
(2025|NVIDIA,监督微调,强化学习,LLaVA,Mamba)Cosmos-Reason1: 从物理常识到具身推理的探索
本文提出了 Cosmos-Reason1 系列多模态大语言模型,专注于提升物理人工智能系统在物理常识与具身推理方面的能力。模型能够通过对视频等视觉输入的理解,结合长链式思维过程,在自然语言中做出符合物理逻辑的推理与决策。
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
目录
3.2 混合 Mamba-MLP-Transformer 主干架构
1. 引言
本文提出了 Cosmos-Reason1 系列多模态大语言模型,专注于提升 物理人工智能(Physical AI)系统在 物理常识(Physical Common Sense)与具身推理(Embodied Reasoning)方面的能力。模型能够通过对视频等视觉输入的理解,结合长链式思维(Chain-of-Thought, CoT)过程,在自然语言中做出符合物理逻辑的推理与决策。
为实现上述目标,作者提出了两个核心本体论(ontology):
-
物理常识本体论:从空间、时间和基本物理三大类别出发,细分为 16 个子类别,系统描述了与物理世界相关的基本规律与直觉性知识。
-
具身推理本体论:定义了适用于五类具身智能体(embodied agents,例如人类、机械臂、类人机器人、自动驾驶等)的四种推理能力(如感知处理、行动预测、物理约束等)。
在模型构建方面,Cosmos-Reason1 包括两个规模的版本:
-
Cosmos-Reason1-8B(约 8B 参数)
-
Cosmos-Reason1-56B(约 56B 参数)
其训练共分四个阶段:
-
视觉预训练:通过图像与视频数据将视觉输入对齐至语言token空间;
-
通用监督微调(SFT):构建通用视觉语言理解能力;
-
物理 AI 监督微调:使用专门数据增强物理常识与具身推理;
-
物理 AI 强化学习(RL):基于规则设计奖励函数,进一步提升模型在推理准确性上的表现。
作者还构建了多个涵盖物理常识和具身推理任务的评测基准(benchmark),并在多个维度上将 Cosmos-Reason1 与其他主流模型(如 GPT-4o、Gemini 2.0、Qwen 等)进行对比。结果显示,该模型在多个物理推理任务上均表现优越,尤其是在时间顺序、因果关系、物体永恒性等方面。

1.1 关键词
物理常识(Physical Common Sense)、具身推理(Embodied Reasoning)、多模态大模型(Multimodal LLM)、直觉物理(Intuitive Physics)
2. Physical AI 推理
本节定义了构建具备真实世界推理能力的物理 AI 模型所需的两项关键能力:物理常识推理(Physical Common Sense Reasoning)与具身推理(Embodied Reasoning)。
