过,经过后面的分析我们会发现,强化学习和有监督学习的优化途径是不同的。
3.4. 强化学习的数据
接下来我们从数据层面谈谈有监督学习和强化学习的区别。
有监督学习的任务建立在从给定的数据分布中采样得到的训练数据集上,通过优化在训练数据集中设定的目标函数(如最小化预测误差)来找到模型的最优参数。这里,训练数据集背后的数据分布是完全不变的。
在强化学习中,数据是在智能体与环境交互的过程中得到的。如果智能体不采取某个决策动作,那么该动作对应的数据就永远无法被观测到,所以当前智能体的训练数据来自之前智能体的决策结果。因此,智能体的策略不同,与环境交互所产生的数据分布就不同。
具体而言,强化学习中有一个关于数据分布的概念,叫作占用度量(occupancy measure),归一化的占用度量用于衡量在一个智能体决策与一个动态环境的交互过程中,采样到一个具体的状态动作对(state-action pair)的概率分布。
占用度量有一个很重要的性质,给定两个策略及其与一个动态环境交互得到的两个占用度量,那么当且仅当这两个占用度量相同时,这两个策略相同。也就是说,如果一个智能体的策略有所改变,那么它和环境交互得到的占用度量也会相应改变。
- 强化学习的策略在训练中会不断更新,其对应的数据分布(即占用度量)也会相应地改变。因此,强化学习的一大难点就在于,智能体看到的数据分布是随着智能体的学习而不断发生改变的。
