
视觉Transformer(ViT ):它凭什么超越CNN,看懂这篇文章你就什么都不缺了!
视觉Transformer(ViT)在计算机视觉领域取得了显著进展,通过自注意力机制建模全局依赖,广泛应用于图像生成和视频理解等任务。然而,早期ViT在密集预测任务如语义分割和实例分割中表现不佳,主要因局部细节建模和多尺度特征能力不足。为此,研究者提出了多种改进方案,包括构建CNN与Transformer的混合架构、引入多尺度融合与双向交互机制,以及优化预训练策略与模型压缩技术。这些改进显著提升了
视觉Transformer(ViT)作为计算机视觉领域的重要突破,成功将Transformer架构引入图像任务,通过自注意力机制建模全局依赖,为图像生成、视频理解等任务带来全新思路。然而,早期ViT在语义分割、实例分割等密集预测任务中表现受限,主要因其局部细节建模和多尺度特征能力不足。
为此,研究者提出多种改进方案:
-
构建CNN与Transformer的混合架构,结合CNN的局部感受野与ViT的全局建模优势;
-
引入多尺度融合与双向交互机制,提升小目标识别与复杂结构解析能力;
-
优化预训练策略与模型压缩技术,如自监督学习、量化部署,增强泛化性与实用性。
当前,ViT已在医疗影像分析、自动驾驶等场景加速落地,成为连接学术与产业的关键桥梁。为助力顶会研究,我整理了12种前沿改进方法 ,并提供完整源码参考 ,助你快速挖掘创新点。
全部论文+开源代码需要的同学看文末!
【论文1:CVPR】ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions
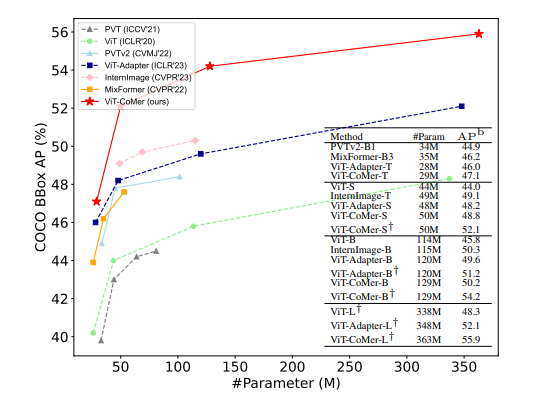
Object detection performance on COCO val2017 using Mask R-CNN.
研究方法
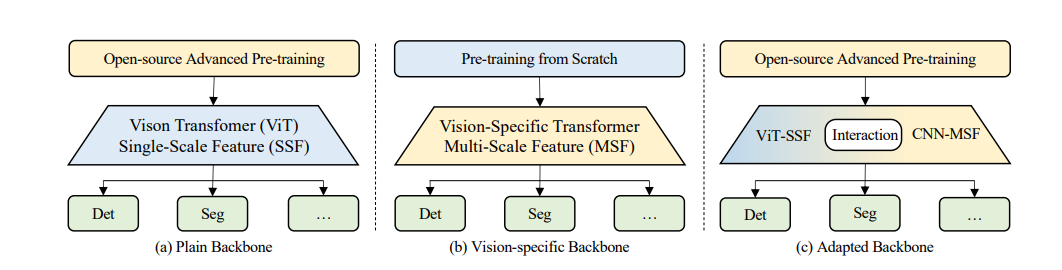
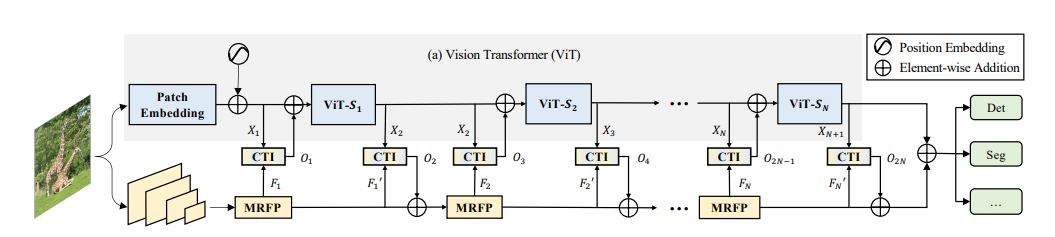
这篇论文围绕视觉 Transformer(ViT)展开研究,提出了 ViT-CoMer 方法,该方法构建双分支架构,其中 ViT 分支直接加载开源预训练权重,CNN 分支通过多感受野特征金字塔模块(MRFP)提取多尺度空间特征,再利用 CNN-Transformer 双向融合交互模块(CTI)实现跨层级特征的多尺度融合,以增强模型的特征表示能力。
创新点
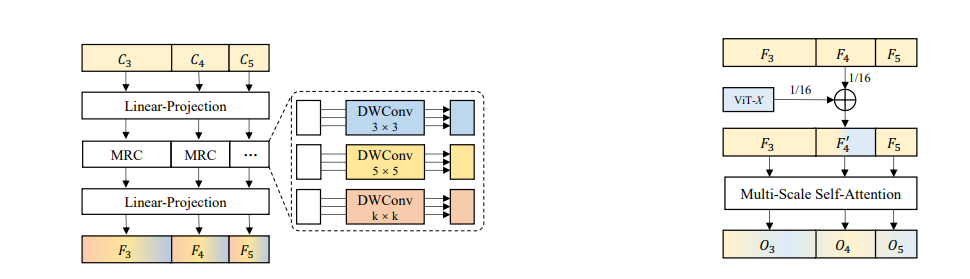
2 important modules
-
提出将空间金字塔多感受野卷积特征注入ViT架构,有效缓解ViT局部信息交互有限和特征表示单一的问题。
-
设计简单高效的CNN-Transformer双向融合交互模块,实现跨层级特征的多尺度融合,利于处理密集预测任务。
-
构建无需额外预训练的ViT backbone,可直接加载各类开源预训练权重,结合多尺度卷积特征交互模块提升密集预测性能。
