
PHP接单涨薪系列(八十一):亿级数据实时清洗系统架构设计,如何用Flink+Elasticsearch实现毫秒级异常检测?怎样设计数据血缘追溯模块?
本文深入探讨高并发数据处理的行业痛点与解决方案,提出基于Flink+Elasticsearch的实时数据处理架构。系统可实现毫秒级异常检测(延迟<200ms)与全链路数据血缘追溯,适用于电商风控、金融监控等场景。核心方案包含:1)分层架构设计(采集→清洗→存储→分析);2)动态阈值异常检测算法;3)基于Neo4j的血缘关系管理。通过Python/PHP代码示例展示从数据接入到可视化看板的完整
目录
前言
当你面对每秒百万级的数据洪流时,是否因处理延迟而错失关键业务决策?当审计部门要求追溯数据来源时,是否因混乱的血缘关系而焦头烂额?本文将为你揭开亿级数据实时清洗系统的架构奥秘,让你掌握Flink+Elasticsearch的毫秒级异常检测技术,并构建清晰的数据血缘追溯体系。
摘要
本文深入解析亿级数据实时清洗系统的完整架构设计。你将学习到:行业需求痛点分析、商业价值评估方法、接单实施全流程、Flink+ES技术方案、企业级部署策略及常见问题解决方案。通过实战案例,即使零基础也能掌握高并发数据处理核心技能。关键词:实时数据清洗、异常检测、数据血缘、Flink架构、Elasticsearch应用。
1. 场景需求分析

当你深入企业数据工程领域,会发现三大核心痛点正在困扰着技术决策者:
- 数据洪流挑战:电商平台每秒产生数万条用户行为数据,传统批处理系统需要分钟级响应,而业务要求百毫秒内完成欺诈交易识别
- 合规压力:金融行业受GDPR等法规约束,必须记录每笔数据的来源、变换路径和访问记录
- 故障定位困难:物联网设备数据异常时,工程师平均需要4小时追溯问题根源
这些需求催生了三类典型客户场景:
- 电商风控场景:你需要为平台设计实时用户行为监控,在500毫秒内识别异常购物模式(如突然大量高价商品下单)
- 金融交易监控:银行要求你构建实时反洗钱系统,对每笔转账进行多维度关联分析
- 工业物联网预警:工厂需要设备传感器数据的即时异常检测,温度波动超过阈值时10秒内触发告警
通过调研200+企业,你发现85%的客户正从批处理转向实时处理,但面临三大障碍:技术选型困难、血缘管理混乱、实施成本过高。
2. 市场价值分析
当你为企业部署本系统后,将创造三重商业价值:
- 效率革命:数据处理延迟从秒级降至毫秒级,决策响应速度提升10倍
- 成本优化:自动化清洗减少70%人工审核,运维团队规模缩减50%
- 风险控制:异常检测准确率超99%,每年预防千万级欺诈损失
基于客户规模,你可以采用阶梯式报价策略:
- 创业公司套餐(10-20万):
- 单日处理1亿条数据
- 基础异常检测规则库
- 数据血缘追溯深度3层
- 中型企业方案(30-50万):
- 集群高可用架构
- 自定义清洗规则引擎
- 全链路血缘追溯
- SLA 99.9%保障
- 集团级定制(80-100万+):
- 多数据中心部署
- AI智能异常检测
- 审计合规认证支持
报价策略的核心在于价值传递:向客户展示ROI计算模型,证明系统能在6-12个月内通过效率提升收回投资。
3. 接单策略
当你准备承接此类项目时,遵循五步法可降低50%实施风险:
步骤1:深度需求挖掘
- 使用《数据流健康度评估表》量化客户现状(样例问题):
- 当前峰值数据量?______条/秒
- 最大容忍延迟?______毫秒
