
python电影推荐系统 数据分析 大数据毕业设计 可视化大屏 爬虫
(1)技术栈:Python语言、Flask框架、MySQL数据库、requests爬虫、Echarts可视化大屏、推荐算法、HTML、爬虫技术【机器学习】集成学习——Stacking模型融合4个机器学习算法、KNNWithZScore推荐算法(2)功能模块:注册登录模块、电影信息模块、电影信息可视化模块、评论数据可视化模块、电影票房预测模块、电影推荐模块、电影信息管理模块、用户信息管理模块(3)说
1、项目介绍
(1)技术栈:
Python语言、Flask框架、MySQL数据库、requests爬虫、Echarts可视化大屏、推荐算法、HTML、爬虫技术
【机器学习】集成学习——Stacking模型融合4个机器学习算法、KNNWithZScore推荐算法
(2)功能模块:
注册登录模块、电影信息模块、电影信息可视化模块、评论数据可视化模块、电影票房预测模块、电影推荐模块、电影信息管理模块、用户信息管理模块
(3)说明:
1)Python语言、Flask框架、MySQL数据库、requests爬虫、Echarts可视化大屏、
2)票房预测模块:【机器学习】集成学习——Stacking模型融合4个机器学习算法
【决策树模型、Lasso模型、随机森林模型、GDBT(梯度提升树)模型】
3)电影推荐模块:Surprise库中的KNNWithZScore推荐算法
4)用户登录、管理员登录、后台管理登录
5)推荐模块 surprise库 app/home/wals.py KNNWithZScore推荐算法
使用Surprise库中的KNNWithZScore推荐算法对电影评分数据进行训练,并通过交叉验证计算RMSE和MAE指标。
根据不同的K值,绘制出平均RMSE和平均MAE随K值变化的曲线图。
分析训练结果,输出最小的RMSE和对应的K值,以及最小的MAE和对应的K值。
根据最优的K值,构建电影推荐模型,并根据模型得到所有电影的推荐结果。
2、项目界面
(1)电影数据可视化大屏
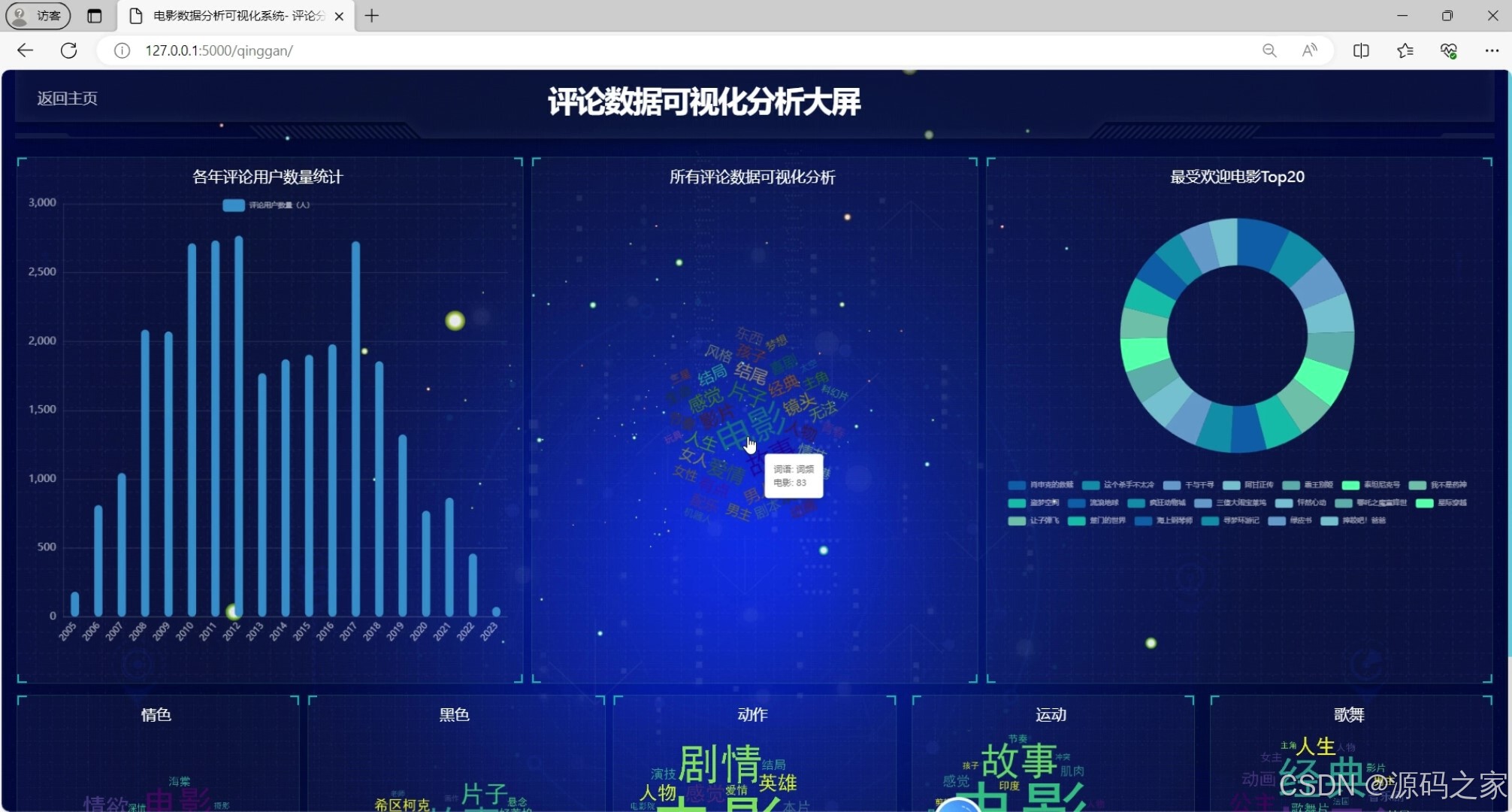
(2)电影评论数据可视化分析大屏
(3)电影数据
(4)电影票房预测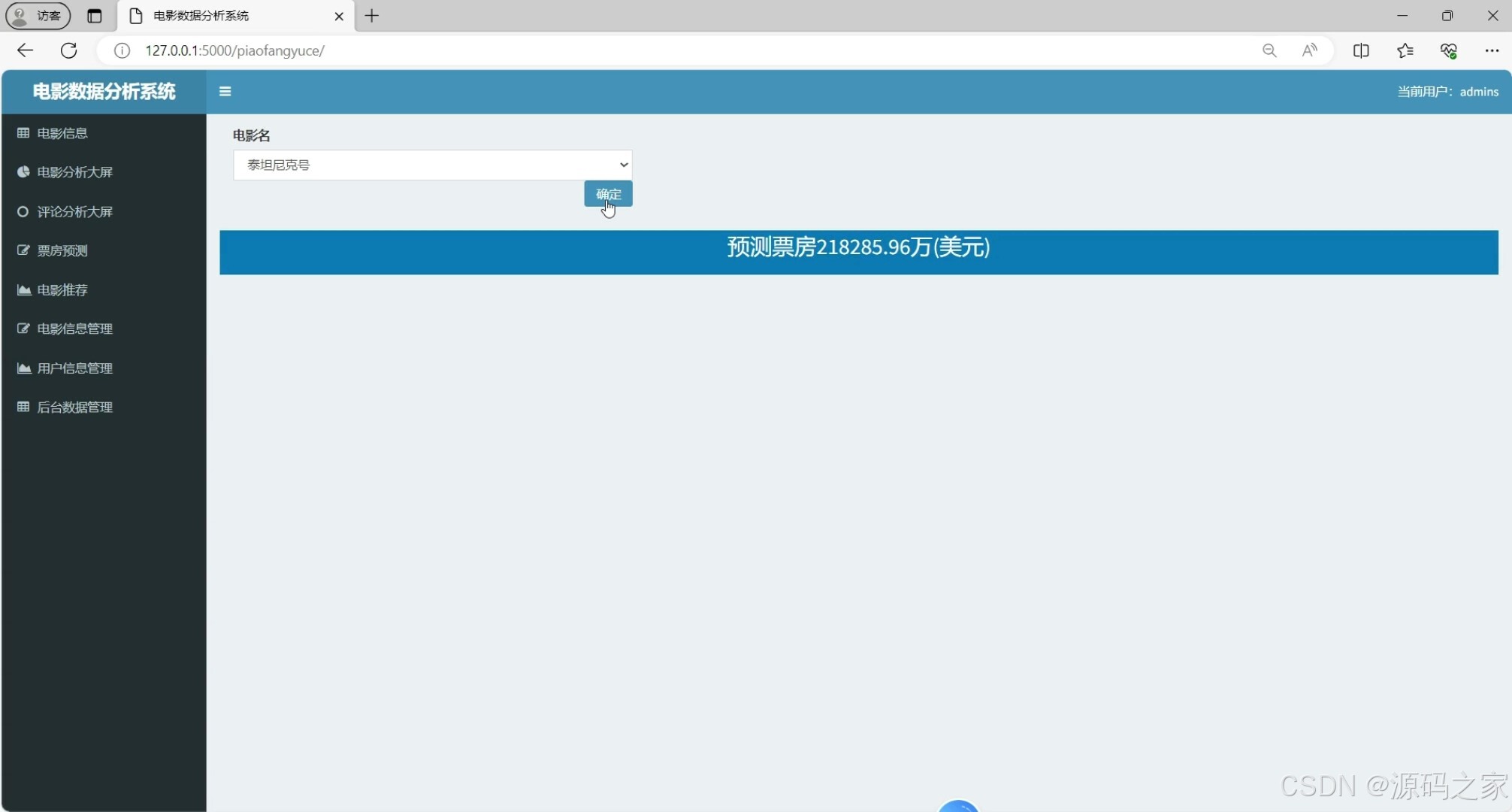
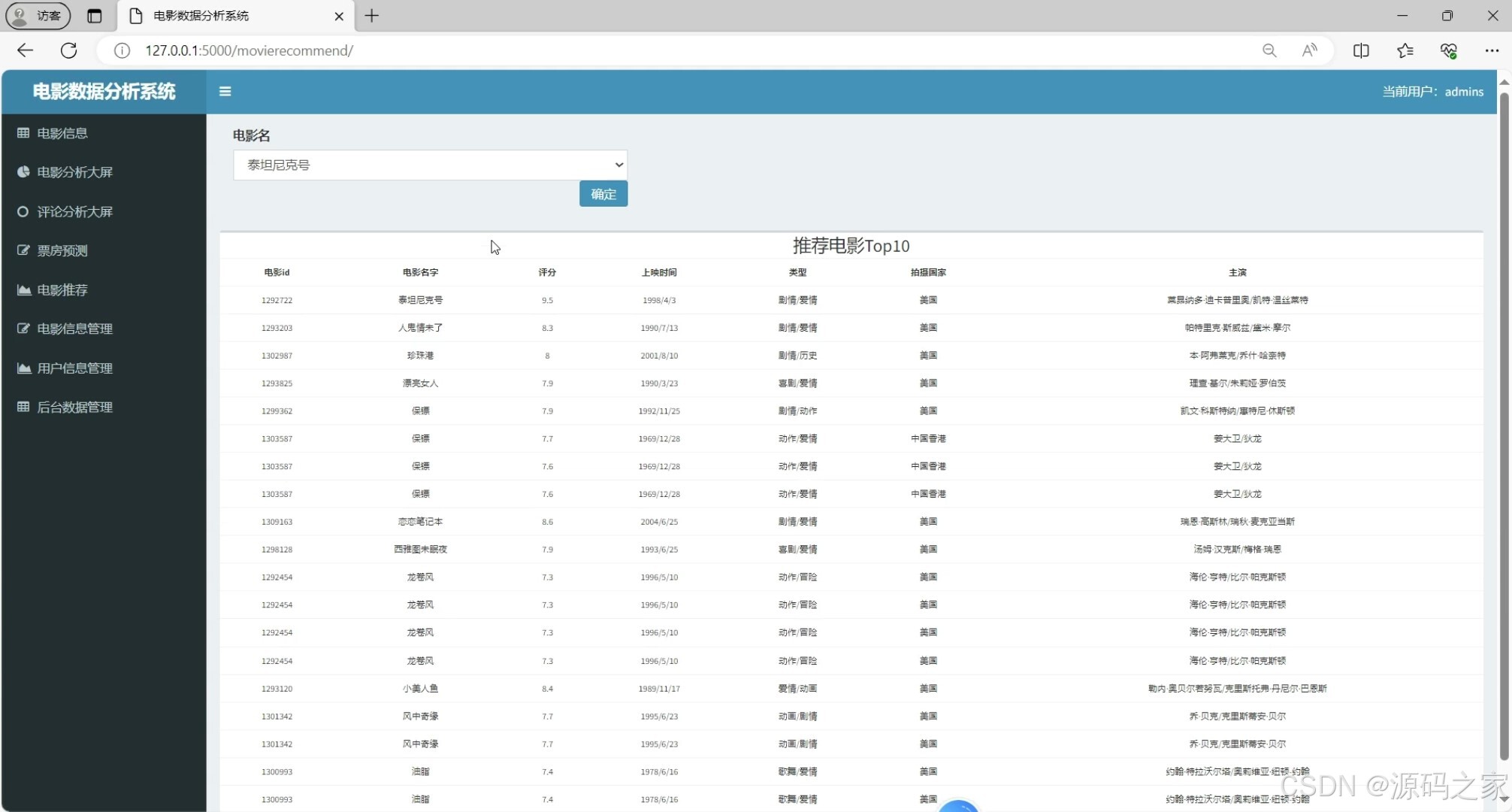
(5)电影推荐
(6)电影数据管理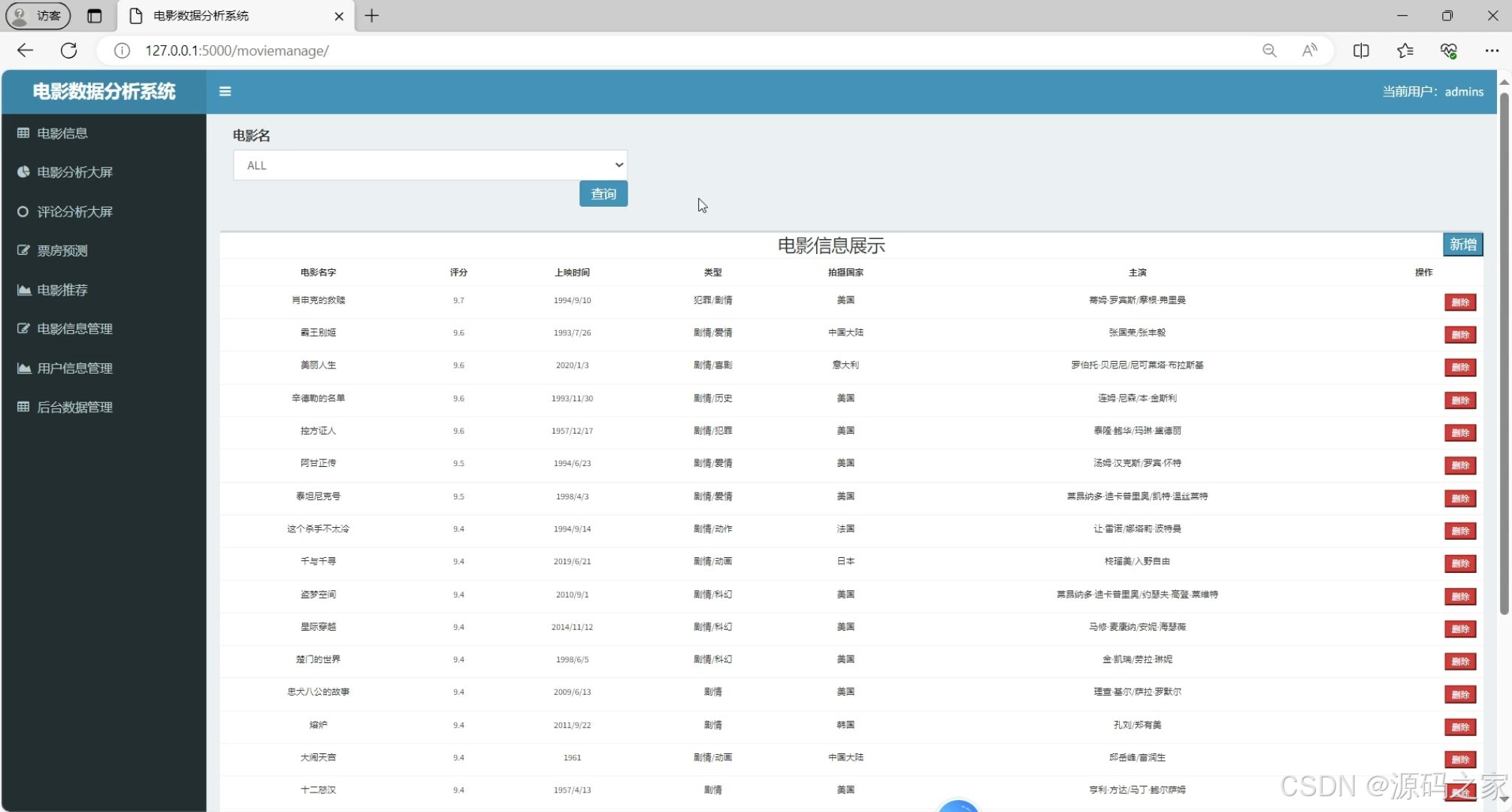