论文链接:https://openaccess.thecvf.com/content/CVPR2024/papers/Xia_ViT-CoMer_Vision_Transformer_with_Convolutional_Multi-scale_Feature_Interaction_for_Dense_CVPR_2024_paper.pdf
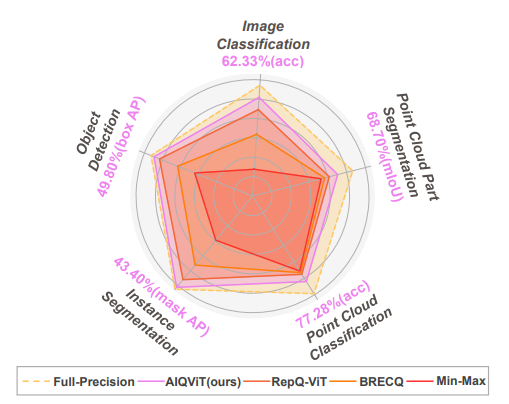
The performances of different approaches on different tasks
【论文2:AAAI2025】AIQViT: Architecture-Informed Post-Training Quantization for Vision Transformers
研究方法
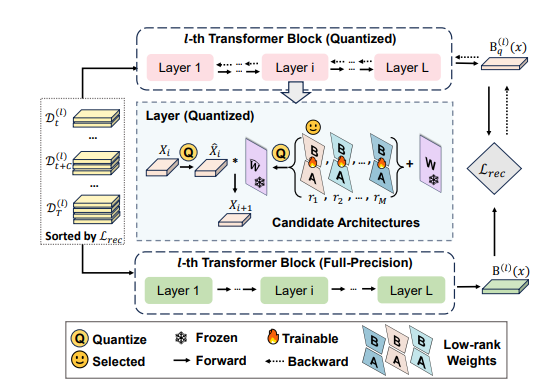
Overview of architecture-informed low-rank compensation
在研究视觉 Transformer(ViT)时,文中提出了一种基于多尺度特征融合的方法。该方法先通过卷积神经网络(CNN)提取图像不同尺度的局部特征,这些特征包含丰富的细节信息;同时利用 ViT 获取图像的全局特征,捕捉长距离依赖关系。最后,将两者提取到的特征进行有效融合,使模型兼具局部细节感知和全局理解能力,从而提升对复杂视觉任务的处理效果。
创新点
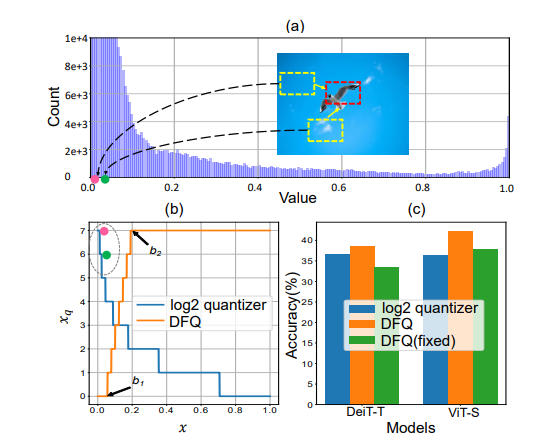
(a) Histogram of the first MHSA module’s postSoftmax activations in DeiT-T. (b) log2 quantizer (in blue) and DFQ (in orange). (c) Results on ImageNet with W3/A3 quantization. “DFQ(fixed)” means all the layers use the same interval. Best viewed in color
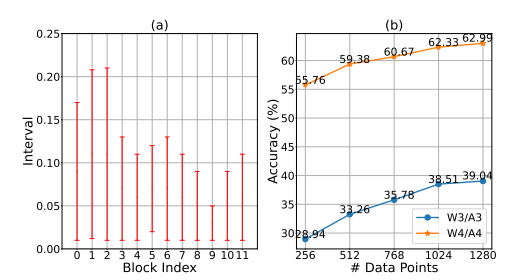
Visualization of the learned intervals and the influences of calibration data size
-
引入动态注意力机制,突破传统ViT固定注意力模式,使模型能更精准聚焦图像关键区域。
-
构建层次化特征聚合结构,弥补ViT在特征尺度处理上的不足,增强模型对多尺度视觉信息的理解。
-
设计轻量化的ViT改进架构,在保持性能的同时减少计算量,提升模型在实际应用中的部署效率。
论文链接:https://arxiv.org/pdf/2502.04628
关注下方《AI前沿速递》🚀🚀🚀
回复“C308”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 6
6 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)