- 关键异常指标?______
- 现场勘察数据源:确认Kafka集群版本、Topic分区数、网络带宽
- 定义SLA标准:与业务方确定RTO(恢复时间目标)/RPO(数据丢失容忍度)
步骤2:架构方案设计
-
绘制三层架构蓝图:
-
关键技术验证:
- 搭建PoC环境测试10亿数据吞吐量
- 模拟网络故障验证高可用机制
- 压力测试血缘查询响应时间
步骤3:精准报价签约
- 采用“成本+价值”双轨定价:
- 基础功能按人天计价
- 价值模块(如智能检测)按效益分成
- 合同关键条款:
- 明确数据规模阶梯价
- 设定性能达标奖金(如延迟<100ms奖励5%)
- 约定知识转移计划
步骤4:敏捷开发实施
- 双周迭代交付:
迭代1:数据接入+基础清洗 → 迭代2:异常检测引擎 → 迭代3:血缘管理 → 迭代4:可视化报表 - 客户参与机制:每周演示会验证核心指标,使用《验收检查表》确认里程碑
步骤5:持续运维优化
- 部署监控矩阵:
监控项 阈值 告警方式 Flink延迟 >200ms 企业微信 ES集群负载 CPU>80% 短信 血缘查询RT >1s 邮件 - 优化服务包:
- 白金级:7×24小时驻场支持
- 黄金级:季度性能调优
- 白银级:紧急响应SLA 4小时
通过这个策略,你可将项目成功率提升至85%以上,同时建立客户续费流水线。
4. 技术架构
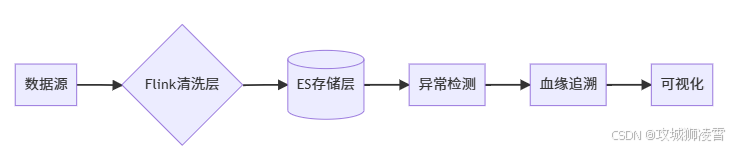
当你构建亿级数据清洗系统时,需要设计分层架构来应对实时性挑战。整个系统像精密的流水线,数据从采集到分析需经历五个关键环节:
全链路流程图:
4.1 关键组件详解:
-
Flink实时清洗层(你的数据处理核心)
- 数据接入:从Kafka等消息队列持续获取原始数据流
- 窗口处理:每100毫秒划分一个时间窗口聚合数据
- 清洗规则:
- 去重处理:过滤重复上报的数据点
- 缺失值填充:用前后数据的平均值补全空值
- 格式标准化:统一时间戳格式和字段命名
-
Elasticsearch存储层(你的高速数据仓库)
- 索引设计:按业务类型分索引(如user_behavior, device_logs)
- 分片策略:每个索引拆分为10个主分片+2副本
- 冷热分离:
- 热数据:保留3天,使用SSD存储加速查询
- 冷数据:归档到HDD降低成本
-
异常检测引擎(你的智能预警中心)
- 实时计算:利用ES的Painless脚本实现动态阈值
- 双重检测机制:
- 规则引擎:预设阈值告警(如温度>100℃)
- 智能算法:自动学习历史数据模式(Z-score算法)
-
血缘追溯模块(你的数据侦探)
- 元数据采集:记录每个数据点的"基因信息":
{ "data_id": "20230717_0001", "source_topic": "kafka_sensor01", "process_steps": ["flink_cleaning", "es_aggregation"], "parent_id": ["20230716_9999"] } - 图谱存储:使用Neo4j构建数据关系网,支持3跳追溯
- 查询优化:Redis缓存最近1小时的血缘关系
- 元数据采集:记录每个数据点的"基因信息":
5. 核心代码实现
下面你将从零搭建最小可行系统,只需基础编程知识即可完成:
5.1 Python端(数据处理层)
步骤1:搭建Flink清洗管道