(8)后台数据管理
3、项目说明
在数字化时代背景下,视频内容消费正呈爆炸式增长,带来个性化的观影推荐需求日益突出。本电影推荐系统毕业设计旨在打造能够精准推荐电影内容,提升用户体验的平台,以满足用户的多元化观影偏好。研究基于豆瓣大数据平台,对豆瓣电影栏目中近些年国产电影数据进行统计分析,探讨电影类型、豆瓣评分、短评、影评之间的关系,从消费者角度出发,希望能用大众评价数据反哺电影行业的发展。
系统的开发不仅致力于解决信息过载问题,降低用户选择难度,而且借助先进的推荐算法优化推荐质量,助力电影行业更精准地了解受众需求,从而推动内容创作和营销策略的精细化。技术栈方面,本系统基于Flask轻量级Web应用框架开发,并融合HTML、CSS、JavaScript等前端技术,构建直观友好的用户界面。利用KNNWithZScore推荐算法系统完成了推荐功能模块。通过ECharts图表库实现了丰富的电影分析可视化功能。本电影推荐系统解决了传统推荐机制中存在的泛化推荐不准确和单一推荐方式带来的用户体验局限性问题,系统通过引入KNNWithZScore推荐算法技术,实现了更符合用户个性化需求的定制化推荐服务,为人们提供系统化、个性化、专业化的服务,以提高人们的愉悦感。
关键词:电影推荐;Flask框架;KNNWithZScore推荐算法;ECharts可视化
4、核心代码
```python
import re
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.metrics import make_scorer, mean_squared_error
from sklearn.metrics import r2_score
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.model_selection import KFold
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression as LR, Lasso
import joblib
import seaborn as sns
model_save_path = r'./app/dataset/testModel/'
if not os.path.exists(model_save_path):
os.makedirs(model_save_path)
