
[VL|RIS]Towards Complex-query Referring Image Segmentation: A Novel Benchmark
鉴于大预训练模型语义理解能力提升,有必要在 RIS 中纳入复杂语言查询。作者基于 RefCOCO 和 Visual Genome 数据集构建新基准数据集 RIS - CQ ,该数据集高质量、大规模,用丰富信息查询挑战现有 RIS,推动 RIS 研究。还提出双模态图对齐模型 DUCOGA 用于 RIS - CQ 任务。
1. BaseInfo
| Title | Towards Complex-query Referring Image Segmentation: A Novel Benchmark |
| Adress | https://arxiv.org/pdf/2309.17205 |
| Journal/Time | ACM Transactions on Multimedia Computing, Communications and Applications (TOMM) |
| Author | 新加坡国立大学 |
| Code | https://github.com/lili0415/DuMoGa |
这刊没听过,搜了一下发现是中科院3区的,SCI 的 JCR 分区是 1 区。
2. Creative Q&A
提出问题:
目前的 RefCOCO 和 RefCOCO+ 85.3% 长度≤5 个单词 ,83.8% 查询仅涉及一两个视觉对象。用复杂表达测试 miou 会下降。
解决问题
主要是针对复杂语言查询的。
基于 RefCOCO 和 Visual Genome 数据集构建新基准数据集 RIS - CQ。利用大语言模型(如 ChatGPT )生成复杂查询,标注质量高,最终得到含 118,287 张图像,平均每个查询 13.18 词的 RIS-CQ 数据集。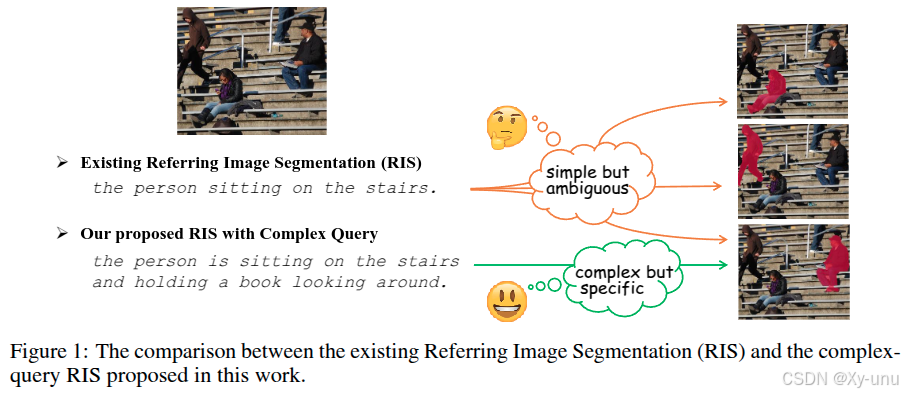
双模态图对齐模型 dual-modality graph alignment model (DUMOGA)
3. Concrete
对数据集的构建写了一章。也有些对数据集的分析。