- 由于奖励建立在状态动作对之上,一个策略对应的价值其实就是一个占用度量下对应的奖励的期望,因此寻找最优策略对应着寻找最优占用度量。
3.5. 强化学习的独特性
对于一般的有监督学习任务,我们的目标是找到一个最优的模型函数,使其在训练数据集上最小化一个给定的损失函数。在训练数据独立同分布的假设下,这个优化目标表示最小化模型在整个数据分布上的泛化误差(generalization error),用简要的公式可以概括为:

相比之下,强化学习任务的最终优化目标是最大化智能体策略在和动态环境交互过程中的价值。策略的价值可以等价转换成奖励函数在策略的占用度量上的期望,即:

观察以上两个优化公式,我们可以总结出两者的相似点和不同点。
- 有监督学习和强化学习的优化目标相似,即都是在优化某个数据分布下的一个分数值的期望。
- 二者优化的途径是不同的,有监督学习直接通过优化模型对于数据特征的输出来优化目标,即修改目标函数而数据分布不变;强化学习则通过改变策略来调整智能体和环境交互数据的分布,进而优化目标,即修改数据分布而目标函数不变。
综上所述,一般有监督学习和强化学习的范式之间的区别为:
- 一般的有监督学习关注寻找一个模型,使其在给定数据分布下得到的损失函数的期望最小;
- 强化学习关注寻找一个智能体策略,使其在与动态环境交互的过程中产生最优的数据分布,即最大化该分布下一个给定奖励函数的期望。