data = pd.read_csv(r"./app/dataset/ana_result/piaofang_info.csv")
data = data.iloc[:, [2, 3, 4, 5, 7, 9, 10, 11]]
X = data.iloc[:, 0:7]
y = data.iloc[:, 7].apply(lambda x: x / 10000)
# 标签经过 log1p 转换,使其更偏向于正态分布
y = np.log1p(y)
# 数据集划分
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2, random_state=1)
oof_df = pd.DataFrame()
test_oof_df = pd.DataFrame()
def performance_metric(y_true, y_predict):
""" Calculates and returns the performance score between
true and predicted values based on the metric chosen. """
# 计算 'y_true' 与 'y_predict' 的r2值
score = r2_score(y_true, y_predict)
# 返回这一分数
return score
def fit_dtr_model(X, y):
cross_validator = KFold(n_splits=5)
regressor = DecisionTreeRegressor(random_state=1)
# Create a dictionary for the parameter 'max_depth' with a range from 1 to 10
params = {'max_depth': [i for i in range(1, 11)]}
# Transform 'performance_metric' into a scoring function using 'make_scorer'
scoring_fnc = make_scorer(performance_metric)
# Create the grid search cv object --> GridSearchCV()
grid = GridSearchCV(regressor, params, scoring=scoring_fnc, cv=cross_validator)
