
【Python selenium过简书滑块】今天这个滑块不简单,看似不简单实则不简单哪!
用Python 的 selenium模块,自动化过简书【滑块】,过程略微复杂,要切割背景图,还要OCR识别
·
文章日期:2024.07.25
使用工具:Python
文章类型:自动化过简书滑块
文章全程已做去敏处理!!! 【需要做的可联系我】
AES解密处理(直接解密即可)(crypto-js.js 标准算法):在线AES加解密工具
【点赞 收藏 关注 】仅供学习,仅供学习。
注意:简书的滑块不仅可以用selenium,也可以直接代码跳过,本文只讲解selenium跳过滑块,勿喷
今天用Python 的 selenium模块,自动化过简书滑块验证,来看视频,滑块验证后出现的页面找不到是因为我直接调用了简书的验证地址,意思是我直接打开了简书的人机验证页面,当我验证成功过后就会出现页面找不到,正常的。
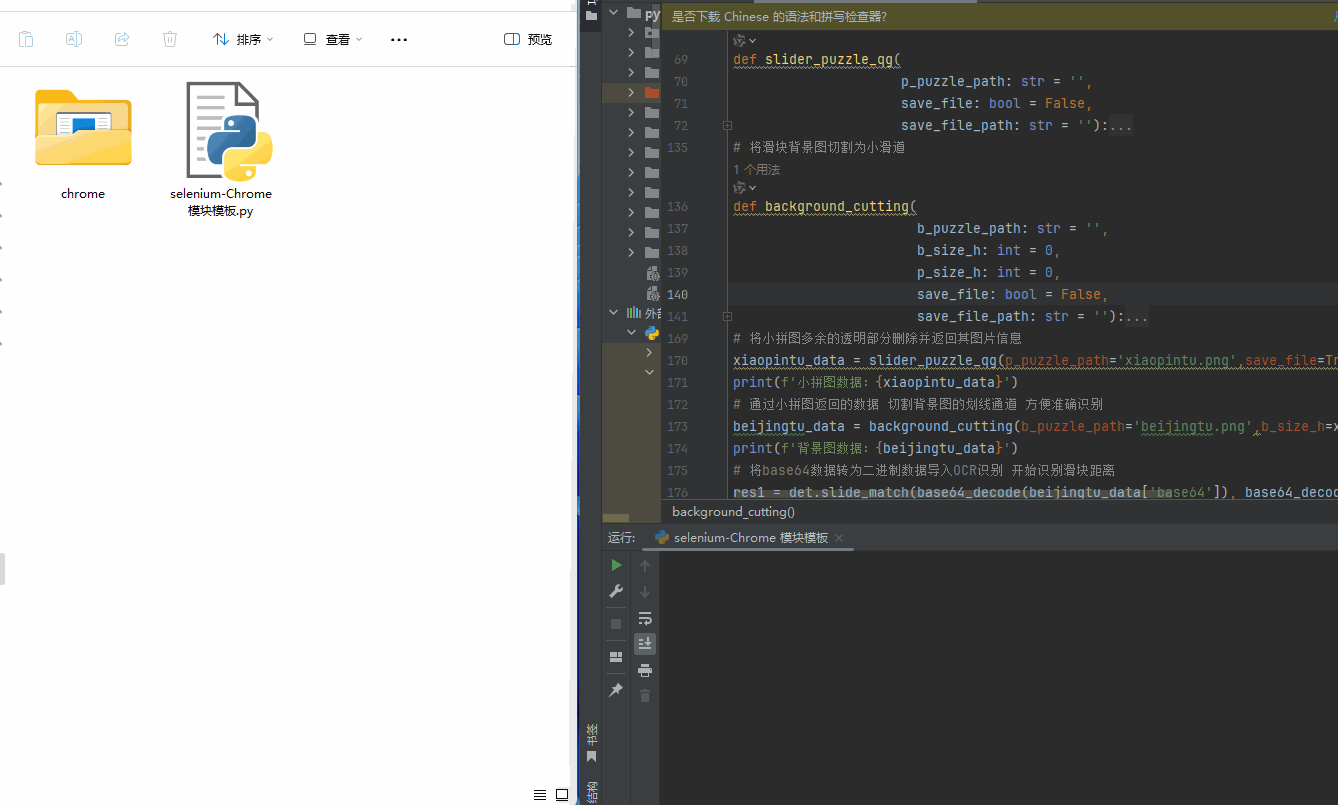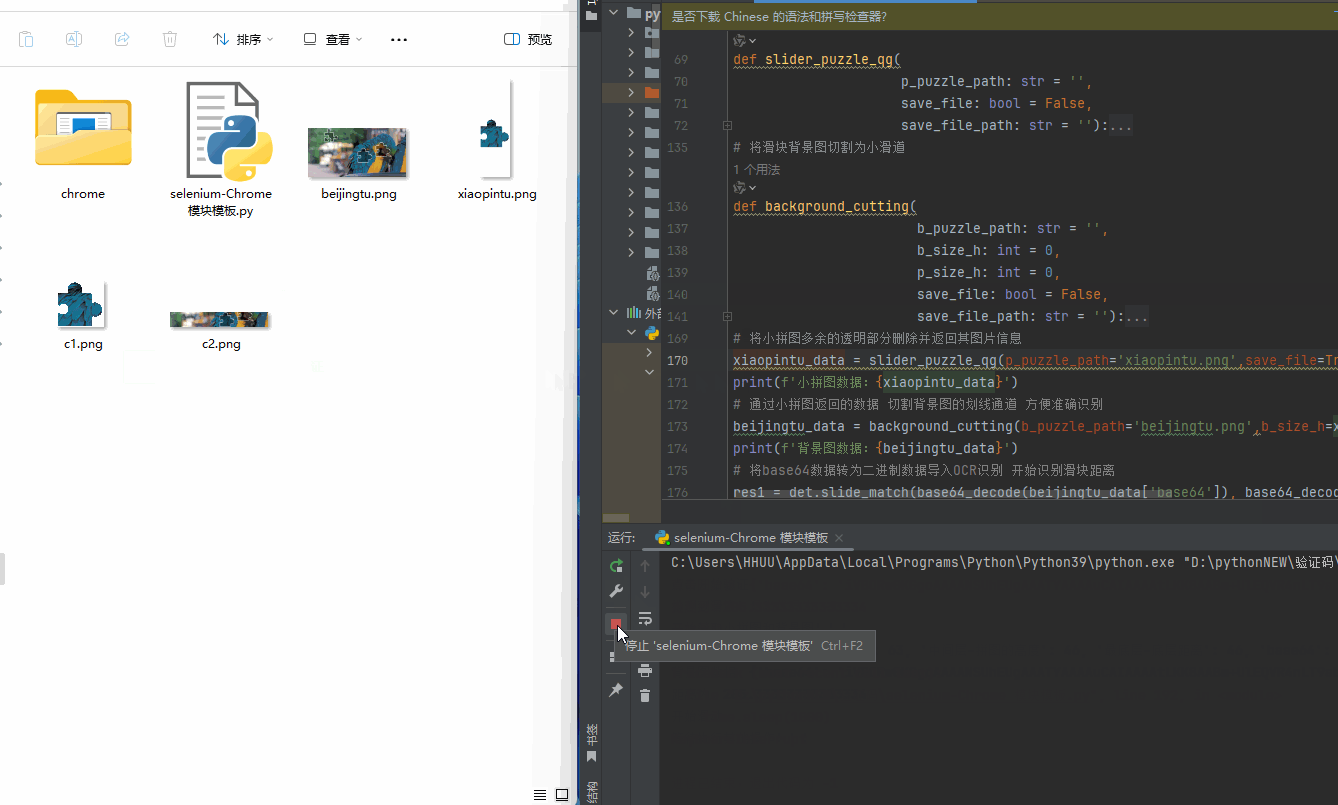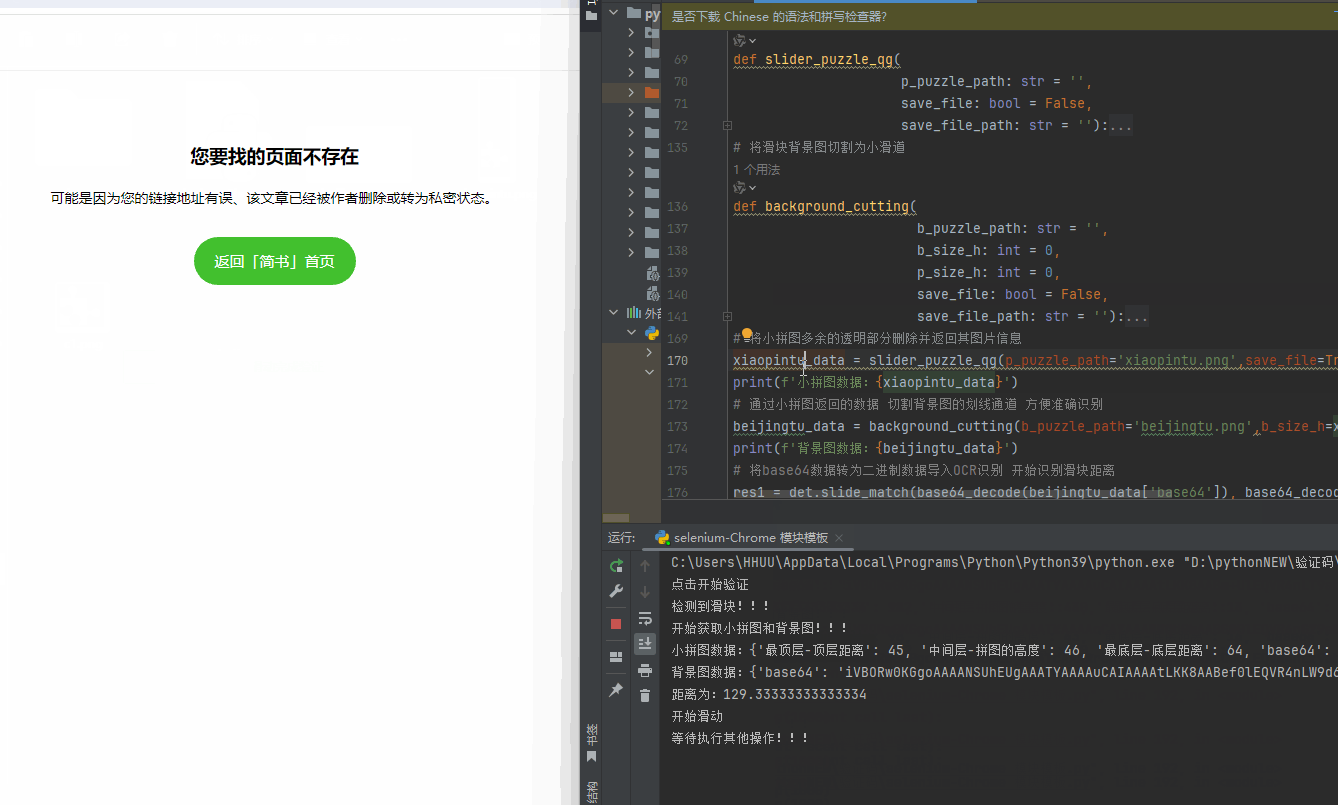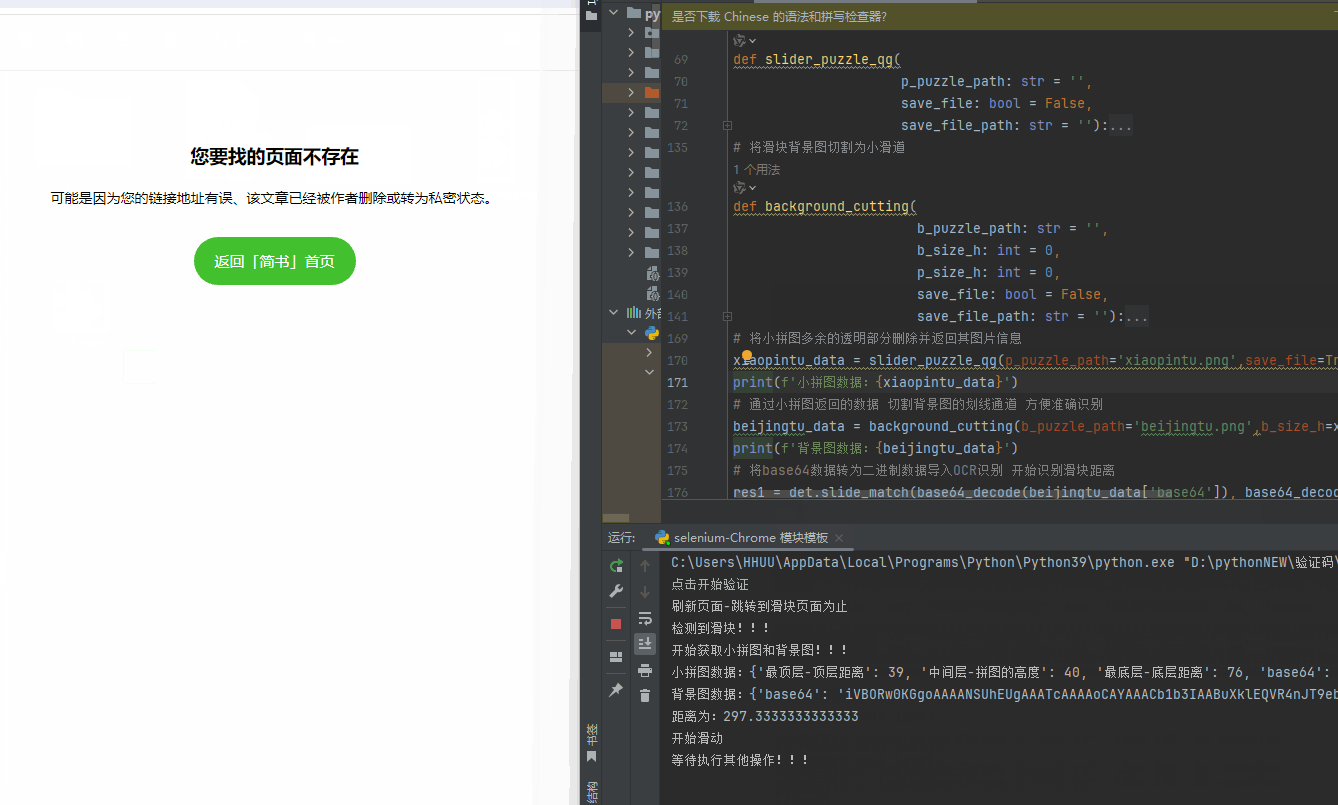
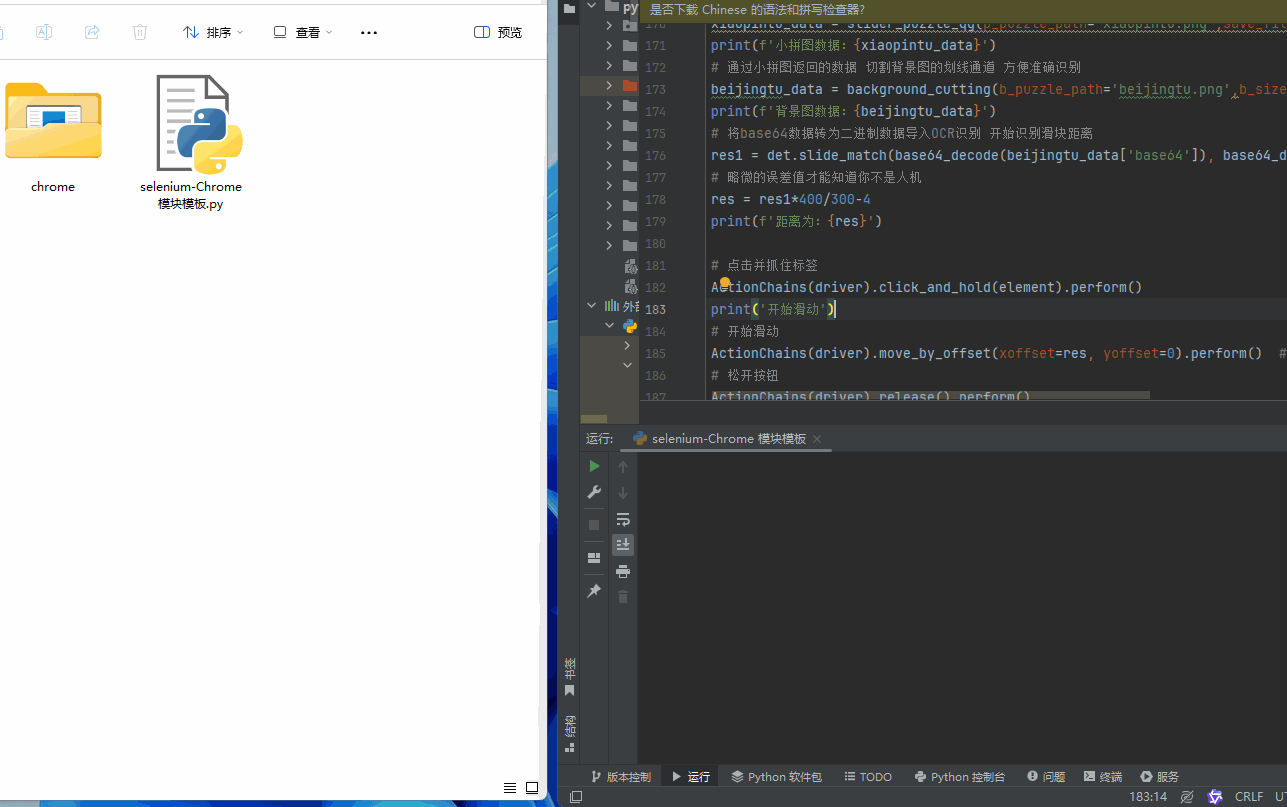