
X-MAS:构建具有异构LLM的多智能体系统
基于LLM的多智能体系统(MAS)通过使多个专业智能体合作,扩展了单个LLM的能力。然而,大多数现有的MAS框架依赖于单一的LLM来驱动所有智能体,将系统的智能限制在该模型的极限之内。本文探讨了由异构LLM驱动的MAS(X-MAS)范式,其中智能体由不同的LLM提供动力,将系统的潜力提升到多样化LLM的集体智能水平。我们介绍了X-MAS-Bench,一个全面的测试平台,旨在评估各种LLM在不同领域
叶睿$ \mathrm{Ye}^{1, *} \quad $ 刘翔瑞 1,∗{ }^{1, *}1,∗
吴琦敏 1{ }^{1}1 庞祥赫 1{ }^{1}1 阴振飞 2,3{ }^{2,3}2,3 白雷 4{ }^{4}4 陈思恒 1,†{ }^{1, \dagger}1,†
1{ }^{1}1 上海交通大学 2{ }^{2}2 牛津大学 3{ }^{3}3 悉尼大学
4{ }^{4}4 上海人工智能实验室 ∗{ }^{*}∗ 等量贡献 †{ }^{\dagger}† 通讯作者
X-MAS: https://github.com/MASWorks/X-MAS
摘要
基于LLM的多智能体系统(MAS)通过使多个专业智能体合作,扩展了单个LLM的能力。然而,大多数现有的MAS框架依赖于单一的LLM来驱动所有智能体,将系统的智能限制在该模型的极限之内。本文探讨了由异构LLM驱动的MAS(X-MAS)范式,其中智能体由不同的LLM提供动力,将系统的潜力提升到多样化LLM的集体智能水平。我们介绍了X-MAS-Bench,一个全面的测试平台,旨在评估各种LLM在不同领域和MAS相关功能中的表现。作为一项广泛的实证研究,我们在5个领域(涵盖21个测试集)和5个功能中评估了27个LLM,进行了超过170万次评估,以确定每个领域-功能组合的最佳模型选择。基于这些发现,我们证明从同质到异构LLM驱动的MAS可以显著提高系统性能,而无需结构上的重新设计。具体来说,在仅聊天机器人的MAS场景中,异构配置在MATH数据集上提高了8.4%的性能。在混合聊天机器人-推理器场景中,异构MAS在AIME数据集上实现了47%的显著性能提升。我们的结果强调了异构LLM在MAS中的转型潜力,突显了一个推进可扩展、协作AI系统前景广阔的方向。
1 引言
大型语言模型(LLMs)如GPT [1]、Gemini [2]、Qwen [3]已在各个领域得到了应用。然而,尽管它们能力非凡,LLMs往往难以应对多方面、复杂和现实世界的问题,这是由于其固有的局限性,例如幻觉 [4, 5]。
为应对这些局限性,基于LLM的多智能体系统(MAS)作为一种有前途的解决方案应运而生 [6, 7, 8]。MAS涉及多个智能体的合作,每个智能体专门执行特定功能,比单一模型更有效地解决问题。这一范式已成功应用于各种场景,包括软件开发 [7, 9]、数学 [10, 11] 和科学发现 [12, 13]。例如,ChatDev [7]、MetaGPT [9] 和 EvoMAC [14] 利用多个编码智能体(例如,编码者和测试者)改进软件编程,而AI协同科学家 [8] 则使用MAS增强生物医学和科学研究。
尽管取得了显著进展,但大多数现有的MAS框架仍然依赖于单一的LLM来驱动所有智能体 [9, 7,11,6,14,15,16]7,11,6,14,15,16]7,11,6,14,15,16]。这种方式本质上将系统的智能限制在底层模型的范围内。例如,如果单一LLM在某些事实中产生基本错误,这些错误不太可能通过由相同模型驱动的智能体合作得到纠正。受集体智能多样性优势的启发 [17, 18, 19],本文探索了具有异构LLM的MAS(X-MAS),推动系统能力超越其先前的限制,利用训练于不同语料库或由不同团队训练的LLM的集体潜力 [20, 21, 22]。
为了对MAS中的LLM进行全面评估,我们引入了X-MAS-Bench,这是一个测试平台,旨在评估各种LLM在不同MAS相关功能和领域的表现。具体而言,我们考虑了MAS中智能体的5个代表性功能,包括问答 [15, 9]、修订 [14, 23]、聚合 [24, 25]、规划 [26, 10] 和评估 [16, 7];以及5个常见领域,包括数学、编码、科学、医学和金融——涵盖21个测试集。每个功能都在受控实验条件下进行评估。例如,在评估聚合时,每个查询被输入到几个预定义的LLM中,其输出被连接起来由待评估的LLM进行聚合。然后对各种LLM的聚合响应进行评估和比较。最后,我们在这些5个功能和5个领域中评估了27个LLM,进行了超过170万次评估,以确定每个领域-功能组合的最佳模型选择。我们的发现包括以下几点:(1)没有单一LLM能在所有场景中表现出色,(2)单一LLM在不同功能和领域中的表现可能会有很大差异,(3)不同的LLM在同一功能和领域内可能会表现出很大的性能差异,(4)较小的LLM有时可以优于较大的LLM,这凸显了在MAS中使用异构LLM的潜在优势。这些结果为研究人员和从业者在为其特定MAS应用选择最合适的LLM提供了宝贵的见解。
基于这些观察结果,我们探讨了从同质到异构LLM驱动的MAS(X-MAS-Design)的转变效果。作为一个概念验证,给定一个MAS方法的实现,我们只需通过参考X-MAS-Bench中的观察结果,简单地为智能体分配适当的LLM(耗时几秒)。为了验证我们的想法,我们考察了三个现有的MAS框架——LLM-Debate [15]、AgentVerse [16] 和 DyLAN [11]——以及我们设计的一个原型MAS,该系统将所有五个功能整合到一个系统中。我们的分析涵盖了五个领域,与X-MAS-Bench相比没有样本重叠。在仅聊天机器人的场景中,我们观察到异构MAS在性能上始终优于同质配置,在MATH [27]基准上实现了高达8.4%的性能提升。有趣的是,虽然仅推理器的MAS通常表现不如仅聊天机器人的系统,但在异构MAS中结合聊天机器人和推理器会导致显著的性能提升。具体来说,在竞争级别的AIME-2024基准上,AgentVerse [16] 的性能从20%提升到50%,DyLAN [11] 从40%提升到63%。我们的进一步实验表明,增加候选LLM的数量用于异构MAS会导致单调的性能提升,强化了MAS中LLM多样性的价值。基于我们的工作,未来的研究可以探索在异构MAS中选择和集成LLM的更细致策略;调查异构MAS在不同行业和其他复杂任务中的可扩展性和适应性。
我们的贡献如下:
- X-MAS-Bench: 我们评估了27个LLM在5个MAS相关功能和5个领域的表现,进行了超过170万次评估,以确定每个领域-功能组合的多种最佳模型选择。这些观察结果可以帮助研究人员和从业者构建MAS。
-
- X-MAS-Design: 基于X-MAS-Bench中的发现,我们提出将现有MAS方法从同质转变为异构LLM驱动的MAS。我们进行了广泛的实验,显示异构MAS始终优于同质MAS。
-
- 开源:我们发布了所有数据、代码和评估结果,以促进未来的MAS研究。
2 相关工作
基于LLM的MAS。基于LLM的多智能体系统(MAS)利用多个基于LLM的智能体协作,比单一LLM更好地解决任务 [16, 9, 28, 6]。ChatDev [7]、MetaGPT [9] 和 EvoMAC [14] 使用多个编码智能体(例如,编码者和测试者)进行软件编程;而MACM [10] 应用数学智能体进行数学运算。针对一般任务,基于辩论的方法 [15, 25] 启用多个专家进行辩论以获得更好的解决方案;AgentVerse [16] 和 DyLAN [11] 动态调整智能体团队以解决问题;而MAS-GPT [6] 训练一个LLM生成MAS。然而,所有这些方法都依赖于单一的LLM来驱动所有智能体,这本质上将系统的智能限制在底层LLM的范围内。本文提出通过利用来自不同来源的异构LLM的集体智能来突破这一限制。