此外,作者也引入了 “系统 1 / 系统 2 ”的认知模型,以模拟人类快速直觉与深度理性推理过程。
本节奠定了 Cosmos-Reason1 模型能力的理论基础:以 本体论体系定义能力边界与目标,从而指导后续数据构建、模型训练与评估指标设计。
2.1 物理常识推理
人类通过观察世界,能自然形成直觉性的物理常识,比如重力、物体恒常性(Object Permanence)、因果性等。类似地,作者指出,AI 系统若能具备这类通用、与身体无关的物理知识,可在未直接交互的情况下进行有效预测与推理。
为此,作者构建了一个物理常识本体论,分为 3 大类、16 个子类,如下所示:
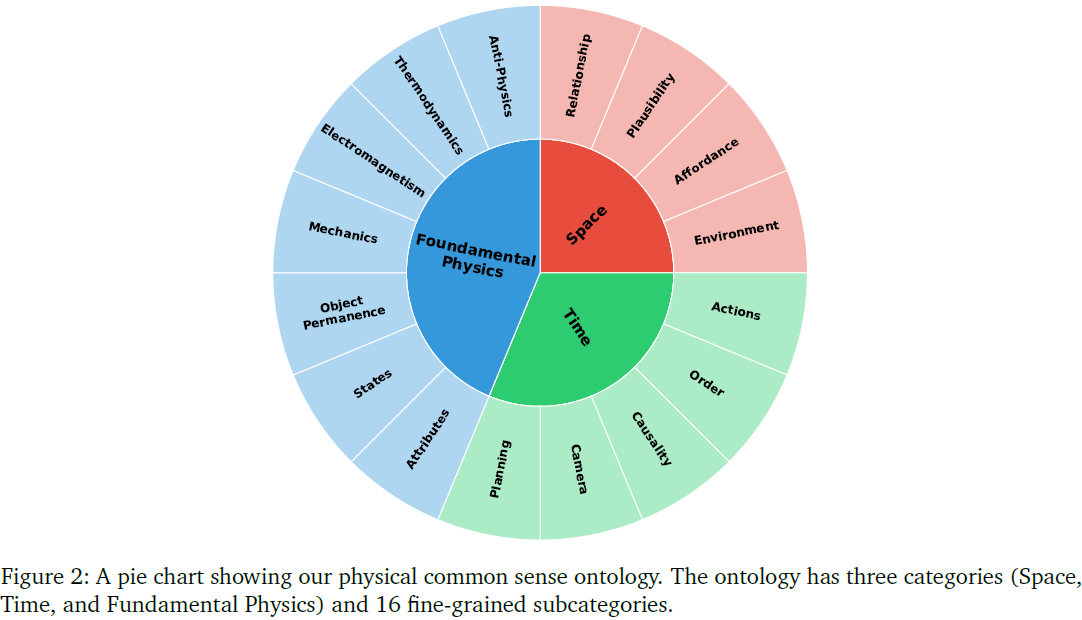
1)空间(Space)
- 空间关系(Relationship):如“左侧”、“上方”,需考虑视角。
- 可行性(Plausibility):判断空间关系是否合理。
- 可供性(Affordance):判断人/机器人对物体的交互能力。
- 环境理解(Environment):理解整体场景或环境。
2)时间(Time)
- 动作(Actions):动作类型、强度、目标等。
- 顺序(Order):事件发生顺序。
- 因果性(Causality):是否存在因果关系。
- 摄像机(Camera):摄像机位置、运动与视角变换。
- 计划(Planning):基于观察做出合理未来计划。
3)基本物理(Fundamental Physics)
- 属性(Attributes):如颜色、质量、材质等。
- 状态(States):状态及变化,如冰变水。
- 物体永恒性(Object Permanence):隐藏或遮挡后是否还存在。
- 力学(Mechanics):静力学、运动学与动力学。
- 电磁学(Electromagnetism):包括光学、电与磁相关知识。
- 热力学(Thermodynamics):温度、热传导、蒸发等。
- 反物理(Anti-Physics):判断违反物理定律的情形,如时间倒流。
2.2 具身推理
具身推理(Embodied Reasoning)强调与物理世界交互中做出合理决策的能力,区别于数学或编程中的抽象符号处理。作者将其细化为以下四项能力:
1)处理复杂感官输入
- 模型需从不完整、模糊的原始感知(如视频帧)中提取有意义的模式。
- 例如:自动驾驶识别前方障碍物,或机器人识别抓取物体。
2)预测行动后果:行为具备物理后果,AI需直觉理解因果关系(如机器人移动对周围物体的影响)。
3)遵守物理约束:包括摩擦力、惯性、材质限制等,AI需考虑物理可行性进行长远计划。
4)从交互中学习:如:通过动作反馈不断修正策略。(本文暂未实现,留作未来研究)
| 能力 | 人类/动物示例 | 机器人/系统示例 |
|---|---|---|
| 处理感知输入 | 人类看烹饪视频;蝙蝠用回声定位 | 机器人识别物体;自动车识别交通标志 |