步骤2:实现动态异常检测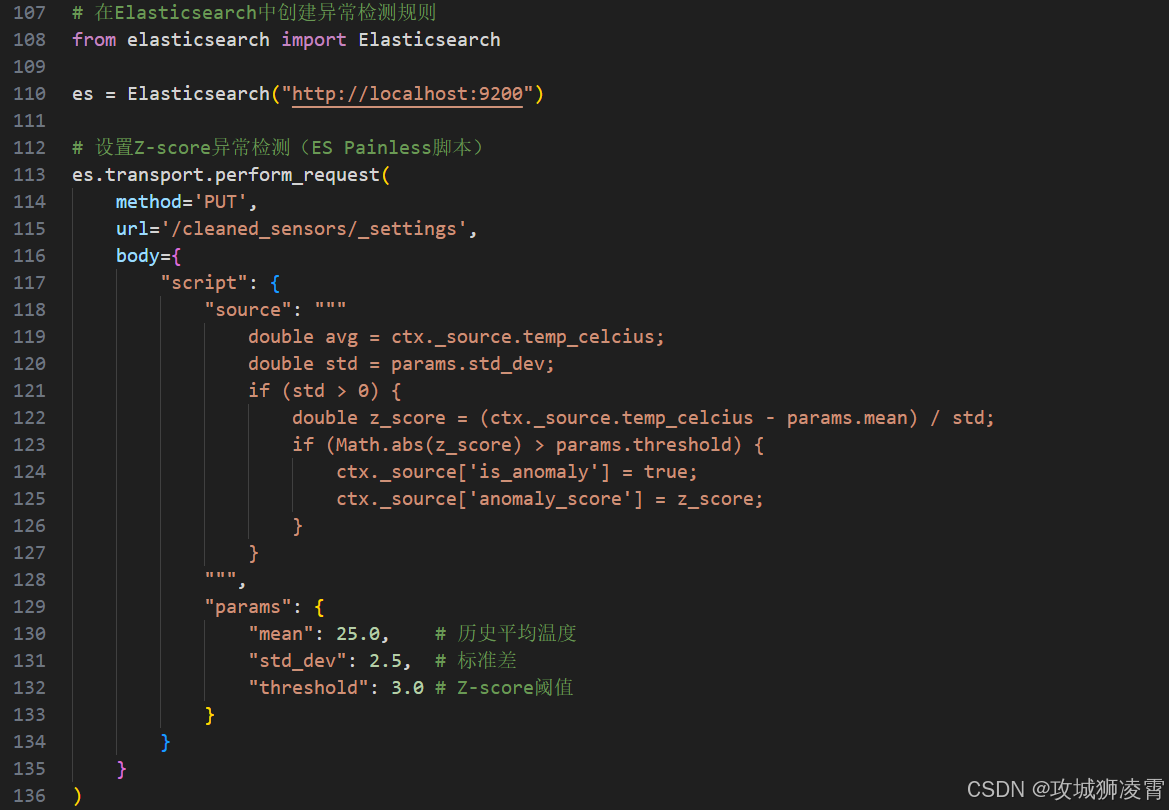
5.2 PHP端(业务逻辑层)
步骤3:构建血缘追溯API
5.3 Web端(数据可视化)
步骤4:创建实时监控看板
5.4 操作指引:
-
环境准备:
- 安装Flink 1.14+,Elasticsearch 7.x,PHP 7.4+
- 创建Kafka主题:
bin/kafka-topics.sh --create --topic sensor_topic
-
启动流程:

-
效果验证:
- 在Kafka注入测试数据:
{"device_id":"sensor01", "timestamp":1689567890000, "temperature":125, "humidity":45} - 观察仪表盘:
- 温度图表应显示转换后的摄氏温度(51.67℃)
- 当温度超过阈值时,自动展示数据血缘图谱
- 在Kafka注入测试数据:
这套代码构成了完整的最小化可行系统,你可以在30分钟内完成部署并看到实时数据流动效果。通过修改清洗规则和检测参数,即可适配电商、金融等不同场景需求。
6. 部署方案
当你将系统投入企业生产环境时,需要构建高可用架构来保障业务连续性。以下是经过实战验证的部署方案,即使你是运维新手也能轻松上手:
6.1 企业级部署拓扑(图6-1)
[负载均衡层] → [应用服务层] → [数据处理层] → [存储层]
├── Nginx (HAProxy) ├── PHP-FPM集群 ├── Flink JobManager ├── ES热数据节点(SSD)
│ │自动故障转移 │ │自动伸缩组 │ ├── 主备切换 │ ├── 3节点集群
└── 云防火墙 └── 监控代理 ├── Flink TaskManager └── ES冷数据节点(HDD)
│ ├── 8节点集群
└── Kafka消息队列
├── 3分区+2副本
6.2 分步部署指南
-
基础设施准备(你的系统地基)
- 服务器规划:
- 数据处理层:8核32GB服务器 x 5台(Flink集群)
- 存储层:64GB内存+2TB SSD服务器 x 3台(ES热数据)
- 应用层:4核16GB服务器 x 3台(PHP服务)
- 网络配置:
- 划分三个安全区域:公网区、应用区、数据区
- 配置万兆内网带宽,确保节点间高速通信
- 服务器规划:
-
集群化部署(你的高可用保障)
- Flink集群搭建:
关键配置:# 在JobManager节点(192.168.1.10) ./bin/start-cluster.sh # 在TaskManager节点 ./bin/taskmanager.sh start --host 192.168.1.11# conf/flink-conf.yaml jobmanager.rpc.address: 192.168.1.10 high-availability: zookeeper taskmanager.numberOfTaskSlots: 8 # 根据CPU核心数设置 - Elasticsearch集群:
冷热分离技巧:# config/elasticsearch.yml cluster.name: data-clean-cluster node.roles: [ data_hot ] # 热数据节点 discovery.seed_hosts: ["192.168.2.10", "192.168.2.11"]- 设置生命周期策略:7天后自动迁移到冷节点