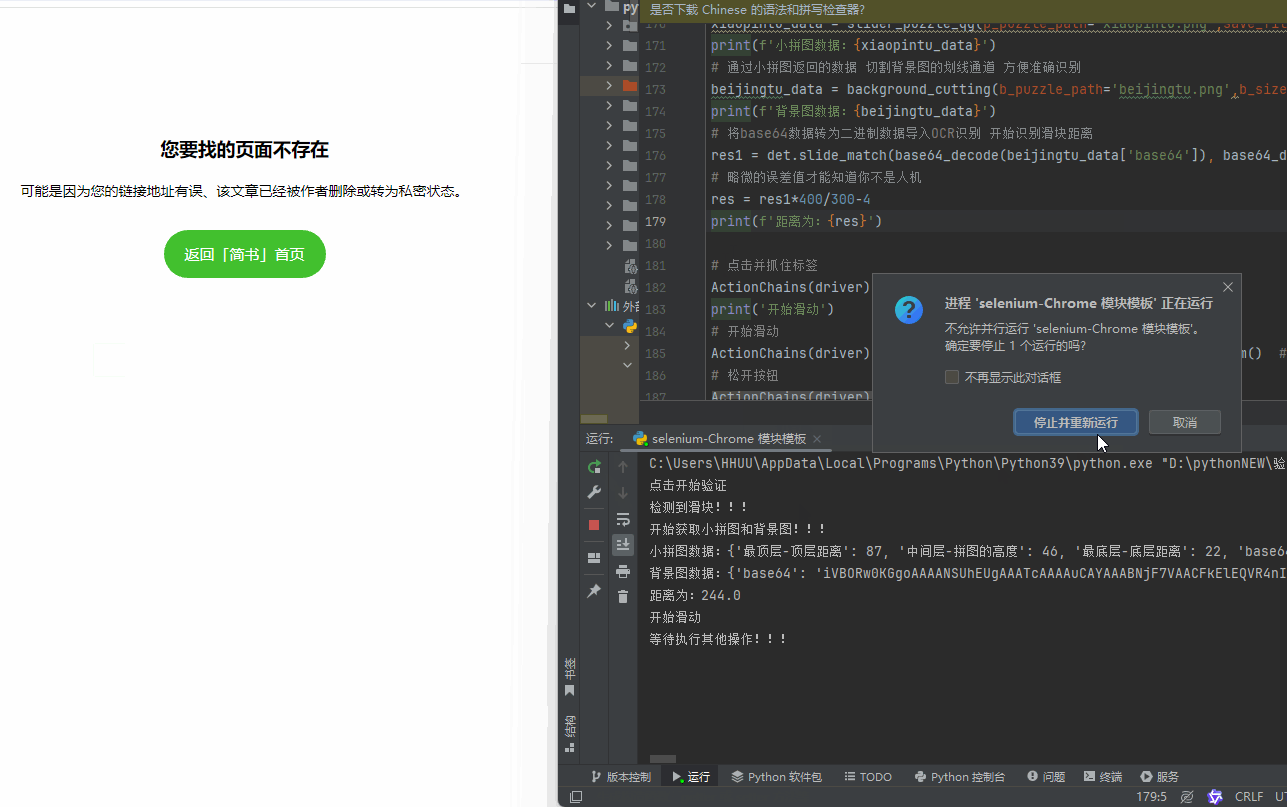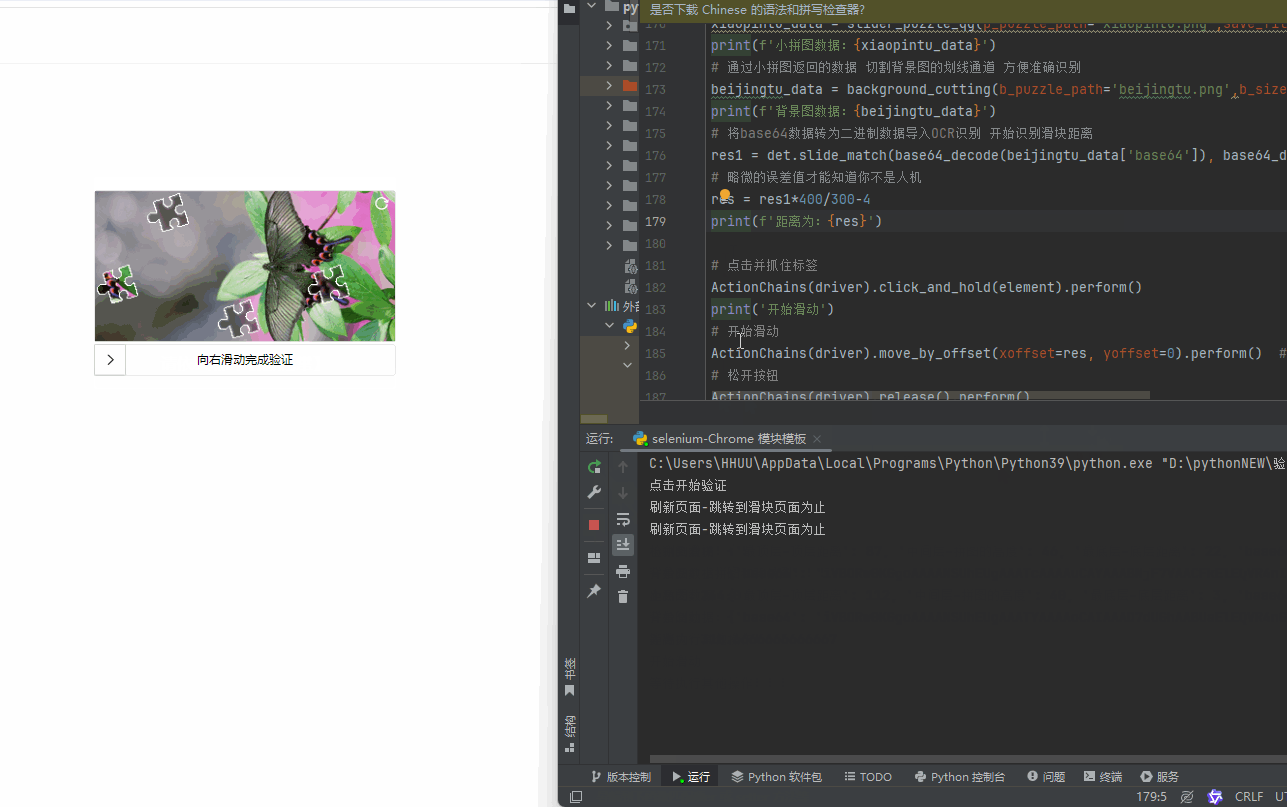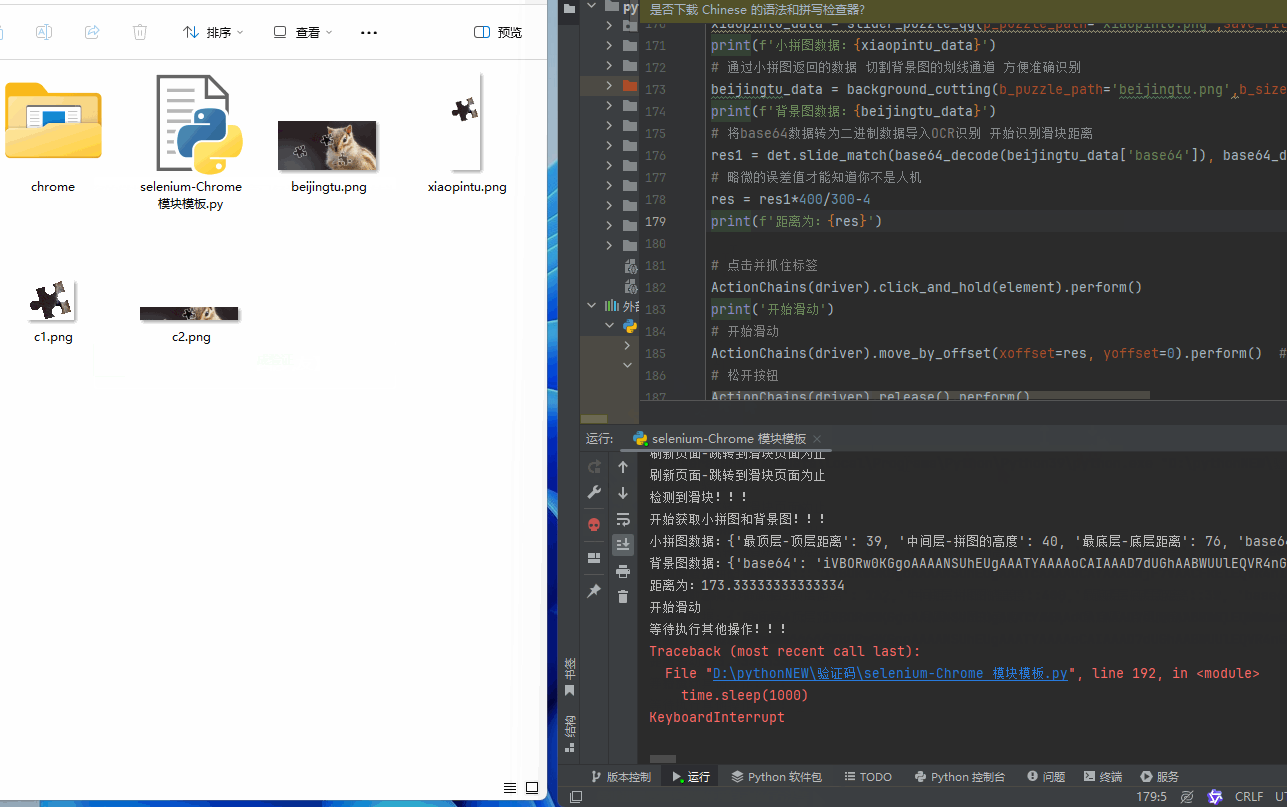
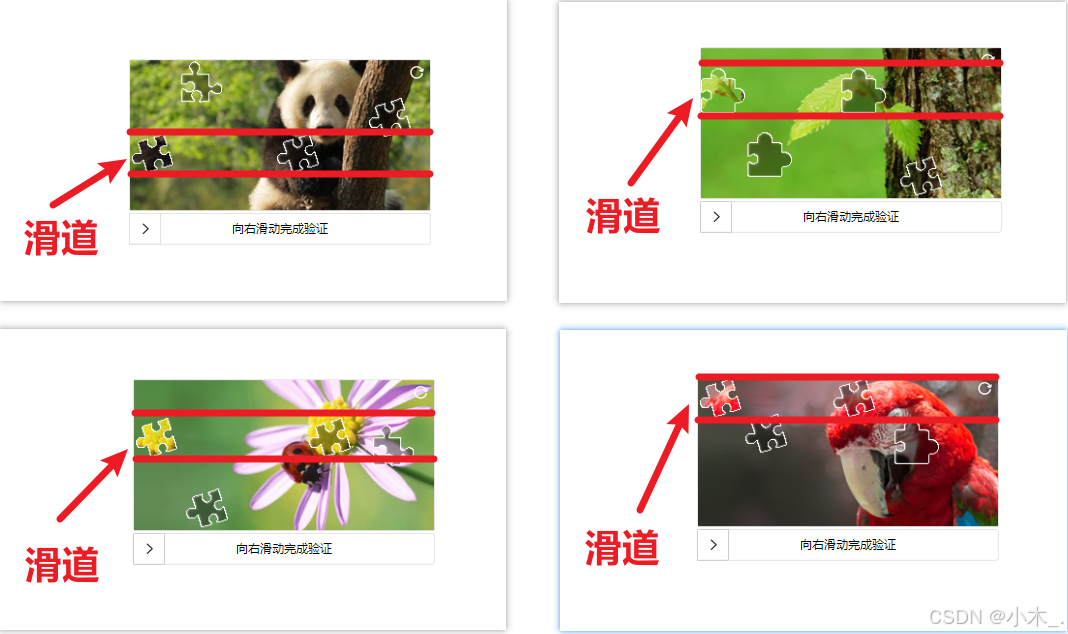
1、首先这个滑块不能直接用OCR识别,需要把图片经过处理才能用COR识别,你看下面的图,如果直接用OCR识别会导致识别出错误的坐标,可能真人去操作都会出错,但经过处理就不会

2、怎么处理呢,看下面的图(PNG),大家应该都知道PNG透明像素是【(0, 0, 0, 0)】,而非透明部分应该是【(0,0,0,此处非0)】,为了更精准,只需要判断最后一位数,只要不低于5-10.