| 预测行为后果 | 木匠预测木材劈裂;狗接球 | 机械臂预判惯性;自动车预判打滑 |
| 遵守物理约束 | 飞行员控制升力;猎豹控制肌肉负荷 | 机械臂限力防碎;无人机避风 |
3. Cosmos-Reason1 模型设计
本节介绍 Cosmos-Reason1 模型的架构设计,强调其专为物理推理任务构建的多模态系统,结合了视觉编码器、投影器与语言模型主干。整体架构旨在实现输入视频与文本的融合理解,并生成包含长链式思维过程的自然语言输出。
3.1 多模态架构
(2023|NIPS,LLaVA,指令遵循,预训练和指令微调,Vicuna,ViT-L/14,LLaVABench)视觉指令微调
(2024|CVPR,LLaVA-1.5,LLaVA-1.5-HD,CLIP-ViT-L-336px,MLP 投影,高分辨率输入,组合能力,模型幻觉)通过视觉指令微调改进基线
(2024,LLaVA-NeXT(LLaVA-1.6),动态高分辨率,数据混合,主干扩展)
Cosmos-Reason1采用 decoder-only 结构,与 LLaVA 架构类似,具备处理图像与视频输入能力。
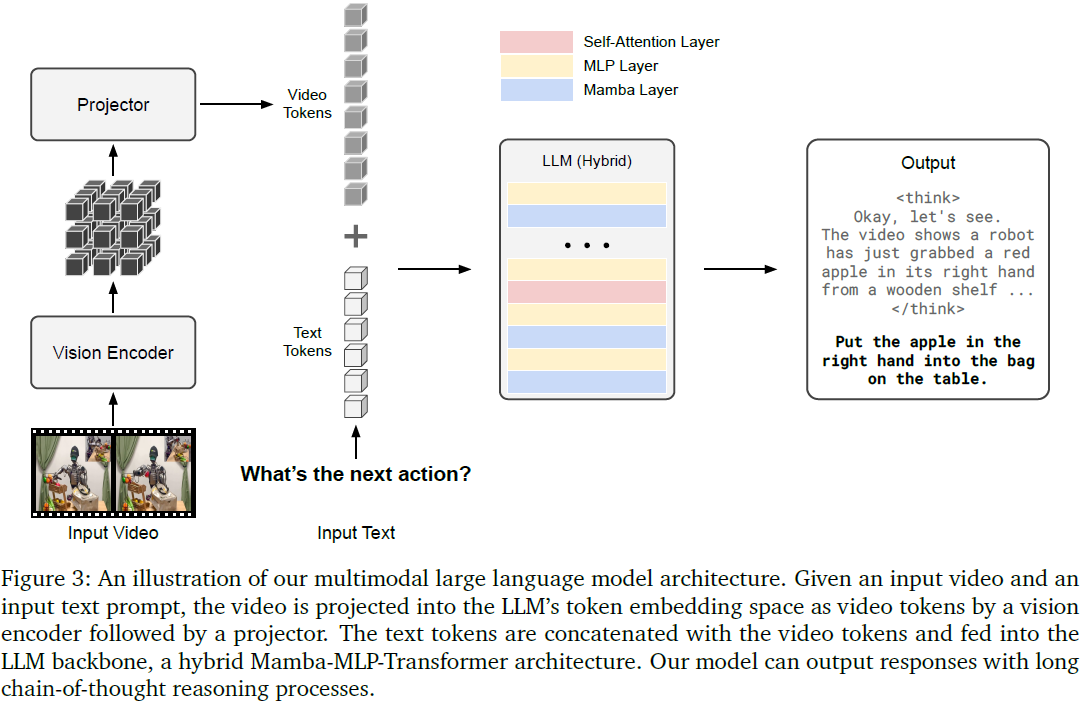
视觉编码器(Vision Encoder)
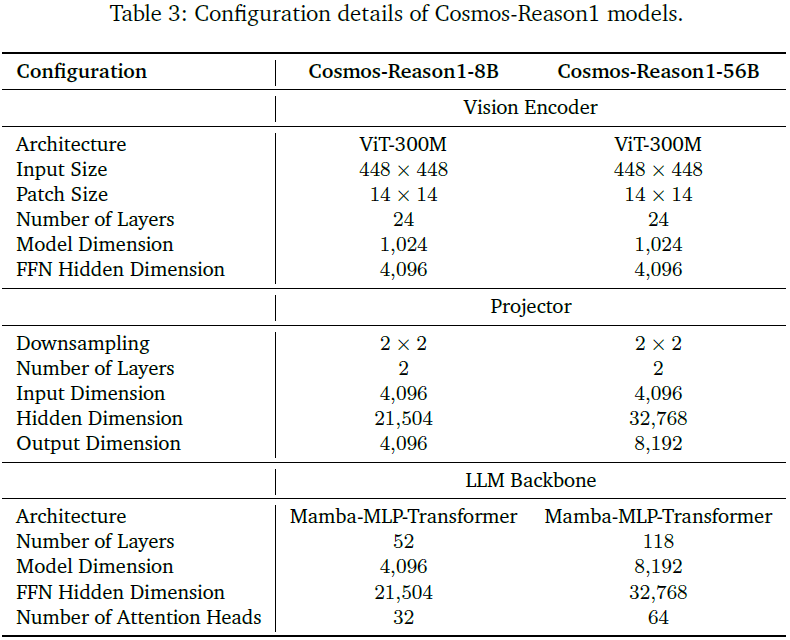
- 采用 InternViT-300M-V2.5(ViT 架构)提取视觉特征。
- 图像预处理:输入图像被分割成 1~12 块(tile),每块为 448×448 分辨率,并生成缩略图保留全局信息。
- 视频处理:从视频中均匀采样最多 32 帧(最大 2fps),每帧大小为 448×448 像素。
投影器(Projector)
- 使用两层 MLP 进行特征下采样与映射
- 输入维度:4096
- 输出维度:8B 模型为 4096,56B 模型为 8192
- 降采样方式:使用 PixelShuffle 将 1024 个视觉 token 降至 256 个token
语言模型主干(LLM Backbone)
- 将视觉 token 与文本 token 拼接后输入主干模型,输出含长链式思维的自然语言响应。
- 主干采用混合架构,详见 3.2 节。
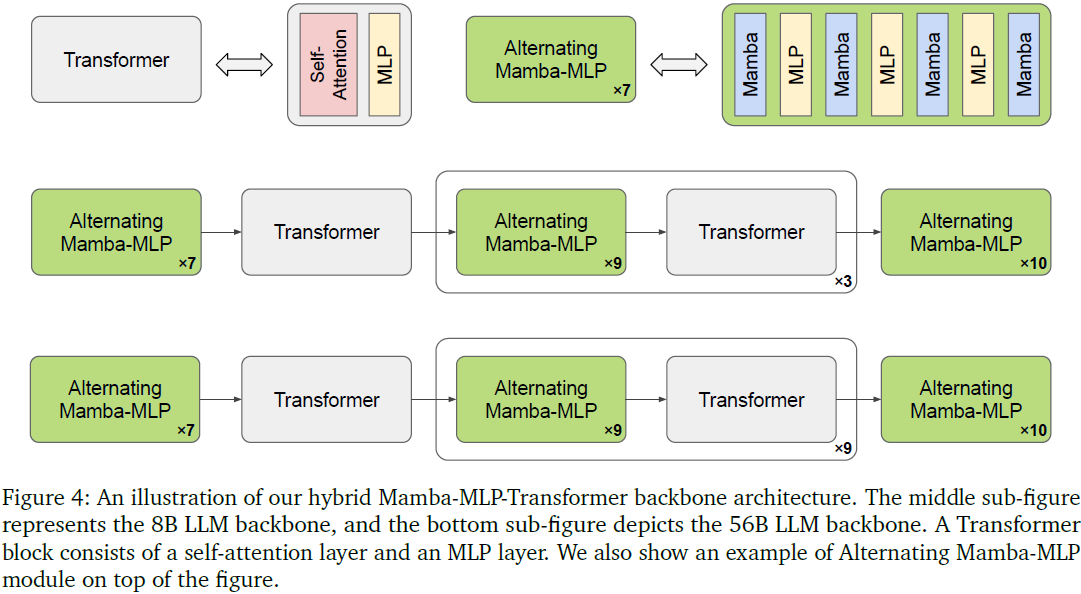
3.2 混合 Mamba-MLP-Transformer 主干架构
(2023,SSM,门控 MLP,选择性输入,上下文压缩)Mamba:具有选择性状态空间的线性时间序列建模
(2024|ICML,Mamba2,SSD,SSM,SMA,矩阵变换,张量收缩,张量并行)Transformer 是 SSM
(2024,Attention-Mamba,MoE 替换 MLP)Jamba:混合 Transformer-Mamba 语言模型
(2024,Jamba1.5,ExpertsInt8量化,LLM,激活损失)大规模混合 Transformer-Mamba 模型