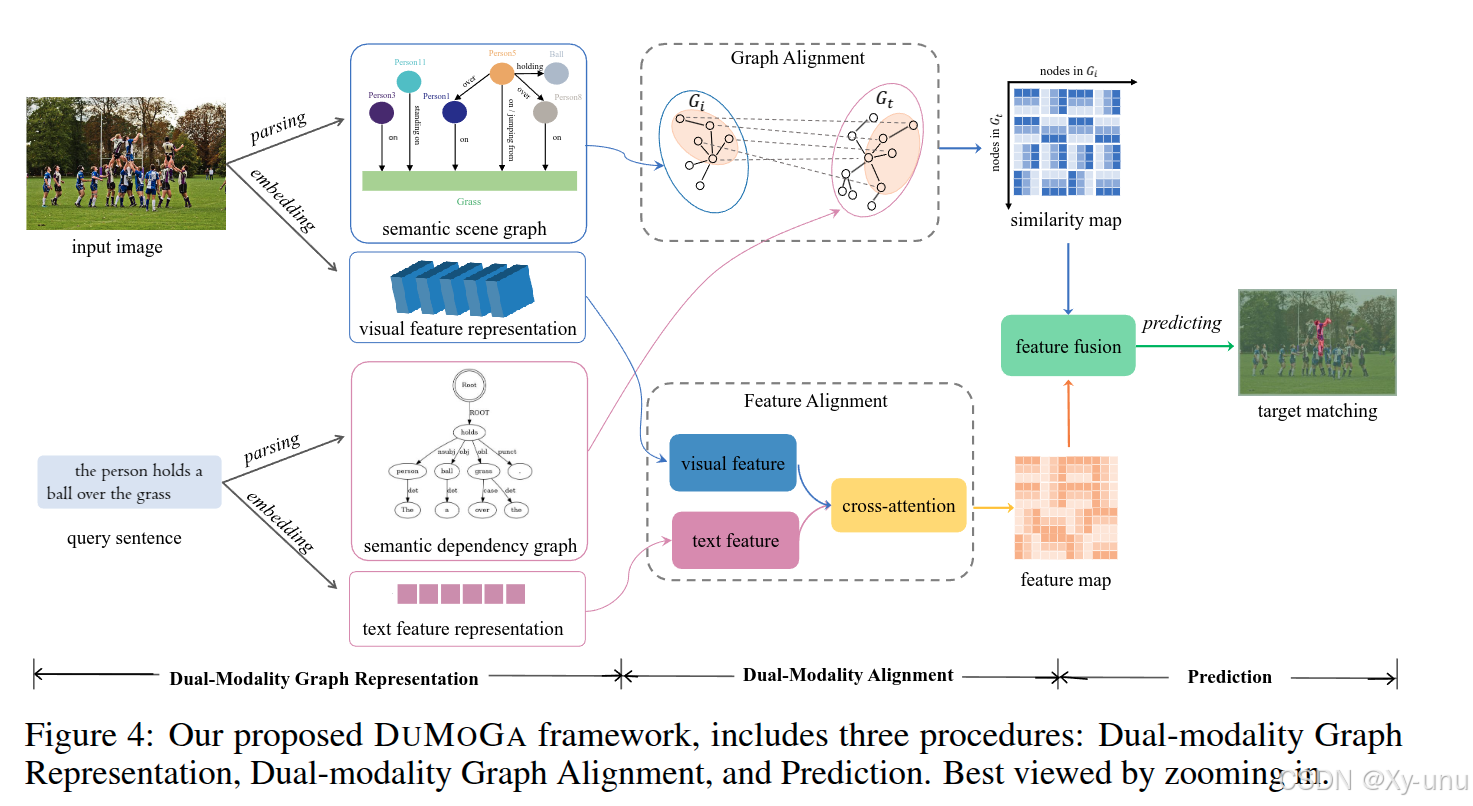
3.1. Model
模型图里对图像和句子经过经解析(parsing)构建语义场景图(semantic scene graph)物体及其关系,和语义关系图(semantic dependency graph)文本语义结构。
Semantic Scene Graph Generation for Vision. 通过经典的 SGG
参考 Panoptic scene graph generation with semantics-prototype learning 论文
图像可分割为一组掩码S,每个掩码关联一个对象类别标签O,并预测出一组关系R。由此构建场景图节点集(包含检测到的对象 )和边集E_i(表示对象间关系),G_i 场景图表示。
文本
参考论文 : Deep contextualized word representations. 使用 ELMo 探索单词间依存关系。树节点和边集。
图文对齐用的简单的交叉注意力+MLP,提取视觉特征也是用 ResNet-50, 语言用 VCTree
CE loss
3.2. Training
单张图像最多检测 10 个对象,每个检测对象特征维度为 1024
BETR 选维度 768 的
ase learning rate at 2e-5 and the batch size at 64.
Adamw optimizer,
3.2.1. Resource
3.2.2 Dataset
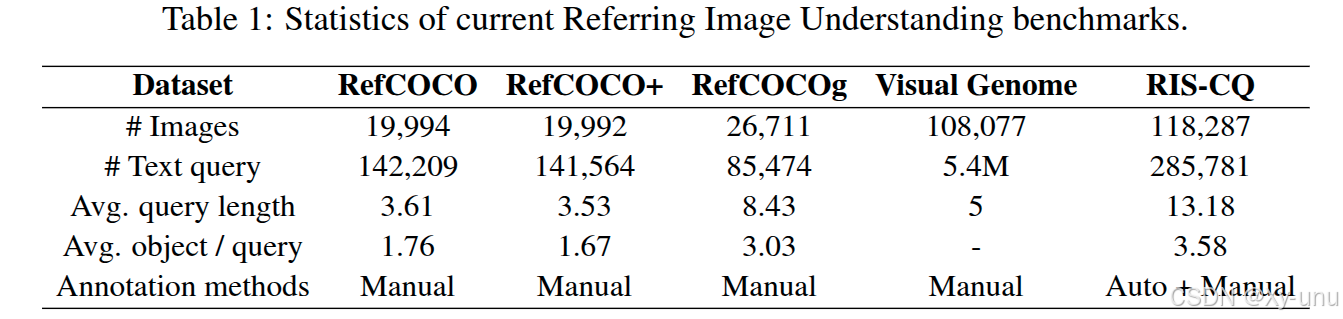
3.3. Eval
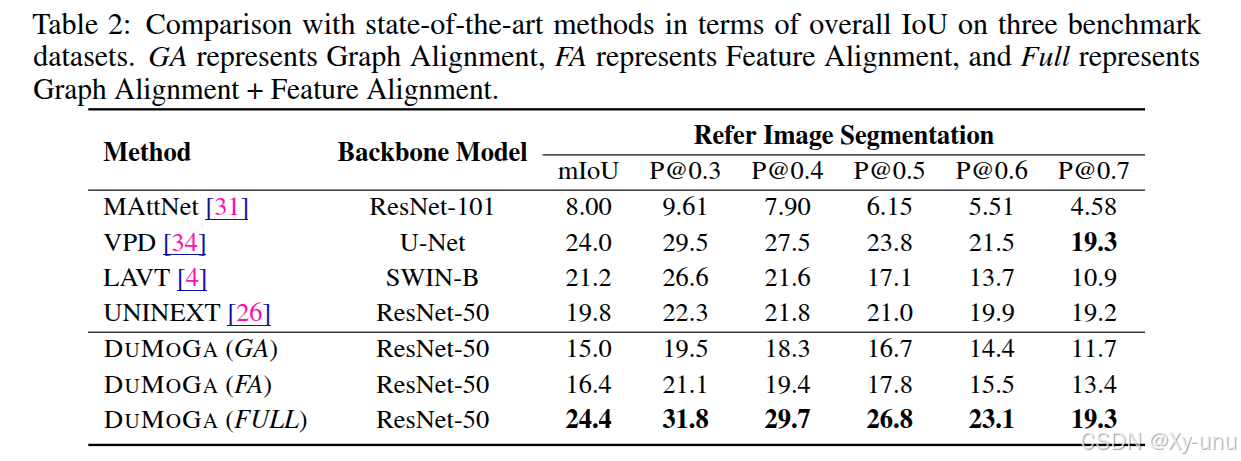
分数也是挺低的
3.4. Ablation
复杂查询的必要性,感觉也是没解释清楚。个人觉得日常用到复杂查询的时候不多,且在文本编码时一般 token 也就不超过 20 ,感觉很少很详细的描述一个物体。
4. Reference
有附录。
5. Additional

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)