4. 强化学习方法分类
强化学习方法可以根据其核心思想和技术手段进行分类,主要分为基于价值的方法、基于策略的方法,以及结合两者的Actor-Critic方法。
- 基于价值的方法(Value-Based Methods):通过估计价值函数(Value Function)来指导智能体的行为。价值函数衡量在某个状态(或状态-动作对)下,智能体未来可能获得的累积奖励的期望值。智能体根据价值函数选择能够最大化未来奖励的动作。
- 基于策略的方法(Policy-Based Methods):直接优化策略本身,而不依赖于价值函数。策略通常表示为一个参数化的函数(如神经网络),通过调整策略参数来最大化累积奖励。
- Actor-Critic方法:结合了基于价值的方法和基于策略的方法,利用两者的优点来改进学习效率。它由两个部分组成:Actor负责学习策略,决定智能体在某个状态下应该执行什么动作;Critic负责评估策略,通过估计价值函数来评判Actor的动作是否优秀。
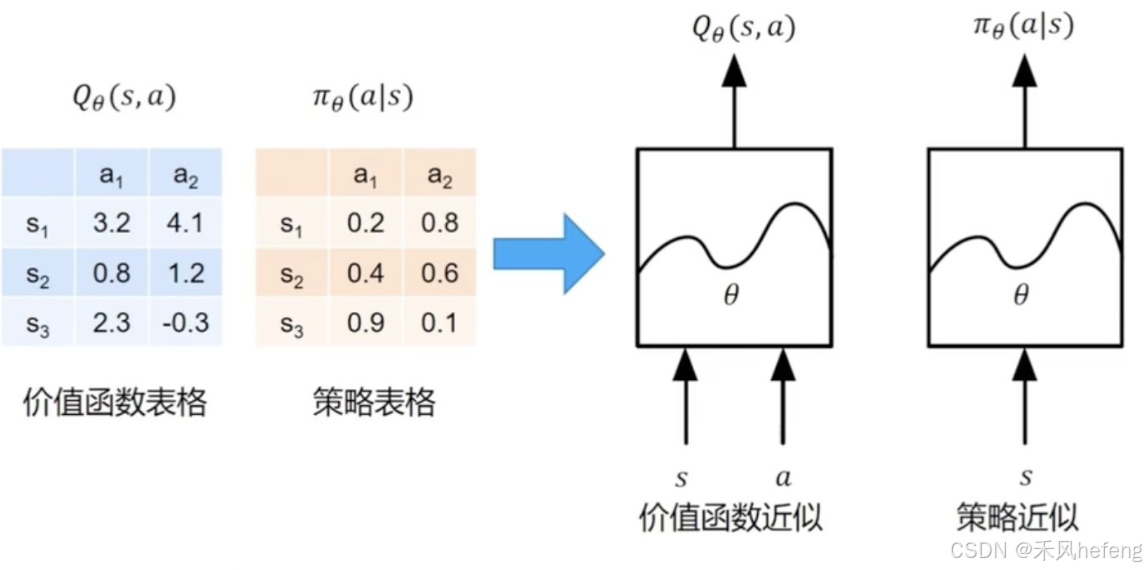
价值和策略近似
价值函数表格中列出了不同状态 S 和动作 a 对应的价值 Q(s, a) 。例如,在状态 下,动作
的价值为 3.2,动作
的价值为 4.1。策略表格中列出了不同状态 S 和动作 a 对应的策略概率