主干采用混合架构,该结构融合了 Transformer 与 Mamba 的优势,提升了对长序列的处理能力和计算效率。
背景与动机:
- Transformer 结构虽然强大,但其自注意力机制的时间复杂度为 𝑂(𝑛²),在长文本或视频处理中存在性能瓶颈。
- Mamba 架构则引入选择性状态空间模型(selective state-space models),具备线性复杂度,适合长序列建模。
4. 数据构建与训练阶段
本节详细介绍 Cosmos-Reason1 的训练流程与数据来源,强调其为物理 AI 任务量身定制的四阶段训练策略:
- 视觉预训练(Vision Pre-Training)
- 通用监督微调(General Supervised Fine-Tuning)
- 物理 AI 监督微调(Physical AI Supervised Fine-Tuning)
- 物理AI 强化学习(Physical AI Reinforcement Learning)
每一阶段均有专属的数据策划流程,确保模型具备从感知到推理的完整能力。
4.1 视觉预训练
目标:将图像与视频视觉 token 映射到语言 token 嵌入空间,实现多模态统一表示。
方法:
- 冻结视觉编码器与 LLM 主干,仅训练两层 MLP 投影器。
- 使用 130M 样本(人类注释 + 模型生成标题 caption),任务包括图像标题生成与视觉问答(VQA)。
4.2 通用监督微调
目标:建立基础的视觉-语言联合理解能力。
方法:
- 开始训练视觉编码器、投影器与语言模型主干。
- 使用 8M 样本:6M 图文对(静态图像+文本),2M 视文对(视频+文本)
数据来源涵盖多任务、多领域,如视频描述、QA、多选题、推理等,目标为打造全面、多样化的感知-理解能力。
4.3 物理 AI 监督微调
这是 Cosmos-Reason1 构建的核心能力阶段,涵盖两个子任务:
- 物理常识推理
- 具身推理
为此,作者提出了严格的数据策划流程,并引入 “理解” 与 “推理” 双重注释:
- 理解:包括状态-动作描述或结构化视频标题(caption)。
- 推理:包括问题、长链式思维轨迹、最终答案。

4.3.1 物理常识数据构建流程
数据构建流程:
- 视频筛选:由人类偏好选取高质量视频,截取片段。
- 详细标题生成:由人工或 VLM 生成视频结构化描述。
- 问题构建:LLM 基于标题生成理解类(可由描述直接回答)与推理类(需要常识或推理)问题。
- 思维轨迹提取:调用 DeepSeek-R1 模型回答推理问题,解析为 “思考过程 + 答案” 格式。
- 清洗与重写:移除多余信息、优化语言表达,生成标准训练样本。
示例:
- 自由形式(Free-form):视频片段 + 标题 → 提问“这个物体可能会去哪?” → DeepSeek-R1生成完整CoT。