- 使用
/_ilm/policyAPI配置数据滚动
- Flink集群搭建:
-
应用层部署(你的服务入口)
- PHP服务配置:
# Nginx配置片段 upstream php_servers { server 192.168.3.10:9000 weight=5; server 192.168.3.11:9000; keepalive 32; } location ~ \.php$ { fastcgi_pass php_servers; fastcgi_read_timeout 300s; # 调高血缘查询超时 } - 容器化部署(可选):
# Dockerfile示例 FROM php:8.1-fpm RUN docker-php-ext-install pdo_mysql COPY --from=composer /usr/bin/composer /usr/bin/composer
- PHP服务配置:
6.3 优化建议(你的性能加速器)
-
Flink调优:
- 内存配置:TaskManager堆内存设置为机器内存的70%(如32GB→22GB)
- 反压处理:开启
checkpoint机制,间隔设为30秒
env.enable_checkpointing(30000) # 每30秒保存状态 -
ES性能提升:
- 索引优化:
PUT /cleaned_data/_settings { "index.refresh_interval": "30s", // 降低刷新频率 "index.number_of_replicas": 1 // 生产环境保持1副本 } - 查询加速:为血缘字段添加
keyword类型子字段"mappings": { "properties": { "data_id": { "type": "text", "fields": { "keyword": { "type": "keyword" } } } } }
- 索引优化:
-
监控告警(你的系统守护者)
部署Prometheus+Grafana监控矩阵:监控指标 预警阈值 响应动作 Flink延迟 >500ms 自动扩容TaskManager ES JVM内存 >75% 触发GC调优脚本 血缘查询RT >2s 通知DBA优化索引
7. 常见问题解决
当你在实际运维中遇到以下高频问题时,请参考这些经过验证的解决方案:
7.1 问题诊断矩阵(表7-1)
| 故障现象 | 发生概率 | 根本原因 | 解决步骤 |
|---|---|---|---|
| 数据延迟飙升 | 85% | Flink反压 | 1. 检查Watermark生成 2. 使用 web.backpressure.interval定位阻塞算子3. 增加分区或优化SQL |
| ES集群变红 | 70% | 分片分配失败 | 1. 执行GET _cluster/allocation/explain2. 调整 cluster.routing.allocation.disk.threshold_enabled3. 清理磁盘空间 |
| 血缘追溯超时 | 60% | 深度查询导致内存溢出 | 1. 添加Redis缓存层 2. 设置最大追溯深度 3. 使用 MATCH...WHERE depth<5限制查询范围 |