异构LLM。在LLM的一般背景下,有一些关于使用异构LLM的工作 [29, 30]。LLM-Blender [31] 训练一个模型来集成多个LLM的输出。MoA [32] 和 ReConcile [33] 启用多个LLM进行讨论,但不考虑其适用性。MASRouter [34] 手动选择若干候选LLM用于MAS,并针对其特定框架进行优化。相比之下,我们的论文系统地评估了LLM在几个MAS相关功能和领域中的能力,旨在普遍受益于各种MAS方法的异构MAS设计。
LLM基准测试。许多工作在各种领域(如数学 [27]、编码 [35]、科学 [36]、医学 [37] 和金融 [38])和功能(如规划 [39] 和评估 [40])中基准测试LLM的能力。然而,我们的论文首次为MAS基准测试LLM,评估了LLM在25个与MAS相关的功能-领域视角中的能力。
3 X-MAS-Bench:评估MAS的LLM
X-MAS-Bench是一个测试平台,旨在评估各种LLM在不同MAS相关功能和领域中的表现。具体而言,我们考虑了MAS中智能体的5个代表性功能——问答 [15, 9]、修订 [14, 23]、聚合 [24, 25]、规划 [26, 10] 和评估 [16, 7]。正交地,我们研究了5个领域,包括数学、编码、科学、医学和金融——涵盖21个测试集。每个功能都在受控实验条件下进行评估。在本节中,我们在第3.1节中展示实验条件的详细信息,并在第3.2节中展示实验结果。
3.1 基准测试MAS相关功能
为了系统地评估LLM在多智能体环境中的能力,我们将MAS行为分解为五个代表性和常用的智能体功能:问答、修订、聚合、规划和评估。对于每个功能,我们定义了标准化的提示协议。在所有情况下,我们仔细控制实验条件,使得唯一变化的因素是正在评估的LLM。下面我们将详细说明每个功能的设计评估。
问答。问答(QA)功能衡量LLM理解问题并以自由文本形式生成正确答案的能力。这个功能是所有MAS方法的基础,例如LLM-Debate [15],其中每个智能体首先独立回答查询,以及MetaGPT [9],其中智能体在处理的第一阶段提供初始草稿响应。在QA评估中,LLM接收来自任何测试数据集(例如,MATH [27])的采样查询作为输入,并以自由文本格式返回答案。输出与真实答案进行比较,所得的准确率将作为评估QA能力的指标。
修订。修订功能评估智能体修正初始答案(可能存在缺陷)以生成正确答案的能力。此功能通常存在于需要迭代细化的工作流程中,例如EvoMAC [14]中的更新智能体和Self-Refine [23]中的校正器。在修订评估中,给定一个格式化的提示,包含采样查询及其由预定义LLM生成的相应答案,要求被评估的LLM通过推理和修订提供的查询和答案来提供最终完整答案。在这种情况下,所有被评估的LLM都提供相同的提示(即,来自相同的查询和相同的预定义LLM),因此确保被评估LLM之间的公平比较。同样,修订后的输出与真实答案进行比较,所得的准确率表示修订能力。
聚合。聚合指的是将多个候选答案合并成连贯、正确甚至改进的最终答案的能力。这是MAS中的关键机制,利用了多条回答路径,例如MacNet [24]中的收敛智能体和MAD [25]中的提取模式的裁判。为了评估聚合,对于每个查询,我们从一组固定的预定义LLM(在此设置为3个)中收集候选响应。被评估的LLM以固定的串联格式提供查询和这些候选响应,并要求合成最终答案。重要的是,所有候选响应及其顺序在所有模型中保持一致,确保提示的一致性并允许公平比较。然后使用准确率作为度量对聚合答案进行评分。
规划。规划涉及将任务分解为子任务,并沿工作流为智能体分配适当的角色以协作解决问题。此功能在系统如MACM [10]和MapCoder [26]中至关重要,其中思考者或规划智能体定义整个智能体工作流。在规划评估中,被评估的LLM的任务是根据采样查询提供合适的计划,给出回答查询所需的智能体角色描述及工作流,其输出应遵循预定义格式以供后续字符串提取。随后,提取有序角色描述和角色数量。接下来,根据角色描述和工作流安排激活相应数量(即角色数量)的候选LLM进行操作。输入提示和候选LLM在所有被评估的LLM中保持固定。整体系统性能——通过最终任务准确率评估——作为规划能力的代理。
评估。评估衡量智能体对其他智能体输出的质量或正确性进行批判性评估的能力。此功能在MAS中用于过滤错误推理、选择更好的解决方案、确定早期停止或指导进一步行动——通常在框架如AgentVerse [16]和ChatDev [7]中看到。在我们的评估中,每个被评估的LLM都被呈现一个查询和由预定义LLM生成的答案。指示被评估的LLM判断提供的答案是否正确回答了查询。候选答案和评估指令在LLM之间保持不变,以确保公平比较。不同于之前功能的评估,被评估LLM的判断与真实正确性进行比较。
3.2 在功能和领域中评估LLM的实验
按照上述功能定义,本节评估各种LLM在不同功能和领域中的能力,旨在展示MAS的LLM景观。报告的结果预计会展示利用异构LLM进行MAS的潜力,并促进未来研究人员选择适合其MAS的LLM。
实验设置。我们检查了27个LLM,覆盖20个聊天机器人(即,指令型LLM)和7个推理器(即,推理型LLM)。在20个聊天机器人中,我们考虑了由不同公司训练的一般聊天机器人,如Llama [21]、Qwen [20]、Mistral [41, 42],以及特定领域的聊天机器人,包括数学 [22]、编码 [43]、科学 [44, 45]、医学 [46, 47] 和金融 [46, 47]。推理器包括来自DeepSeek [48]、Qwen [49] 和其他 [50]的LLM。我们将每个模型的最大标记限制设置为其自身容量,最大为8192标记,默认温度为0.5。特别地,所有在规划工作流中实例化的LLM都以固定温度0执行,以保证规划涉及格式遵循。我们的数据集涵盖了包括数学 [27, 51, 52, 53, 54, 55]、编码 [56, 57, 58]、科学 [36, 59, 60, 61]、医学 [62, 63, 64] 和金融 [65, 66, 67] 的领域,其中每个数据集最多随机抽取500个示例而不重复;详见第C节。
没有单一LLM在所有场景中表现优异。我们在图2中绘制了每个评估聊天机器人LLM在25个功能-领域组合中的大小-性能值,并在表1中报告了每个组合的前3名LLM的摘要;见图5和表5的所有LLM的结果。从这些结果中,我们看到(1)没有任何单一LLM在所有场景中普遍表现优异。一个异构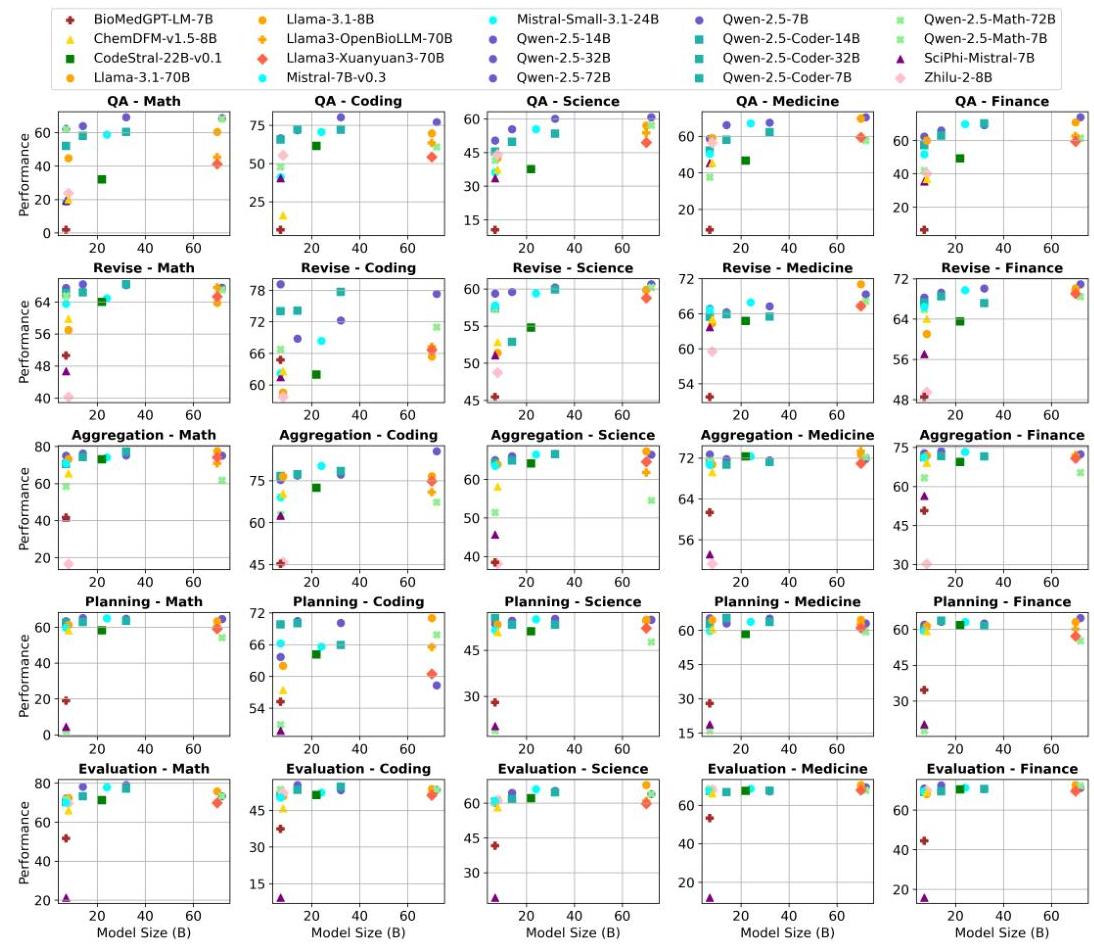
图2:在5个MAS相关功能和5个领域中基准测试聊天机器人LLM。我们看到没有任何单一LLM在所有场景中表现优异,这表明在MAS中使用异构LLM的潜在优势。所有评估结果都将开源以供未来研究。
MAS可以通过为特定场景分配专用模型(例如,医学中的Llama3-OpenBioLLM)来最大化集体智能。 (2) LLM在MAS相关功能中的表现各不相同,强化了异构性的价值。