- 多选(Multiple-choice,MC):采样高质量视频 1.2M 段,自动构造 2.4M 理解类与 0.6M 推理类 MCQ。
4.3.2 具身推理数据构建流程
目标任务(三类):
- 任务完成验证(task-completion verification)
- 动作可行性评估(action affordance)
- 下一步子任务预测(next plausible subtask prediction)
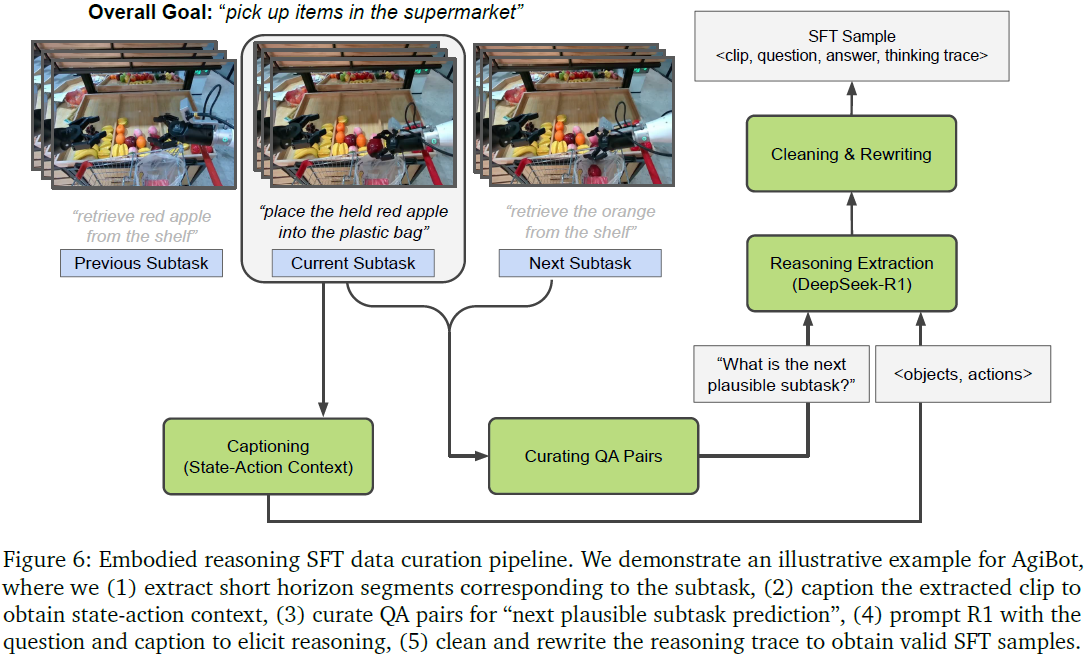
构建流程:
- 视频分割为短时段动作片段
- 用 VLM 生成结构化标题(state-action context)
- 基于动作标签与标题生成 QA 对
- 使用 DeepSeek-R1 生成推理轨迹
- 清洗与重写生成标准样本
数据来源:
- BridgeData V2:物体操作(移动、堆叠等)
- RoboVQA:六类问答任务(规划、验证、预测等)
- AgiBot:家庭任务序列(如“从冰箱拿出红椒 → 放入塑料袋”)
- HoloAssist:第一人称操作,包含错误与修复动作
- AV(自动驾驶):真实交通环境,带有人工标注的三类caption(场景、难度、提示)
4.3.3 直觉物理数据
为提升基础物理能力,作者引入三种高度结构化、接近自监督的数据子集:
空间拼图(Puzzle)
- 将图像打乱为 2×2 块,预测原始相对位置
- 构建身份识别题,引入干扰项
- 总样本:11K
时间箭头(Arrow of Time, AoT)
- 视频正/逆播放
- 判断是否违反时间单向性(如 “破碎变完整”)
- 总样本:30K
物体永恒性(Object Permanence)
- 使用 Libero 模拟器生成视频,包含遮挡与物体消失
- 提示模型观察异常情况
- 样本量:10K,推理轨迹由中间版本的 Cosmos-Reason1-8B 生成
4.4 物理 AI 强化学习
目标:在已有能力基础上,进一步精炼物理推理表现。
奖励构建:
- 准确性奖励:答案正确得分,基于 MCQ 格式实现可验证性。
- 格式奖励:要求模型输出与格式。
数据改写:将推理监督微调样本转换为选择题,特别是物理常识、具身推理与直觉物理三类。
训练框架:
- 自建基于Ray的分布式 RL 框架
- 采用 GRPO 算法:无需 critic,按样本分组归一化奖励,简洁高效
参数配置:
- 每轮采样 128 个问题,每个问题生成 9 个回答
- 学习率:4e-6,KL 损失惩罚:0.005,训练 500 轮

5. 基准测试
为了全面评估 Cosmos-Reason1 模型在物理 AI 任务中的表现,作者设计并构建了两个专门基准:
- 物理常识推理基准(Physical Common Sense Reasoning)
- 具身推理基准(Embodied Reasoning)
这些基准围绕模型本体论中定义的能力展开,采用 基于视频的多项选择题(MCQ)与二选一(Yes/No)格式,确保回答需要真实的物理理解与多步推理,而不仅是文本匹配或检索。