就表示此处是非透明像素点,哪就可以证明它是已经检测到了小拼图的位置,由此可以得出拼图位于顶部的高度。小拼图自身的高度可以通过,向下继续检测,当第四位像素点是低于5-10的时候,就表示此处是小拼图的底部了,由此也可得出小拼图的高度。剩下的就不需要检测了,直接跳过即可,如果有需要,那可以通过总拼图的高度减去小拼图的顶部高度和自身高度,也就能得出小拼图距离底部的高度了。

3、放简单了来说,我们只要这个【滑道背景】和【小拼图】即可,这样可以保证OCR识别准确,不会识别错误。到这里你要是还不明白,就去自己尝试尝试,慢慢你就明白了
【附上代码】代码拿走吧,注释写的很明白,不懂可以留言哦
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import re
import numpy as np
from PIL import Image
import io
import time
import base64
# 安装库 pip install ddddocr
import ddddocr
# 运行脚本实列化一次即可,不要重复实列化,会浪费时间
det = ddddocr.DdddOcr(det=False, ocr=False)
# 配置 Chrome 浏览器
chrome_options = webdriver.ChromeOptions()
chrome_options.binary_location = "chrome/chrome.exe" # 指定 Chrome 浏览器的路径
chrome_options.add_argument("--disable-infobars") # 禁用浏览器中的"信息栏",避免干扰测试。
# 启动浏览器
driver = webdriver.Chrome(options=chrome_options)
def start_url():
driver.get("https://www.jianshu.com/sfservice/index.html")
start_url()
print('点击开始验证')
time.sleep(0.5)
while True:
try:
# 定位按钮
element = driver.find_element(By.XPATH, r'/html/body/div/div[1]/div[2]/div/div')
print('检测到滑块!!!')
time.sleep(1.5)
data = driver.page_source
break
except:
print('刷新页面-跳转到滑块页面为止')
start_url()
time.sleep(1.5)
print('开始获取小拼图和背景图!!!')