单一LLM在不同领域和功能中的表现可能有显著差异。个别LLM在不同领域和功能中的表现存在显著差异,突显了在同质MAS中依赖单一模型的局限性。例如,在图2中,Qwen2.5-7B在编码领域的修订中表现非常出色;而在医学领域的修订和编码领域的规划中则降至中等水平。
在相同领域和功能中,LLM之间的表现差异很大。对于修订功能或编码领域,我们观察到被评估LLM的不同行为,如图2(第二行和第二列)所示的分散散点。
小规模LLM在特定场景中可以胜过大规模LLM。虽然像Qwen2.5-72B-Instruct和Llama-3.1-70B-Instruct这样的大规模模型经常领先,但小规模模型偶尔在特定功能-领域对中表现优异。例如,在修订-编码对中,Qwen2.5-7B-Instruct(79.2)胜过Qwen2.5-72B-Instruct(77.3);而在聚合-金融和评估-金融对中,Qwen2.5-14B在所有模型中表现最佳。这表明异构MAS可以通过纳入小型、专用模型来优化性能和计算效率,减少对资源密集型大模型的依赖,同时维持或改善结果。
低性能模型突显了同质MAS的风险。一些模型在不同领域和功能中持续表现不佳(例如,BioMedGPT-LM-7B 和 SciPhi-Mistral-7B-32k)。
表1:每种功能-领域组合的前3名LLM摘要(仅聊天机器人场景)。所有评估的LLM都是指令型模型(例如,Qwen2.5-32B 表示 Qwen2.5-32B-Instruct)。我们看到没有任何单一LLM在所有场景中表现优异。同时,顶级模型并不总是那些规模最大的,这表明改进性能和成本的潜力。
| 功能 | 排名 | 数学 | 编码 | 科学 | 医学 | 金融 |
|---|---|---|---|---|---|---|
| QA | 312\sqrt[12]{\sqrt{3}}123 | Qwen2.5-32B (69.2) | Qwen2.5-32B (80.3) | Qwen2.5-72B (60.7) | Qwen2.5-72B (70.4) | Qwen2.5-72B (74.0) |
| 312\sqrt[12]{\sqrt{3}}123 | Qwen2.5-72B (68.8) | Qwen2.5-72B (77.1) | Qwen2.5-32B (60.0) | Llama3-OpenBioLLM-70B (69.7) | Qwen2.5-32B (71.0) | |
| 312\sqrt[12]{\sqrt{3}}123 | Qwen2.5-Math-72B (68.2) | Qwen2.5-Coder-14B (72.3) | Qwen2.5-Math-72B (57.1) | Llama-3.1-70B (69.6) | Qwen2.5-Coder-32B (70.3) | |
| Revise | 312\sqrt[12]{\sqrt{3}}123 | Qwen2.5-Coder-32B (68.4) | Qwen2.5-7B (79.2) | Qwen2.5-72B (60.6) | Llama-3.1-70B (71.0) | Qwen2.5-72B (70.9) |
| 312\sqrt[12]{\sqrt{3}}123 | Qwen2.5-14B (68.4) | Qwen2.5-Coder-32B (77.7) | Qwen2.5-32B (60.2) | Qwen2.5-72B (69.3) | Llama-3.1-70B (70.1) | |
| 312\sqrt[12]{\sqrt{3}}123 | Qwen2.5-32B (68.2) | Qwen2.5-72B (77.3) | Qwen2.5-Math-72B (60.2) | Qwen2.5-Math-72B (68.1) | Qwen2.5-32B (70.1) | |
| Aggregation | 312\sqrt[12]{\sqrt{3}}123 | Llama-3.1-70B (77.4) | Qwen2.5-72B (85.5) | Llama-3.1-70B (67.3) | Llama3-OpenBioLLM-70B (73.4) | Qwen2.5-14B (73.6) |
| 312\sqrt[12]{\sqrt{3}}123 | Qwen2.5-Coder-32B (77.1) | Mistral-Small-3.1-24B (80.2) | Qwen2.5-32B (66.7) | Qwen2.5-7B (72.7) | Mistral-Small-3.1-24B (73.2) | |
| 312\sqrt[12]{\sqrt{3}}123 | Qwen2.5-14B (76.2) | Qwen2.5-Coder-32B (78.4) | Qwen2.5-Coder-32B (66.5) | Llama-3.1-70B (72.7) | Qwen2.5-7B (72.8) | |
| Planning | 312\sqrt[12]{\sqrt{3}}123 | Qwen2.5-14B (65.0) | Llama-3.1-70B (71.0) | Qwen2.5-Coder-7B (55.5) | Qwen2.5-Coder-14B (65.4) | Qwen2.5-72B (64.7) |
| 312\sqrt[12]{\sqrt{3}}123 | Mistral-Small-3.1-24B (65.0) | Qwen2.5-14B (70.5) | Qwen2.5-32B (55.3) | Qwen2.5-7B (65.3) | Qwen2.5-Coder-14B (63.6) | |
| 312\sqrt[12]{\sqrt{3}}123 | Qwen2.5-32B (64.7) | Qwen2.5-32B (70.1) | Mistral-Small-3.1-24B (55.1) | Qwen2.5-32B (65.2) | Qwen2.5-14B (63.2) | |
| Evaluation | 312\sqrt[12]{\sqrt{3}}123 | Qwen2.5-32B (79.0) | Qwen2.5-14B (55.4) | Llama-3.1-70B (67.9) | Llama-3.1-70B (70.5) | Llama-3.1-70B (72.6) |
| 312\sqrt[12]{\sqrt{3}}123 | Qwen2.5-14B (78.1) | Qwen2.5-Coder-32B (54.7) | Mistral-Small-3.1-24B (66.1) | Qwen2.5-72B (69.4) | Qwen2.5-14B (72.6) | |
| 312\sqrt[12]{\sqrt{3}}123 | Mistral-Small-3.1-24B (77.9) | Llama-3.1-70B (53.8) | Qwen2.5-32B (65.3) | Mistral-Small-3.1-24B (68.7) | Qwen2.5-Math-72B (72.3) |
依赖此类模型的同质MAS将受到严重限制,而异构设置可以通过集成合适且高性能的LLM来缓解这一问题。