5.1 物理常识推理基准
构建流程:
- 起始问题库:5737 个问题(2828 个二选一,2909 个多选题)
- 按照第二节定义的本体论分类(图 7),覆盖 16 个子类别
- 从中精选 604 题组成正式评估集
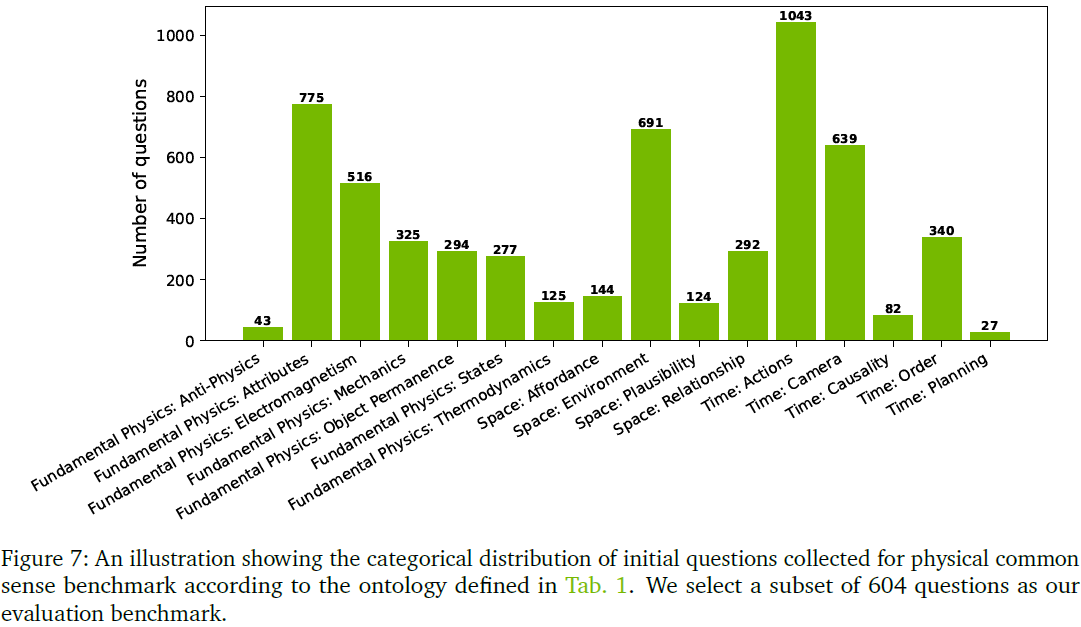
问题类型分布:
- 空间类(Space):80 题(13.25%)
- 时间类(Time):298 题(49.33%)
- 基本物理类(Fundamental Physics):226 题(37.42%)
设计原则:
- 所有问题均基于视频片段生成
- 强制要求推理过程,避免凭直觉判断
- 仅评估最终答案是否正确,暂不评估思维链质量
5.2 具身推理基准
此基准主要评估模型是否具备以下三类关键能力:
- 任务完成验证(Task-completion verification)
- 动作可行性评估(Action affordance)
- 下一步子任务预测(Next plausible action prediction)
问题格式:全部为多选题(MCQ),基于视觉上下文设计。
设计原则:
- 统一问题模板:所有问题使用一致格式,避免被语言模式提示干扰
- 统一动作粒度:通过预定义的 “动作-子任务-目标” 三层级避免歧义
- 人工精调选项:确保干扰项具备 “视觉可判别性” 与 “逻辑错位”,增加挑战性
子集说明:
1)BridgeData V2
- 来源于val集
- 每题提供机器人目标任务与视频,询问下一步最合理动作
- 问题数:100
2)RoboVQA
- 从val集中采样101段视频
- 聚焦任务完成验证与动作可行性
- 转换为二选一形式的问题
3)RoboFail
- 手工精选100例,强调失败/异常动作处理
- 更关注复杂的物理约束与细节识别(如误抓、场景遮挡)
4)AgiBot
- 从测试集采样100个视频片段
- 每题提供任务背景,要求选择最可能的下一子任务
5)HoloAssist
- 从 34 个排除训练集的视频中选出 100 段
- 提供当前粗粒度目标与动作,预测下一步操作
6)AV(自动驾驶):精选100段视频,问题涉及:
- 下一动作预测
- 行为验证
- 某动作是否可行
- 所有问题基于人工高质量 caption 设计,确保评估有效性
6. 实验
本节详细评估 Cosmos-Reason1 在三个关键维度的表现:
- 物理常识推理
- 具身推理
- 直觉物理推理
作者不仅对比了多个主流多模态大模型(如 GPT-4o、Gemini 2.0、Qwen2.5 等)在这些任务上的准确率,还评估了 Cosmos-Reason1 在监督微调(SFT)与强化学习(RL)阶段的增益效果,并展示了用于训练的 RL 基础设施与策略。
6.1 物理 AI 监督微调实验结果
| 模型 | 学习率 | 训练轮数 | 优化器 | 批量大小 |