。例如,在状态
下,选择动作
的概率为 0.2,选择动作
的概率为 0.8。
价值函数 Q(s, a) 可以通过函数近似(如神经网络)来表示,即 ,其中
是神经网络的参数。当状态空间或动作空间很大时,使用表格存储价值函数会变得不现实。通过函数近似,可以更高效地表示和优化价值函数。策略
也可以通过函数近似(如神经网络)来表示,即
,其中
是神经网络的参数。策略近似允许智能体学习复杂的策略,尤其是在连续动作空间或高维状态空间中。
那么是否可以直接使用深度神经网络建立这些近似函数?是的!深度神经网络可以作为函数近似器,用于表示价值函数 和策略
。深度神经网络的强大表达能力使得它能够处理高维状态空间和复杂任务,例如直接从图像中学习策略。
深度强化学习(Deep Reinforcement Learning, DRL)是结合深度学习和强化学习的方法,利用深度神经网络作为函数近似器来优化价值函数或策略。深度强化学习使强化学习算法能够解决更复杂的问题,例如机器人控制、游戏AI、自动驾驶等。
端到端强化学习
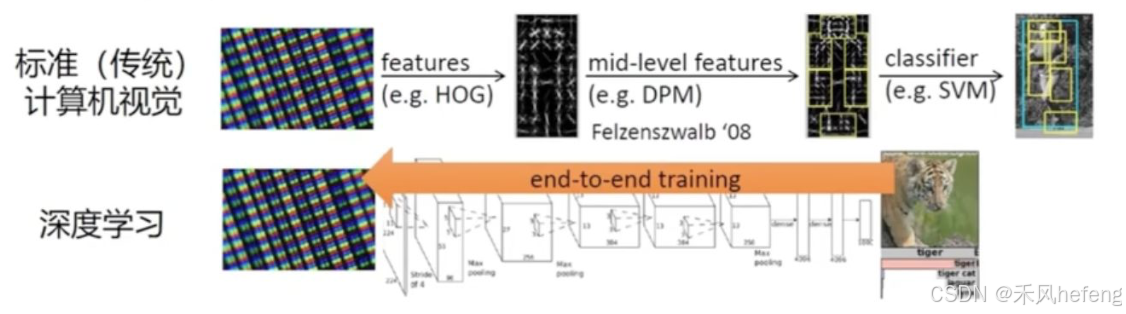
传统计算机视觉通常分为多个阶段:特征提取(Features),从原始数据中提取低层次特征,例如HOG(Histogram of Oriented Gradients);中层特征(Mid-level