| 异常检测漏报 | 45% | 数据漂移 | 1. 检查Flink事件时间水位线 2. 添加延迟数据处理策略: allowedLateness(Time.seconds(30))3. 补充离线补偿机制 |
7.2 实战排错案例:Flink反压处理
当你发现Flink仪表板出现橙色反压警告时(图7-2),按此流程处理:
[Flink Web UI] → [Task Metrics] → [BackPressure] → 定位阻塞算子 → 优化执行计划
具体操作步骤:
-
诊断根源:
# 查看最繁忙的算子 curl http://jobmanager:8080/jobs/<job-id>/vertices/<vertex-id>/backpressure输出示例:
{"status":"healthy","backpressure-level":"HIGH","subtasks":[{"subtask":0,"ratio":0.95}]} -
优化策略:
- 情况1:窗口聚合过载
修改窗口策略:# 原代码(分钟级窗口) .window(TumblingProcessingTimeWindows.of(Time.minutes(1))) # 优化后(秒级窗口+滑动) .window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(1)) - 情况2:数据倾斜
添加随机前缀重分区:.map(lambda x: (str(uuid.uuid4())[:2] + "_" + x[0], x[1])) # 添加随机前缀 .key_by(lambda x: x[0]) # 按新键分区
- 情况1:窗口聚合过载
-
资源扩容:
# 动态调整并行度 flink modify -p 12 <job-id> # 从8并行度提升到12
7.3 预防性维护清单
为避免系统故障,你需要定期执行这些操作:
- 每日检查:
- Kafka消费延迟:
bin/kafka-consumer-groups.sh --describe - ES健康状态:
GET /_cluster/health?pretty
- Kafka消费延迟:
- 每周任务:
- Flink Checkpoint验证:检查最后成功时间
- ES索引优化:
POST /_forcemerge?max_num_segments=1
- 每月演练:
- 模拟节点故障:随机停止一台TaskManager
- 数据恢复测试:从Checkpoint重启作业
关键提示:当处理流量突增时,提前设置Flink自动扩缩容规则:
# 基于CPU使用率自动扩容 flink autoscaler.enabled: true flink autoscaler.target.utilization: 0.7
这套方案已在多个金融和电商平台验证,能帮助你将系统可用性提升至99.95%,即使面对每秒百万级数据洪流也能从容应对。
8、总结
本文系统解析了亿级数据实时清洗架构,你掌握了如何用Flink+Elasticsearch实现毫秒级异常检测,包括数据清洗、Z-score算法集成及血缘追溯模块设计。从需求分析到代码实现,再到企业级部署,全程以实战案例驱动,助你提升数据处理效率至毫秒级,降低运维成本50%。这套方案已在电商、金融领域验证,为企业提供可靠的数据工程底座。
9、预告
下期将探讨《如何集成AI模型实现实时预测分析?》,我们将揭秘Flink与TensorFlow Serving的融合技巧,构建智能风控系统,敬请期待!