|---|---|---|---|---|
| 8B | 1e-5 → 1e-6(分两阶段) | 共 80 K | Fused Adam (β1=0.9, β2=0.95) | 32 |
| 56B | 1e-5 → 1e-6 | 共 50 K | 同上 | 32 |
采样策略为领域均衡,防止某类任务过拟合。评估中使用温度 0.6、top-p 0.95,共采样 5 次平均准确率。对其他模型使用零样本链式提示(zero-shot CoT)调用 API 或公开模型。
6.1.1 物理常识评估结果
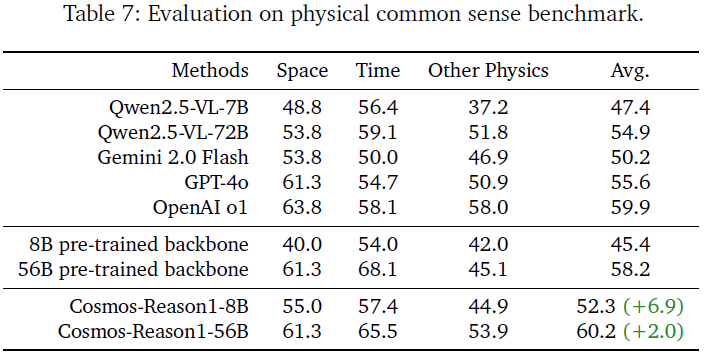
分析:
- 56B 模型超越所有对比模型,包括 OpenAI o1 与 GPT-4o
- 8B 模型也显著优于同尺寸的 Qwen 7B,验证物理常识数据的有效性
6.1.2 具身推理评估结果
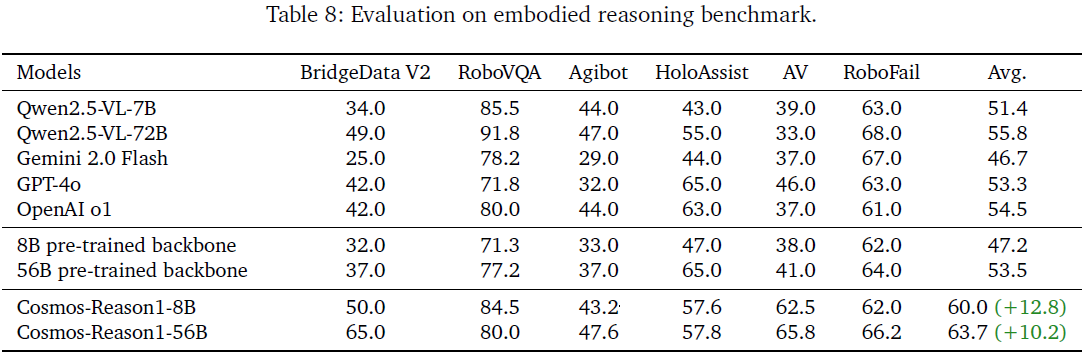
分析:
- Cosmos-Reason1 显著领先其他模型(提升幅度 10~13 %)
- AV 与 Bridge 子任务提升尤为明显,体现其对 “预测下一个动作” 的优势
- 56B 模型综合能力最强,特别适应高复杂任务如 RoboFail
6.1.3 直觉物理能力评估
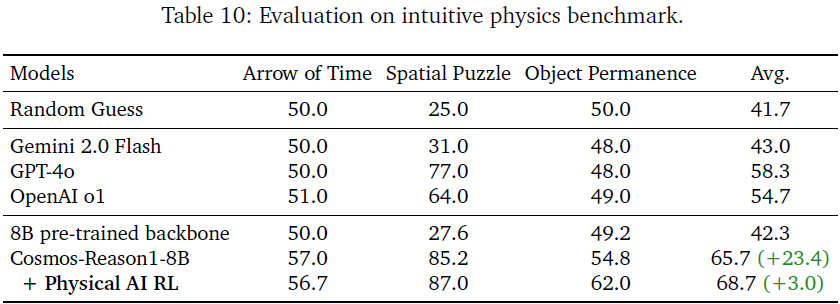
分析:
- 主流 VLM 在 Object Permanence 和 Arrow of Time 上接近随机水平,暴露出 对基本物理原理的理解不足
- Cosmos-Reason1-8B 在三项任务上均大幅领先,证明直觉物理监督微调数据有效
6.2 物理 AI 强化学习实验结果
6.2.1 RL 基础设施设计
- 构建了类 veRL 与 OpenRLHF 的 自定义强化学习框架
- 采用 Ray分布式架构 管理 rollout、reward、policy 同步
- 实现了 渐进批处理机制 提高吞吐,优化 NCCL 通信
RL 算法:GRPO(Generalized Reward Propagation Optimization)
1)无需 Critic,仅基于组内标准化奖励计算优势函数:
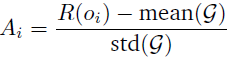
其中,R 为奖励函数,o 为相应,G 为响应组 𝒢 = {𝑜_1, 𝑜2, . . . , 𝑜_𝐺}
2)训练参数:
- 学习率:4e-6
- 批次大小:128 问题 × 每问题 9 个生成
- KL 惩罚项:0.005
- 最大 token 数:6144
6.2.2 RL 后训练效果

分析:
- 平均提升 +8.2%,RL后训练有效巩固推理能力
- 提升最显著的任务包括Bridge(+16.4%)、HoloAssist(+14.6%)、AV(+13.9%)
- 常识任务也获得稳定提升(+2.8%)
7. 相关工作
7.1 视觉物理理解