Features),在低层次特征的基础上,进一步提取更高层次的特征,如DPM(Deformable Parts Model);分类器(Classifier),使用提取的特征训练分类器,例如SVM(Support Vector Machine),用于最终的分类或识别任务。
而端到端训练(End-to-End Training)使得深度学习模型可以直接从原始数据(如图像)学习到最终的任务目标(如分类),无需手工设计特征。模型通过多层神经网络自动提取特征,并通过反向传播优化整个网络。
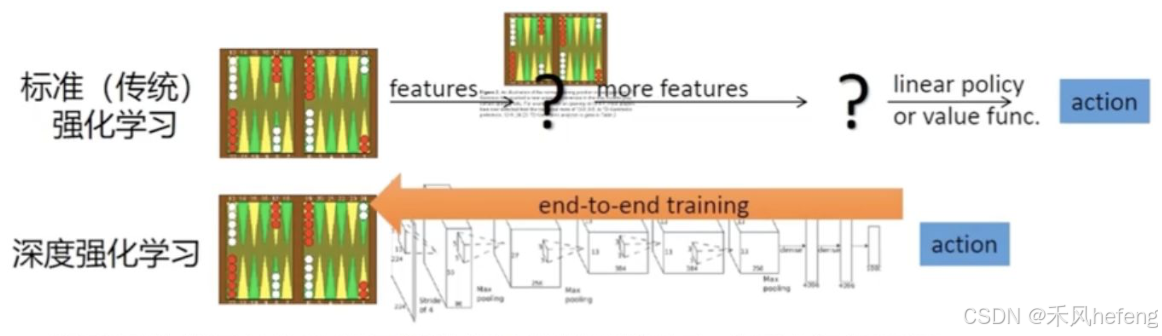
传统强化学习包括:特征提取(Features),从环境状态中提取特征;更多特征(More Features),进一步提取更高层次的特征;线性策略或值函数(Linear Policy or Value Function),基于提取的特征,使用线性策略或值函数来选择动作。
而深度强化学习的端到端训练(End-to-End Training)可以直接从原始状态(如图像)学习到最终的动作选择,无需手工设计特征。模型通过深度神经网络自动提取特征,并优化策略或值函数。
深度强化学习
深度强化学习是通过深度神经网络进行价值函数和策略的近似,从而实现端到端的强化学习:
- 价值函数近似:使用深度神经网络表示动作价值函数
,其中
是神经网络的参数。