一致的高绩效者支持稳健的异构配置。像Qwen-2.5-32B-Instruct、Qwen-2.5-72B-Instruct和Llama-3.1-70B-Instruct这样的模型频繁排名靠前跨领域和功能(例如,Qwen-2.5-32BInstruct在QA-coding中得分为80.3,在evaluation-math中得分为79.0)。这些模型可以在异构MAS中充当可靠的锚点,辅以针对特定任务的专用模型(例如,医学中的Llama3-OpenBioLLM-70B),确保稳健且可扩展的性能提升。
4 X-MAS-Design:利用多样性进行MAS
基于X-MAS-Bench(第3.2节)的发现,我们探讨了从同质到异构LLM驱动的MAS(X-MAS-Design)的转变效果。我们在第4.1节中展示了如何将同质MAS转换为异质MAS。我们在仅聊天机器人场景(第4.2节)和混合聊天机器人-推理器场景(第4.3节)中提供实验结果。
4.1 从同质到异构LLM驱动的MAS的转变
转换现有的MAS方法。作为概念验证,我们旨在展示简单的手动修改LLM配置可以增强MAS的性能,而无需任何结构性改进。对于每个目标MAS方法(例如,AgentVerse [16],LLM-Debate [15]),我们保留原始智能体角色和交互拓扑结构,但用几个适当的LLM替换单一的同质LLM。具体来说,对于原始设计中的每个领域-功能对(例如,AgentVerse中的编码评估者),我们用基于X-MAS-Bench(第3.2节)观察结果的最佳模型替换统一的LLM驱动程序。通过保留方法的交互逻辑和提示模板,我们确保任何性能提升完全来自于LLM的异质性,而不是工作流程的修改。请注意,这种修改是高效的,因为人类研究人员只需不到一分钟即可完成,即使我们用有限规模的LLM(例如,7B [20])替代人类也可以自动化。
X-MAS-Proto。除了将现有的MAS方法改编为异构方法外,我们还实现了X-MAS-Proto,一个明确实现所有五个功能(QA、修订、聚合、规划、评估)的原型MAS,作为适当对象进行调查。系统(参见图1中的MAS)首先调用一个规划智能体,生成几个针对问题的高层次想法;接下来,多个QA智能体基于相应的想法同时回答查询,其中一个答案将被评估和修订以获得潜在更好的答案;最后,一个聚合智能体综合多个答案以得出最终解决方案。通过X-MAS-Proto,我们可以直接为不同的功能性智能体分配适当的LLM,旨在清楚地展示LLM异质性在MAS中的好处。
表2:从同质到异构LLM驱动的MAS(X-MAS-Design)的转变。考虑了四种MAS方法和四种候选模型。X-MAS-Design在5个领域中始终达到最高性能(对于候选LLM来说,有3个领域相对较新)。
| MAS 方法 | LLM | 数学 | 编码 | 科学 | 医学 | 金融 | 平均 |
|---|---|---|---|---|---|---|---|
| AgentVerse [16] | Qwen2.5-Math-7B | 2.40 | 3.21 | 0.40 | 6.00 | 5.33 | 3.47 |
| Qwen2.5-Coder-32B | 75.20 | 72.69 | 32.00 | 47.60 | 64.00 | 58.30 | |
| Qwen2.5-32B | 83.20 | 76.31 | 34.00 | 50.40 | 74.67 | 63.72 | |
| Mistral-3.1-24B | 66.80 | 62.25 | 31.20 | 40.00 | 65.33 | 55.12 | |
| X-MAS-Design | 88.40 | 77.51 | 41.20 | 51.20 | 72.00 | 66.06 | |
| LLM-Debate [15] | Qwen2.5-Math-7B | 79.20 | 40.96 | 29.60 | 35.20 | 30.67 | 43.13 |
| Qwen2.5-Coder-32B | 82.40 | 78.71 | 34.40 | 46.80 | 68.00 | 62.06 | |
| Qwen2.5-32B | 85.20 | 75.50 | 32.80 | 50.80 | 77.33 | 64.33 | |
| Mistral-3.1-24B | 76.80 | 66.67 | 33.60 | 52.00 | 66.67 | 59.15 | |
| X-MAS-Design | 88.40 | 79.92 | 39.20 | 51.60 | 77.33 | 67.29 | |
| DyLAN [11] | Qwen2.5-Math-7B | 0.00 | 13.25 | 15.20 | 13.20 | 5.33 | 9.40 |
| Qwen2.5-Coder-32B | 77.20 | 78.31 | 34.80 | 41.60 | 61.33 | 58.65 | |
| Qwen2.5-32B | 81.60 | 74.70 | 38.00 | 46.00 | 73.33 | 62.73 | |
| Mistral-3.1-24B | 75.20 | 61.85 | 32.80 | 41.60 | 72.00 | 56.69 | |
| X-MAS-Design | 88.80 | 78.71 | 38.80 | 47.20 | 76.00 | 65.90 | |
| X-MAS-Proto | Qwen2.5-Math-7B | 10.40 | 12.85 | 2.00 | 10.80 | 5.33 | 8.28 |
| Qwen2.5-Coder-32B | 82.00 | 76.71 | 33.60 | 46.80 | 58.67 | 59.56 | |
| Qwen2.5-32B | 82.00 | 69.88 | 31.20 | 45.60 | 72.00 | 60.14 | |
| Mistral-3.1-24B | 78.80 | 63.05 | 34.40 | 46.40 | 72.00 | 58.93 | |
| X-MAS-Design | 90.40 | 78.71 | 40.00 | 46.80 | 73.33 | 65.85 |
4.2 仅聊天机器人场景的实验
实验设置。我们在X-MAS-Proto和三个现有的MAS方法上进行实验,包括AgentVerse [16]、LLM-Debate [15] 和 DyLAN [11]。考虑到性能和效率,我们选择了四个候选聊天机器人LLM:Qwen-2.5-32B、Mistral-Small-3.1-24B、Qwen-2.5-Coder-32B 和 Qwen-2.5-Math-7B。我们在MATH-500、MBPP、SciBench、PubMedQA 和 FinanceBench的保留测试集中测试MAS,涵盖了所检查的5个领域。详见第D节的模型选择。
X-MAS-Design相对于同质MAS的一致性能提升。表2报告了四种MAS方法的同质和异质版本的性能比较,选择了四个LLM作为候选。该表表明,X-MAS-Design(异质MAS配置)在平均意义上始终优于所有四种方法的所有同质配置。在DyLAN中,X-MAS-Design实现了平均65.90的性能,超过了最佳同质模型(Qwen2.5-32B,62.73)3个百分点。只有两个异常情况——LLM-Debate在医学领域和Agentverse在金融领域——可能是由于候选LLM不包括这些特定领域的专用模型。这些结果验证了X-MAS-Bench的发现,即识别出适用于领域-功能组合的最佳模型选择。通过利用多样且适当的LLM,X-MAS-Design利用集体智能,在不需对现有MAS方法进行结构更改的情况下实现卓越性能。