# Fit the grid search object to the data to compute the optimal model
grid = grid.fit(X, y)
dtr_max_depth = grid.best_estimator_.get_params()['max_depth']
# Return the optimal model after fitting the data
return dtr_max_depth
def fit_decision_tree_model_forcast():
# 进行决策树预测模型的训练
dtr_max_depth = fit_dtr_model(X, y)
dtr_regressor = DecisionTreeRegressor(max_depth=dtr_max_depth)
dtr_regressor.fit(X, y)
pred_y = dtr_regressor.predict(test_X)
test_oof_df['dtr'] = pred_y
r2_score = performance_metric(test_y, pred_y)
rmse_score = np.sqrt(mean_squared_error(pred_y, test_y))
print('决策树回归模型评价指标为:')
print("The R2 score is ", r2_score)
print('均方差', rmse_score)
joblib.dump(dtr_regressor, model_save_path + 'dtr_model.pkl')
return rmse_score
def fit_lasso_model_forcast():
# 进行Lasso预测模型的训练
lasso_regressor = Lasso()
lasso_regressor.fit(X, y)
pred_y = lasso_regressor.predict(test_X)
test_oof_df['lasso'] = pred_y
r2_score = performance_metric(test_y, pred_y)
rmse_score = np.sqrt(mean_squared_error(pred_y, test_y))
print('Lasso回归模型评价指标为:')
print("The R2 score is ", r2_score)
print('均方差', rmse_score)