- 策略近似:使用深度神经网络表示策略
,其中
- 端到端学习:直接从原始输入(如图像)学习到最终的动作选择,无需手工设计特征。
深度强化学习中的梯度计算方法,具体公式为: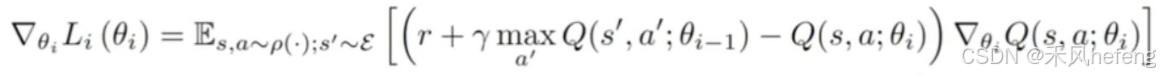
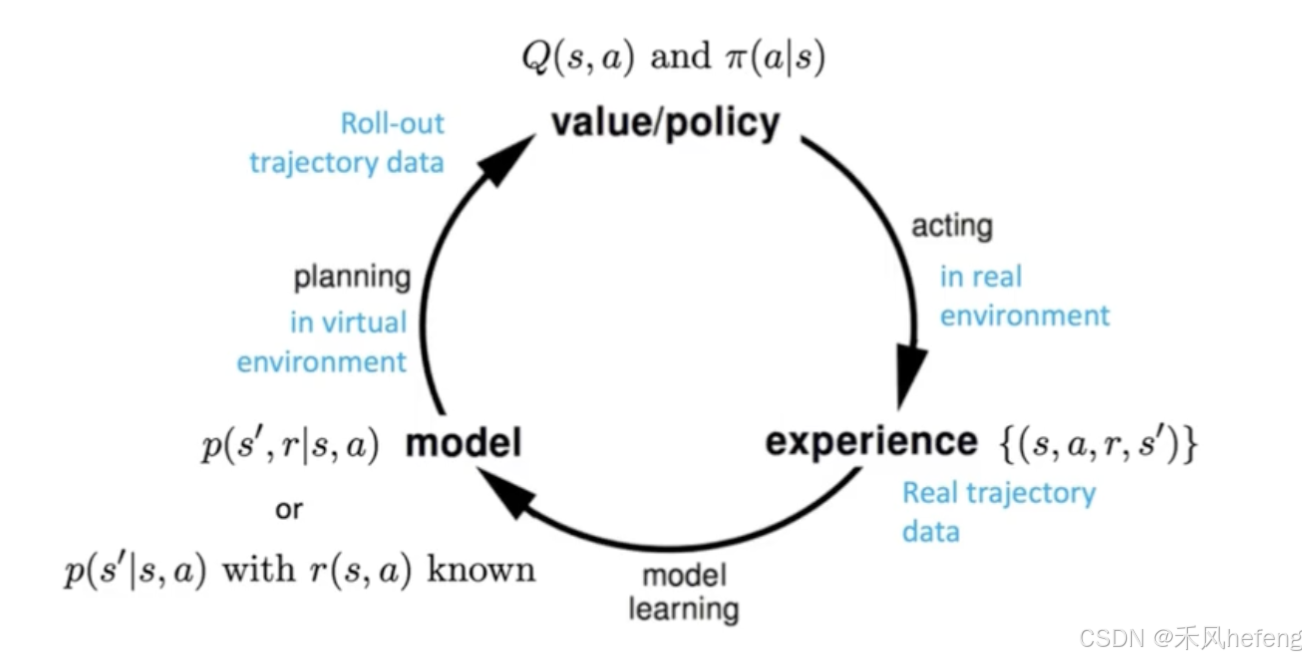
基于模拟模型的强化学习(Model-based RL)
基于模拟模型的强化学习(Model-based RL)分为四个主要部分:价值/策略(Value/Policy)、经验(Experience)、模型(Model)和规划(Planning)。
- 价值函数 Q(s, a) 和策略
- 经验(Experience)指智能体在真实环境中通过执行动作获取的经验数据,形式为
。
- 模型(Model)是对环境的模拟,通常表示为状态转移概率
和奖励函数 r(s, a) 。
- 状态转移概率 p(s'|s, a) 表示在状态 s 下执行动作 a 后,转移到状态 s'的概率。
- 奖励函数 r(s, a) 表示在状态 s 下执行动作 a 后获得的奖励。
- 规划(Planning):在虚拟环境中,利用模型生成轨迹数据(trajectory data),形式为
目标策动的强化学习(Goal-oriented RL)