异质性的方法无关的好处。X-MAS-Design的性能提升在所有四个MAS方法中是一致的,尽管它们的架构和理念不同。这种X-MAS-Design改进的方法无关性质突出了其多功能性,为我们的核心思想提倡X-MAS提供了强有力的证据。
X-MAS-Design可以利用弱模型的优势来弥补其劣势。同质配置在不同领域的表现显示出显著的差异,某些模型在特定领域表现不佳。例如,Qwen2.5-Math-7B在大多数领域表现不佳(例如,AgentVerse中的数学2.40分,科学0.40分),表明其泛化能力有限。即使是更强的模型如Qwen2.5-32B和Mistral-3.1-24B也存在弱点,例如Mistral-3.124B在科学领域(AgentVerse)中的31.2分。相比之下,X-MAS-Design始终实现平衡性能。也就是说,X-MAS-Design通过结合它们的优势来缓解单个LLM的局限性,表明集体智能的好处以及我们的X-MAS-Bench为设计X-MAS提供了有益指导。
表3:在混合聊天机器人和推理器中的X-MAS-Design的有效性。虽然基于推理器的同质MAS表现不如基于聊天机器人的同质MAS,但在异质MAS中加入聊天机器人和推理器有助于大幅提升性能。
| MAS 方法 | LLM | 数学 | 编码 | 科学 | 医学 | 金融 | 平均 |
|---|---|---|---|---|---|---|---|
| AgentVerse [16] | 聊天机器人 | 20.00 | 75.50 | 37.60 | 47.20 | 72.00 | 50.46 |
| 推理器 | 0.00 | 11.65 | 5.60 | 44.40 | 21.33 | 16.60 | |
| X-MAS-Design | 50.00 | 77.91 | 40.00 | 52.40 | 78.67 | 59.80 | |
| LLM-Debate [15] | 聊天机器人 | 16.67 | 74.70 | 35.60 | 49.20 | 73.33 | 49.90 |
| 推理器 | 26.67 | 79.12 | 41.60 | 50.00 | 72.00 | 53.88 | |
| X-MAS-Design | 56.67 | 81.12 | 44.40 | 54.40 | 80.00 | 63.32 | |
| DyLAN [11] | 聊天机器人 | 20.00 | 74.70 | 34.00 | 44.00 | 70.76 | 48.67 |
| 推理器 | 40.00 | 76.31 | 42.40 | 45.60 | 68.00 | 54.46 | |
| X-MAS-Design | 63.33 | 80.32 | 42.80 | 46.80 | 76.00 | 61.85 | |
| X-MAS-Proto | 聊天机器人 | 23.33 | 72.69 | 34.80 | 44.80 | 68.00 | 48.72 |
| 推理器 | 0.00 | 71.49 | 23.20 | 49.20 | 56.00 | 39.98 | |
| X-MAS-Design | 70.00 | 79.12 | 47.20 | 52.80 | 76.00 | 65.02 |
4.3 混合聊天机器人-推理器场景的实验
实验设置。所检查的MAS方法与第4.2节相同。由于聊天机器人和推理器表现出不同的行为,我们考虑两个候选LLM:Qwen-2.5-72B-Instruct和DeepSeek-R1-Distill-Qwen-32B。这些方法在AIME-2024和MBPP、SciBench、PubMedQA和FinanceBench的保留分割上进行测试,涵盖了五个检查领域。我们还在完全新的(相对于X-MAS-Bench)测试集上测试这些方法:AIME-2025 [68](最新的AIME数学竞赛)和MATH-MAS [69](多步骤)。详见第E节的模型选择。
在X-MAS-Design中混合聊天机器人和推理器在所有领域和MAS方法中实现卓越性能。在表3中,我们探讨了在XMAS-Design中混合聊天机器人和推理器LLM的潜力。从表中可以看出(1)X-MAS-Design,结合由异构LLM驱动的聊天机器人和推理器智能体,始终优于所有五个领域的单独聊天机器人和推理器配置。(2)单独的聊天机器人和推理器配置显示出互补的优势和劣势。异构X-MAS-Design通过结合聊天机器人和推理器的优势来缓解个体角色的局限性,这是由X-MAS-Bench的170万次评估指导的。这种协同作用使跨不同领域的稳健性能成为可能。
混合聊天机器人和推理器在数学领域(AIME)中导致显著改进。我们另外在两个全新的基准上评估同质和异质MAS:AIME-2025和MATHMAS,见表4。从表3和4中可以看出,在数学领域(即,AIME-2024、AIME-2025、MATH-MAS),X-MAS-Design贡献了显著的性能提升。值得注意的是,对于X-MAS-Proto,X-MAS-Design在AIME-2024中得分70%70 \%70%,比第二好的同质MAS高出
表4:在全新基准上的检查。X-MAS-Design实现了显著最佳性能。
| 基准 | AIME-25 | MATH-M |
|---|---|---|
| 聊天机器人 | 13.33 | 14.18 |
| 推理器 | 10.00 | 5.97 |
| X-MAS-Design | 46.67\mathbf{4 6 . 6 7}46.67 | 48.13\mathbf{4 8 . 1 3}48.13 |
46.67%46.67 \%46.67%个百分点,这表明X-MAS在推理密集型任务中的潜力。同时,X-MAS-Design分别在具有挑战性的AIME-2025和MATH-MAS上比第二好的基于聊天机器人的同质MAS高出33%33 \%33%和34%34 \%34%,这表明我们核心思想的通用性。在推理模型盛行的时代,我们的实验指出一个潜在方向:通过混合聊天机器人和推理器进一步扩展计算规模的X-MAS。
4.4 消融研究
增加候选模型的数量可以提高X-MAS-Design的性能。按照第4.2节的设置,我们在三个领域(数学、编码和科学)上使用X-MAS-Proto进行实验,调整候选模型的数量。我们使用完整的分割以获得更大的样本数量。从图3中,我们可以观察到(1)X-MAS-Design始终优于同质MAS(即,1个候选模型),这表明X-MAS的好处。(2)随着候选模型数量的增加,我们通常可以观察到性能的提升。一个例外是在科学领域,这可能是由于从2增加到3的添加模型与科学不密切相关。这条曲线强烈表明在MAS中包含多样化LLM的好处。
任意模型选择可能导致次优性能:X-MAS-Bench提供了关键观察结果以指导XMAS的设计。为了验证X-MAS-Bench观察结果的有效性,我们将由X-MAS-Bench指导的LLM选择与任意选择的X-MAS进行比较。我们遵循第2节的设置,在MATH-500上对X-MAS-Proto进行实验。我们任意确定5组合理的设计X-MAS配置(详见第D.2节),用蓝色条形表示在图4中。由三种不同LLM驱动的同质MAS用红色条形表示。从图中可以看出(1)基于X-MAS-Bench观察结果设计的X-MAS-Design显著表现最佳。(2)在没有X-MAS-Bench指导的5个X-MAS中,其中3个的表现略好于同质MAS,而1个的表现略差于最佳同质MAS,另一个甚至表现显著更差(仅24.8%24.8 \%24.8%)。这表明适当的LLM选择对于确保X-MAS的性能至关重要,而X-MAS-Bench的结果可以提供有价值的见解。