# 背景图
beijingtu = re.findall('verify-tips.*?<img src="data:image/png;base64,(.*?)"',data)[0]
# 小拼图
xiaopintu = re.findall('verify-sub-block.*?<img src="data:image/png;base64,(.*?)"',data)[0]
# base64 解密
def base64_decode(str):
return base64.b64decode(str)
with open('beijingtu.png','wb') as f:
f.write(base64_decode(beijingtu))
with open('xiaopintu.png','wb') as f:
f.write(base64_decode(xiaopintu))
# 将正常大拼图转换为小拼图, 使用前先去掉多余的透明
def slider_puzzle_qg(
p_puzzle_path: str = '',
save_file: bool = False,
save_file_path: str = ''):
'''
:param p_puzzle_path: 本地长拼图的路径
:param save_file: 是否保存最终修改后的图片 默认False
:param save_file_path: 保存最终修改后的图片名称,不含后缀 默认:自动生成
:return: base64图片
'''
# 打开大拼图图片
image = Image.open(p_puzzle_path)
width, height = image.size
pixels = image.load()
# 采用红绿灯模式 存储和记录信息
# _a:第一层-行数 _b:第二层-行数 _c:第三层-行数 k:记录拼图的像素数据
_a = 0 # 红灯-最顶层 - 透明
_b = 0 # 黄灯-中间层 - 数据核心 - 拼图的像素
_c = 0 # 绿灯-最底层 - 透明
k = [] # 将拼图的像素存储, 存储为一维数组
buffered = io.BytesIO()
for x in range(height):
# 临时的行数据像素 - 左右
data_pixel = []
for y in range(width):
# 读取png像素点 RGBA 值 (png是4通道、jpg是3通道) PNG:RGBA JPG:RGB
r, g, b, a = pixels[y, x]
data_pixel += [(r, g, b, a)]
# 转换为NumPy数组
NumPy_data_pixel = np.array(data_pixel)
# 计算一整行像素值是否为透明, 是透明则跳过并记录在红绿灯内, 如果不是透明则将数据进行存储并记录在红绿灯内
# True:透明(无数据) False:不透明(有数据)
if np.all(NumPy_data_pixel == 0):
if _b == 0:
# 记录最顶层的行数 - 小拼图距离顶部的距离
_a += 1
else:
# 当开始底层为0时,则表示第一次执行此命令,则要存储刚刚所保存的一维像素数组数据, 保存为图片
if _c == 0:
# 创建空白图片 - 宽:拼图的宽度 高:通过数据层获取 颜色:透明 格式:png
new_image = Image.new('RGBA', (width, _b), color=(0, 0, 0, 0))
# 采用一维的像素组数据写入图片
new_image.putdata(k)
# 将数据写入buffered里
new_image.save(buffered, format="PNG")
if save_file:
if save_file_path:
new_image.save(save_file_path + '.png')
else:
# 保存最终图片 随机名称
new_image.save(''.join(str(time.time()).split('.') + [".png"]))
# 记录最底层的行数 - 小拼图距离底部的距离
_c += 1
else:
# 记录拼图的有多少行-高度-上下距离-仅拼图的高度
_b += 1
# 拼图的像素数据 一维
k += data_pixel
# 最后返回字典格式数据
return {
'最顶层-顶层距离': _a,
'中间层-拼图的高度': _b,
'最底层-底层距离': _c,
'base64': base64.b64encode(buffered.getvalue()).decode()
}
# 将滑块背景图切割为小滑道
def background_cutting(
b_puzzle_path: str = '',
b_size_h: int = 0,
p_size_h: int = 0,
save_file: bool = False,
save_file_path: str = ''):
'''
:param b_puzzle_path: 本地滑块背景图的路径
:param b_size_h: 小拼图在背景图中的所在高度,上下距离
:param p_size_h: 小拼图的高度大小
:param save_file: 是否保存最终修改后的图片 默认False
:param save_file_path: 保存最终修改后的图片名称,不含后缀 默认:自动生成
:return: base64图片
'''
# 打开图片
image = Image.open(b_puzzle_path)
width, height = image.size
# 宽度,从左到右的距离
left, right = 0, width
# 高度,从上到下的距离
top, bottom = b_size_h, b_size_h + p_size_h
# 切割图片
cropped_image = image.crop((left, top, right, bottom))
if save_file:
if save_file_path:
cropped_image.save(save_file_path + '.png')
else:
# 保存最终图片 随机名称
cropped_image.save(''.join(str(time.time()).split('.') + [".png"]))
buffered = io.BytesIO()
# 将数据写入buffered里
cropped_image.save(buffered, format="PNG")
return {'base64': base64.b64encode(buffered.getvalue()).decode()}
# 将小拼图多余的透明部分删除并返回其图片信息
xiaopintu_data = slider_puzzle_qg(p_puzzle_path='xiaopintu.png',save_file=True,save_file_path='c1')
print(f'小拼图数据:{xiaopintu_data}')
# 通过小拼图返回的数据 切割背景图的划线通道 方便准确识别
beijingtu_data = background_cutting(b_puzzle_path='beijingtu.png',b_size_h=xiaopintu_data['最顶层-顶层距离'],p_size_h=xiaopintu_data['中间层-拼图的高度'],save_file=True,save_file_path='c2')
print(f'背景图数据:{beijingtu_data}')
# 将base64数据转为二进制数据导入OCR识别 开始识别滑块距离
res1 = det.slide_match(base64_decode(beijingtu_data['base64']), base64_decode(xiaopintu_data['base64']), simple_target=True)['target'][0]
# 略微的误差值才能知道你不是人机
res = res1*400/300-4
print(f'距离为:{res}')
# 点击并抓住标签
ActionChains(driver).click_and_hold(element).perform()
print('开始滑动')
# 开始滑动
ActionChains(driver).move_by_offset(xoffset=res, yoffset=0).perform() # 向右滑动114像素(向左是负数)
# 松开按钮
ActionChains(driver).release().perform()
print('等待执行其他操作!!!')
time.sleep(1000)
# 关闭浏览器
driver.quit()


GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)