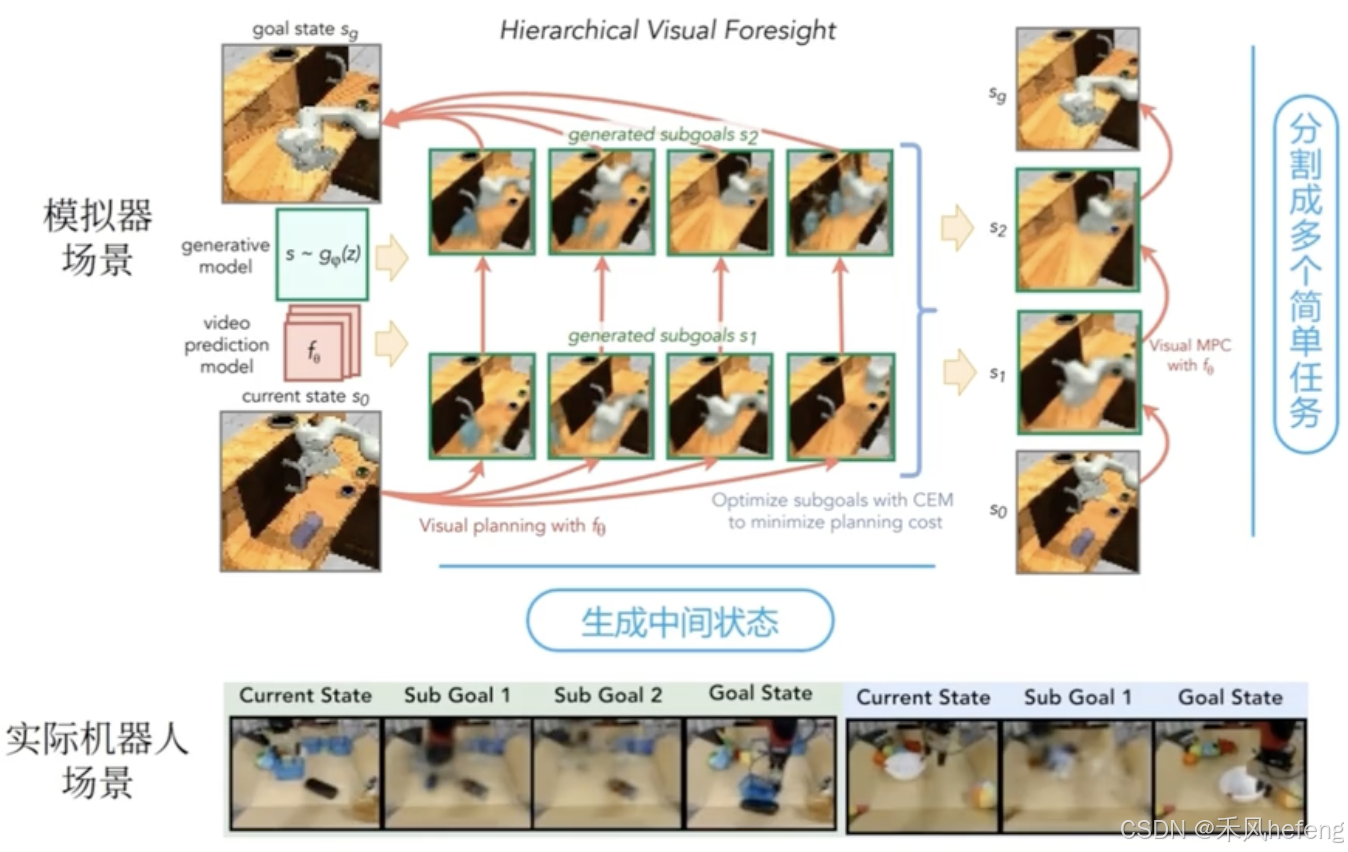
目标导向的强化学习通过生成和优化子目标,将复杂任务分解为多个简单任务,从而更高效地实现目标。分层视觉规划利用生成模型和视觉预测,优化子目标并最小化规划成本。这种方法特别适合在复杂环境中(如机器人控制)实现长时程任务。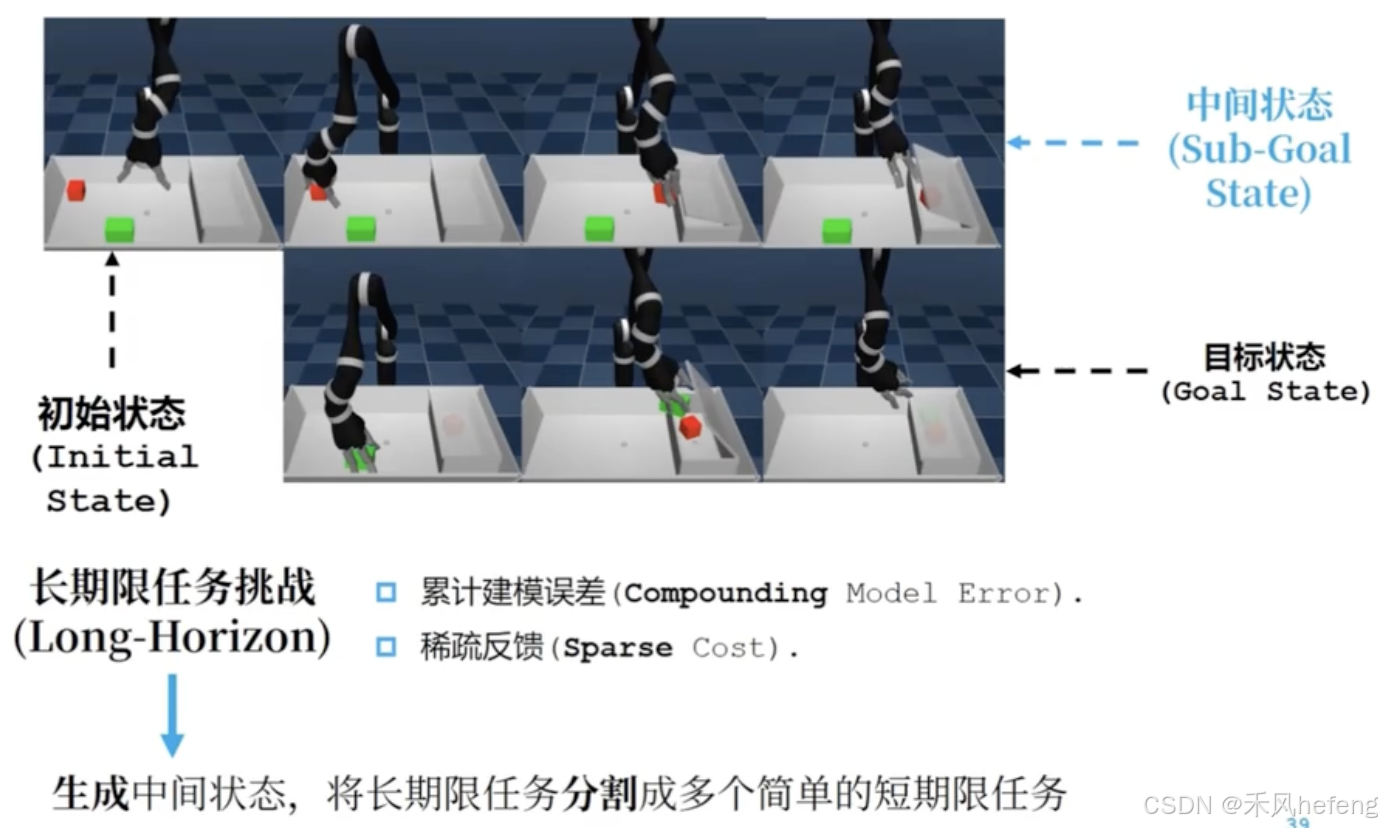
模仿学习(Imitation Learning)
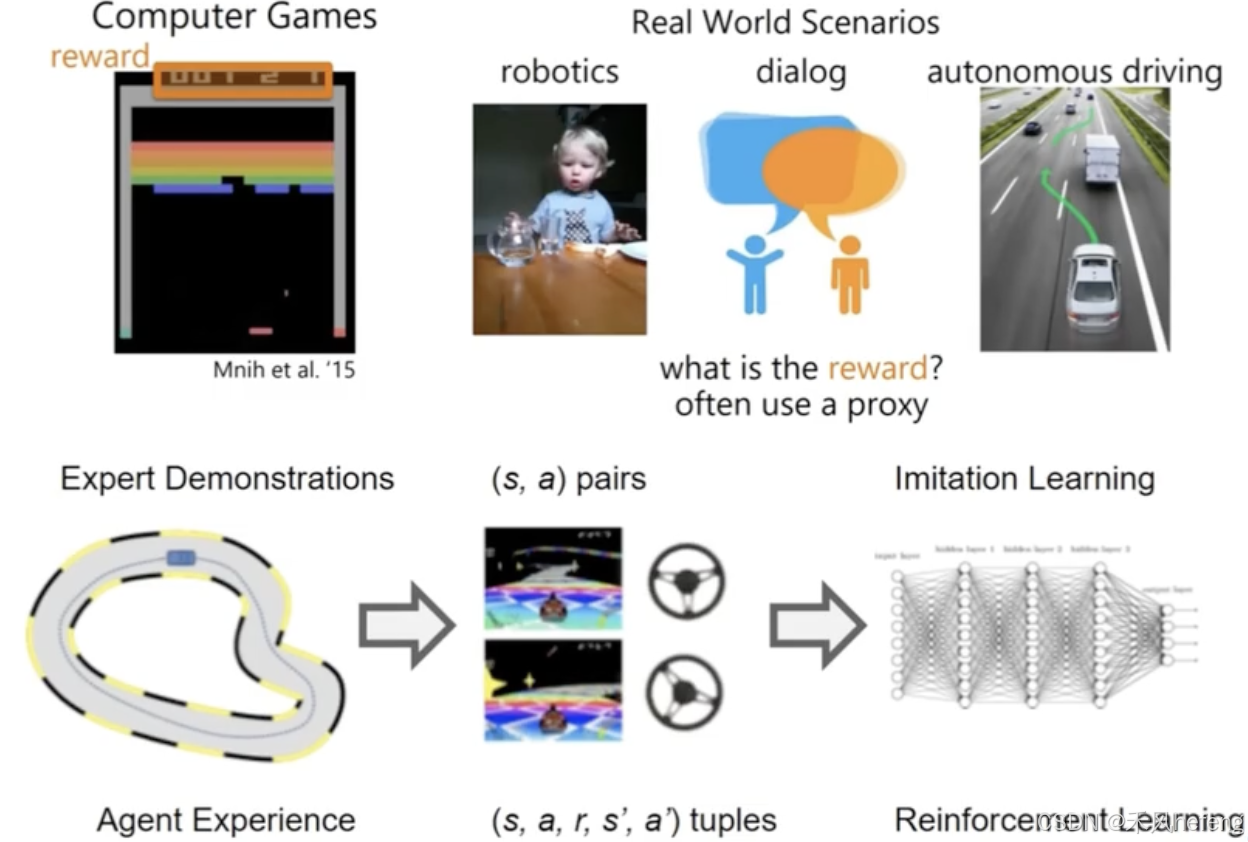
模仿学习是一种通过专家演示来训练智能体的方法。其核心思想是智能体通过观察专家的行为状态 s 和动作a 的配对,即 (s, a) 对,学习如何模仿专家的策略。与强化学习不同,模仿学习不需要显式的奖励信号,而是通过专家的演示来间接定义奖励。在模仿学习中,奖励通常是通过代理(proxy)来定义的,由于模仿学习不直接使用环境奖励,而是通过专家的演示来间接定义奖励。例如,智能体的行为与专家行为的相似度可以作为奖励的代理。
模仿学习与强化学习有紧密联系,两者都通过优化策略来完成任务。而强化学习通过环境奖励直接优化策略,模仿学习通过专家演示间接优化策略。因此,模仿学习可以作为强化学习的初始化方法,帮助智能体更快地学习。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)