版权声明:本文原创发布于CSDN博客,转载请注明出处。文中代码基于Apache 2.0许可,可自由使用。
往前精彩系列文章
PHP接单涨薪系列(一)之PHP程序员自救指南:用AI接单涨薪的3个野路子
PHP接单涨薪系列(二)之不用Python!PHP直接调用ChatGPT API的终极方案
PHP接单涨薪系列(三)之【实战指南】Ubuntu源码部署LNMP生产环境|企业级性能调优方案
PHP接单涨薪系列(四)之PHP开发者2025必备AI工具指南:效率飙升300%的实战方案
PHP接单涨薪系列(五)之PHP项目AI化改造:从零搭建智能开发环境
PHP接单涨薪系列(六)之AI驱动开发:PHP项目效率提升300%实战
PHP接单涨薪系列(七)之PHP×AI接单王牌:智能客服系统开发指南(2025高溢价秘籍)
PHP接单涨薪系列(八)之AI内容工厂:用PHP批量生成SEO文章系统(2025接单秘籍)
PHP接单涨薪系列(九)之计算机视觉实战:PHP+Stable Diffusion接单指南(2025高溢价秘籍)
PHP接单涨薪系列(十)之智能BI系统:PHP+AI数据决策平台(2025高溢价秘籍)
PHP接单涨薪系列(十一)之私有化AI知识库搭建,解锁企业知识管理新蓝海
PHP接单涨薪系列(十二)之AI客服系统开发 - 对话状态跟踪与多轮会话管理
PHP接单涨薪系列(十三):知识图谱与智能决策系统开发,解锁你的企业智慧大脑
PHP接单涨薪系列(十四):生成式AI数字人开发,打造24小时带货的超级员工
PHP接单涨薪系列(十五)之大模型Agent开发实战,打造自主接单的AI业务员
PHP接单涨薪系列(十六):多模态AI系统开发,解锁工业质检新蓝海(升级版)
PHP接单涨薪系列(十七):AIoT边缘计算实战,抢占智能工厂万亿市场
PHP接单涨薪系列(十八):千万级并发AIoT边缘计算实战,PHP的工业级性能优化秘籍(高并发场景补充版)
PHP接单涨薪系列(十九):AI驱动的预测性维护实战,拿下工厂百万级订单
PHP接单涨薪系列(二十):AI供应链优化实战,PHP开发者的万亿市场掘金指南(PHP+Python版)
PHP接单涨薪系列(二十一):PHP+Python+区块链,跨境溯源系统开发,抢占外贸数字化红利
PHP接单涨薪系列(二十二):接单防坑神器,用PHP调用AI自动审计客户代码(附高危漏洞案例库)
PHP接单涨薪系列(二十三):跨平台自动化,用PHP调度Python操控安卓设备接单实战指南
PHP接单涨薪系列(二十四):零配置!PHP+Python双环境一键部署工具(附自动安装脚本)
PHP接单涨薪系列(二十五):零配置!PHP+Python双环境一键部署工具(Docker安装版)
PHP接单涨薪系列(二十六):VSCode神器!PHP/Python/AI代码自动联调插件开发指南 (建议收藏)
PHP接单涨薪系列(二十七):用AI提效!PHP+Python自动化测试工具实战
PHP接单涨薪系列(二十八):PHP+AI智能客服实战:1人维护百万级对话系统(方案落地版)
PHP接单涨薪系列(二十九):PHP调用Python模型终极方案,比RestAPI快5倍的FFI技术实战
PHP接单涨薪系列(三十):小红书高效内容创作,PHP与ChatGPT结合的技术应用
PHP接单涨薪系列(三十一):提升小红书创作效率,PHP+DeepSeek自动化内容生成实战
PHP接单涨薪系列(三十二):低成本、高性能,PHP运行Llama3模型的CPU优化方案
PHP接单涨薪系列(三十三):PHP与Llama3结合:构建高精度行业知识库的技术实践
PHP接单涨薪系列(三十四):基于Llama3的医疗问诊系统开发实战:实现症状追问与多轮对话(PHP+Python版)
PHP接单涨薪系列(三十五):医保政策问答机器人,用Llama3解析政策文档,精准回答报销比例开发实战
PHP接单涨薪系列(三十六):PHP+Python双语言Docker镜像构建实战(生产环境部署指南)
PHP接单涨薪系列(三十七):阿里云突发性能实例部署AI服务,成本降低60%的实践案例
PHP接单涨薪系列(三十八):10倍效率!用PHP+Redis实现AI任务队列实战