5 结论
本文提倡构建基于异构LLM的MAS。我们介绍了X-MASBench,这是一个全面的测试平台,旨在评估各种LLM在支持MAS方面的能力。我们提供了一个系统的实证研究,评估了27个LLM(包括聊天机器人和推理器,通才和专家)在5个代表性的MAS相关功能和5个常见领域中的表现,突显了在MAS中使用异构LLM的潜力。基于从X-MAS-Bench获得的见解,我们考察了从同质到异构LLM驱动的MAS(X-MAS-Design)的影响。我们的实验操作在4种MAS方法上表明,通过利用异构MAS可以在不进行任何结构重新设计的情况下显著且一致地提高MAS的性能,强烈支持我们的倡导。请参阅第A节中的限制。
我们的工作突出了一种引人入胜的方向,即通过利用异构LLM的集体智能来实现更高层次的智能而不需额外训练。展望未来,未来的研究可以探索诸如自动或动态模型选择、进一步扩展模型候选者的影响力、优化LLM选择与MAS之间的协同效应、以较弱的代理实现强性能以及专门针对MAS训练代理等领域。
参考文献
- [1] OpenAI. Gpt-4技术报告。arXiv预印本arXiv:2303.08774, 2023.
-
- [2] Gemini团队,Petko Georgiev,Ving Ian Lei,Ryan Burnell,Libin Bai,Anmol Gulati,Garrett Tanzer,Damien Vincent,Zhufeng Pan,Shibo Wang等。Gemini 1.5: 解锁数百万上下文标记的多模态理解。arXiv预印本arXiv:2403.05530, 2024.
-
- [3] 杨安,杨宝松,张贝辰,惠斌元,郑波,余博文,李成远,刘大义,魏浩然等。Qwen2.5技术报告。arXiv预印本arXiv:2412.15115, 2024.
-
- [4] 张跃,李亚夫,崔乐洋,蔡登,刘磊茂,许廷晨,傅婷晨,黄新亭,赵恩博,张雨等。人工智能海洋中的海妖之歌:大型语言模型幻觉调查。arXiv预印本arXiv:2309.01219, 2023.
-
- [5] Min Sewon, Krishna Kalpesh, Lyu Xinxi, Lewis Mike, Yih Wen-tau, Koh Pang, Iyyer Mohit, Zettlemoyer Luke, 和Hannaneh Hajishirzi. Factscore: 长文本生成中事实精度的细粒度原子评估。在2023年经验方法自然语言处理会议论文集,第12076–12100页,2023.
-
- [6] 叶睿,唐硕,葛锐,杜雅欣,尹振飞,邵静,陈思恒。MAS-GPT:训练LLM构建基于LLM的多智能体系统。在大规模语言模型推理和规划研讨会,2025.
-
- [7] 钱辰,刘伟,刘宏璋,陈诺,当宇凡,李佳昊,杨成,陈威泽,苏玉盛,丛欣等。ChatDev:用于软件开发的通信代理。在计算语言学协会第62届年会论文集(第1卷:长篇论文),第15174–15186页,2024.
-
- [8] Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno 等. 朝向人工智能协作科学家。arXiv预印本arXiv:2502.18864, 2025.
-
- [9] Hong Sirui, Zhuge Mingchen, Chen Jonathan, Zheng Xiawu, Cheng Yuheng, Wang Jinlin, Zhang Ceyao, Wang Zili, Yau Steven Ka Shing, Lin Zijuan 等. MetaGPT: 元编程用于多代理协作框架。在第十二届国际学习表示会议,2024.
-
- [10] Lei Bin, Zhang Yi, Zuo Shan, Payani Ali, Ding Caiwen. Macm: 利用多代理系统在解决复杂数学问题中进行条件挖掘。在第三十八届神经信息处理系统年度会议,2024.
-
- [11] Liu Zijun, Zhang Yanzhe, Li Peng, Liu Yang, Yang Diyi. 动态LLM驱动的代理网络用于面向任务的代理协作。在第一届语言建模会议,2024.
-
- [12] Daniil A Boiko, Robert MacKnight, Ben Kline, 和 Gabe Gomes. 使用大型语言模型进行自主化学研究。Nature, 624(7992):570–578, 2023.
-
- [13] Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, 和 David Ha. AI科学家:迈向全自动开放式科学发现。arXiv预印本arXiv:2408.06292, 2024.
-
- [14] Hu Yue, Cai Yuzhu, Du Yaxin, Zhu Xinyu, Liu Xiangrui, Yu Zijie, Hou Yuchen, Tang Shuo, 和 Chen Siheng. 自我演化多代理网络用于软件开发。在第十三届国际学习表示会议,2025.
-
- [15] Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, 和 Igor Mordatch. 通过多代理辩论提高语言模型的事实性和推理能力。在第四十一届国际机器学习会议,2024.
-
- [16] Weize Chen, Su Yusheng, Zuo Jingwei, Yang Cheng, Yuan Chenfei, Chan Chi-Min, Yu Heyang, Lu Yaxi, Hung Yi-Hsin, Qian Chen 等. Agentverse: 促进多代理协作和探索新兴行为。在第十二届国际学习表示会议,2024.
-
- [17] Lu Hong 和 Scott E Page. 多样化问题求解者群体的表现可超过高能力问题求解者群体。国家科学院院刊,101(46):16385–16389, 2004.
-
- [18] Maria Kozhevnikov, Carol Evans, 和 Stephen M Kosslyn. 认知风格作为环境敏感的认知个体差异:现代合成及其在教育、商业和管理中的应用。心理学公共利益,15(1):3–33, 2014.
- [19] Ishani Aggarwal, Anita Williams Woolley, Christopher F Chabris, 和 Thomas W Malone. 认知多样性、集体智能和团队学习。集体智能会议记录,1(3.1):3-3, 2015 .
- [20] 杨安, 杨宝松, 张贝辰, 惠斌元, 郑博, 余博文, 李成远, 刘大义衡, 黄飞, 魏浩然, 林欢, 杨健, 屠建宏, 张建伟, 杨建新, 杨家曦, 周靖仁, 林俊阳, 当凯, 卢克明, 包科勤, 杨可欣, 李梅, 薛明峰, 张佩, 朱琴, 门瑞, 林润基, 李天豪, 夏廷宇, 任兴章, 任轩诚, 范阳, 苏阳, 张一昌, 刘余, 刘玉琼, 崔泽宇, 张震儒, 秋子涵. Qwen2.5技术报告. arXiv预印本arXiv:2412.15115, 2024.