joblib.dump(lasso_regressor, model_save_path + 'lasso_model.pkl')
return rmse_score
def fit_random_forest_regression_model():
rf_model = RandomForestRegressor()
rf_model.fit(X, y)
pred_y = rf_model.predict(test_X)
test_oof_df['rf'] = pred_y
r2_score = performance_metric(pred_y, test_y)
rmse_score = np.sqrt(mean_squared_error(pred_y, test_y))
print('随机森林模型评价指标为:')
print("The R2 score is ", r2_score)
print('均方差', rmse_score)
joblib.dump(rf_model, model_save_path + 'rf_model.pkl')
return rmse_score
def fit_gdbt_model():
gdbt_model = GradientBoostingRegressor()
gdbt_model.fit(X, y)
pred_y = gdbt_model.predict(test_X)
test_oof_df['gdbt'] = pred_y
r2_score = performance_metric(pred_y, test_y)
rmse_score = np.sqrt(mean_squared_error(pred_y, test_y))
print('GDBT模型评价指标为:')
print("The R2 score is ", r2_score)
print('均方差', rmse_score)
joblib.dump(gdbt_model, model_save_path + 'gdbt_model.pkl')
return rmse_score
def fit_stacking_model():
lr_model = LR()
lr_model.fit(test_oof_df, test_y)
pred_y = lr_model.predict(test_oof_df)
r2_score = performance_metric(pred_y, test_y)