IntPhys、PHYRE、Physical VQA 等数据集致力于测评模型对基本物理规律的理解(如物体连续性、力与结果等)。
DynamicsNet、Visual Interaction Networks (VINs) 等方法强调对物体状态和交互动态建模,支持轨迹预测。
这些方法大多依赖于显式物理模拟或结构化输入,缺乏复杂视觉条件下的高层次语言推理能力。
7.2 视频问答
传统视频 QA 模型如 TVQA、Next-QA、VideoChatGPT 等,主要聚焦于 “谁做了什么” 类事实性问题。
VideoCoCa 与 Video-LLAVA 尝试将多模态预训练扩展到视频场景,但缺少 链式思维输出能力,不适合复杂物理问题。
本文所构建的 Cosmos-Reason1,更注重 因果性理解、物理可行性推理与直觉物理建模,超越了传统视频 QA 范畴。
7.3 具身 AI
数据集如 ALFRED、TEACh、Ego4D 强调基于第一人称视频的动作预测与场景交互,适用于训练具身代理。
EAI Benchmarks(如BridgeData、RoboVQA) 提供语义任务标注、动作图谱和物理反馈,强调行动合理性。
但现有系统往往采用模块化 pipeline 或强化学习策略,不具备语言模型驱动的 可解释长链推理能力。
7.4 多模态大模型
模型如 GPT-4V、Gemini、Qwen-VL、InternVL、LLaVA 提供图文/视文理解能力,已被广泛用于问答与生成任务。
GPT-4o 具备多模态输入能力,但在直觉物理和具身预测方面仍表现接近随机。
本文方法结合了 Mamba 模块的效率与 Transformer 的推理能力,并引入任务专属训练策略,形成针对物理智能任务的优化路径。
7.5 RLHF 与物理推理奖励优化
强化学习在人类偏好对齐(如 ChatGPT)中已广泛应用。
本文首次提出适用于视频物理任务的可验证性奖励机制(accuracy + formatting),配合无 critic 的 GRPO 算法,在 MCQ 格式上实现稳定增益。
相比之前使用隐式奖励或人类偏好评分的方式,本方法更可控、更高效、适用于复杂推理验证。
8. 结论
Cosmos-Reason1 是专为物理 AI 推理任务设计的多模态大语言模型,创新地引入物理常识与具身推理双本体论,融合预训练、监督学习与强化学习,显著提升模型在真实物理场景中的理解与决策能力。文中还提出多个挑战性基准,填补当前多模态模型在基础物理推理能力上的评估空白。
论文地址:https://arxiv.org/abs/2503.15558
项目页面:https://github.com/nvidia-cosmos/cosmos-reason1
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 21
21 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)