- [21] Dubey Abhimanyu, Jauhri Abhinav, Pandey Abhinav, Kadian Abhishek, Al-Dahle Ahmad, Letman Aiesha, Mathur Akhil, Schelten Alan, Yang Amy, Fan Angela 等. Llama 3模型群. arXiv预印本arXiv:2407.21783, 2024.
- [22] 杨安, 张贝辰, 惠斌元, 高博菲, 余博文, 李成鹏, 刘大义衡, 屠建宏, 周靖仁, 林俊阳 等. Qwen2.5-math技术报告: 通过自我改进走向数学专家模型. arXiv预印本arXiv:2409.12122, 2024.
- [23] Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang 等. Self-refine: 迭代式自我反馈改进. 神经信息处理系统进展, 36, 2024.
- [24] 钱辰, 谢子皓, 王奕菲, 刘伟, 朱坤伦, 夏汉辰, 当宇凡, 杜卓芸, 陈维泽, 杨城, 刘志源, 孙茂松. 扩展基于大规模语言模型的多智能体协作. 在第十三届国际学习表示会议, 2025.
- [25] 梁天, 何智伟, 姜文祥, 王星, 王艳, 王蕊, 杨昱久, 施淑明, 屠兆鹏. 通过多智能体辩论鼓励大型语言模型的发散思维. 在Yaser Al-Onaizan, Mohit Bansal 和 Yun-Nung Chen 编辑的2024年经验方法自然语言处理会议论文集, 第17889-17904页, 美国佛罗里达州迈阿密, 2024年11月. 计算语言学协会.
- [26] Md Ashraful Islam, Mohammed Eunus Ali, 和 Md Rizwan Parvez. Mapcoder: 用于竞争性问题解决的多智能体代码生成. 在计算语言学协会第62届年会论文集(第1卷:长篇论文), 第4912-4944页, 2024.
- [27] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, 和 Jacob Steinhardt. 使用数学数据集衡量数学问题解决能力. NeurIPS, 2021.
- [28] Shengran Hu, Cong Lu, 和 Jeff Clune. 自动设计智能体系统. 在第十三届国际学习表示会议, 2025.
- [29] Lingjiao Chen, Matei Zaharia, 和 James Zou. 少即是多:使用多个LLM以更低的成本进行应用. 在ICML2023基础模型高效系统研讨会, 2023.
- [30] Saranya Venkatraman, Nafis Irtiza Tripto, 和 Dongwon Lee. Collabstory: 多LLM协作故事生成与作者分析. arXiv预印本arXiv:2406.12665, 2024.
- [31] Dongfu Jiang, Xiang Ren, 和 Bill Yuchen Lin. LLM-blender: 使用成对排名和生成融合集成大型语言模型. 在计算语言学协会第61届年会论文集(第1卷:长篇论文), 第14165-14178页, 2023.
- [32] Junlin Wang, Jue WANG, Ben Athiwaratkun, Ce Zhang, 和 James Zou. 混合智能体增强大型语言模型能力. 在第十三届国际学习表示会议, 2025 .
- [33] Justin Chen, Swarnadeep Saha, 和 Mohit Bansal. Reconcile: 圆桌会议通过共识改善多样化的LLM推理. 在计算语言学协会第62届年会论文集(第1卷:长篇论文), 第7066-7085页, 2024.
- [34] Yue Yanwei, Zhang Guibin, Liu Boyang, Wan Guancheng, Wang Kun, Cheng Dawei, 和 Qi Yiyan. Masrouter: 学习为多智能体系统路由LLM. arXiv预印本arXiv:2502.11133, 2025.
- [35] Carlos E Jimenez, John Yang, Alexander Wettig, Yao Shunyu, Pei Kexin, Press Ofir, 和 Narasimhan Karthik R. Swe-bench: 语言模型能否解决现实世界的GitHub问题?在第十二届国际学习表示会议,2024.
- [36] David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, 和 Samuel R Bowman. Gpqa: 一种研究生级别的谷歌证明问答基准。arXiv预印本arXiv:2311.12022, 2023.
- [37] OpenAI. Introducing healthbench. https://openai.com/index/healthbench/, 2025. Accessed: 2025-05-15.
- [38] 谢倩倩, 韩卫光, 张晓, 赖彦钊, 彭敏, Alejandro Lopez-Lira, 和 黄吉民. Pixiu: 一个大型语言模型、指令数据和评估基准。在神经信息处理系统国际会议第37届会议论文集,第 33469−33484,202333469-33484,202333469−33484,2023.
- [39] Valmeekam Karthik, Marquez Matthew, Olmo Alberto, Sreedharan Sarath, 和 Subbarao Kambhampati. Planbench: 一个可扩展的基准,用于评估大型语言模型在规划和变化推理方面的表现。神经信息处理系统进展,36:38975-38987, 2023.
- [40] Tan Sijun, Zhuang Siyuan, Montgomery Kyle, William Yuan Tang, Cuadron Alejandro, Wang Chenguang, Popa Raluca, 和 Stoica Ion. Judgebench: 评估基于LLM的法官的基准。在第十三届国际学习表示会议,2025.
- [41] Mistral. Mistral-7b-instruct-v0.3. https://huggingface.co/mistralai/ Mistral-7B-Instruct-v0.3, 2024. Accessed: 2025-05-15.
- [42] Mistral. Mistral-small-3.1-24b-instruct-2503. https://huggingface.co/mistralai/ Mistral-Small-3.1-24B-Instruct-2503, 2025. Accessed: 2025-05-15.
- [43] 惠斌元, 杨健, 崔泽宇, 杨佳曦, 刘大义衡, 张雷, 刘天宇, 张佳军, 余博文, 卢柯明 等. Qwen2.5-coder技术报告. arXiv预印本arXiv:2409.12186, 2024.
- [44] 赵子涵, 马达, 陈路, 孙良泰, 李子浩, 夏毅, 陈波, 许洪深, 朱思珠, 珠苏 等. 开发ChemDFM作为化学领域的大型语言基础模型. Cell Reports Physical Science, 6(4), 2025.
- [45] SciPhi. Sciphi-mistral-7b-32k. https://huggingface.co/SciPhi/SciPhi-Mistral-7B-32k, 2023. Accessed: 2025-05-15.
- [46] Duxiaoman-DI. Llama3-xuanyuan3-70b-chat. https://huggingface.co/Duxiaoman-DI/ Llama3-XuanYuan3-70B-Chat, 2024. Accessed: 2025-05-15.
- [47] SYSU-MUCFC-FinTech-Research-Center. Zhilu-2-8b-instruct. https://huggingface.co/ SYSU-MUCFC-FinTech-Research-Center/ZhiLu-2-8B-Instruct, 2024. Accessed: 2025-05-15.
- [48] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Ma Shirong, Wang Peiyi, Xiao Bi 等. Deepseek-r1: 通过强化学习激励LLM推理能力. arXiv预印本arXiv:2501.12948, 2025.
- [49] Qwen Team. Qwq-32b: 拥抱强化学习的力量,2025年3月.
- [50] OpenThoughts Team. Open Thoughts. https://open-thoughts.ai, 2025年1月.
- [51] Wang Ling, Dani Yogatama, Chris Dyer, 和 Phil Blunsom. 通过理由生成进行程序归纳:学习解决和解释代数文字问题。在计算语言学协会第55届年会论文集(第1卷:长篇论文),第158-167页,2017年。
- [52] Luyu Gao, Aman Madaan, Zhou Shuyan, Uri Alon, Liu Pengfei, Yang Yiming, Jamie Callan, 和 Graham Neubig. PAL: 程序辅助的语言模型。在国际机器学习会议论文集,第10764-10799页。PMLR, 2023.