rmse_score = np.sqrt(mean_squared_error(pred_y, test_y))
print('Staking模型评价指标为:')
print("The R2 score is ", r2_score)
print('均方差', rmse_score)
joblib.dump(lr_model, model_save_path + 'stacking_model.pkl')
return rmse_score
def forcast_piaofang(para):
para = pd.DataFrame(para)
# 加载决策树预测模型
dtr_model = joblib.load(model_save_path + 'dtr_model.pkl')
dtr_pred = dtr_model.predict(para)
print("决策树预测票房%s万" % np.expm1(dtr_pred[0]))
# 加载Lasso预测模型
lasso_model = joblib.load(model_save_path + 'lasso_model.pkl')
lasso_pred = lasso_model.predict(para)
print("Lasso预测票房%s万" % np.expm1(lasso_pred[0]))
# # 加载随机森林预测模型
rf_model = joblib.load(model_save_path + 'rf_model.pkl')
rf_pred = rf_model.predict(para)
print("随机森林预测票房%s万" % np.expm1(rf_pred[0]))
# 加载GDBT预测模型
gdbt_model = joblib.load(model_save_path + 'gdbt_model.pkl')
gdbt_pred = gdbt_model.predict(para)
print("GDBT预测票房%s万" % np.expm1(gdbt_pred[0]))
# return [dtr_pred, lr_pred]
return [[dtr_pred[0], lasso_pred[0], rf_pred[0], gdbt_pred[0]]]
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 15
15 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)