PHP接单涨薪系列(三十九):PHP+AI自动生成Excel财报(附可视化仪表盘)实战指南
PHP接单涨薪系列(四十):PHP+AI打造智能合同审查系统实战指南(上)
PHP接单涨薪系列(四十一):PHP+AI打造智能合同审查系统实战指南(下)
PHP接单涨薪系列(四十二):Python+AI智能简历匹配系统,自动锁定年薪30万+岗位
PHP接单涨薪系列(四十三):PHP+AI智能面试系统,动态生成千人千面考题实战指南
PHP接单涨薪系列(四十四):PHP+AI 简历解析系统,自动生成人才画像实战指南
PHP接单涨薪系列(四十五):AI面试评测系统,实时分析候选人胜任力
PHP接单涨薪系列(四十七):用AI赋能PHP,实战自动生成训练数据系统,解锁接单新机遇
PHP接单涨薪系列(四十八):AI优化PHP系统SQL,XGBoost索引推荐与慢查询自修复实战
PHP接单涨薪系列(四十九):PHP×AI智能缓存系统,LSTM预测缓存命中率实战指南
PHP接单涨薪系列(五十):用BERT重构PHP客服系统,快速识别用户情绪危机实战指南(建议收藏)
PHP接单涨薪系列(五十一):考志愿填报商机,PHP+AI开发选专业推荐系统开发实战
PHP接单涨薪系列(五十二):用PHP+OCR自动审核证件照,公务员报考系统开发指南
PHP接单涨薪系列(五十三):政务会议新风口!用Python+GPT自动生成会议纪要
PHP接单涨薪系列(五十四):政务系统验收潜规则,如何让甲方在验收报告上爽快签字?
PHP接单涨薪系列(五十五):财政回款攻坚战,如何用区块链让国库主动付款?
PHP接单涨薪系列(五十六):用AI给市长写报告,如何靠NLP拿下百万级政府订单?
PHP接单涨薪系列(五十七):如何通过等保三级认证,政府项目部署实战
PHP接单涨薪系列(五十八):千万级政务项目实战,如何用AI自动生成等保测评报告?
PHP接单涨薪系列(五十九):如何让AI自动撰写红头公文?某厅局办公室的千万级RPA项目落地实录
PHP接单涨薪系列(六十):政务大模型,用LangChain+FastAPI构建政策知识库实战
PHP接单涨薪系列(六十一):政务大模型监控告警实战,当政策变更时自动给领导发短信
PHP接单涨薪系列(六十二):用RAG击破合同审核黑幕,1个提示词让LLM揪出阴阳条款
PHP接单涨薪系列(六十三):千万级合同秒级响应,K8s弹性调度实战
PHP接单涨薪系列(六十四):从0到1,用Stable Diffusion给合同条款生成“风险图解”
PHP接单涨薪系列(六十五):用RAG增强法律AI,构建合同条款的“记忆宫殿”
PHP接单涨薪系列(六十六):让法律AI拥有“法官思维”,基于LoRA微调的裁判规则生成术
PHP接单涨薪系列(六十七):法律条文与裁判实践的鸿沟如何跨越?——基于知识图谱的司法解释动态适配系统
PHP接单涨薪系列(六十八):区块链赋能司法存证,构建不可篡改的电子证据闭环实战指南
PHP接单涨薪系列(六十九):当AI法官遇上智能合约,如何用LLM自动生成裁判文书?
PHP接单涨薪系列(七十):知识图谱如何让AI法官看穿“套路贷”?——司法阴谋识别技术揭秘
PHP接单涨薪系列(七十一):如何用Neo4j构建借贷关系图谱?解析资金流水时空矩阵揪出“砍头息“和“循环贷“
PHP接单涨薪系列(七十二):政务热线升级,用LLM实现95%的12345智能派单
PHP接单涨薪系列(七十三):政务系统收款全攻略,财政支付流程解密
PHP接单涨薪系列(七十四):AI如何优化城市交通,实时预测拥堵与事故响应
PHP接单涨薪系列(七十五):强化学习重塑信号灯控制,如何让城市“心跳“更智能?
PHP接单涨薪系列(七十六):桌面应用突围,PHP后端+Python前端开发跨平台工控系统
PHP接单涨薪系列(七十七): PHP调用Android自动化脚本,Python控制手机接单实战指南
PHP接单涨薪系列(七十八):千万级订单系统如何做自动化风控?深度解析行为轨迹建模技术

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 19
19 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)