- [53] Maxwell-Jia. Aime-2024. https://huggingface.co/datasets/Maxwell-Jia/AIME_2024, 2024. Accessed: 2025-05-15.
- [54] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, 和 Jacob Steinhardt. 测量大规模多任务语言理解。在国际学习表示会议,2021.
- [55] 王禹博, 马雪光, 张格, 尹元盛, 查布拉尼, 郭世光, 任卫明, 陈文虎, 何宣, 江子言, 珠天乐, 库马克斯, 王凯, Zhuang Alex, 范荣奇, 袁香越, 叶想, 陈温花. MMLU-pro: 更加稳健和具有挑战性的多任务语言理解基准. 在第三十八次会议关于神经信息处理系统数据集和基准轨道, 2024.
- [56] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, 等. 评估训练于代码的大规模语言模型。arXiv预印本arXiv:2107.03374, 2021.
- [57] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, 等. 使用大规模语言模型进行程序综合。arXiv预印本arXiv:2108.07732, 2021.
- [58] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, 和 Lingming Zhang. ChatGPT生成的代码是否真的正确?对代码生成大规模语言模型的严格评估。在第三十七届神经信息处理系统会议,2023.
- [59] Wang Xiaoxuan, Ma Da, Chen Lu, Sun Liangtai, Li Zihao, Xia Yi, Chen Bo, Xu Hongshen, Zhu Zichen, Zhu Su, 等. 开发ChemDFM作为一种化学领域的大型语言基础模型。Cell Reports Physical Science, 6(4), 2025.
- [60] SciPhi. Sciphi-mistral-7b-32k. https://huggingface.co/SciPhi/SciPhi-Mistral-7B-32k, 2023. Accessed: 2025-05-15.
- [61] Duxiaoman-DI. Llama3-xuanyuan3-70b-chat. https://huggingface.co/Duxiaoman-DI/ Llama3-XuanYuan3-70B-Chat, 2024. Accessed: 2025-05-15.
- [62] SYSU-MUCFC-FinTech-Research-Center. Zhilu-2-8b-instruct. https://huggingface.co/ SYSU-MUCFC-FinTech-Research-Center/ZhiLu-2-8B-Instruct, 2024. Accessed: 2025-05-15.
- [63] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Ma Shirong, Wang Peiyi, Xiao Bi, 等. Deepseek-r1: 通过强化学习激励LLM推理能力。arXiv预印本arXiv:2501.12948, 2025.
- [64] Qwen Team. Qwq-32b: 拥抱强化学习的力量,2025年3月。
- [65] OpenThoughts Team. Open Thoughts. https://open-thoughts.ai, January 2025.
- [66] Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by rationale generation: Learning to solve and explain algebraic word problems. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 158-167, 2017.
- [67] Gao Luyu, Madaan Aman, Zhou Shuyan, Alon Uri, Liu Pengfei, Yang Yiming, Callan Jamie, and Neubig Graham. PAL: Program-aided language models. In International Conference on Machine Learning, pages 10764-10799. PMLR, 2023.
- [68] Maxwell-Jia. Aime-2024. https://huggingface.co/datasets/Maxwell-Jia/AIME_2024, 2024. Accessed: 2025-05-15.
- [69] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations, 2021.
- [70] Wang Yubo, Ma Xueguang, Zhang Ge, Ni Yuansheng, Chandra Abhranil, Guo Shiguang, Ren Weiming, Arulraj Aaran, He Xuan, Jiang Ziyan, Li Tianle, Ku Max, Wang Kai, Zhuang Alex, Fan Rongqi, Yue Xiang, and Chen Wenhu. MMLU-pro: A more robust and challenging multi-task language understanding benchmark. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024.
- [71] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [72] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- [73] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- [74] Wang Xiaoxuan, Hu Ziniu, Lu Pan, Zhu Yanqiao, Zhang Jieyu, Subramaniam Satyen, Loomba Arjun R, Zhang Shichang, Sun Yizhou, and Wang Wei. SciBench: Evaluating college-level scientific problem-solving abilities of large language models. In Forty-first International Conference on Machine Learning, 2024.
- [75] Liangtai Sun, Han Yang, Zhao Zihan, Ma Da, Shen Zhennan, Chen Baocai, Chen Lu, and Yu Kai. SciEval: A multi-level large language model evaluation benchmark for scientific research. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19053-19061, 2024.
- [76] Kehua Feng, Ding Keyan, Wang Weijie, Zhuang Xiang, Wang Zeyuan, Qin Ming, Zhao Yu, Yao Jianhua, Zhang Qiang, and Chen Huajun. SciKnowEval: Evaluating multi-level scientific knowledge of large language models. arXiv preprint arXiv:2406.09098, 2024.
- [77] Ankit Pal, Logesh Kumar Umapathi, 和 Malaikannan Sankarasubbu. MedMCQA: 一个大规模多学科多选数据集,用于医学领域的问题回答。在健康、推断和学习会议论文集,第248-260页。PMLR, 2022.
- [78] Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, 和 Peter Szolovits. What disease does this patient have? 一个大规模开放领域问题回答数据集来自医学考试。应用科学,11(14):6421, 2021.
- [79] Qiao Jin, Bhuwan Dhingra, Liu Zhengping, Cohen William, 和 Lu Xinghua. PubMedQA: 一个用于生物医学研究问题回答的数据集。在2019年经验方法自然语言处理和第九届国际联合自然语言处理会议论文集(EMNLP-IJCNLP),第2567-2577页,2019. Pranab Islam, Anand Kannappan, Douwe Kiela, Rebecca Qian, Nino Scherrer, 和 Bertie Vidgen. FinanceBench: 一个新的金融问题回答基准。arXiv预印本arXiv:2311.11944, 2023.
- [81] Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan R Routledge, 等. FinQA: 一个用于财务数据数值推理的数据集。在2021年经验方法自然语言处理会议论文集,第3697-3711页,2021.
- [82] P. Malo, A. Sinha, P. Korhonen, J. Wallenius, 和 P. Takala. 好债还是坏债:检测经济文本中的语义倾向。信息科学与技术协会期刊,65, 2014.
- [83] OpenCompass. Aime2025. https://huggingface.co/datasets/opencompass/AIME2025, 2024. Accessed: 2025-05-15.
- [84] Heng Zhou, Hejia Geng, Xiangyuan Xue, Zhenfei Yin, 和 Lei Bai. Reso: 一个基于奖励驱动的自组织LLM多智能体系统,用于推理任务。arXiv预印本arXiv:2503.02390, 2025.
- [85] Mistral. Codestral-22b-v0.1. https://huggingface.co/mistralai/Codestral-22B-v0.1, 2024. Accessed: 2025-05-15.
- [86] Malaikannan Sankarasubbu Ankit Pal. OpenBioLLMs: 推动开源大型语言模型在医疗保健和生命科学领域的发展。https://huggingface.co/aaditya/OpenBioLLM-Llama3-70B, 2024.
- [87] Yizhen Luo, Jiahuan Zhang, Siqi Fan, Kai Yang, Yushuai Wu, Mu Qiao, 和 Zaiqing Nie. BioMedGPT: 开放式生物医学多模态生成预训练变换器。arXiv预印本arXiv:2308.09442, 2023.
参考论文:https://arxiv.org/pdf/2505.16997

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 26
26 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)